







最近这一两周看到不少互联网公司都已经开始秋招发放Offer。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

基本术语
多模态人工智能利用来自多个不同模态(如文本、图像、声音、视频等)的数据进行学习和推理。多模态人工智能强调不同模态数据之间的互补性和融合性,通过整合多种模态的数据,利用表征学习、模态融合与对齐等技术,实现跨模态的感知、理解和生成,推动智能应用的全面发展。
接下来分三部分:_数据采集与表示、数据处理与融合、学习与推理,一起来科普下多模型的基本术语。

一、数据采集与表示
什么是传感器(Sensor)?传感器是一种检测物理量并将其转换为可测量信号的装置或元件。在多模态学习中,传感器用于捕捉不同模态的数据,如摄像头捕捉图像(视觉模态)、麦克风捕捉声音(声音模态)等。
传感器是多模态数据采集的起点,它使得机器能够感知并获取来自不同物理世界的信息。

传感器
什么是模态(Modal)?模态是指信息的表现形式或感知方式,如文本、图像、声音、视频等。在语言学中,模态也可以指说话人对某种语言表达的态度或语气。但在多模态学习中,我们主要关注数据的表现形式。
什么是多模态(MultiModal)?多模态是指利用来自多个不同模态的数据进行学习和推理的过程。这些模态可以是文本、图像、声音、视频等的组合。
不同的模态提供了不同的信息渠道,它们之间可能存在冗余性,但更多的是互补性。多模态模型能够整合来自不同模态的信息,正是利用这些不同模态的信息来增强模型的感知与理解能力。

多模态
什么是表征学习(Representation Learning)?表征学习是指学习数据的有效表示方式,使得数据在该表示下更容易被机器学习算法处理。
在多模态学习中,表征学习是关键环节之一。它负责将原始的多模态数据转换为适合模型处理的低维、稠密且富有语义信息的表示。
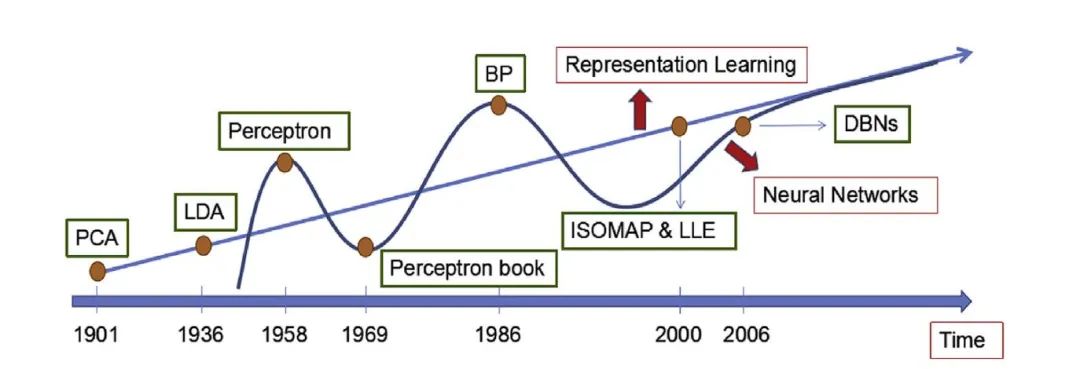
表征学习
二、数据处理与融合
什么是模态融合(Modal Fusion)?模态融合是指将来自不同模态的信息进行有效整合的过程。
-
早期融合:在数据处理的早期阶段就将不同模态的数据合并在一起。
-
晚期融合:在数据处理的后期阶段才将不同模态的信息进行整合。
-
混合融合:结合早期融合和晚期融合的优点,在不同的处理阶段进行多次融合。
模态融合能够充分利用不同模态之间的互补性,提高模型的性能和鲁棒性。
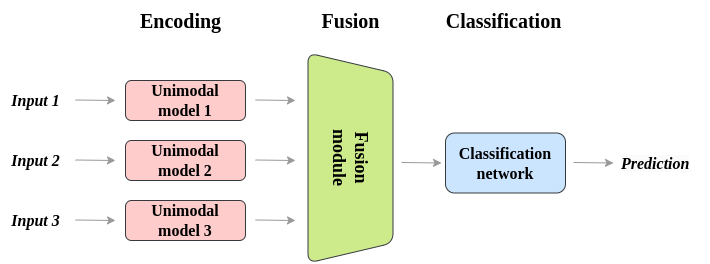
模态融合
什么是模态对齐(Modal Alignment)?模态对齐是指寻找来自不同模态数据之间的对应关系或一致性。
-
时间维度对齐:如将视频中的动作与音频中的语音进行对齐。
-
空间维度对齐:如将图像中的像素与文本中的单词进行对齐。
模态对齐是多模态学习中实现不同模态信息有效融合的重要前提。通过对齐操作,可以确保不同模态的数据在时间和空间上保持一致性,从而进行更有效的融合和推理。

