






在[部署好ollama之后],我们再来介绍ollama的一些其他用法。
一、修改环境变量
1.1 配置远程访问
在我们本地部署好ollama之后,仅支持本机访问,我们可以通过修改环境变量让其他人可以远程访问。
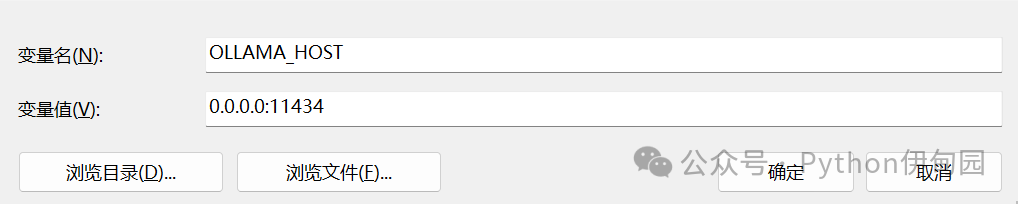
在wins电脑上增加环境变量:
OLLAMA_HOST 0.0.0.0:11434
1.2 配置本地模型路径
1.2.1 本地模型默认路径
wins本地模型默认路径:C:\Users\%username%\.ollama\models。
这里 %username% 是当前登录的用户名。例如,如果用户名为 Smqnz,则模型文件的默认存储路径可能是 C:\Users\Smqnz\.ollama\models。
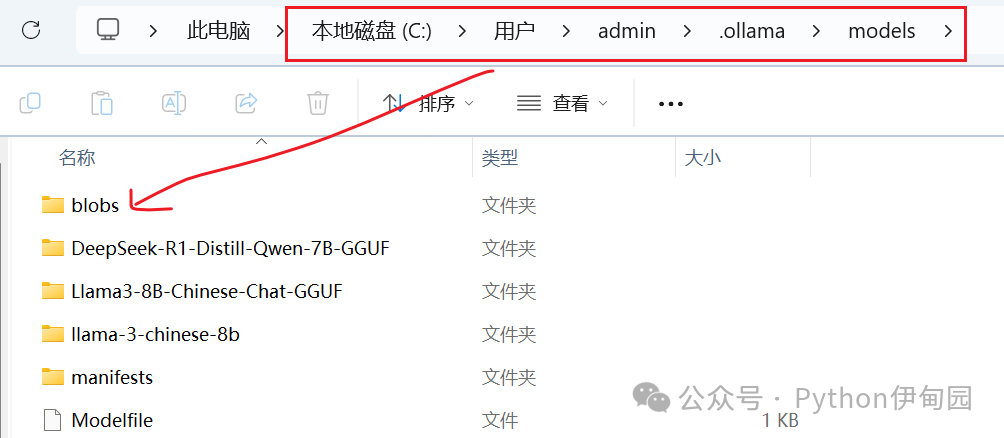
以我的电脑为例:
C:\Users\admin\.ollama\models
1.2.2 修改本地模型默认路径
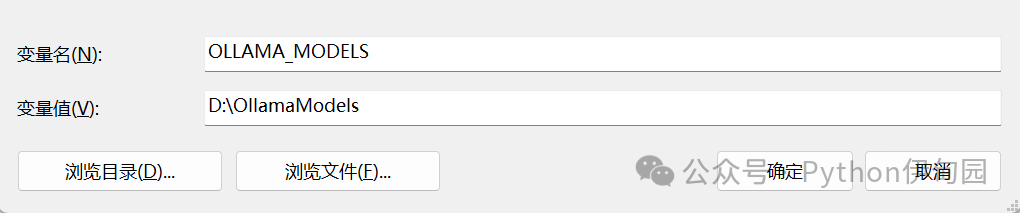
wins上的环境变量增加:
OLLAMA_MODELS 你想要存放的路径
以下为修改示例:
修改后,重启ollama即可。
1.3 配置允许的http请求来源
OLLAMA_ORIGINS 是 Ollama 中用于配置跨域资源共享(CORS)的环境变量,可以指定哪些来源(域名、IP 地址等)可以访问 Ollama 提供的 API 服务。
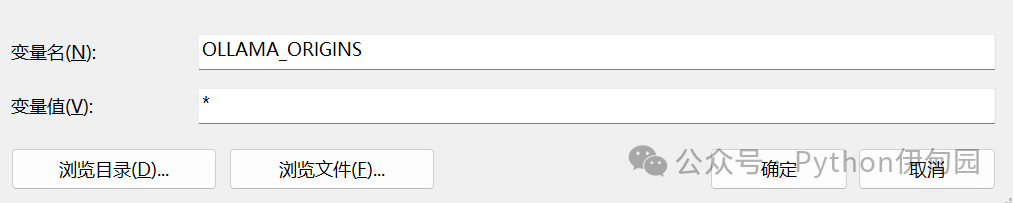
如果我们想让它接收任何来源(IP)的http请求的话,我们需要将其设置为*。
OLLAMA_ORIGINS *
这里一定要注意,以上修改的环境变量名称必须为大写,不要随意修改。
二、ollama常用API请求
一般来说,我们可以通过打开命令行窗口直接进行对话。
但是这种方式对于开发者来说并不实用,一般我们需要通过其API进行访问与开发,本次我们就来详细聊一下ollama常见的API。
2.1 文本生成API
Ollama 提供了一套功能丰富的文本生成接口,方便用户与本地部署的模型进行交互,以下是其主要的文本生成接口及功能介绍:
接口路径:POST /api/generate
功能:向模型发送提示(prompt),生成文本回复。
请求参数:
model:模型名称,如 “deepseek-r1:7b”。
