






Entropy Law:多数据集组合时的数据筛选方法
Entropy Law: The Story Behind Data Compression and LLM Performance
数据是大型语言模型(LLM)的基石。大多数方法侧重于评价单个样本的质量,而忽略了样本间的组合效应。
受LLMS信息压缩特性的启发,我们发现了一个将LLM性能与数据压缩比和第一个epoch训练损失联系起来的“熵定律”,它们分别反映了数据集的信息冗余度和对该数据集中编码的固有知识的掌握。
基于熵定律的结果,我们提出了一种非常有效和通用的数据选择方法ZIP来训练LLMS,该方法旨在对压缩比较低的数据子集进行优先排序。基于贪婪地选择不同数据的多阶段算法,我们可以得到一个具有满意多样性的良好数据子集。
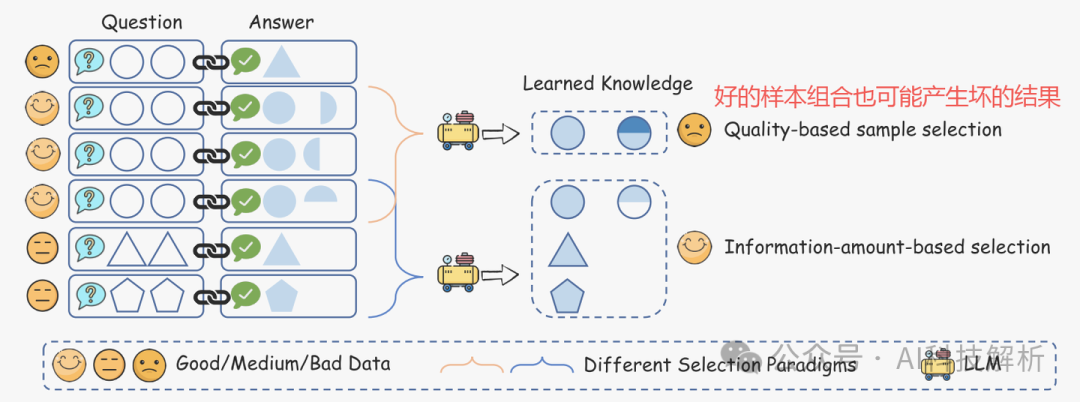
虽然有多个好的样本数据,但它们编码的知识可能是冗余的和相互冲突的。而由几个相对较低质量但不同的样本组成的另一个数据子集可能比上述子集传递更多的信息。(这说明多数据组合时要去重。。。)
在论文《Compression Represents Intelligence Linearly》中提到:LLMS中自回归语言建模的基本机制是信息压缩。(就是训练总数据集的token数/总数据集的char个数,其实并不能完全代表模型的能力,只能说表示了tokenizer的能力)

使用每条消息的平均编码长度(即比特每字符,BPC)来评估模型的压缩效率。
将LLM的性能表示为Z,它预计会受到以下因素的影响:
- 数据压缩比R: 该度量可以通过将压缩前的数据大小除以压缩后的大小得出,该大小可以通过各种现有的压缩算法来计算。直观地说,压缩比较低的数据集表示较高的信息密度。
- 训练损失L: 表示数据是否难以被模型记住。在给定相同的基本模型的情况下,高训练损失通常是由于数据集中的噪声或不一致的信息造成的。在实践中,第一个训练周期中少量训练步长的平均损失足以产生指示性的L值,从而使模型不会对数据进行过度拟合。
- 数据一致性C: 数据的一致性由给定先前上下文的下一个令牌的概率的熵来反映。较高的数据一致性通常会产生较低的训练损失。
- 平均数据质量Q: 这反映了数据的平均样本级质量。
那么有
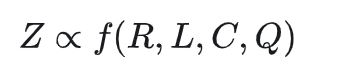
其中数据一致性C通常和L相关,因此选一个就行。数据质量不会随选择而变化,视为常数,则有
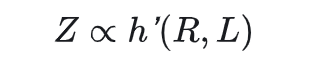
模型的性能与数据压缩比和训练损失有关。将这种关系称为“熵定律”。
ZIP筛选
该方法的目标是在有限的训练数据预算下最大化有效信息量。