模态对齐
三、学习与推理
什么是迁移学习(Transfer Learning)?迁移学习是一种机器学习方法,它利用在一个任务上学到的知识来帮助解决另一个不同但相关的任务。
在多模态学习中,迁移学习可以帮助模型更快地适应新的模态或任务,提高学习效率。例如,可以将在大量文本数据上学到的知识迁移到图像描述任务中。

迁移学习
什么是多模态学习(Multimodal Learning)?多模态学习是指利用来自多个不同模态的数据进行学习和推理的过程。它旨在整合不同模态之间的互补信息,以提高模型的感知与理解能力。
多模态学习是当前人工智能领域的一个研究热点,它推动了智能应用的边界扩展。通过多模态学习,我们可以构建更加智能、更加全面的系统来应对复杂多变的现实世界。

多模态学习

基础知识
在人工智能的不断发展中,多模态学习逐渐崭露头角,成为了一个重要的研究方向。它不再局限于单一类型的数据处理,而是将图像、文本、音频等多种信息源结合起来,为机器提供了更加丰富和多元的理解视角。
接下来分四部分:传统机器学习、深度学习___、优化算法、应用领域,___一起来总结下多模型的基础知识。

MultiModal
一、传统机器学习
什么是传统机器学习(Machine Learning)?传统机器学习涉及模型评估与选择、线性模型应用、分类与回归等多种技术,旨在通过训练数据集学习并构建模型,以实现对未知数据的准确预测或分类。

机器学习
什么是模型评估(Evaluate)与选择?在传统机器学习中,模型评估是选择最佳模型的关键步骤。这通常涉及将数据集分为训练集、测试集和验证集,使用训练集来训练模型,然后使用测试集来评估模型的性能。
常见的评估指标包括准确率、精确率、召回率、F1分数等。模型选择则是基于这些评估指标来挑选出最优的模型。

模型评估
什么是线性模型(Linear Model)?线性模型是最简单的机器学习模型之一,它假设目标变量与特征之间存在线性关系。线性回归和逻辑回归是线性模型的典型代表。线性回归用于预测连续值,而逻辑回归则用于二分类问题。

线性模型
什么是分类(Classification)?分类是机器学习中的一个重要领域,它旨在将输入数据分配到预定义的类别中。除了逻辑回归外,决策树、随机森林、支持向量机(SVM)和K近邻(KNN)等算法也是分类任务中常用的方法。

分类
什么是回归(Regression)?与分类不同,回归任务的目标是预测一个连续值。除了线性回归外,多项式回归、岭回归和套索回归等也是处理回归问题的常用技术。

二、深度学习
什么是深度学习(Deep Learning)?深度学习通过构建多层神经网络,自动学习数据特征,实现预测、分类等任务,广泛应用于图像、语音、文本等领域。
它涵盖了多种网络结构,如卷积神经网络(CNN)用于图像和视频处理,循环神经网络(RNN)及其改进版如LSTM、GRU等用于序列数据处理,以及Transformer等基于自注意力机制的模型在自然语言处理(NLP)领域的广泛应用。

