







response = requests.get(url=url, headers=headers)
print(response)
然后直接运行
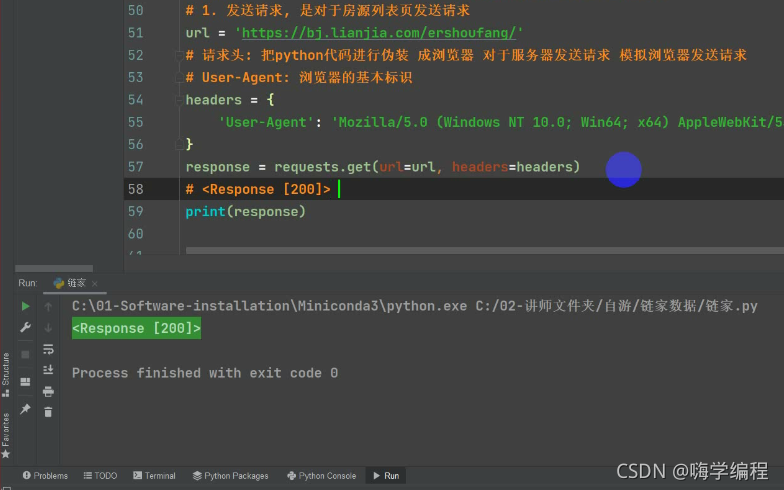 这里返回的是response [200]>
这里返回的是response [200]>
它是响应体的一个对象
200 是一个状态码,表示请求成功,说明咱们对网站的发送请求没有问题了。
那么为什么返回的不是数据,而是response [200]>呢?
2、获取数据
这时候咱们就要获取文本数据了,打印的时候在response后面加上text,获取响应体的文本数据。这样子咱们才能获取到跟网页源代码一样的数据了。
print(response.text)
 很多人觉得编程难,这其实不难,现在两步实现了,才五行代码,而且基本上都是复制粘贴的。多试几遍不就记住了,对吧。
很多人觉得编程难,这其实不难,现在两步实现了,才五行代码,而且基本上都是复制粘贴的。多试几遍不就记住了,对吧。
3、解析数据
提取我们想要的内容, 房源详情页url。
首先导入咱们的数据解析模块
import parsel
我们获取到的response.text ,它是一个html字符串数据内容。如果你想要对于字符串数据内容直接解析提取的话,只能用re正则表达式。
但是咱们今天是用的parsel模块,所以我们要对我们获取到的HTML字符串内容进行转换,转成Selector方法,然后response.text给它传进去。
然后用Selector变量接收一下,打印看看是个啥
print(Selector)
它这里返回的就是一个Selector对象
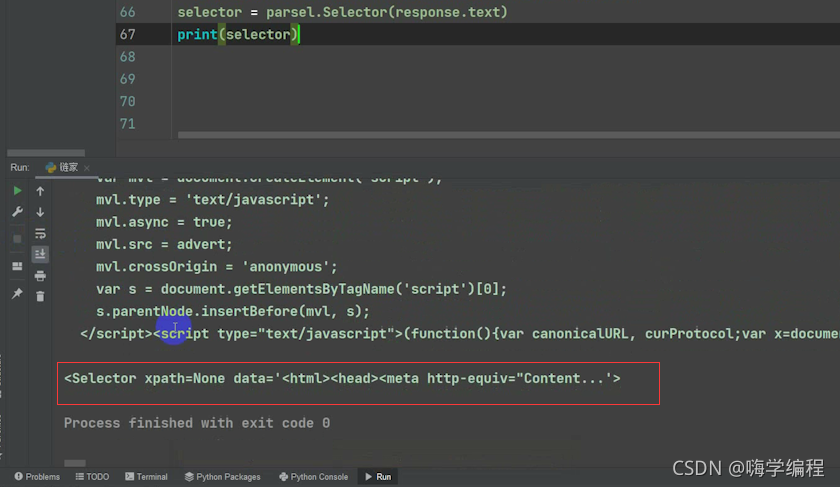 那这个对象里面我们就可以调用它相对应的一些方法, 我们今天调用的是一个css的选择器。
那这个对象里面我们就可以调用它相对应的一些方法, 我们今天调用的是一个css的选择器。
css选择器是一个解析方法,根据标签属性内容提取相关的数据。
selector.css(‘’)
首先点击开发者工具上的那个箭头,点击我们想要的东西。
我们想要的是这个url地址
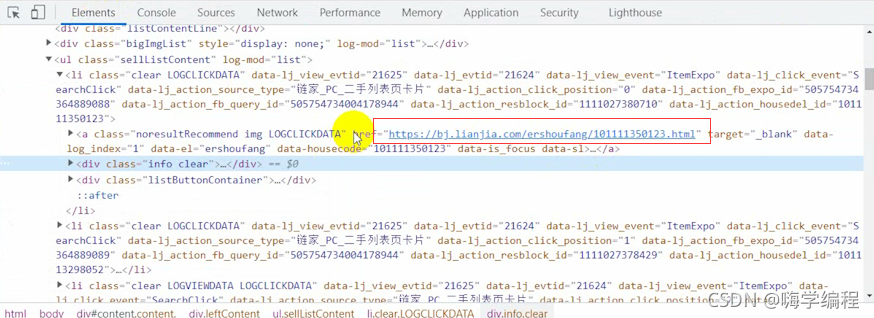 如果我们不会css语法,就直接选中这里
如果我们不会css语法,就直接选中这里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5791
5791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