- 1、首先全局选择压缩比最低的多个候选样本构建样本池,目的是找到信息密度较高的样本。直观地说,样本内信息冗余度高的数据不太可能具有良好的全局多样性。
- 2、然后采用粗粒度局部选择阶段,将剩余的每个样本添加进样本池,计算总样本池的压缩比。选择总压缩比较小的样本添加进来。这一步计算了多样本之间的组合效果。
- 3、从样本池中选择一个局部样本。和其他样本逐个计算压缩比,压缩比低表明差异大,可保留。最终得到信息差异最大的一个子样本池。

ZIP
这个方法本质上就是通过信息压缩率衡量数据集的信息冗余程度,从而选出差异性最大的数据集**(去重)**进行训练。
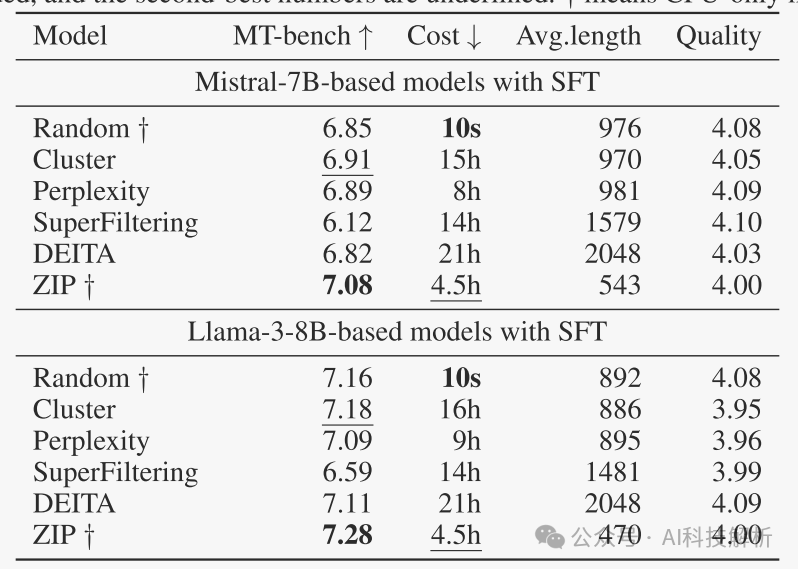
ZIP数据筛选方法比随机选择和其他筛选方法取得了更好的效果。
总结
其实就是去掉重复度高的数据集。但是实际场景中,即使是重复度高的数据集中也会包含大量不重复的内容,这部分内容对拓展模型知识范围有用,因此不如直接对数据去重好用。
类似的还有《Data curation via joint example selection further accelerates multimodal learning》,通过模型loss筛选出最有价值的数据集单独进行训练,减少了训练数据、降低了迭代次数,提高了效率。
高质量微调数据集探索
From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models
https://github.com/meowpass/FollowComplexInstruction
本文提出了三个问题:1:什么样的数据能增强SFT的效果?2:如何得到这类数据?3:如何利用上述数据进行有效微调?

Constraints data
- 1、什么样的数据能增强SFT的效果?
复杂约束的数据具有更好的微调结果。也就是数据的描述越详细、准确,微调效果越好。
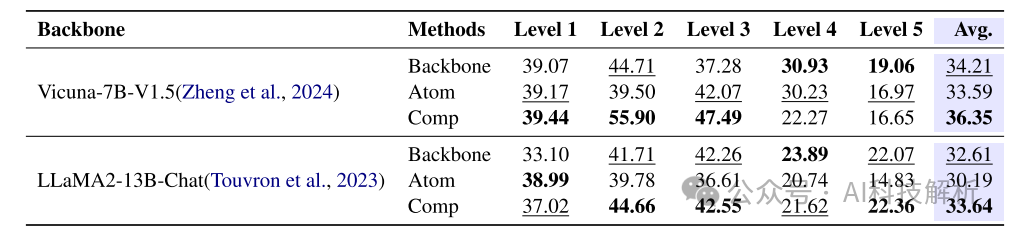
不同数据方法的得分
其中Backbone是指原始预训练模型,Atom指使用单约束数据微调的模型,Comp是指使用多条合成约束微调的模型。可以看出多约束数据模型结果更好。
- 2、如何得到这类数据?
高级LLM(Generation)的输出质量高于较弱LLM(Vanilla)的输出质量。然而,来自较弱LLM的输出然后由高级LLM细化(辨别)显著优于由高级LLM直接生成的输出(生成)。我们认为这是因为指令(即约束)的微小变化会导致实质性的输出差异,基于区分的方法比基于生成的方法更好地捕捉到这一点。
大模型做判别的效果比生成效果更好!!!
