







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

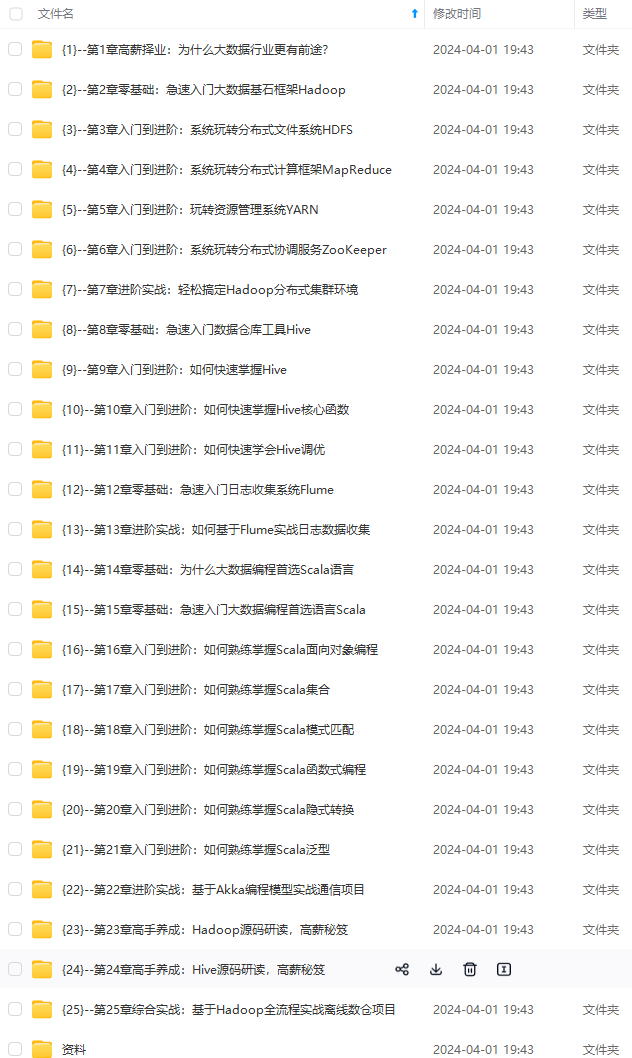
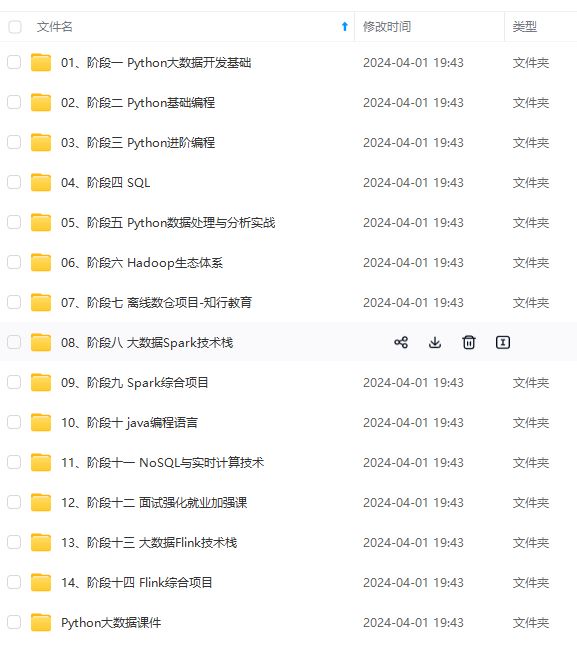


