







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
EC纠删码、多NameNode支持
+ Hadoop MapReduce
任务本地化优化、内存参数自动推断
+ Hadoop YARN
Timeline Service V2、队列配置
2、Apache Hadoop集群搭建
Hadoop集群整体概述
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群

Hadoop集群简介
- 逻辑上分离
两个集群互相之间没有依赖、互不影响
- 物理上在一起
某些角色进程往往部署在同一台物理服务器上
- MapReduce集群呢?
MapReduce是计算框架、代码层面的组件没有集群之说
Hadoop集群搭建(Hadoop集群分布式安装)
-
Step1:集群角色规划
- 角色规划的准则根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上?
+ 角色规划注意事项资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
| 服务器 | 运行角色 |
|---|---|
| node1 | namenode datanode resourcemanager nodemanager |
| node2 | secondarynamenode datanode nodemanager |
| node3 | atanode nodemanager |
- Step2:服务器基础环境准备
主机名(3台机器) vim /etc/hostname
node1
node2
node3
设置静态IP
+ `node1:`
`UUID="08d531cc-32bb-4c25-b146-566ad30307af"`
`IPADDR="192.168.88.131"`
+ `node2:`
`UUID="08d531cc-32bb-4c25-b147-566ad30307af"`
`IPADDR="192.168.88.132"`
+ `node3:`
`UUID="08d531cc-32bb-4c25-b148-566ad30307af"`
`IPADDR="192.168.88.133"`Hosts映射(3台机器) `vim /etc/hosts`
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3
防火墙关闭(3台机器)
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙开启自启
ssh免密登录(node1执行->node1|node2|node3)
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com
创建统一工作目录(3台机器)
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径
- Step3:上传安装包、解压安装包
- Step4:Hadoop安装包目录结构
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
配置文件概述
+ 官网文档:https://hadoop.apache.org/docs/r3.3.0/
+ 第一类1个:hadoop-env.sh
+ 第二类4个:
xxxx-site.xml ,site表示的是用户定义的配置,会覆盖default中的默认配置。
core-site.xml 核心模块配置 hdfs-site.xml hdfs文件系统模块配置
mapred-site.xml MapReduce模块配置
yarn-site.xml yarn模块配置
+ 第三类1个:workers
+ 所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
-
修改配置文件(配置文件路径 hadoop-3.3.0/etc/hadoop)
- hadoop-env.sh
#文件最后添加 export JAVA\_HOME=/export/server/jdk1.8.0_241 export HDFS\_NAMENODE\_USER=root export HDFS\_DATANODE\_USER=root export HDFS\_SECONDARYNAMENODE\_USER=root export YARN\_RESOURCEMANAGER\_USER=root export YARN\_NODEMANAGER\_USER=root- core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 文件系统垃圾桶保存时间 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property>- hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property>- mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- MR程序历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>- yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 历史日志保存的时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>- workers
node1 node2 node3 -
分发同步hadoop安装包
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
- 将hadoop添加到环境变量(3台机器)
vim /etc/profile
export HADOOP\_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP\_HOME/bin:$HADOOP\_HOME/sbin
source /etc/profile
#别忘了scp给其他两台机器哦
-
Hadoop集群启动
- (首次启动)格式化namenode
hdfs namenode -format- 脚本一键启动
[root@node1 ~]# start-dfs.sh Starting namenodes on [node1] Last login: Thu Nov 5 10:44:10 CST 2020 on pts/0 Starting datanodes Last login: Thu Nov 5 10:45:02 CST 2020 on pts/0 Starting secondary namenodes [node2] Last login: Thu Nov 5 10:45:04 CST 2020 on pts/0 [root@node1 ~]# start-yarn.sh Starting resourcemanager Last login: Thu Nov 5 10:45:08 CST 2020 on pts/0 Starting nodemanagers Last login: Thu Nov 5 10:45:44 CST 2020 on pts/0-
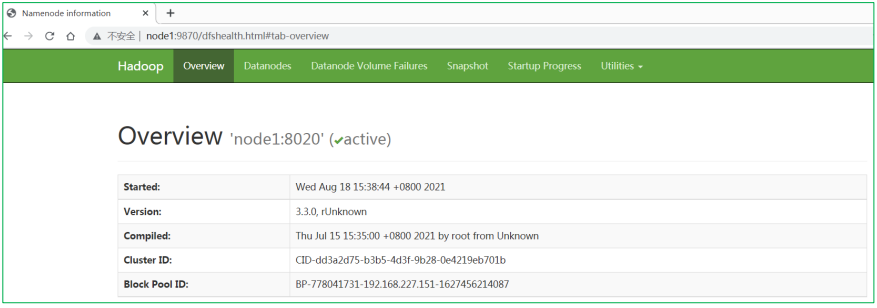
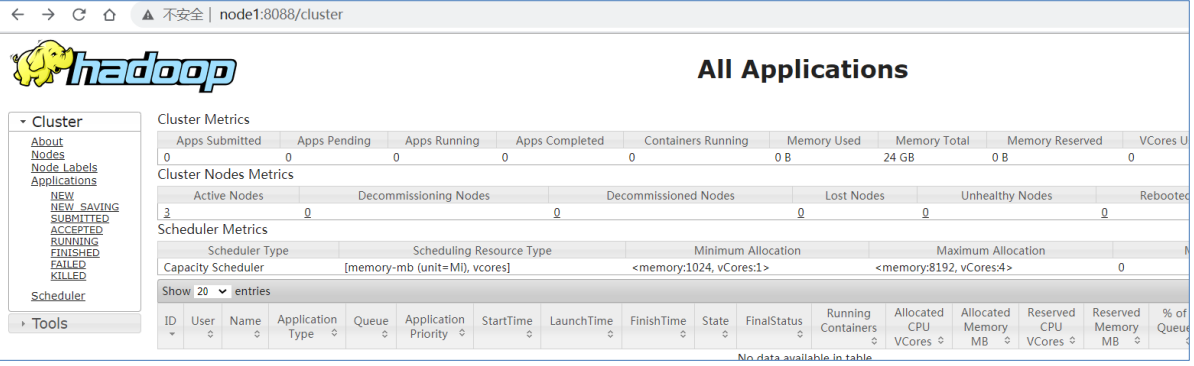
Web UI页面
- HDFS集群:http://node1:9870/