- 3、如何利用上述数据进行有效微调?
引入了一种基于强化学习微调(RLFT)的方法,该方法利用正样本和负样本来改善复杂的指令跟踪。

RLFT微调
方法
1、为了获得组合数据,首先从三个广泛使用的预调优数据集收集种子指令。然后重写指令以合并多个约束。
2、提出了一种基于判别的方法来获得输出,首先利用LLaMA 2-13B-Chat(学生模型)来生成我们合成的复杂指令的果。然后利用Zhou等人(2023 a)的测试脚本来识别模型未能遵循的约束,因为这些约束是客观的,并且可以自动验证。最后采用先进的LLM(教师模型)GPT-3.5-turbo,逐一纠正失败的约束。
3、对于每个指令Ic,可以收集正样本集和负样本集。监督微调(SFT)仅利用成功满足复杂指令中指定的约束的正样本。
然而,负样本未能满足某些限制,也提供了有价值的监督信息。因此通过强化学习微调来利用正样本和负样本。具体地,给定输出集合O,对于每个复杂指令Ic,可以形成包括f个对比三元组的训练数据集 。在每个训练三元组中,(正样本)的最终校正输出优于〇 i(负样本),如以下在复杂指令Ic中指定的更多约束。在此之后,直接偏好优化(DPO)可以应用于对偏好信息进行建模。损失函数是语言模型参数πθ的最大似然目标。
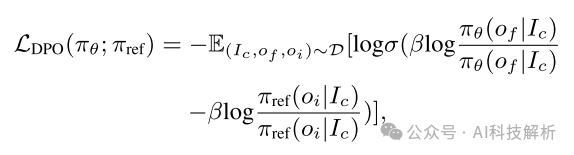
仅依赖于LDPO可能导致选择和拒绝输出的概率较低,但它们之间存在显著差异。因此,我们另外整合SFT损失LSFT以约束πθ偏离优选的数据分布
效果评估
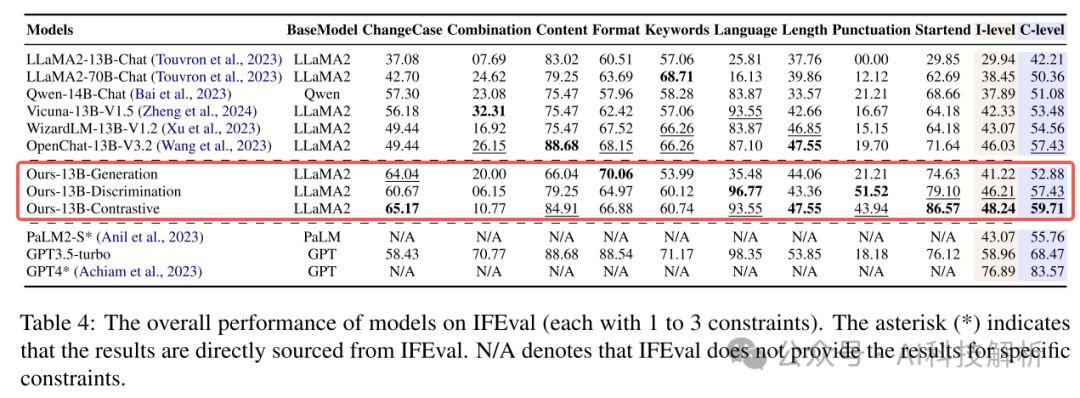
其中Ours-13B-Generation 直接使用 GPT-3.5-turbo 生成输出,并通过监督微调 (SFT) 训练骨干模型。Ours-13B-Discrimination 通过主干模型生成输出,然后使用 GPT-3.5-turbo 进行细化,并通过 SFT 训练主干模型。Ours-13B-Contrastive 利用 DPO 进行训练,对正样本和负样本进行建模。三种方法的骨干模型均为LLaMA2-13B-Chat,训练数据的说明相同;只有训练数据和训练范式的输出不同。
得分基本上都高于其他方法和原始模型。
如何进行数据筛选
Scaling Laws for Data Filtering – Data Curation cannot be Compute Agnostic
https://github.com/locuslab/scaling_laws_data_filtering
虽然数据是海量的,但是高质量数据是有限的。
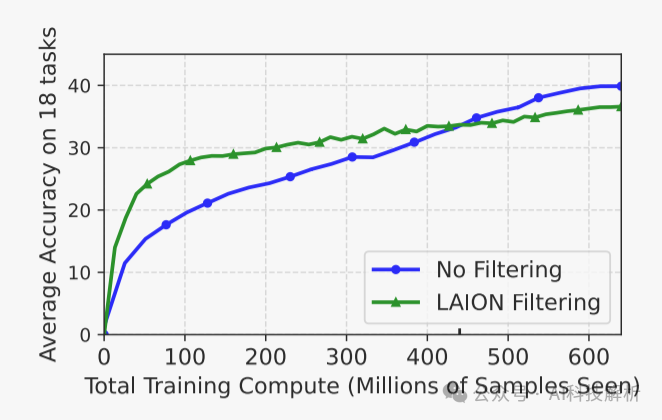
测试表明,在低计算量的情况下(Epoch数目少),好的数据更好:在低训练计算量的情况下,利用高质量的数据是有益的。但随着Epoch数目的增加,低质量数目集效果更好(可能是见识到的内容更多)。
大模型如何学习知识?