什么是卷积神经网络(CNN)?CNN是深度学习中最常用于处理图像和视频数据的网络结构。它通过卷积层自动提取图像中的局部特征,并通过池化层减少数据的空间维度,最终通过全连接层进行分类或回归。

什么是循环神经网络(RNN)?RNN特别适合于处理序列数据,如文本、语音和时间序列。它能够捕捉序列中的长期依赖关系,但由于梯度消失或梯度爆炸问题,训练传统RNN可能很困难。
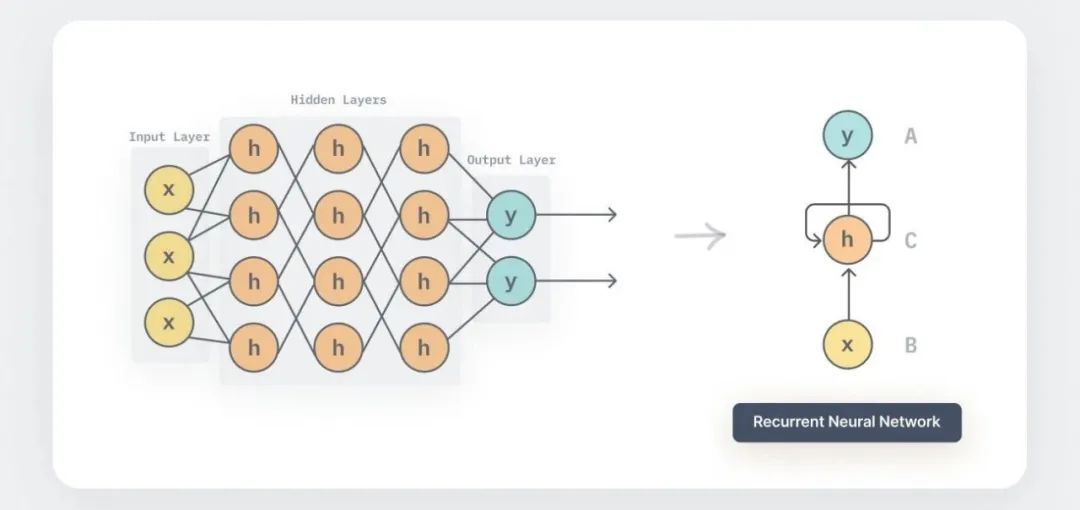
什么是Transformer?Transformer是一种基于自注意力机制的模型,它彻底改变了自然语言处理(NLP)领域。Transformer通过多头注意力机制并行处理输入序列的所有位置,从而避免了RNN的序列依赖性,大大提高了处理速度和效果。Transformer及其变体(如BERT、GPT系列)已成为NLP任务的主流模型。

三、优化算法
什么是优化算法(Optimization Algorithm)?优化算法是用于寻找最小化或最大化某个目标函数(如损失函数)的参数值的方法。在深度学习中,这通常涉及到调整神经网络的权重和偏置,涉及到梯度下降和反向传播。
梯度下降是常用优化算法,通过计算目标函数对参数的梯度,并反向更新参数以逼近最优解。反向传播是训练神经网络时高效计算梯度的方法,与梯度下降结合,有效调整网络参数。

什么是梯度下降(Gradient Descent)?梯度下降是最常用的优化算法之一,用于最小化目标函数(即损失函数)。它通过计算目标函数关于模型参数的梯度,并沿着梯度的反方向更新参数来逐步逼近最优解。

梯度下降
什么是反向传播(Backpropagation)?反向传播是训练神经网络时常用的梯度计算方法。它利用链式法则从输出层开始逐层计算梯度,并更新每一层的参数。反向传播与梯度下降结合使用,可以高效地训练神经网络。