- YARN集群:http://node1:8088/
-
错误1:运行hadoop3官方自带mr示例出错。
- 错误信息
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property>- 解决 mapred-site.xml,增加以下配置
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
Hadoop集群启停
- 每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。
- HDFS集群
#hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenode
- YARN集群
#hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
#hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager
shell脚本一键启停
- 在node1上,使用软件自带的shell脚本一键启动。前提:配置好机器之间的SSH免密登录和workers文件。
- HDFS集群 start-dfs.sh stop-dfs.sh
- YARN集群 start-yarn.sh stop-yarn.sh
- Hadoop集群 start-all.sh stop-all.sh
HDFS集群
- 地址:http://namenode_host:9870 其中namenode_host是namenode运行所在机器的主机名或者ip 如果使用主机名访问,别忘了在Windows配置hosts
YARN集群
- 地址:http://resourcemanager_host:8088 其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip 如果使用主机名访问,别忘了在Windows配置hosts
3、HDFS分布式文件系统基础
文件系统定义
- 文件系统 是一种 存储 和 组织数据 的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户 对文件访问和查找变得容易;
- 文件系统使用 树形目录 的抽象逻辑概念代替了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘哪里,只需要记住这个文件的所属目录和文件名即可;
- 文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。
传统常见的文件系统
- 所谓 传统 常见的文件系统更多指的的单机的文件系统,也就是底层不会横跨多台机器实现。比如windows操作系统上的文件系统、Linux上的文件系统、FTP文件系统等等。
- 这些文件系统的共同特征包括:
- 带有抽象的目录树结构,树都是从/根目录开始往下蔓延;
- 树中节点分为两类:目录和文件 ;
- 从根目录开始,节点路径具有唯一性。
数据、元数据
- 数据
指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。 - 元数据
元数据(metadata)又称之为解释性数据,记录数据的数据;
文件系统元数据一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。
海量数据存储遇到的问题
- 成本高
传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高。 - 如何支撑高效率的计算分析
传统存储方式意味着数据:存储是存储,计算是计算,当需要处理数据的时候把数据移动过来。
程序和数据存储是属于不同的技术厂商实现,无法有机统一整合在一起。 - 性能低
单节点I/O性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景。 - 可扩展性差
无法实现快速部署和弹性扩展,动态扩容、缩容成本高,技术实现难度大。
一、分布式存储的优点
问题:数据量大,单机存储遇到瓶颈
解决:
单机纵向扩展:磁盘不够加磁盘,有上限瓶颈限制
多机横向扩展:机器不够加机器,理论上无限扩展
二、元数据记录的功能
问题:文件分布在不同机器上不利于寻找
解决:元数据记录下文件及其存储位置信息,快速定位文件位置
三、分块存储好处
问题:文件过大导致单机存不下、上传下载效率低
解决:文件分块存储在不同机器,针对块并行操作提高效率
四:副本机制的作用
问题:硬件故障难以避免,数据易丢失
解决:不同机器设置备份,冗余存储,保障数据安全
HDFS简介
- HDFS(Hadoop Distributed File System ),意为: Hadoop分布式文件系统 。是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据的存储问题。
- HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据(比如TB 和PB)。
- HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
HDFS设计目标
- 硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此 故障检测和自动快速恢复 是HDFS的核心架构目标。
- HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成 用于批处理 ,而不是用户交互式的。相较于数据访问的反应时间,更 注重数据访问的高吞吐量 。
- 典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成 支持大文件(Large Data Sets) 。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
- 大部分HDFS应用对文件要求的是 write-one-read-many 访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
- 移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
- HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。
HDFS应用场景
适合场景
大文件
数据流式访问
一次写入多次读取
低成本部署,廉价PC
高容错

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
- 移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
- HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。
HDFS应用场景
适合场景
大文件
数据流式访问
一次写入多次读取
低成本部署,廉价PC
高容错
[外链图片转存中…(img-3K4NAIN8-1715232672628)]
[外链图片转存中…(img-AuobkuKT-1715232672628)]
[外链图片转存中…(img-2oLbAEry-1715232672628)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 6434
6434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