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
…
,
n
1, 2, 3, \ldots , n
1,2,3,…,n 的一个 MM 的信息。每行表示一个 MM 的信息,有三个整数:
r
m
b
rmb
rmb,
r
p
rp
rp 和
t
i
m
e
time
time。
最后一行有两个整数,分别为
m
m
m 和
r
r
r。
输出格式
你只需要输出一行,其中有一个整数,表示 sqybi 在保证 MM 数量的情况下花费的最少总时间是多少。
样例 #1
样例输入 #1
4
1 2 5
2 1 6
2 2 2
2 2 3
5 5
样例输出 #1
13
提示
sqybi 说:如果题目里说的都是真的就好了…
sqybi 还说,如果他没有能力泡到任何一个 MM,那么他就不消耗时间了(也就是消耗的时间为
0
0
0),他要用这些时间出七夕比赛的题来攒 rp…
【数据规模】
对于
20
%
20 %
20% 的数据,
1
≤
n
≤
10
1 \le n \le 10
1≤n≤10;
对于
100
%
100 %
100% 的数据,
1
≤
r
m
b
≤
100
1 \le rmb \le 100
1≤rmb≤100,
1
≤
r
p
≤
100
1 \le rp \le 100
1≤rp≤100,
1
≤
t
i
m
e
≤
1000
1 \le time \le 1000
1≤time≤1000。
对于
100
%
100 %
100% 的数据,
1
≤
m
,
r
,
n
≤
100
1 \le m, r, n \le 100
1≤m,r,n≤100。
解题思路
- 1)二维01背包.
- 2)注意人数的重要性大于时间。
参考代码
#include<bits/stdc++.h>
using namespace std;
int dp[105][105],times[105][105];
int main()
{
int n,m,r;
int rmb[105],rp[105],time[105];
cin>>n;
for(int i=1;i<=n;i++)
cin>>rmb[i]>>rp[i]>>time[i];
cin>>m>>r;
for(int i=1;i<=n;i++)
{
for(int j=m;j>=rmb[i];j--)
{
for(int k=r;k>=rp[i];k--)
{
if(dp[j][k]<dp[j-rmb[i]][k-rp[i]]+1)
{
dp[j][k]=dp[j-rmb[i]][k-rp[i]]+1;
times[j][k]=times[j-rmb[i]][k-rp[i]]+time[i];
}
if(dp[j][k]==dp[j-rmb[i]][k-rp[i]]+1&×[j][k]>times[j-rmb[i]][k-rp[i]]+time[i])
{
times[j][k]=times[j-rmb[i]][k-rp[i]]+time[i];
}
}
}
}
cout<<times[m][r];
return 0;
}
第二题 [NOIP2001 普及组] 求先序排列
题目描述
给出一棵二叉树的中序与后序排列。求出它的先序排列。(约定树结点用不同的大写字母表示,且二叉树的节点个数 $ \le 8$)。
输入格式
共两行,均为大写字母组成的字符串,表示一棵二叉树的中序与后序排列。
输出格式
共一行一个字符串,表示一棵二叉树的先序。
样例 #1
样例输入 #1
BADC
BDCA
样例输出 #1
ABCD
解题思路
- 1)后序遍历中,最后一个节点一定是根节点。
- 2)递归将一棵树分成两颗子树,找到他们的父节点,不断递归输出。
参考代码
#include<bits/stdc++.h>
using namespace std;
string mid, aft;
void dfs(int ml, int mr, int al, int ar)
{
if (ml > mr || al > ar)
return;
printf("%c", aft[ar]);
for (int k = ml; k <= mr; k++)
{
if (mid[k] == aft[ar])
{
dfs(ml, k-1, al, al+k-ml-1);
dfs(k+1, mr, al+k-ml, ar-1);
break;
}
}
}
int main(void)
{
cin>>mid>>aft;
int len = mid.size()-1;
dfs(0, len, 0, len);
return 0;
}
第三题 取数游戏
题目描述
一个
N
×
M
N \times M
N×M的由非负整数构成的数字矩阵,你需要在其中取出若干个数字,使得取出的任意两个数字不相邻(若一个数字在另外一个数字相邻
8
8
8个格子中的一个即认为这两个数字相邻),求取出数字和最大是多少。
输入格式
第1行有一个正整数
T
T
T,表示了有
T
T
T组数据。
对于每一组数据,第一行有两个正整数
N
N
N和
M
M
M,表示了数字矩阵为
N
N
N行
M
M
M列。
接下来
N
N
N行,每行
M
M
M个非负整数,描述了这个数字矩阵。
输出格式
T
T
T行,每行一个非负整数,输出所求得的答案。
样例 #1
样例输入 #1
3
4 4
67 75 63 10
29 29 92 14
21 68 71 56
8 67 91 25
2 3
87 70 85
10 3 17
3 3
1 1 1
1 99 1
1 1 1
样例输出 #1
271
172
99
提示
对于第1组数据,取数方式如下:
[67] 75 63 10
29 29 [92] 14
[21] 68 71 56
8 67 [91] 25
对于
20
%
20%
20%的数据,
N
,
M
≤
3
N, M≤3
N,M≤3;
对于
40
%
40%
40%的数据,
N
,
M
≤
4
N,M≤4
N,M≤4;
对于
60
%
60%
60%的数据,
N
,
M
≤
5
N, M≤5
N,M≤5;
对于
100
%
100%
100%的数据,
N
,
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
8 71 56
8 67 [91] 25
对于
20
%
20%
20%的数据,
N
,
M
≤
3
N, M≤3
N,M≤3;
对于
40
%
40%
40%的数据,
N
,
M
≤
4
N,M≤4
N,M≤4;
对于
60
%
60%
60%的数据,
N
,
M
≤
5
N, M≤5
N,M≤5;
对于
100
%
100%
100%的数据,
N
,
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-oGHDnLq8-1713339153689)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









