







前言
避坑autolabelimg,这个自动标注软件,因为他只支持yolov5s的训练模型,而且只支持检测coco数据集中的80个类别。
这个软件我尝试了很久,找了很多方法都不行,遂放弃了,到头来,发现yolov5就自带了保存预测标签的功能。在detect.py的参数里,–save-txt
下边是我目标检测训练的两个小玩具,小王子(prince)和加菲猫(garfield)


yolov5官网链接
https://github.com/ultralytics/yolov5
目录
本文流程分为两个主要部分:
1.下载安装yolov5进行推理测试
2.自己标注数据
3.训练自己的专属模型
4.使用自己的模型进行剩余图片的自动标注
1. yolov5 安装测试
把yolov5的环境搭建一下:
我的win11笔记本电脑联想拯救者2018款GPU 1060 , CUDA 10.1 所以安装Pytorch 1.7.1
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch
然后下载官方的代码
https://github.com/ultralytics/yolov5
这里点击code,点击 download zip就下载好了安装包。
然后在终端界面使用cd的方式进入目录该目录
pip install -r requirements.txt # install
然后去官网下载yolov5的模型进行测试,我这里准备了四个模型来测试,下载到yolov5/pt文件夹中,这个文件夹是我自己新建的
如图所示:
然后我新建了 demoimg文件夹放测试图片:

运行代码:
python detect.py --weights .\pt\yolov5m.pt --source .\demoimg\
如果报错找不到pillow库可以参考附录1:
运行结果保存到exp文件夹中了,去查看
(yolov5) PS G:\bsh\yolov5\yolov5-master> python detect.py --weights .\pt\yolov5m.pt --source .\demoimg\
detect: weights=['.\\pt\\yolov5m.pt'], source=.\demoimg\, data=data\coco128.yaml, imgsz=[640, 640], conf\_thres=0.25, iou\_thres=0.45, max\_det=1000, device=, view\_img=False, save\_txt=False, save\_conf=False, save\_crop=False, nosave=False, classes=None, agnostic\_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist\_ok=False, line\_thickness=3, hide\_labels=False, hide\_conf=False, half=False, dnn=False, vid\_stride=1
YOLOv5 2023-7-20 Python-3.8.17 torch-1.7.1 CUDA:0 (NVIDIA GeForce GTX 1060, 6144MiB)
Fusing layers...
YOLOv5m summary: 290 layers, 21172173 parameters, 0 gradients, 48.9 GFLOPs
image 1/2 G:\bsh\yolov5\yolov5-master\demoimg\1.jpg: 448x640 1 zebra, 24.0ms
image 2/2 G:\bsh\yolov5\yolov5-master\demoimg\2.jpg: 576x640 2 persons, 2 cars, 1 frisbee, 28.0ms
Speed: 2.0ms pre-process, 26.0ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp
检测结果还是一如既往的好,标注框要比yolov7自带的粗许多

然后准备标注数据集。
2. 标注图片
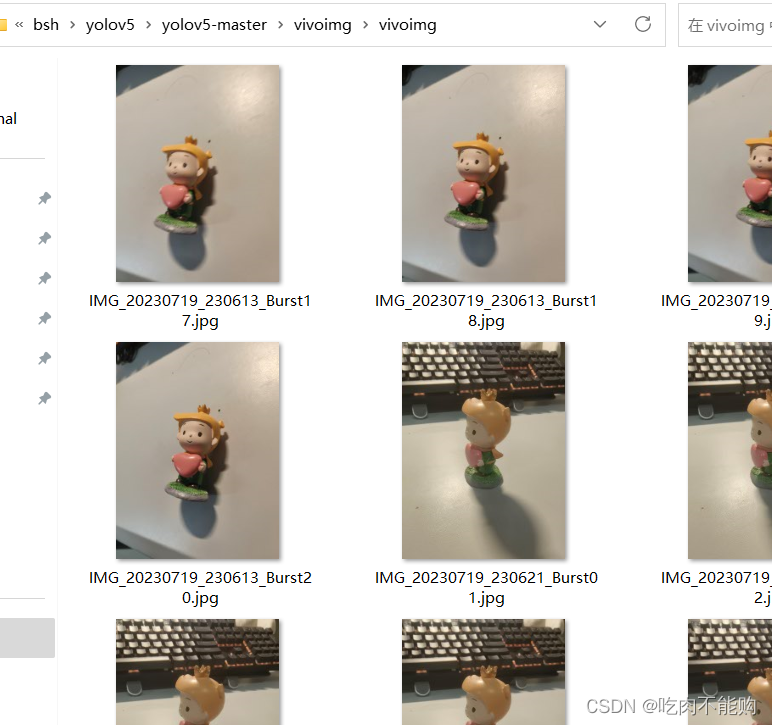
是我自己拍的200张照片,使用手机快门按住不松手,一次拍20张,然后拍10次,样本图片如下图,是两个小玩偶,一个是小王子(Prince),一个是加菲猫(Garfield)