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
通常认为,LLM在预训练中学习知识。但是LLM对长尾知识的习得很差。有观点认为,Attention的qkv结构是对知识进行抽取(q*k计算attn_score对v加权平均),MLP结构是知识记忆。
下面通过实验进行深入分析。
创建虚拟知识数据集
为了便于测试,创建了虚拟知识数据集,包含对虚构而又真实的实体的描述的段落,使得预训练的LLM中没有相关知识。**Injected knowledge:**将每一段注入到预训练批中的一个序列中,并在遇到知识时考察LLM的记忆和概括的动力学。我们称这些通道为注入的知识。 为了考察LLMS在不同深度对已获得的事实知识进行概括的能力,将习得的概念分为三个深度:
- 记忆:记住用于训练的确切序列
- 语义概括:在单句水平上将事实知识概括为释义格式
- 成分概括:在注入的知识中合成多个句子中呈现的事实知识。
根据这一直觉,我们仔细地为每个注入的知识的三个不同获取深度的每一个设计了五个探针,总共产生了1800个探针。每个探测都被构建为完形填空任务,由输入和目标跨度组成,其中目标跨度是一个简短的短语,旨在测试我们评估的事实知识的获得情况。注入的知识和对应的探测的例子如表1所示。

为了详细分析LLMS在预培训期间对事实知识的获取,我们通过检查日志概率来评估模型的状态,以获得细粒度信息。
结论
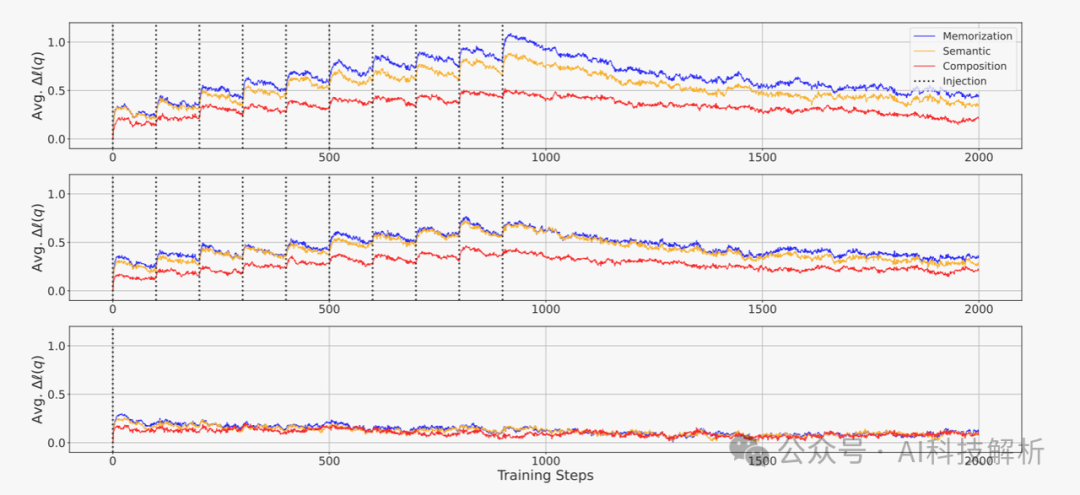
1、从上图可看出,每次注入知识更新模型后,对数概率都有所增加,表明学习到了知识,当不再注入后,知识慢慢遗忘。证明了事实知识获取的机制:LLMS通过积累微获取来获取事实知识,然后在预训练期间每次模型遇到其他知识时都会忘记当前知识。 (这是不是说明更大的bs效果更好??!更少的iter次数,更少的遗忘次数) 2、当模型在看到事实知识后进行更新时,观察到对数概率的改善最显著的是记忆,其次是语义概括,而成分概括的改善最小。