







train_model文件夹是用来存储模型的记录与参数的
2、生成.tfrecords文件的代码微调说明
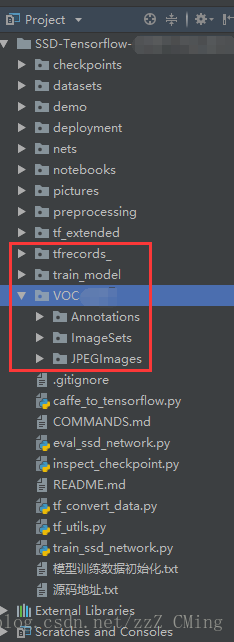
第三步:修改标签项——打开datasets文件夹中pascalvoc_common.py文件,将自己的标签项填入。我之前做的图片标签.xml文件中,就只有一个标签项“watch”,所以要根据你自己数据集实际情况进行修改;
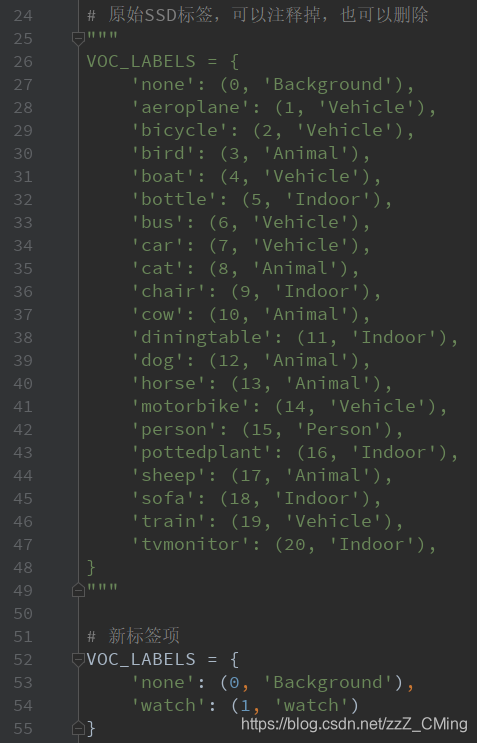
第四步:修改读取个数、读取方式——打开datasets文件夹中的pascalvoc_to_tfrecords.py文件,
- 修改67行
SAMPLES_PER_FILES的个数; - 修改83行读取方式为
'rb'; - 如果你的文件不是
.jpg格式,也可以修改图片的类型;
3、生成.tfrecords文件
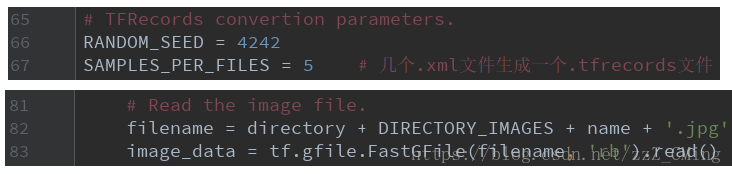
第五步:生成.tfrecords文件——打开tf_convert_data.py文件,依次点击:run、Edit Configuration,在Parameters中填入以下内容,再运行tf_convert_data.py文件,在面板中得到成功信息,可以在tfrecords_文件夹下看到生成的.tfrecords文件;
--dataset_name=pascalvoc
--dataset_dir=./VOC2007/
--output_name=voc_2007_train
--output_dir=./tfrecords_
4、重新训练模型的代码微调说明
第六步:修改训练数据shape——打开datasets文件夹中的pascalvoc_2007.py文件,
- 根据自己训练数据修改:
NUM_CLASSES= 类别数;
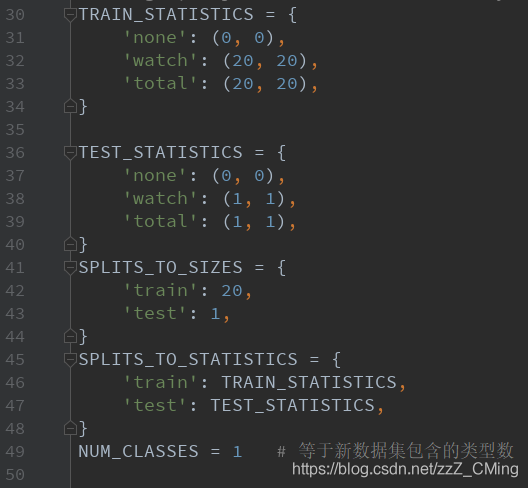
说明:TRAIN_STATISTICS的数值我并没有深入了解,大于新数据集该标签的总数一般都不会报错。我的数据集是由20张、每张包含一只手表的图片组成,所以下图的值我设定为20,大于20也没有报错,如果你有更精确的想法,请留言告诉大家!
第七步:修改类别个数——打开nets文件夹中的ssd_vgg_300.py文件,
- 根据自己训练类别数修改96 和97行:等于类别数+1;