手动标注36张图片,然后整合成数据集
参考链接:
http://t.csdn.cn/4fmx4
找到如下文件进行种类的修改:
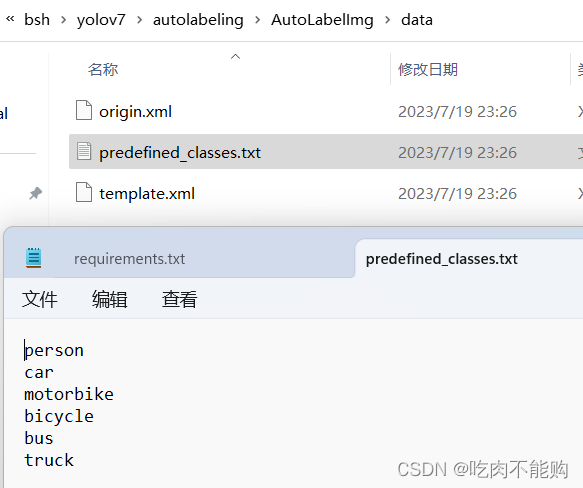
我删掉了,然后改为
prince
garfield
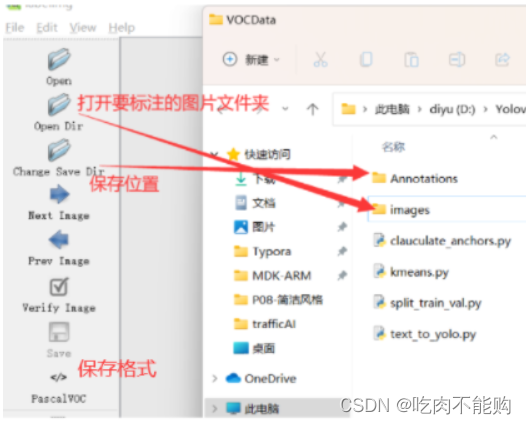
在yolov5的数据集文件夹中新建两个文件夹
运行autolabelimg
python .\labelImg.py
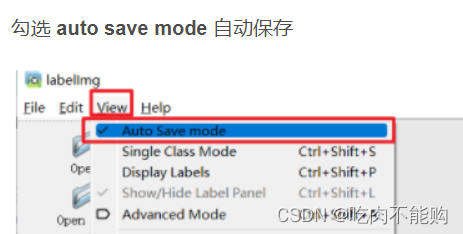
