






目录
简介基本组件小试牛刀关于沟通代码案例:调用Embedding、Completion、Chat Model总结 目前LangChain框架在集团大模型接入手册中的学习案例有限,为了让大家可以快速系统地了解LangChain大模型框架并开发,产出此文章。本文章包含了LangChain的简介、基本组件和可跑的代码案例(包含Embedding、Completion、Chat三种功能模型声明)。
01
简介
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
LangChain 作为一个大语言模型(LLM)集成框架,旨在简化使用大语言模型的开发过程,包括如下组件: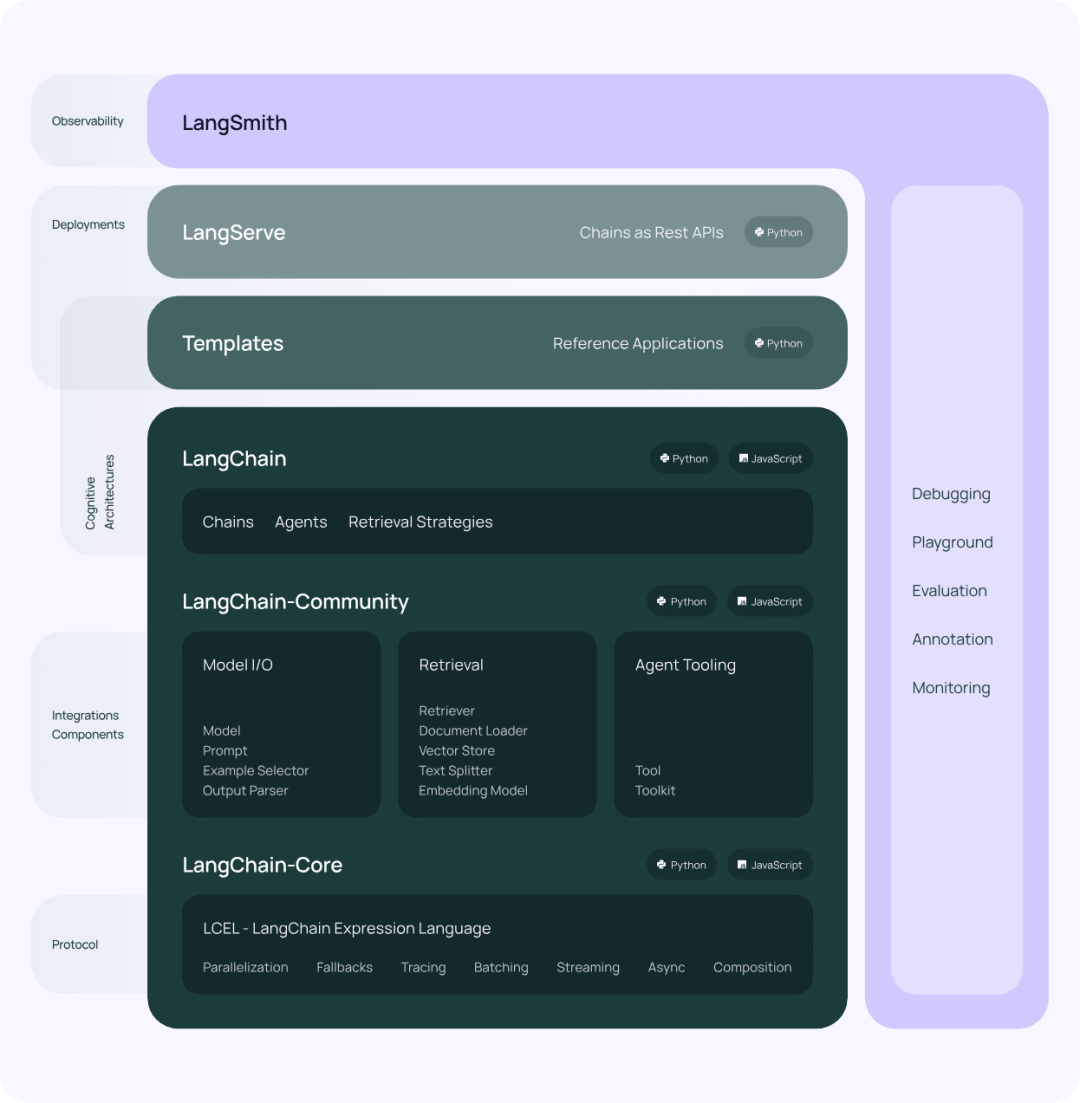
LangChain框架优点:
1.多模型支持: LangChain 支持多种流行的预训练语言模型,如 OpenAI GPT-3、Hugging Face Transformers 等,为用户提供了广泛的选择。
2.易于集成: LangChain 提供了简单直观的API,可以轻松集成到现有的项目和工作流中,无需深入了解底层模型细节。
3.强大的工具和组件: LangChain 内置了多种工具和组件,如文档加载器、文本转换器、提示词模板等,帮助开发者处理复杂的语言任务。
4.可扩展性: LangChain 允许开发者通过自定义工具和组件来扩展框架的功能,以适应特定的应用需求。
5.性能优化: LangChain 考虑了性能优化,支持高效地处理大量数据和请求,适合构建高性能的语言处理应用。
6.Python 和 Node.js 支持: 开发者可以使用这两种流行的编程语言来构建和部署LangChain应用程序。
由于支持 Node.js ,前端大佬们可使用Javascript语言编程从而快速利用大模型能力,无需了解底层大模型细节。同时也支持JAVA开发,后端大佬同样适用。
本篇文章案例聚焦Python语言开发。
02
基本组件
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
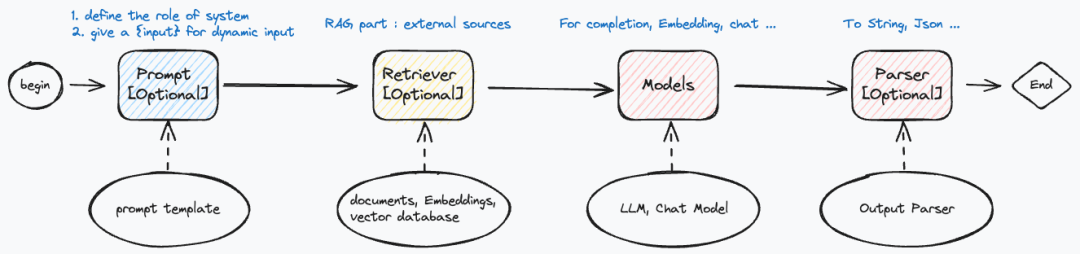
-
Prompt【可选】
-
- 告知LLM内system服从什么角色
- 占位符:设置{input}以便动态填补后续用户输入
-
Retriever【可选】
-
- LangChain一大常见应用场景就是RAG(Retrieval-Augmented Generation),RAG 为了解决LLM中语料的通用和时间问题,通过增加最新的或者垂类场景下的外部语料,Embedding化后存入向量数据库,然后模型从外部语料中寻找相似语料辅助回复
