







Spark MLlib模型—决策树系列算法
前面我们重点介绍了机器学习中的特征工程,以及 Spark MLlib 框架支持的特征处理函数。基于线性回归模型,我们对比了不同特征处理方法下的模型效果。
一般来说,线性模型的模型容量比较有限,它仅适合拟合特征向量与预测标的之间存在线性关系的场景。但在实际应用中,线性关系少之又少,就拿“房价预测”的项目来说,不同的房屋属性与房价之间,显然不是单纯的线性关系。这也是为什么在房价预测的任务上,线性回归模型的预测误差一直高居不下。因此,为了提升房价预测的准确度,我们有必要从模型选型的角度,着手去考虑采用其他类型的模型算法,尤其是非线性模型。
在机器学习领域,如果按照“样本是否存在预测标的(Label)”为标准,机器学习问题可以分为监督学习(Supervised Learning)与非监督学习(Unsupervised Learning)。Spark MLlib 同时支持这两大类机器学习算法,如下图所示。
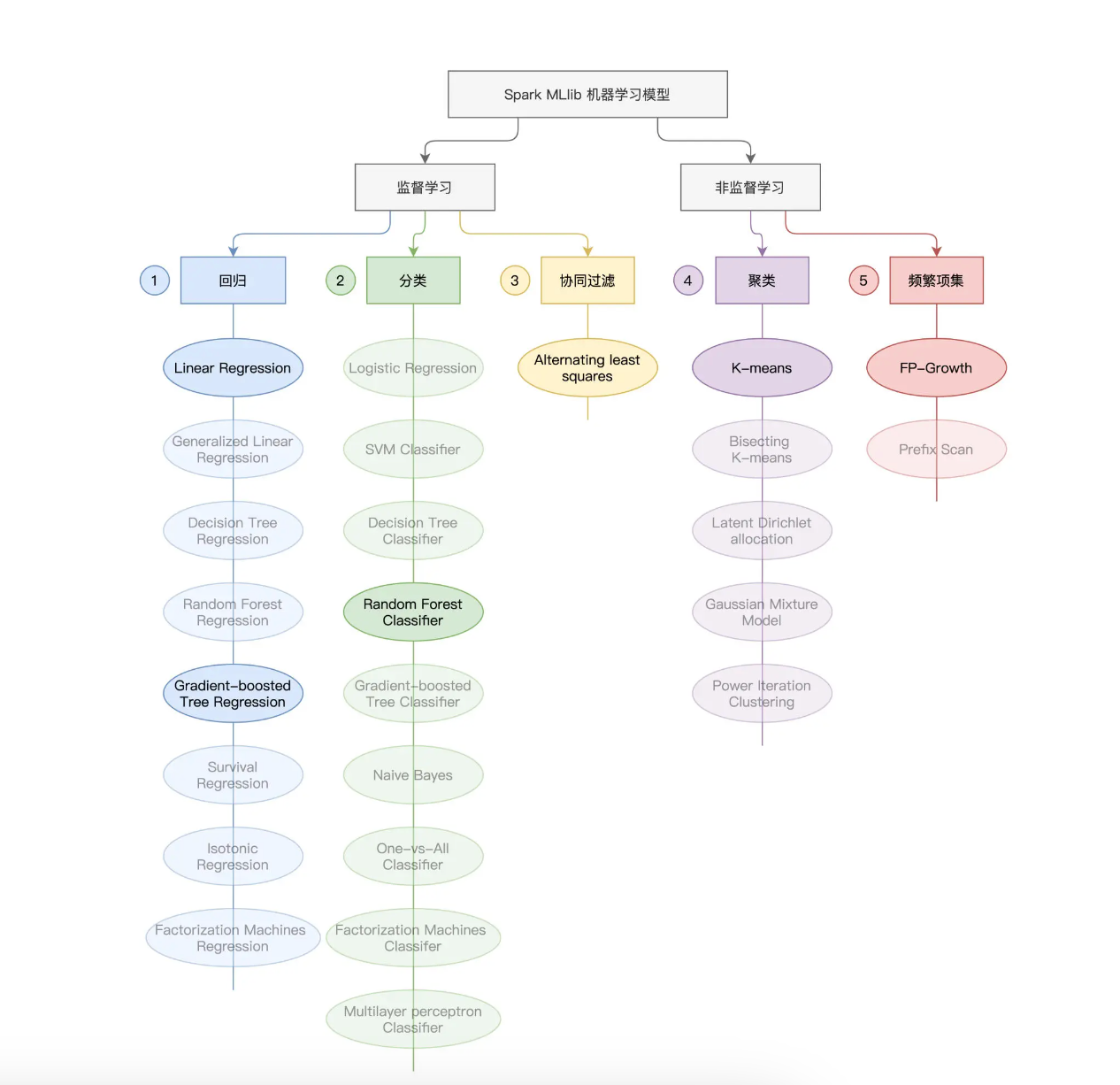
以看到,在 Spark MLlib 开发框架下,按照使用场景不同,监督学习又被细分为回归(Regression)、分类(Classification)和协同过滤(Collaborative Filtering);而非监督学习被细分为聚类(Clustering)与频繁项集(Frequency Patterns)。
决策树系列算法
马上就是“双十一”了,你可能很想血拼一把,但一摸自己的钱包,理智又占领了高地。试想一下,预算有限的情况下,你会如何挑选一款手机呢?我们往往会结合价位、品牌、评价等一系列因素考量,最后做出决策。其实这个依据不同决定性因素来构建决策路径的过程,放在机器学习里,就是决策树。接下来,我们用严谨一点的术语再描述一下什么是决策树。
决策树(Decision Trees)是一种根据样本特征向量而构建的树形结构。决策树由节点(Nodes)与有向边(Vertexes)组成,其中节点又分为两类,一类是内部节点,一类是叶子节点。内部节点表示的是样本特征,而叶子节点代表分类。
举例来说,假设我们想根据“居室数量”和“房屋面积”这两个特征,把房屋分为 5 类。那么,我们就可以构建一个决策树,来做到这一点,如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