在运行的label软件勾选 view-Auto save mode
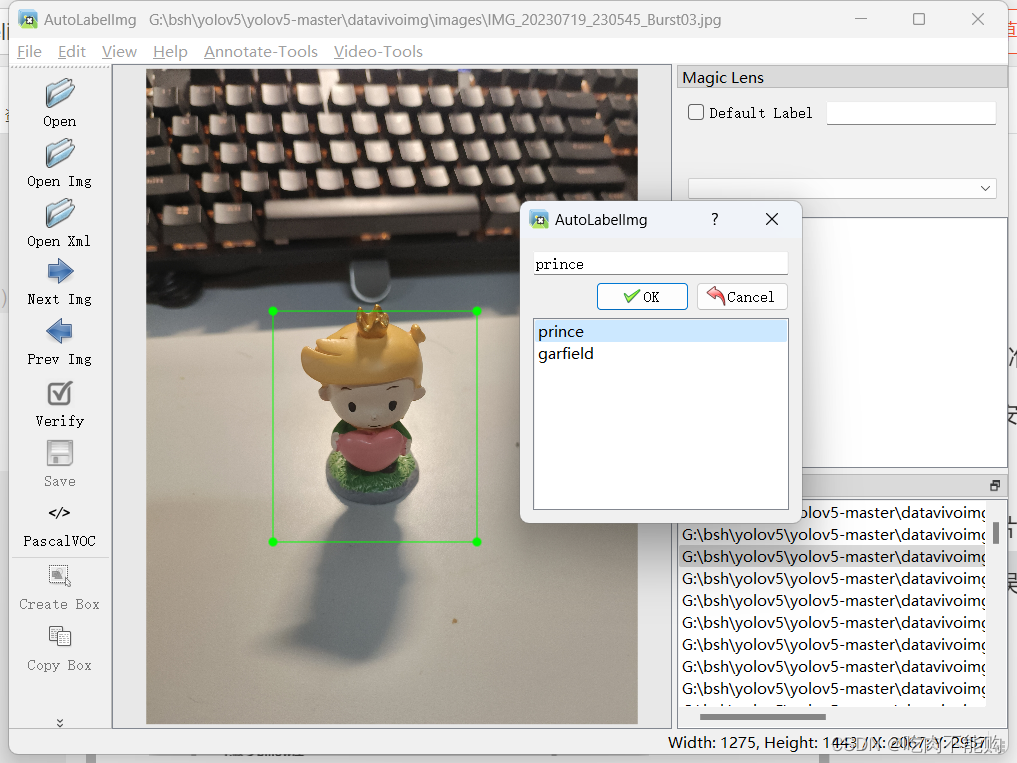
然后这个图是参考链接中的,和autolabelimg差不多,但是一个是open img,一个是open xml,一个意思,格式还是voc格式
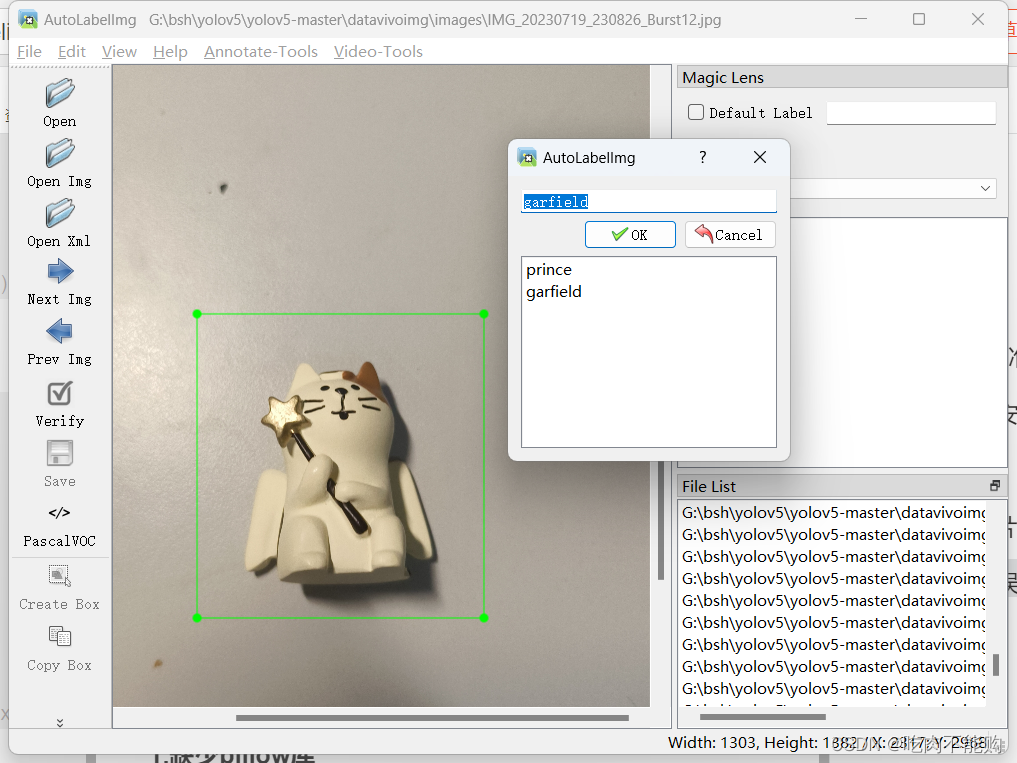
点击create box进行标注,我大概标注了36张,因为一开始标注了20张训练效果不好
可以点开看看样子,用记事本打开,这是voc格式,待会把他们转换成coco格式