-
Models
-
- 可做 Embedding化,语句补全,对话等
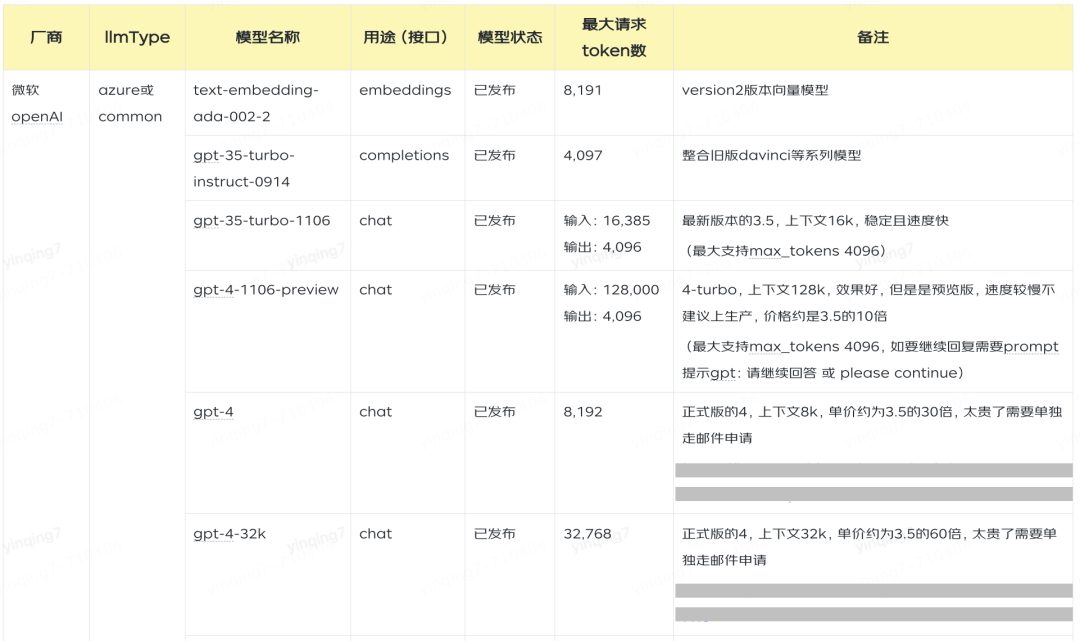
支持的模型选择,OpenAI为例
-
Parser【可选】
-
- StringParser,JsonParser 等
- 将模型输出的AIMessage转化为string, json等易读格式
上述介绍了Langchain开发中常见的components,接下来将通过一简单案例将上述组件串起来,让大家更熟悉Langchain中的组件及接口调用。
03
小试牛刀
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。

输出:
"Why don't bears wear shoes?\nBecause they have bear feet!"
其中 chain = prompt | model | output_parser 按照数据传输顺序将上述声明的 prompt template、大语言模型、输出格式串联起来(Chain),逻辑清晰直接。
代码案例:调用Embedding、Completion、Chat Model
- 将文本转化为Embedding :langchain_community.embeddings <-> OpenAIEmbeddings

- 文本补全:langchain_community.llms <-> OpenAI completion
from langchain_community.llms import OpenAI
llm = OpenAI(
model_name='gpt-35-turbo-instruct-0914',
openai_api_key=os.environ["OPENAI_API_KEY"],
base_url=base_url,
temperature=0
)
llm.invoke("I have an order with order number 2022ABCDE, but I haven't received it yet. Could you please help me check it?")
对话模型:langchain_openai <-> ChatOpenAI

04
总结
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
LangChain作为一个使用流程直观的大模型开发框架,掌握它优势多多。希望您可以通过上述内容入门并熟悉LangChain框架,欢迎多多交流!
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









