







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
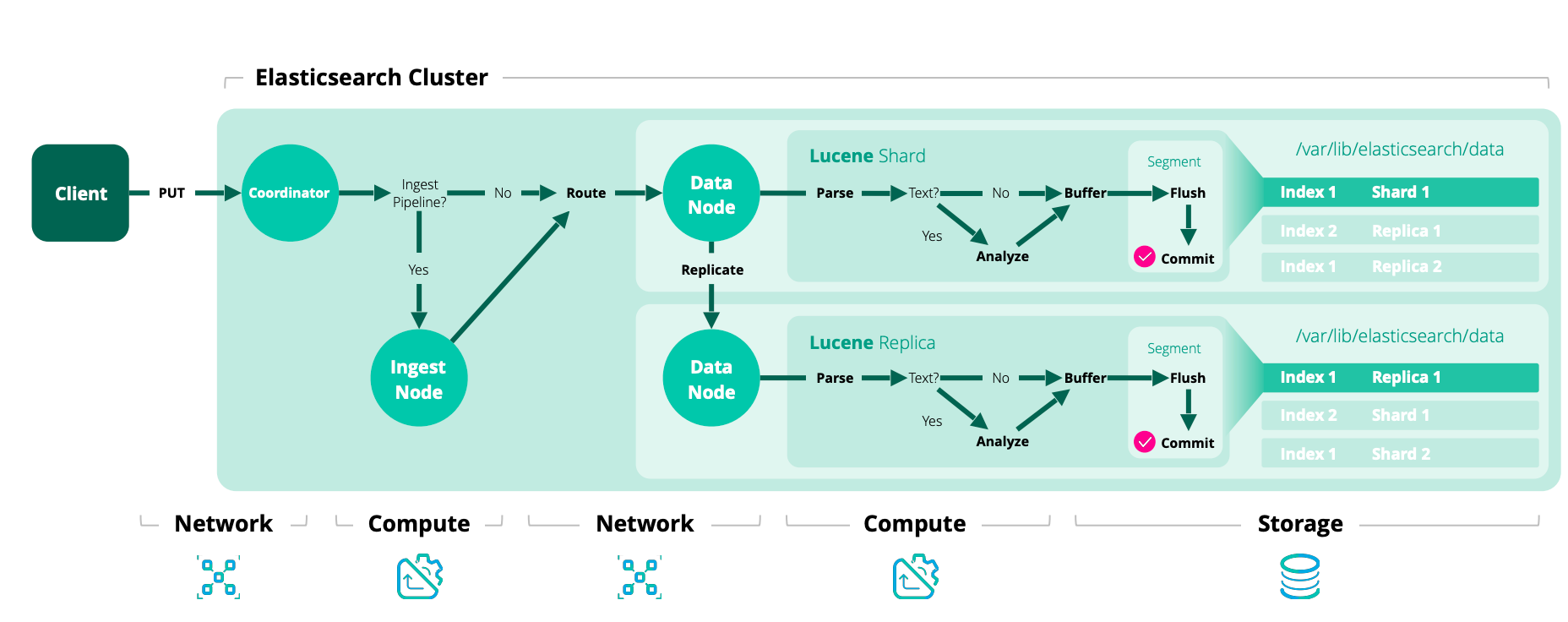
第一步、写入文档到内存缓冲区(此时文档不可被检索)。

第二步、缓冲区的内容写入到 segment,但是还未提交(可被检索)。

在 Elasticsearch 中,写入和打开一个新segment的过程称为 refresh,refresh操作会自上次刷新(refresh)以来执行的所有操作都可用搜索。
refresh触发的方式有如下三种:
1、刷新间隔到了自动刷新。
2、URL增加?refresh参数,需要传空或者true。
3、调用Refresh API手动刷新
默认情况下,Elasticsearch 每秒定期刷新,但是仅限于在过去的30s内收到的一个或者多个 search请求。这个也就是近实时的一个点,文档的更改不会立即显示在下一次的检索中,需要等待 refresh 操作完成之后才可以检索出来。
我们可以通过如下方式触发refresh操作或者调整自动刷新的间隔。
POST /_refresh
POST /blogs/_refresh
调整刷新间隔,每 30s 刷新
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
关闭自动刷新
PUT /my_logs/_settings
{ "refresh_interval": -1 }
设置为每秒自动刷新
PUT /my_logs/_settings
{ "refresh_interval": "1s"
refresh_interval需要一个 持续时间 值, 例如1s(1 秒) 或2m(2 分钟)。 一个绝对值1表示的是1毫秒--无疑会使你的集群陷入瘫痪。
段(segment)合并
由于 refresh 操作会每秒自动刷新生成一个新的段(segment),这样的话短时间内,segment会暴增,segment数量太多,每一个都会造成文件句柄、内存、CPU的大量消耗,还有一个更重要的点就是,每个检索请求也会轮流检查每一个segment,所以segment越多,检索也就越慢。
Elasticsearch 通过在后台自动合并 segment 来解决这个问题的。小的segment被合并到大的segment,然后大的segment在被合并到更大的segment。

