






数字人是各种技术的集合,所以文章尽可能完整的介绍,项目中涉及的大小模型均可在本地部署并在我本人机器上运行。系统环境:
CPU: i9 14900 16GB
GPU: GTX 4060 8GB
SYS: Windows 11
WSL: Ubuntu 22.04
本文章使用到的技术内容:
- 数字人框架: LiveTalking
- 大模型: Llama3.1
- TTS: GPT-SoVits
- 语音转视频: Wav2Lip
- 前端展示:WebRTC
项目整体架构
分析数字人所需要的功能:
- 大模型生成回答文本
- 回答的文本生成语音
- 生成的语音生成视频
- 生成的视频推流前端
大模型生成文本
这个部分可以另外开五篇文章来介绍,主要是使用开源的大模型部署在本地或者使用公共大模型接口。
部署在本地的开源大模型
目前成熟的本地部署开源大模型的方式是ollama,另外就是可以使用python启动模型。由于调用大模型这里并没有什么可以定制的内容且ollama包含丰富的开源大模型内容,所以选择ollama来部署大模型。
目前的开源大模型中较好的有:
以上这几种都有较小的版本(7b、8b)可以在本地(GPU: rtx4060 with 8GB)上运行。
通过在官网上下载安装ollama,然后执行
ollama run llama3.1
即可下载并运行llama3.1的默认版本,下载完成后将会看到输入框,便可以使用本地大模型了。
由于开源大模型的规模比较小,知识不会全面和准确,所以需要使用知识库或者对模型微调,这里另开一篇文章。
公共大模型接口
这里指的是使用OpenAI、文心一言等闭源大模型接口,OpenAI相对其他大模型呈碾压态势,而文心一言由于其对中文特性的支持能在国内拿到一些份额。由于目前大模型降价很厉害,购买Token是一种非常具有性价比的选择。
但如果你处于战略性行业,对数据的安全和私密要求比较高,所有服务都是私有化部署的时候,使用闭源大模型服务就是一种非常危险的行为,尤其是使用OpenAI这种境外的服务厂商。另外就是闭源模型无法微调、使用知识库时可能消耗大量的Token,也是我没有使用闭源大模型厂商服务的原因。
回答的文本生成语音
其实就是文本转语音,就像使用翻译时候的朗读功能一样,只不过需要更加真实的音色、语气和停顿。
部署在本地的TTS模型
开源TTS模型效果比较好的是 GPT-SoVits,文档中对部署方式写的比较清晰,在github首页按照介绍使用就可以了,这里不多描述。
需要注意的是这个模型可以使用你输入的一段语音来生成一段具有相似音色的语音,需要准备好语音片段以及语音包含的文字内容。
在线TTS接口
这是最好的中文Text to Speech接口: [Azure] 有些方式可以免费使用,可以在Github上探索一下。
生成的语音转成视频
这部分几乎全部是开源模型的市场,目前有如下几个模型:
所以使用hallo和MuseTalk可能是最好的选择,但是我使用的数字人框架只支持MuseTalk和Wav2Lip,使用MuseTalk的时候安装mmvc总是出错,最后换成Wav2Lip,效果一般。