四、应用领域
多模态应用领域有哪些?多模态学习涵盖了计算机视觉(CV)、自然语言处理(NLP)和语音识别等多个应用领域。
什么是计算机视觉(Computer Vision, CV)?CV是多模态学习的一个重要应用领域,它涉及对图像和视频内容的理解和分析。CNN在CV任务中表现出色,被广泛应用于图像分类、目标检测、图像分割、人脸识别等任务中。

计算机视觉
什么是自然语言处理(Natural Language Processing,NLP)?NLP是另一个重要的应用领域,它涉及对文本数据的理解和生成。Transformer及其变体在NLP任务中取得了巨大成功,被广泛应用于文本分类、情感分析、机器翻译、问答系统等任务中。

自然语言处理
什么是语音识别(Speech Recognition)?语音识别是另一个融合了多种模态(如音频和文本)的应用领域。它旨在将人类语音转换为文本表示,并进一步用于NLP任务。

语音识别

多模态学习
多模态学习(Multimodal Learning)是一种利用来自不同感官或交互方式的数据进行学习的方法,这些数据模态可能包括文本、图像、音频、视频等。多模态学习通过融合多种数据模态来训练模型,从而提高模型的感知与理解能力,实现跨模态的信息交互与融合。
接下来分三部分:模态表示、多模态融合、跨模态对齐,一起来总结下多模型的核心:多模态学习