segment 合并的时候会自动将已删除的文档从文件系统中删除,已经删除的文档或者更新文档的旧版本不会被合并到新的 segment中。

1、当 index 的时候,refresh操作会创建新的segment,并将segment打开以供检索。
2、合并进行会选择一小部分大小相似的segment,在后台将他们合并到更大的segment中,这个操作不会中断 index 与 search 操作。
optimize API
optimize API不应该用在经常更新的索引上
该 optimize API 可以控制分片最大的 segment数量,对于有的索引,例如日志,每天、每周、每月的日志被单独存在一个索引上,老得索引一般都是只读的,也不太可能发生变化,所以我们就可以使用这个 optimize API 优化老的索引,将每个分片合并为一个单独的segment。这样既可以节省资源,也可以加快检索速度。
- 合并索引中的每个分片为一个单独的段
POST /logstash-2014-10/_optimize?max_num_segments=1
持久化
上述的refresh操作是 Elasticsearch 近实时 的原因,那么数据的持久化就要看fsync操作把数据从文件系统缓冲区flush到磁盘了。所以只有当translog被fsync操作或者是提交时,translog中的数据才会持久化到磁盘。
如果没有持久化操作,当 Elasticsearch 宕机发生故障的时候,就会发生数据丢失了,所以 Elasticsearch 依赖于translog进行数据恢复。
在 Elasticsearch 进行提交操作的时候,成本是非常高的,所以策略就是在写入到内存缓冲区的时候,同步写入一份数据到translog,所有的index与delete操作都会在内部的lucene索引处理后且未确认提交之前写入teanslog。
如果发生了异常,当分片数据恢复时,已经确认提交但是并没有被上次lucene提交操作包含在内的最近操作就可以在translog中进行恢复。
Elasticsearch 的 flush操作是执行 Lucene提交并开始生成新的translog的过程,为了确保translog文件不能过大,flush操作在后台自动执行,否则在恢复的时候也会因为文件过大花费大量的时间。
对于translog有如下设置选项:
index.translog.durability默认设置为request,意思就是只有当主分片和副本分片fsync且提交translog之后,才会向客户端响应index,delete,update,bulk请求成功。index.translog.durability设置为async,则 Elasticsearch 会在每个index.translog.sync_interval提交translog,如果遇到节点恢复,则在这个区间执行的操作就可能丢失。
对于上述的几个参数,都可以动态更新
index.translog.sync_interval
将 translog fsync到磁盘并提交的频率。默认5s,不允许小于100ms。
index.translog.durability
是否在每次index,delete,update,bulk操作之后提交translog。
request: 默认,fsync 每次请求之后提交,如果发生故障,所有已确认的写入操作到已经提交到磁盘
async: fsync在后台每个sync_interval时间间隔提交。如果发生故障,自上次提交以来所有已确认的写入操作将被丢弃。
index.translog.flush_threshold_size
防止 translog 文件过大的设置,一旦达到设置的该值,就会发生 flush 操作,并生成一个新的 commit point。默认512mb。
总结
1、一个文档被index之后,添加内存缓存区,同时写入 translog。

2、refresh 操作完成后,缓存被清空,但是 translog 不会
- 内存缓冲区的文档被写入到一个新的
segment中,且没有进行fsync操作。 segment打开,可供检索。- 内存缓冲区清空。

3、更多的文档被添加到内存缓冲区并追加到 translog。

4、每隔一段时间,translog 变得越来越大,索引被刷新(flush),一个新的 translog 被创建,并且一个提交执行。
- 所有内存缓冲区的文档都被写入到一个新的段。
- 缓冲区被清空。
- 一个提交点写入磁盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的
translog被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化记录。当 Elasticsearch 启动的时候,它会从磁盘中使用的最后一个提交点(commit point)去恢复已知的 segment ,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时的CRUD,当我们通过ID进行查询、更新、删除一个文档、它会尝试在相应的 segment 中检索之前,首先检查 translog 中任何最近的变更操作。也就是说这个是可以实时获取到文档的最新版本。

最后送上一个我自己理解的图,参考了官网的描述,以及网上画的,如有错误欢迎指出。
如果感觉写的还不错,对你有帮助,欢迎点赞、转发、收藏,也可以评论互相交流。
也可以去搜索《醉鱼Java》点个关注,一起学习进步。

参考
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/mapping-routing-field.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/indices-create-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/images/data_processing_flow.png
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
essing_flow.png>
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-iomKsF8r-1713198771292)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}