






微调的概念
首先为什么要微调呢?现在的大模型大多数都是“foundation”模型,是非常泛化的,它们在众多专业领域的表现是不如我们微调之后的模型的,所以微调其实就是将一个泛型化的大模型调整成为一个更适用于某个专业领域的专用大模型。
两种常用的微调范式:增量预训练和指令跟随。增量预训练微调主要是为了让一个模型学到一些新知识,如某个垂类领域的知识,训练数据通常为文章,书籍,代码等等,不需要标注。而指令跟随微调是为了让模型学会对话模板,根据人类指令进行对话,常用数据为高质量的对话和问答数据,需要标注。
看一个流程图:
微调的过程
一条数据如何成为一条用于训练模型的数据呢?首先要将原始数据转变为模型可以识别的数据,即标准格式数据,通常为一种固定格式的JSON 文件;之后把数据喂给模型时,需要创建对话模板,帮助模型区分什么是用户说的,什么是模型回答的,具体操作是增加一些分隔符。通常我们也只对output值计算loss。
接下来看一看微调方案。
LoRA方法:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
看一下具体的内容: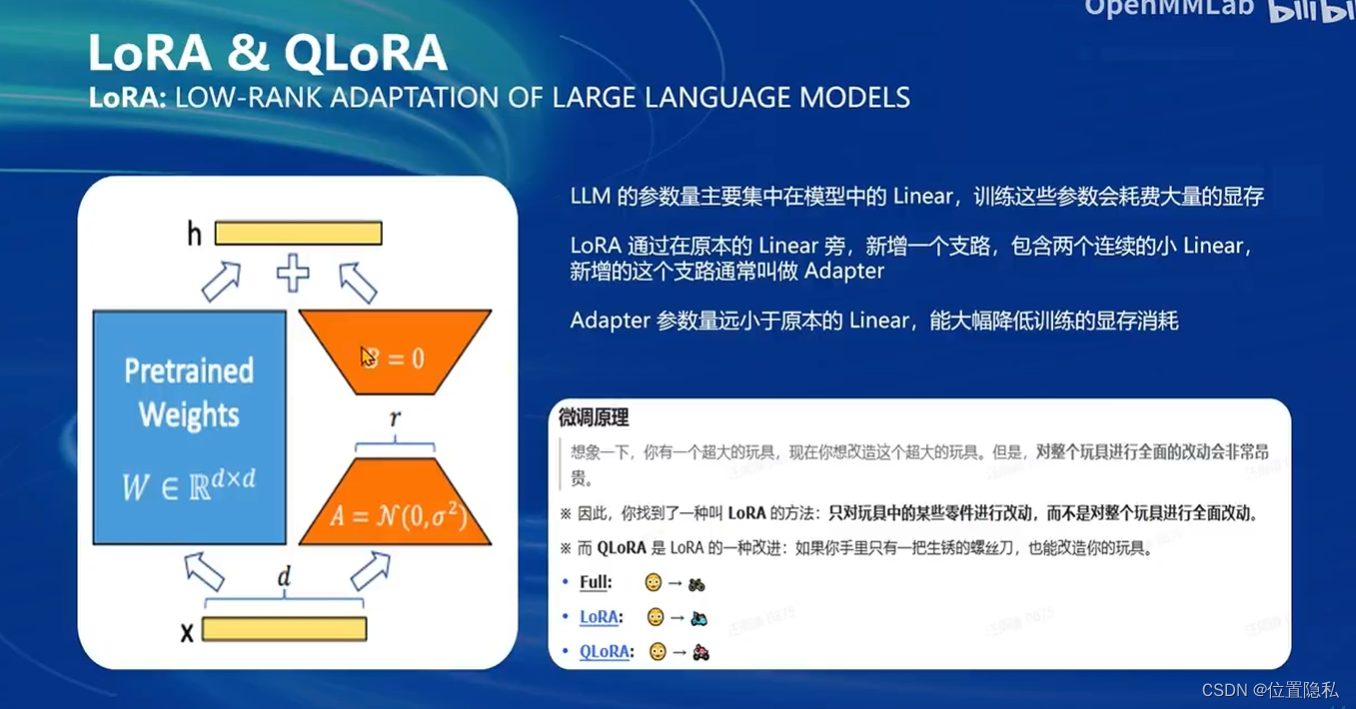
多模态LLM原理
多模态LLM,就是不仅能够识别文本,而且能够识别图像。使用方案为LLAVA,输入为文本问题和图像,输出是回答文本,形成数据对,可以用单模态大语言模型训练出一个image projector。两者统称为LLAVA模型。训练过程依旧分为两个阶段:Pretrain和Finetune。简单来讲就是先用简单的问题文本和图像进行预训练,然后将预训练的大模型通过更加复杂更加具有价值的高质量文本和图像进行训练。
XTUNER微调实战
见:Tutorial/xtuner/llava/xtuner_llava.md at camp2 · InternLM/Tutorial (github.com)















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