prompt:输入的提示文本。
stream:是否启用流式输出,默认为 false。
options:可选参数,包括:
temperature:控制生成文本的多样性,取值范围通常为 0 到 1。
max\_tokens:最大生成的 token 数量。
top\_p:Top-p 采样参数。
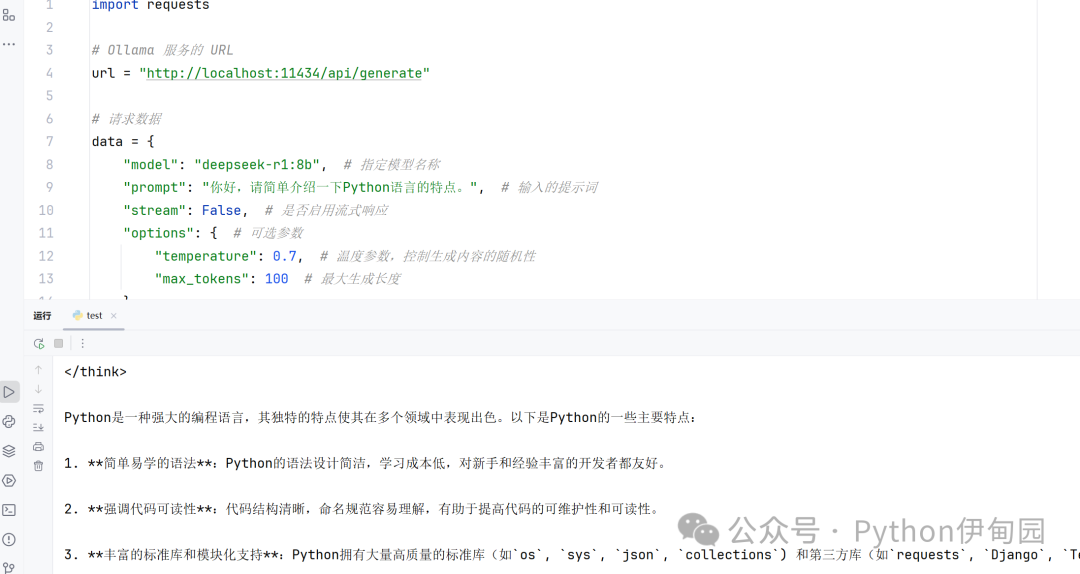
import requests`` ``# Ollama 服务的 URL``url = "http://localhost:11434/api/generate"`` ``# 请求数据``data = {` `"model": "deepseek-r1:8b", # 指定模型名称` `"prompt": "你好,请简单介绍一下Python语言的特点。", # 输入的提示词` `"stream": False, # 是否启用流式响应` `"options": { # 可选参数` `"temperature": 0.7, # 温度参数,控制生成内容的随机性` `"max_tokens": 100 # 最大生成长度` `}``}`` ``# 发送 POST 请求``response = requests.post(url, json=data)`` ``# 检查响应状态``if response.status_code == 200:` `result = response.json()` `print("生成的文本:", result.get("response"))``else:` `print("请求失败,状态码:", response.status_code)` `print("错误信息:", response.text)
2.2 对话聊天API
接口路径:POST /api/chat
功能:支持多轮对话,模型会记住上下文。
请求参数:
model:模型名称。
messages:消息列表,包含用户输入和模型回复,格式为 {“role”: “user”, “content”: “用户输入内容”}。
stream:是否启用流式输出,默认为 false。
options:可选参数,与生成文本接口类似。
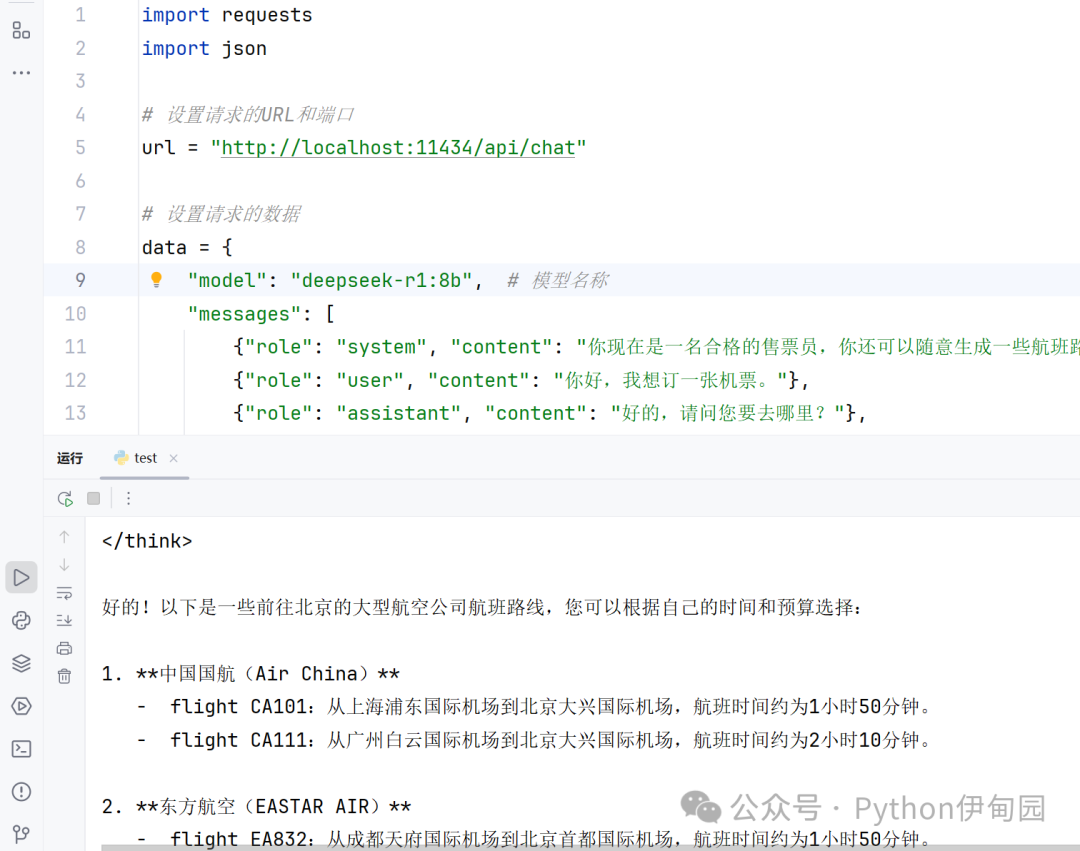