第八步:修改类别个数——打开eval_ssd_network.py文件,
- 修改66行的类别个数:等于类别数+1;

第九步:修改训练步数epoch——打开train_ssd_network.py文件,
- 修改27行的数据格式,改为
'NHWC'; - 修改135行的类别个数:等于类别数+1;
- 修改154行训练总步数,
None会无限训练下去; - 说明:60行、63行是关于模型保存的参数;

5、加载vgg_16,重新训练模型
第十步:下载vgg_16模型——下载地址请点击,密码:ge3x;下载完成解压后存入checkpoint文件中;
最后一步:重新训练模型——打开train_ssd_network.py文件,依次点击:run、Edit Configuration,在Parameters中填入以下内容,再运行train_ssd_network.py文件
--train_dir=./train_model/
--dataset_dir=./tfrecords_/
--dataset_name=pascalvoc_2007
--dataset_split_name=train
--model_name=ssd_300_vgg
--checkpoint_path=./checkpoints/vgg_16.ckpt
--checkpoint_model_scope=vgg_16
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box
--save_summaries_secs=60
--save_interval_secs=100
--weight_decay=0.0005
--optimizer=adam
--learning_rate=0.001
--learning_rate_decay_factor=0.94
--batch_size=4
--gpu_memory_fraction=0.7
注意:上面是输入参数:
--save_interval_secs是训练多少次保存参数的步长;--optimizer是优化器;--learning_rate是学习率;--learning_rate_decay_factor是学习率衰减因子;- 如果你的机器比较强大,可以适当增大
--batch_size的数值,以及调高GPU的占比--gpu_memory_fraction --model_name:我并没有尝试使用其他的模型做增量训练,如果你有需要,也请留言联系我,我很乐意研究;
若得到下图日志,即说明模型开始训练:

训练结束可以在train_model文件夹下看到生成的参数文件;
到这里,训练终于结束了!!!
–-----------------------------------------------------------------------------—--------------------------------------------
–-----------------------------------------------------------------------------—--------------------------------------------
二、结果展示
这是我训练的loss,我的数据集总共就20张图片,进行4.8W次训练用了将近一个小时,我的配置是GTX1060的单显卡;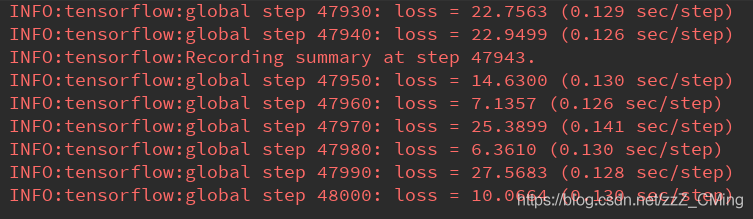
1、在日志中,选取最后一次生成模型作为测试模型进行测试;
2、在demo文件夹下放入测试图片;
3、最后在notebooks文件夹下建立demo_test.py测试文件,代码如下:
4、注意第48行,导入的新模型的名称是否正确;
# -\*- coding:utf-8 -\*-
# -\*- author:zzZ\_CMing CSDN address:https://blog.csdn.net/zzZ\_CMing
# -\*- 2018/07/20; 15:19
# -\*- python3.6
import os
import math
import random
import numpy as np
import tensorflow as tf
import cv2
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
from notebooks import visualization
import sys
sys.path.append('../')
slim = tf.contrib.slim
# TensorFlow session: grow memory when needed. TF, DO NOT USE ALL MY GPU MEMORY!!!
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
# 定义数据格式,设置占位符
net_shape = (300, 300)
# 输入图像的通道排列形式,'NHWC'表示 [batch\_size,height,width,channel]
data_format = 'NHWC'
# 预处理,以Tensorflow backend, 将输入图片大小改成 300x300,作为下一步输入
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
# 数据预处理,将img\_input输入的图像resize为300大小,labels\_pre,bboxes\_pre,bbox\_img待解析
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format, resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
# 拓展为4维变量用于输入
image_4d = tf.expand_dims(image_pre, 0)
# 定义SSD模型
# 是否复用,目前我们没有在训练所以为None
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)**

为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
[**一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!**](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)
**AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算**
!**](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)
**AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算**















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