然而,接下来,在释义注入场景中,记忆和语义概括之间的差距几乎消失。 3、当使用重复注入情景更新模型时,该模型显示出在所有习得深度的对数概率都有更大的改善,但遗忘也更快,最终导致在训练结束时与释义注入情景相似的改善水平。 4、用更大和更多样化的数据集训练LLMS的高性能主要不是因为在训练期间观察到的绝对数量的令牌[43]的涌现能力,而是因为模型更多次地遇到更广泛的知识,这允许更多知识的对数概率变得足够高,足以作为模型的输出进行解码。 5、训练步骤和对已获得事实知识的遗忘具有幂规律关系。
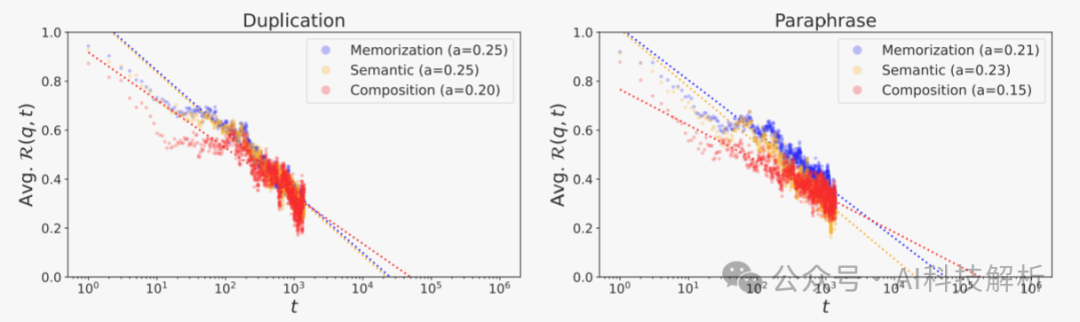
6、一般常识是使用更大的批处理大小进行预训练可以帮助LLM获得更多知识。但还没有完全证明。使用较小的批次大小训练的LLMS显示出更高的有效性,但衰减也比较快。这意味着以较小的批次大小训练的模型具有较短的可学习性阈值,这一点使得LLM无法学习以超过该阈值的间隔提供的知识。 7、如果预训练数据集中的给定事实知识是长尾的,并且该知识以长于特定阈值的间隔呈现给模型,则无论预训练的持续时间如何,这种知识都不可能被解码为模型的top-k生成或学习。大多数众所周知的事实可能以比该可学习性阈值更短的训练步骤的间隔呈现给模型。 8、重复数据消除往往会减缓对已获得的事实知识的遗忘。以较短的间隔呈现该模型的重复文本将导致记忆和概括之间的差距扩大,这将促使该模型比概括事实知识更喜欢生成记忆的上下文(生成重复)。
数学推理能力优化方法:DeepSeek-Prover
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
通过生成的定理数据提高LLM的数学推理能力。
1、我们引入了一种迭代方法,从非正式的数学问题中合成800万个正式陈述,每个陈述都附有正式证明。实验结果表明,该方法显著提高了合成数据的可扩展性和质量。
2、在此合成数据集上进行训练的模型,在基准测试中达到了最先进的性能。
方法
🌴1、从广泛的非正式数学问题集合中生成正式的数学陈述,需要进一步的证明.