MultiModal
一、模态表示
什么是模态表示(Modal Representation)?模态表示是将不同感官或交互方式的数据(如文本、图像、声音等)转换为计算机可理解和处理的形式,以便进行后续的计算、分析和融合。
-
文本模态的表示:文本模态的表示方法有多种,如独热表示、低维空间表示(如通过神经网络模型学习得到的转换矩阵将单词或字映射到语义空间中)、词袋表示及其衍生出的n-grams词袋表示等。目前,主流的文本表示方法是预训练文本模型,如BERT。
-
视觉模态的表示:视觉模态分为图像模态和视频模态。图像模态的表示主要通过卷积神经网络(CNN)实现,如LeNet-5、AlexNet、VGG、GoogLeNet、ResNet等。视频模态的表示则结合了图像的空间属性和时间属性,通常由CNN和循环神经网络(RNN)或长短时记忆网络(LSTM)等模型共同处理。
-
声音模态的表示:声音模态的表示通常涉及音频信号的预处理、特征提取和表示学习等步骤,常用的模型包括深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)等。
表征学习(Representation Learning)旨在从原始数据中自动提取有效特征,形成计算机可理解的模态表示,以保留关键信息并促进跨模态交互与融合。
表征学习(Representation Learning) ≈ 向量化(Embedding)-
什么是多模态联合表示(Joint Representation)?多模态联合表示是一种将多个模态(如文本、图像、声音等)的信息共同映射到一个统一的多模态向量空间中的表示方法。
多模态联合表示通过神经网络、概率图模型将来自不同模态的数据进行融合,生成一个包含多个模态信息的统一表示。这个表示不仅保留了每个模态的关键信息,还能够在不同模态之间建立联系,从而支持跨模态的任务,如多模态情感分析、视听语音识别等。
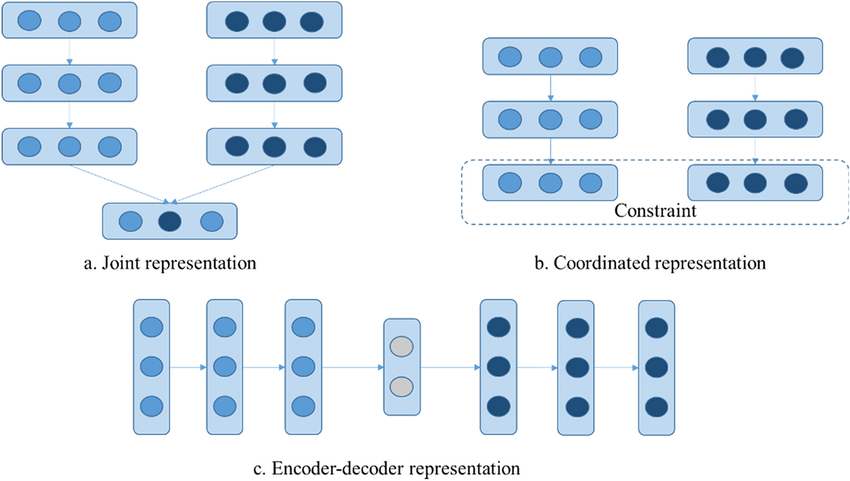
多模态表示
什么是多模态协同表示(Coordinated Representation)?多模态协同表示是一种将多个模态的信息分别映射到各自的表示空间,但映射后的向量或表示之间需要满足一定的相关性或约束条件的方法。这种方法的核心在于确保不同模态之间的信息在协同空间内能够相互协作,共同优化模型的性能。
