










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
"path": "/base_province",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
##### 2)配置说明
###### 1. Reader 参数说明

**注意:****这里的 splitPk 参数是数据分片字段,一般是主键,仅支持整型 ,而且只有 TableMode 模式下才有效**。
###### 2. Writer 参数说明

我们的 hdfswriter 中有一个 column 参数,但是我们知道 HDFS 是没有列的这个概念的。其实,这里代表的是我们Hive表中数据的字段类型,这个配置参数是给 Hive 看的。之后我们在使用 hdfsreader 的时候 依然要配置这个参数,这个参数的意义仍然是 hive 的数据字段。
**注意:****这里的 fileName 参数指的是 HDFS 前缀名而并不是完整文件名!**
###### 3)提交任务
使用DataX向HDFS同步数据时,必须确保目标路径已存在!
hadoop fs -mkdir /base_province
python bin/datax.py job/base_province.json
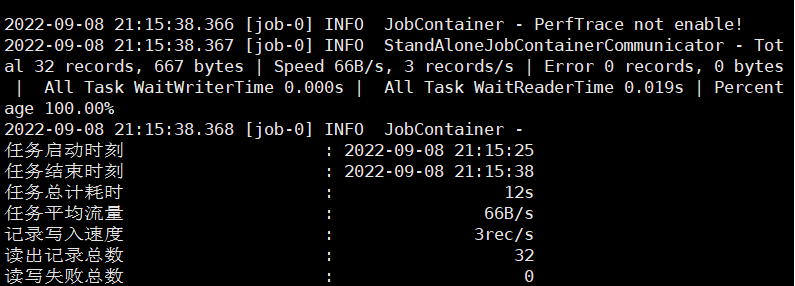
执行结果:

 可以看到,我们的文件名是由我们 hdfswriter 中指定的前缀 fileName + uuid 组成的。
查看HDFS 中的文件内容(因为我们的文件是经过 gzip 压缩的,所以网页端查看不了):
hadoop fs -cat /base_province/* | zcat

可以看到,MySQL 中 34 条数据一共写入了 32 条,这是因为我们设置了 where 参数的值为 id>=3
#### 4.1.2、MySQLReader & QuerySQLMode
###### 1)配置文件
{
“job”: {
“content”: [
{
“reader”: {
“name”: “mysqlreader”,
“parameter”: {
“connection”: [
{
“jdbcUrl”: [
“jdbc:mysql://hadoop102:3306/gmall”
],
“querySql”: [
“select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3”
]
}
],
“password”: “123456”,
“username”: “root”
}
},
“writer”: {
“name”: “hdfswriter”,
“parameter”: {
“column”: [
{
“name”: “id”,
“type”: “bigint”
},
{
“name”: “name”,
“type”: “string”
},
{
“name”: “region_id”,
“type”: “string”
},
{
“name”: “area_code”,
“type”: “string”
},
{
“name”: “iso_code”,
“type”: “string”
},
{
“name”: “iso_3166_2”,
“type”: “string”
}
],
“compress”: “gzip”,
“defaultFS”: “hdfs://hadoop102:8020”,
“fieldDelimiter”: “\t”,
“fileName”: “base_province”,
“fileType”: “text”,
“path”: “/base_province”,
“writeMode”: “append”
}
}
}
],
“setting”: {
“speed”: {
“channel”: 1
}
}
}
}
可以看到,TableMode 的 mysqlreader 中是通过在 connection 参数设置 table 参数的值来指定我们的表,而这里 QuerySQLMode 模式是通过 querySql 参数来指定 SQL ,从SQL中可以得到表名。此外,QuerySQLMode 模式没有 columns 和 where 参数,因为这些都可以在 SQL 中指定。
那 TableMode 和 QuerySQLMode 有什么区别呢?其实 QuerySQLMode 正因为它可以指定 SQL ,所以就更加灵活,我们可以使用复杂的 join 和聚合函数,这一点是 TableMode 所实现不了的。反过来,我们上面知道 TableMode 的配置文件中可以在 mysqlreader 中指定一个参数 splitPk 来开启多个 Task 去读取一张表,这一点同样是 QuerySQLMode 所不具备的,QuerySQLMode 只支持单个 Task。
QuerySQLMode 这种模式用的还是比较少的,毕竟我们的 Hive 也可以完成数据的聚合和联结。
此外,关于 hdfswriter 还有一些注意事项:
****注意事项:****
HFDS Writer并未提供nullFormat参数:也就是用户并不能自定义null值写到HFDS文件中的存储格式。默认情况下,HFDS Writer会将null值存储为空字符串(''),而Hive默认的null值存储格式为\N。所以后期将DataX同步的文件导入Hive表就会出现问题。
解决该问题的方案有两个:
一是修改DataX HDFS Writer的源码,增加自定义null值存储格式的逻辑(也就是如果读取到 null 就把它替换为 "\\N",双斜杠是因为 DataX 是 Java 写的),可参考[这里]( )。
二是在Hive中建表时指定null值存储格式为空字符串(''")
###### 2)配置文件说明
mysqlreader:

hdfswriter 和上面的是一样的。
###### 3)提交任务
结果和上面是一样的,这里不再演示。
#### 4.1.3、DataX 传参
通常情况下,离线数据同步任务需要每日定时重复执行(就像我们之前 flume 上传到 HDFS 也指定过),故HDFS上的目标路径通常会包含一层日期,以对每日同步的数据加以区分,也就是说每日同步数据的目标路径不是固定不变的,因此DataX配置文件中 HDFS Writer 的path参数的值应该是动态的。为实现这一效果,就需要使用DataX传参的功能。
##### 1)修改配置文件
DataX传参的用法如下,在JSON配置文件中使用${param}引用参数,在提交任务时使用-p"-Dparam=value"传入参数值,我们只需要修改 hdfswriter 下 parameter 参数下的 path 为:
“path”: “/base_province/${dt}”
##### 2)创建 hdfs 路径
hadoop fs -mkdir /base_province/2020-06-14
###### 3)提交任务
python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json
### 4.2、HDFS -> MySQL
****案例要求:****同步HDFS上的/base\_province目录下的数据到 MySQL gmall 数据库下的 test\_province表。
****需求分析:****要实现该功能,需选用 HDFSReader 和 MySQLWriter。
#### ****1)********编写配置文件****
vim test_province.json
{
“job”: {
“content”: [
{
“reader”: {
“name”: “hdfsreader”,
“parameter”: {
“defaultFS”: “hdfs://hadoop102:8020”,
“path”: “/base_province”,
“column”: [
“*”
],
“fileType”: “text”,
“compress”: “gzip”,
“encoding”: “UTF-8”,
“nullFormat”: “\N”,
“fieldDelimiter”: “\t”,
}
},
“writer”: {
“name”: “mysqlwriter”,
“parameter”: {
“username”: “root”,
“password”: “123456”,
“connection”: [
{
“table”: [
“test_province”
],
“jdbcUrl”: “jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8”
}
],
“column”: [
“id”,
“name”,
“region_id”,
“area_code”,
“iso_code”,
“iso_3166_2”
],
“writeMode”: “replace”
}
}
}
],
“setting”: {
“speed”: {
“channel”: 1
}
}
}
}
#### 2)配置说明
hdfsreader:

mysqlwriter:

其中 writeMode 的三种不同取值代表三种不同的 SQL 语句,其中 replace 和 on duplicate key update 都要求我们的 MySQL 表是有主键的。我们经常使用的 insert 语句是不需要主键的,所以当有主键重复的时候会直接报错。而 replace 语句如果遇到表中已经存在该主键的数据会直接替换掉, on duplicate key update 语句的话如果遇到表中已经存在该主键的数据会更新不同值的字段。
#### 3)提交任务
创建 HDFS 输出端 MySQL 的表:
DROP TABLE IF EXISTS test_province;
CREATE TABLE test_province (
id bigint(20) NOT NULL,
name varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
region_id varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
area_code varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
iso_code varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
iso_3166_2 varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
提交任务:
bin/datax.py job/test_province.json
#### 4)查看结果
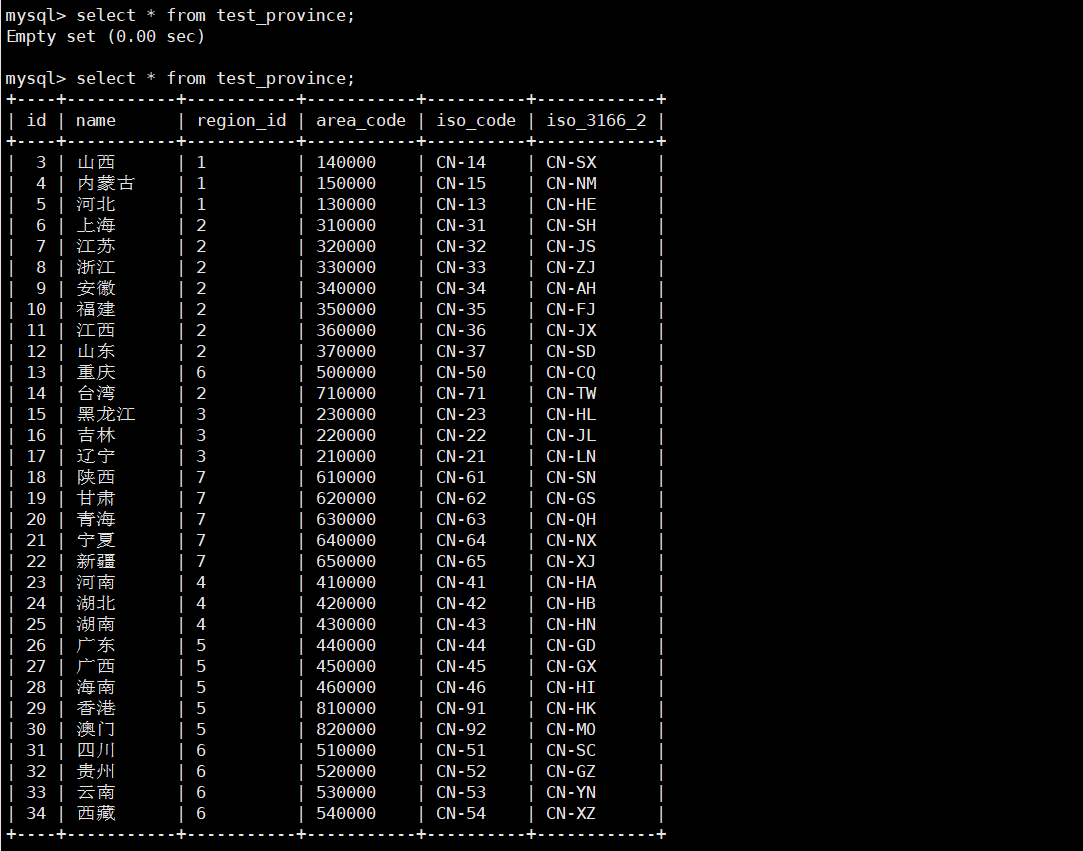
## 5、DataX 优化
上面 DataX 的任务配置文件中,job 下有两个参数 content 和 setting,content 是配置 reader 和 writer 的,而 setting 其实就是来给 DataX 优化用的(通过控制流量、并发)。
### 5.1、速度控制
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在数据库可以承受的范围内达到最佳的同步速度。
关键优化参数如下:
| | |
| --- | --- |
| ****参数**** | ****说明**** |
| ****job.setting.speed.channel**** | 并发数 |
| ****job.setting.speed.record**** | 总 record 限速(tps:条数/s) |
| ****job.setting.speed.byte**** | 总 byte 限速(bps:字节数/s) |
| ****core.transport.channel.speed.record**** | 单个 channel 的record限速,默认值为10000(10000条/s) |
| ****core.transport.channel.speed.byte**** | 单个channel的byte限速,默认值1024\*1024(1M/s) |
****注意事项:****
1. 若配置了总 record 限速,则必须配置单个 channel 的 record 限速
2. 若配置了总 byte 限速,则必须配置单个 channe 的 byte 限速
3. 若配置了总 record 限速和总 byte 限速,channel 并发数参数就会失效。因为配置了总record限速和总 byte 限速之后,实际 channel 并发数是通过计算得到的:
****计算公式为:****
min(总byte限速/单个channel的byte限速,总record限速/单个 channel 的record限速)
****配置示例:****



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
,实际 channel 并发数是通过计算得到的:
****计算公式为:****
min(总byte限速/单个channel的byte限速,总record限速/单个 channel 的record限速)
****配置示例:****
[外链图片转存中...(img-CFpAtZSt-1715629590142)]
[外链图片转存中...(img-jLStaVwN-1715629590142)]
[外链图片转存中...(img-idv29jYk-1715629590142)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