不过我又查看了下hallo,发现其推理效果不错,但是时间是真的长。check this issue:github.com/fudan-gener… 所以几乎无法完成我们的实时生成需求。
生成的视频推流前端
这部分实际上是最有挑战性的,主要的过程是:
- 静音模式下播放固定的动画视频
- 文字转语音,并切分成流式帧
- 将语音通过模型生成视频帧
- 将视频帧和语音帧同步的通过WebRTC推流到前端
技术细节比较多,还不是特别熟悉,暂时不写。
实践
通过上面的架构,我们直接使用LiveTalking框架,按照文档的指示来使用整个工作流,需要的工作就是:
- 提供大模型服务
- 提供TTS服务
- 做一些修改以适应需求
在开发的过程中发现有如下问题:
- 大模型对接有问题,支持的太少
- 前端界面也有一些问题
大模型支持
我部署完之后发现本地大模型没办法接入,所以直接在app.py内修改human()函数,我用了llama_index这个工具,比langchain的优势在于比较简单,可以快速插入,修改的内容如下:
if params['type'] == 'echo':
## 导入 llama_index(提前执行 pip install llama_index)
from llama_index.llms.ollama import Ollama
## 接入本地llama3.1大模型
llm = Ollama(model="llama3.1:latest", request_timeout=120.0)
## 全量执行输入的文字
## 这里有问题就是同步异步的问题,实际上大模型获取结果不应该阻塞渲染
resp = llm.complete(params['text'])
## 获取
nerfreals[sessionid].put_msg_txt(resp.text)
这样前端数字人回答的就是大模型的输出了。
前端UI更改
发现数字人无论怎么先进,都离不开文字输入输出的支持,即使支持了语音输入,也不过加了一个语音转文字的功能,所以在前端加上聊天对话是必要的,简单的修改一下界面如下图:
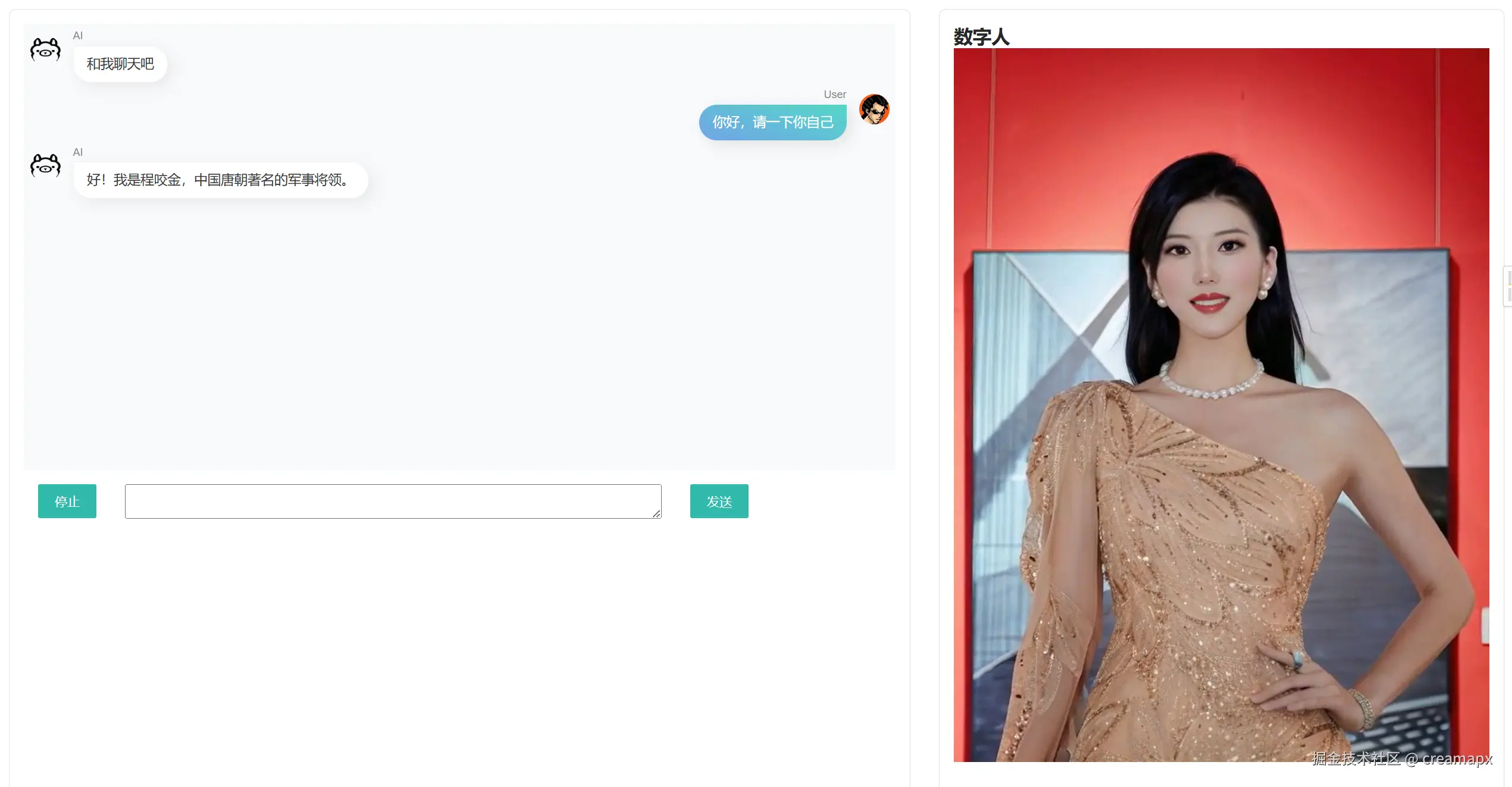
这样就完成了我们最开始的需求,具体修改的文件将放在Github上。
最后的思考
结论:数字人是比较鸡肋比较KPI的人工智能应用,它的应用场景仅限于生成视频投放到视频网站上或者去直播。在任何生产环境中很难提供真正的生产力。
我们现有的类似助手的应用:
- 苹果的Siri等手机助手
- 各种车机、物联网设备
- 各种大模型的应用
- 银行等机构的服务机器人
没有一个是使用数字人的,算力是一方面,更重要的是根本没有达到算力应有的效果和实际的生产力。 纯鸡肋。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









