






目录
1. 引言
GCANet(Gate-Controlled Attention Network)是一种用于图像去雾的深度学习算法,通过引入注意力机制来改进传统的去雾方法,提升去雾效果,增强图像的清晰度和可见性,并且能够在复杂的雾天场景中提供卓越的去雾效果。其自适应的特征增强机制使其在各种实际应用中表现出色。
GCANet的核心思想是使用门控注意力机制来关注图像中的重要特征,从而更有效地去除雾气。
GCANet包含两个主要部分:
1.特征提取网络(Feature Extraction Network):
该网络用于提取输入雾天图像的特征。它通常由多个卷积层和非线性激活函数组成,能够捕捉图像中的低级和高级特征。
2.门控注意力模块(Gate-Controlled Attention Module):
该模块是GCANet的关键创新。它通过计算不同通道和空间位置的注意力权重来识别重要的图像区域。注意力模块利用这些权重来调整特征图,抑制不重要的信息,增强重要的特征。
2. 门控上下文注意机制(GCA)
注意机制是用来调节学习特征的相对重要性。图1所示的GCA操作分为两个主要阶段:全局上下文池化和注意力门控。
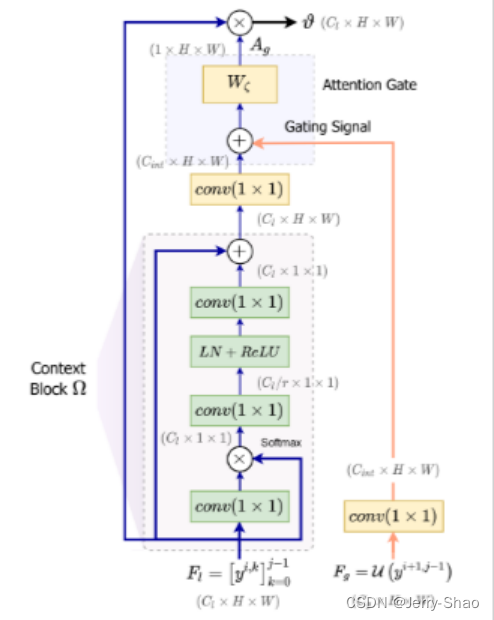
门控上下文注意块结构
3. 去雾流程
1.输入雾天图像:首先将雾天图像输入到特征提取网络中,提取出多尺度的特征图。
2.注意力计算:在特征提取过程中,门控注意力模块会计算每个特征图的注意力权重,生成门控注意力图。
3.特征增强:将门控注意力图应用于特征图,以增强有用的特征并抑制噪声。
4.图像重建:通过去雾网络将增强后的特征图还原为清晰的图像。
4. 模型代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShareSepConv(nn.Module):
def __init__(self, kernel_size):
super(ShareSepConv, self).__init__()
assert kernel_size % 2 == 1, 'kernel size should be odd'
self.padding = (kernel_size - 1)//2
weight_tensor = torch.zeros(1, 1, kernel_size, kernel_size)
weight_tensor[0, 0, (kernel_size-1)//2, (kernel_size-1)//2] = 1
self.weight = nn.Parameter(weight_tensor)
self.kernel_size = kernel_size
def forward(self, x):
inc = x.size(1)
expand_weight = self.weight.expand(inc, 1, self.kernel_size, self.kernel_size).contiguous()
return F.conv2d(x, expand_weight,
None, 1, self.padding, 1, inc)
class SmoothDilatedResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(SmoothDilatedResidualBlock, self).__init__()
self.pre_conv1 = ShareSepConv(dilation*2-1)
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.pre_conv2 = ShareSepConv(dilation*2-1)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(self.pre_conv1(x))))
y = self.norm2(self.conv2(self.pre_conv2(y)))
return F.relu(x+y)
class ResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = self.norm2(self.conv2(y))
return F.relu(x+y)
class GCANet(nn.Module):
def __init__(self, in_c=4, out_c=3, only_residual=True):
super(GCANet, self).__init__()
self.conv1 = nn.Conv2d(in_c, 64, 3, 1, 1, bias=False)
self.norm1 = nn.InstanceNorm2d(64, affine=True)
self.conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.norm2 = nn.InstanceNorm2d(64, affine=True)
self.conv3 = nn.Conv2d(64, 64, 3, 2, 1, bias=False)
self.norm3 = nn.InstanceNorm2d(64, affine=True)
self.res1 = SmoothDilatedResidualBlock(64, dilation=2)
self.res2 = SmoothDilatedResidualBlock(64, dilation=2)
self.res3 = SmoothDilatedResidualBlock(64, dilation=2)
self.res4 = SmoothDilatedResidualBlock(64, dilation=4)
self.res5 = SmoothDilatedResidualBlock(64, dilation=4)
self.res6 = SmoothDilatedResidualBlock(64, dilation=4)
self.res7 = ResidualBlock(64, dilation=1)
self.gate = nn.Conv2d(64 * 3, 3, 3, 1, 1, bias=True)
self.deconv3 = nn.ConvTranspose2d(64, 64, 4, 2, 1)
self.norm4 = nn.InstanceNorm2d(64, affine=True)
self.deconv2 = nn.Conv2d(64, 64, 3, 1, 1)
self.norm5 = nn.InstanceNorm2d(64, affine=True)
self.deconv1 = nn.Conv2d(64, out_c, 1)
self.only_residual = only_residual
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = F.relu(self.norm2(self.conv2(y)))
y1 = F.relu(self.norm3(self.conv3(y)))
y = self.res1(y1)
y = self.res2(y)
y = self.res3(y)
y2 = self.res4(y)
y = self.res5(y2)
y = self.res6(y)
y3 = self.res7(y)
gates = self.gate(torch.cat((y1, y2, y3), dim=1))
gated_y = y1 * gates[:, [0], :, :] + y2 * gates[:, [1], :, :] + y3 * gates[:, [2], :, :]
y = F.relu(self.norm4(self.deconv3(gated_y)))
y = F.relu(self.norm5(self.deconv2(y)))
if self.only_residual:
y = self.deconv1(y)
else:
y = F.relu(self.deconv1(y))
return y5. GCANet的优势
自适应性强:通过门控注意力机制,GCANet可以自适应地关注不同图像中的重要区域,提高去雾效果。
去雾效果好:相比传统的去雾方法和一些简单的深度学习模型,GCANet在处理复杂的雾天场景时表现更好。
易于训练:GCANet的结构设计合理,训练过程相对简单,适用于各种雾天图像数据集。
6. 去雾效果



















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









