







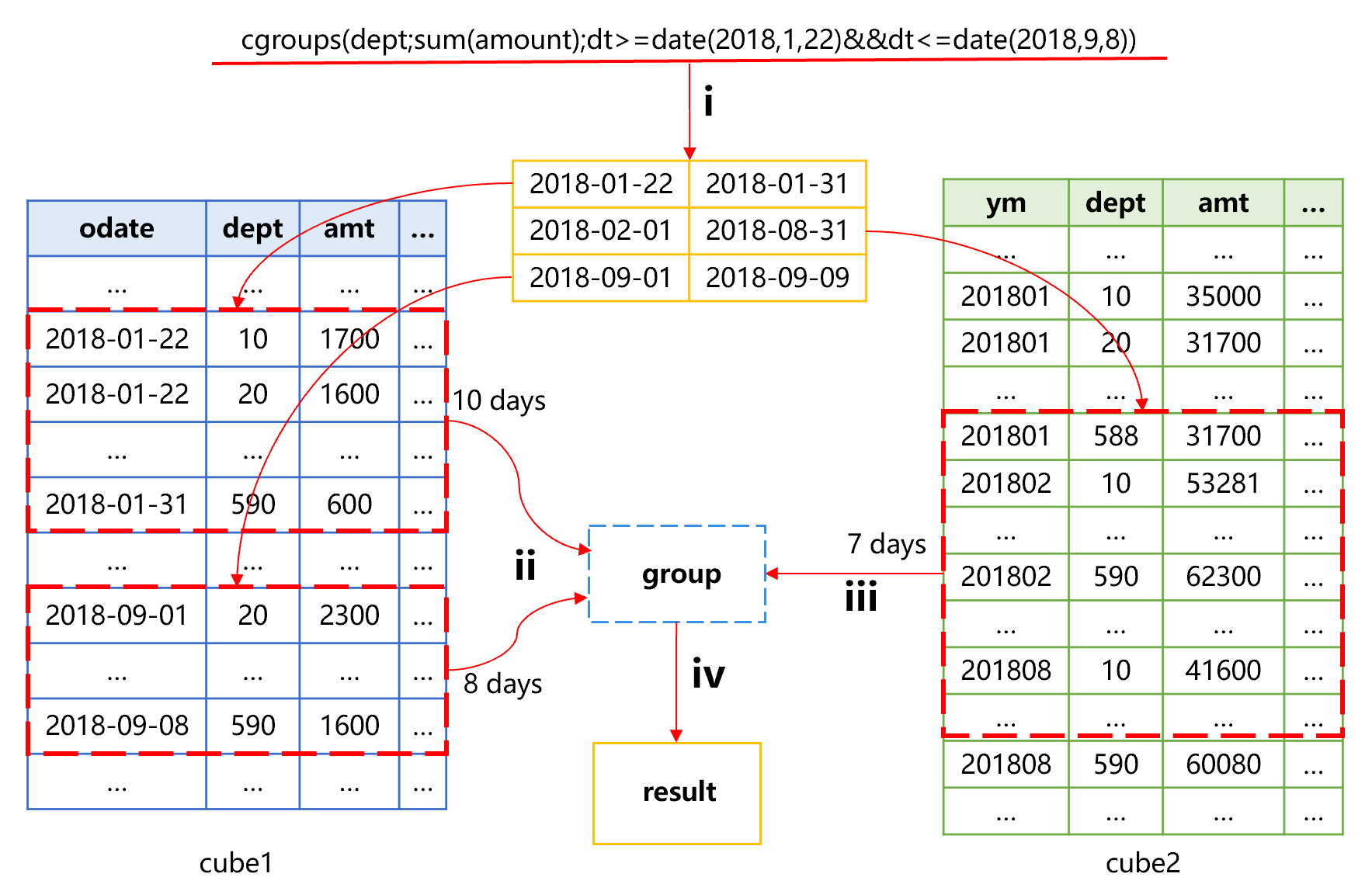
将时间段分成三段,2月到8月整月的数据基于月汇总cube2计算聚合值,再使用cube1计算 1 月 22 日到 1 月 31 日和 9 月 1 日到 9 月 8 日的聚合值,涉及的计算量是 7(2 月 -8 月)+10(1 月 22 日 -1 月 31 日)+8(9 月 1 日 -9 月 8 日)=25,而如果使用cube1数据聚合,其计算量是 223(从 1 月 22 日到 9 月 8 日的天数),几乎减少了 10 倍。
SPL代码示例:
| A | |
| 1 | =file(“orders.ctx”).open() |
| 2 | =A1.cuboid(cube1,odate,dept;sum(amt)) |
| 3 | =A1.cuboid(cube2,month@y(odate),dept;sum(amt)) |
| 4 | =A1.cgroups(dept;sum(amt);odate>=date(2018,1,22)&&dt<=date(2018,9,8)) |
cgroups 函数增加了条件参数,SPL 发现有时间段条件和更高层次的预汇总数据,则会使用时间段预汇总机制来减少运算量。本例中,就会分别从 cube1 和 cube2 中读取相应数据再来汇总。
SPL硬遍历
预汇总能够应对的场景仍然很有限,要做出灵活的多维分析,还是要指望过硬的遍历能力。多维分析运算本身并不算复杂,遍历计算主要是针对维度的过滤。传统数据库只能用WHERE硬算,维度相关的过滤也当作常规运算,不能获得较好的性能。SPL提供了多种维度过滤机制,可以满足各类多维分析场景的性能要求。
布尔维序列
多维分析中最常见的切片(切块)是针对枚举维度进行的,除了时间维度几乎都是枚举维度,如产品、地区、类型等。常规处理方式用SQL表达大概这样:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