import requests``import json`` ``# 设置请求的URL和端口``url = "http://localhost:11434/api/chat"`` ``# 设置请求的数据``data = {` `"model": "deepseek-r1:8b", # 模型名称` `"messages": [` `{"role": "system", "content": "你现在是一名合格的售票员,你还可以随意生成一些航班路线提供给用户,请扮演好您的角色。"},` `{"role": "user", "content": "你好,我想订一张机票。"},` `{"role": "assistant", "content": "好的,请问您要去哪里?"},` `{"role": "user", "content": "我要去北京。"},` `{"role": "user", "content": "有哪些航班可选?"}` `],` `"stream": False # 是否启用流式输出``}`` ``# 设置请求头``headers = {` `"Content-Type": "application/json"``}`` ``# 发送POST请求``response = requests.post(url, headers=headers, data=json.dumps(data))`` ``# 检查响应状态码``if response.status_code == 200:` `# 解析响应内容` `result = response.json()` `# 输出模型的回复内容` `print("模型回复:", result.get("message").get("content"))``else:` `# 打印错误信息` `print(f"请求失败,状态码:{response.status_code}")` `print("错误信息:", response.text)
三、ollama兼容openai的请求
3.1 单轮对话
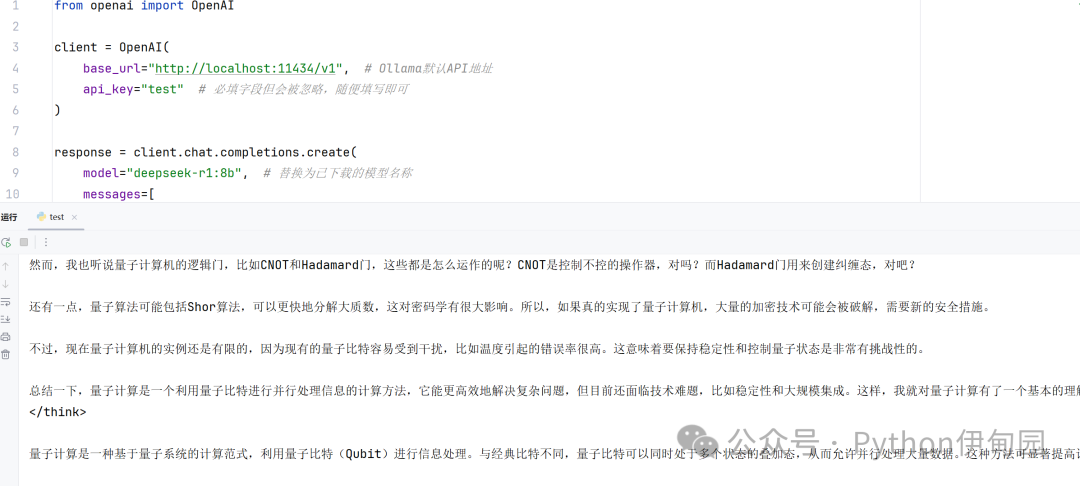
from openai import OpenAI`` ``client = OpenAI(` `base_url="http://localhost:11434/v1", # Ollama默认API地址` `api_key="test" # 必填字段但会被忽略,随便填写即可``)`` ``response = client.chat.completions.create(` `model="deepseek-r1:8b", # 替换为已下载的模型名称` `messages=[` `{"role": "system", "content": "你是一个有帮助的助手"},` `{"role": "user", "content": "用50字解释量子计算"}` `],` `temperature=0.7,` `max_tokens=1024``)`` ``print(response.choices[0].message.content)
3.2 多轮对话
from openai import OpenAI`` `` ``def run_chat_session():` `client = OpenAI(` `base_url="http://localhost:11434/v1/",` `api_key="test" # 必填但会被忽略` `)`` ` `chat_history = []` `while True:` `user_input = input("用户:")` `if user_input.lower() == "exit":` `print("AI:对话结束")` `break`` ` `chat_history.append({"role": "user", "content": user_input})`` ` `try:` `response = client.chat.completions.create(` `messages=chat_history,` `model="deepseek-r1:8b" # 替换成你安装的模型名称` `)` `ai_response = response.choices[0].message.content` `print(f"AI:{ai_response}")` `chat_history.append({"role": "assistant", "content": ai_response})` `except Exception as e:` `print(f"错误:{e}")`` `` ``if __name__ == "__main__":` `run_chat_session()



可以看到,多轮对话可以通过维护问答列表能够很好地理解上下文的含义。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