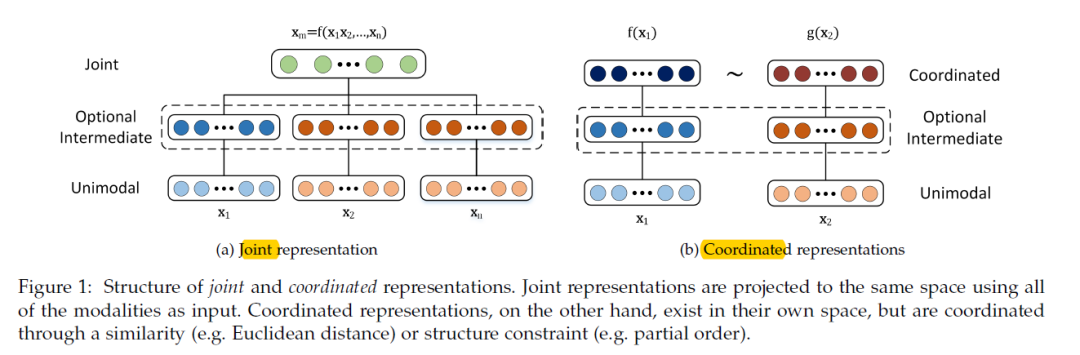
多模态表示
二、多模态融合
什么是多模态融合(MultiModal Fusion)?多模态融合能够充分利用不同模态之间的互补性,它将抽取自不同模态的信息整合成一个稳定的多模态表征。从数据处理的层次角度将多模态融合分为数据级融合、特征级融合和目标级融合。
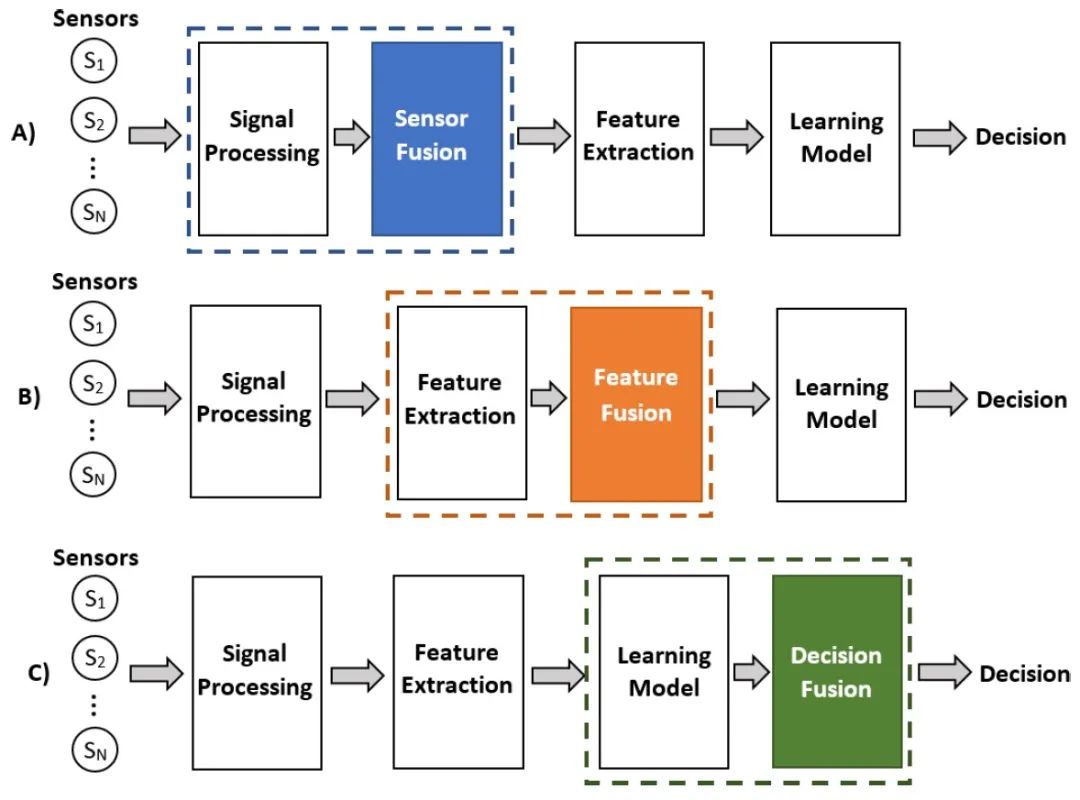
多模态融合
-
数据级融合(Data-Level Fusion):
-
数据级融合,也称为像素级融合或原始数据融合,是在最底层的数据级别上进行融合。这种融合方式通常发生在数据预处理阶段,即将来自不同模态的原始数据直接合并或叠加在一起,形成一个新的数据集。
-
应用场景:适用于那些原始数据之间具有高度相关性和互补性的情况,如图像和深度图的融合。
-
-
特征级融合(Feature-Level Fusion):
-
特征级融合是在特征提取之后、决策之前进行的融合。不同模态的数据首先被分别处理,提取出各自的特征表示,然后将这些特征表示在某一特征层上进行融合。
-
应用场景:广泛应用于图像分类、语音识别、情感分析等多模态任务中。
-
-
目标级融合(Decision-Level Fusion):
-
目标级融合,也称为决策级融合或后期融合,是在各个单模态模型分别做出决策之后进行的融合。每个模态的模型首先独立地处理数据并给出自己的预测结果(如分类标签、回归值等),然后将这些预测结果进行整合以得到最终的决策结果。
-
应用场景:适用于那些需要综合考虑多个独立模型预测结果的场景,如多传感器数据融合、多专家意见综合等。
-
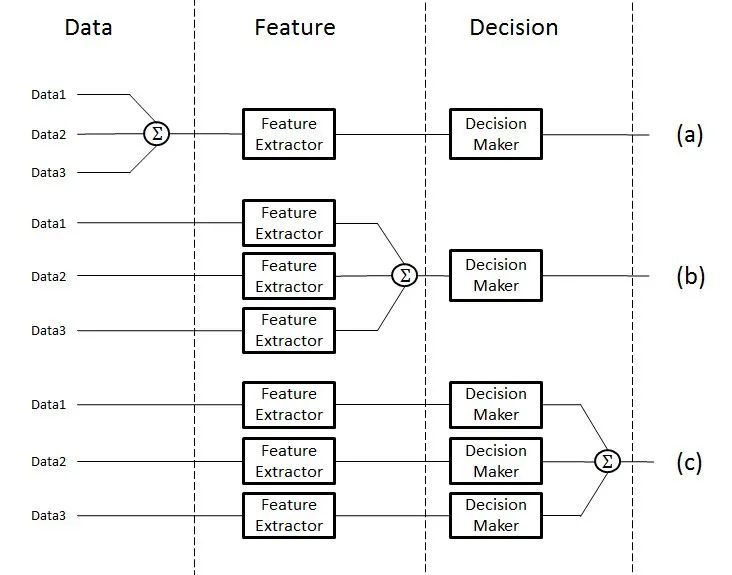
多模态融合
三、跨模态对齐
什么是跨模态对齐(MultiModal Alignment)?跨模态对齐是通过各种技术手段,实现不同模态数据(如图像、文本、音频等)在特征、语义或表示层面上的匹配与对应。跨模态对齐主要分为两大类:显式对齐和隐式对齐。