然后划分划分训练集、验证集、测试集
在Annotation和images相同目录放一个split_train_val.py文件
然后把split_train_val.py文件代码粘贴上:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml\_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt\_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.8 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
直接运行
python
会自动生成imagesets文件夹,里边还有个Main文件夹,Main里边有几个txt文件

然后再把数据集的voc格式改为coco格式,在datavivoimg目录下创建程序 text_to_yolo.py 并运行
# -\*- coding: utf-8 -\*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["prince", "garfield"] # 改成自己的类别
img_path = "D:/me/ultraxxxxxxin/datasets/luosi/" # 改成自己的路径
print(img_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(img_path+'Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(img_path'labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out\_file.write(str(cls\_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image\_set in sets:
if not os.path.exists(img\_path+'labels/'):
os.makedirs(img\_path+'labels/')
image\_ids = open(img\_path+'ImageSets/Main/%s.txt' % (image\_set)).read().strip().split()
if not os.path.exists(img_path+'dataSet\_path/'):
os.makedirs(img_path+'dataSet\_path/')
list_file = open('dataSet\_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image\_id in image_ids:
list_file.write(img_path+'images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
然后运行:
(yolov5) PS G:\bsh\yolov5\yolov5-master\datavivoimg> python .\text_to_yolo.py
#如果运行成功,会输出如下代码:
G:\bsh\yolov5\yolov5-master\datavivoimg
然后去查看
labels里边的标签和dataset_path里的文件
3. yolov5训练得到模型文件
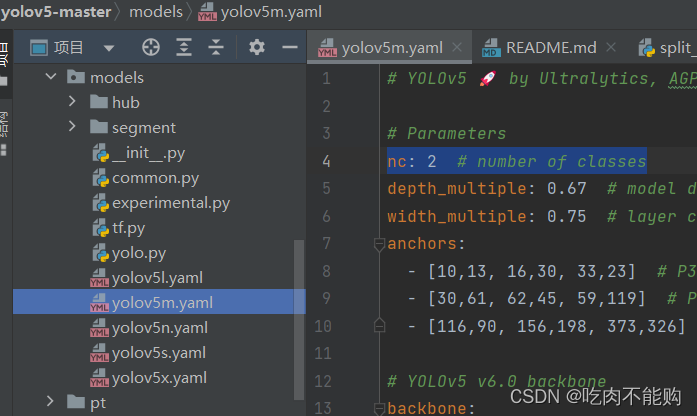
首先配置自己数据集的yaml文件:
在 yolov5 目录下的 data 文件夹下 新建一个 vivo.yaml文件(可以自定义命名),用记事本打开
内容如下,修改的时候注意空格问题,一定要严格按照格式来修改:
train: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/train.txt
val: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/val.txt
# number of classes
nc: 2
# class names
names: ["prince", "garfield"]
然后注意,不需要修改yolov5的配置文件(这里不需要修改,其实上边的vivo.yaml里修改了numclass之后会自动覆盖)

然后进行训练
python train.py --weights pt/yolov5m.pt --cfg models/yolov5m.yaml --data data/vivo.yaml --epoch 200 --batch-size 6 --img 640
按照我的参数,我笔记本的gpu 1060,大概1-2个小时,挺快的。
如果训练报错缺少库要自己改一改,
例如我缺少了git库就去conda install git,
而且pillow库版本9.3过高不匹配,我就修改到pip install pillow==8.0
因为我batchsize=8报错memory异常,所以调小到6,然后开始训练:
训练结果如下:
### 一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

### 二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

### 三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