跨模态对齐
什么是显示对齐(Explicit Alignment)?直接建立不同模态之间的对应关系,包括无监督对齐和监督对齐。
-
无监督对齐:利用数据本身的统计特性或结构信息,无需额外标签,自动发现不同模态间的对应关系。
-
CCA(典型相关分析):通过最大化两组变量之间的相关性来发现它们之间的线性关系,常用于图像和文本的无监督对齐。
-
自编码器:通过编码-解码结构学习数据的低维表示,有时结合循环一致性损失(Cycle Consistency Loss)来实现无监督的图像-文本对齐。
-
-
监督对齐:利用额外的标签或监督信息指导对齐过程,确保对齐的准确性。
-
多模态嵌入模型:如DeViSE(Deep Visual-Semantic Embeddings),通过最大化图像和对应文本标签在嵌入空间中的相似度来实现监督对齐。
-
多任务学习模型:同时学习图像分类和文本生成任务,利用共享层或联合损失函数来促进图像和文本之间的监督对齐。
-
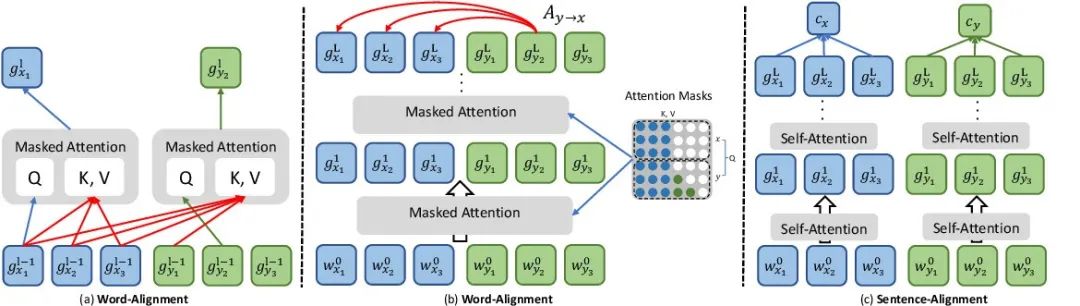
什么是隐式对齐(Implicit Alignment)?不直接建立对应关系,而是通过模型内部机制隐式地实现跨模态的对齐。这包括注意力对齐和语义对齐。
-
注意力对齐:通过注意力机制动态地生成不同模态之间的权重向量,实现跨模态信息的加权融合和对齐。
-
Transformer模型:在跨模态任务中(如图像描述生成),利用自注意力机制和编码器-解码器结构,自动学习图像和文本之间的注意力分布,实现隐式对齐。
-
BERT-based模型:在问答系统或文本-图像检索中,结合BERT的预训练表示和注意力机制,隐式地对齐文本查询和图像内容。
-
-
语义对齐:在语义层面上实现不同模态之间的对齐,需要深入理解数据的潜在语义联系。
-
图神经网络(GNN):在构建图像和文本之间的语义图时,利用GNN学习节点(模态数据)之间的语义关系,实现隐式的语义对齐。
-
预训练语言模型与视觉模型结合:如CLIP(Contrastive Language-Image Pre-training),通过对比学习在大量图像-文本对上训练,使模型学习到图像和文本在语义层面上的对应关系,实现高效的隐式语义对齐。
-















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