与需要复杂定义和构造的高级数学主题相比,具有明确条件和明确目标的问题通常更容易形式化。因此,本文主要探讨高中和本科水平的竞争问题。采用了网络抓取和仔细的数据清理技术,从高中和本科练习,考试和比赛的在线资源中提取问题,从而产生了869,659个高质量自然语言数学问题的数据集。 🌴2、通过模型评分和假设拒绝方法过滤自形式化语句,以选择高质量的语句。
该模型被指示将每个正式陈述的质量分为几类:“优秀”、“良好”、“高于平均水平”、“一般”或“差”。“被评为“一般”或“差”的发言随后被排除在外。 🌴3、这些语句由一个名为DeepSeek-Prover的模型证明,其正确性由名为Lean 42的正式验证器验证,产生经过验证的正式语句和证明。
即使经过质量过滤,我们的模型生成的正式语句中至少有20%是不正确的,如果使用蛮力解决,会导致大量的计算浪费。为了最大限度地减少对不可证明语句的资源浪费,提高证明搜索过程的效率,我们利用语句及其否定之间的逻辑对称性来加速证明合成。 🌴4、这些数据作为合成数据用于微调DeepSeek-Prover。
不断地用新生成的数据对模型进行微调。更新后的模型然后用于后续的自动形式化迭代。 在增强DeepSeek-Prover之后,重复前面描述的整个过程。这个循环一直持续到DeepSeek-Prover的改进变得微不足道。
值得注意的是,为了提高证明效率,我们同时证明了原始陈述及其否定。这种方法的优点是,当原始陈述通过证明其否定而无效时,可以迅速丢弃原始陈述。
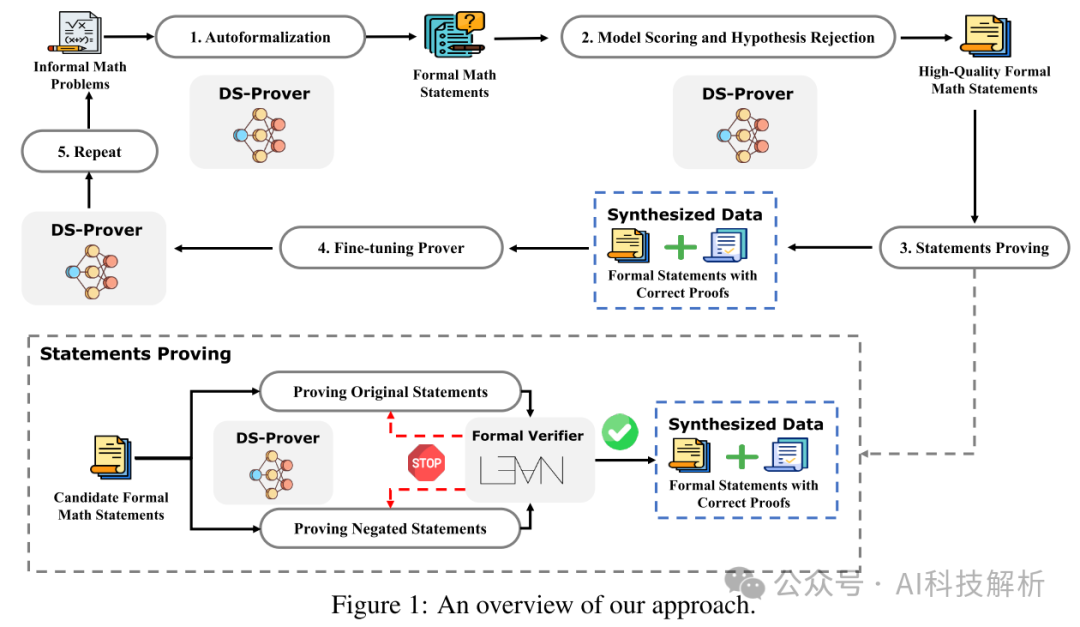
效果评估

精度有明显提升
PiSSA微调
PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
GitHub - GraphPKU/PiSSA: PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
PiSSA是一种类似LoRA的微调方式。
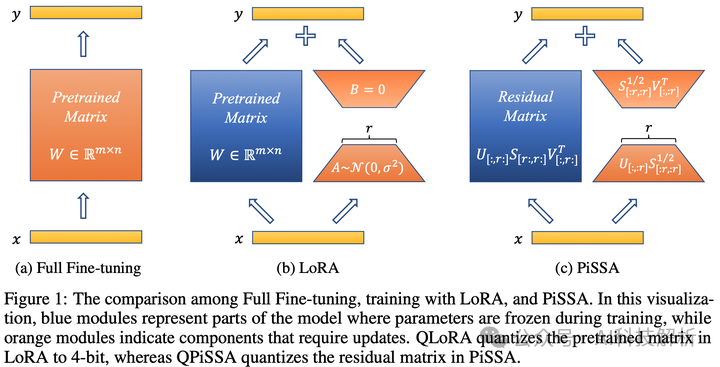
首先将权重矩阵进行SVD分解,得到W = USV^T ,其中设置低秩参数r,根据分解矩阵的性质将W拆为两部分。
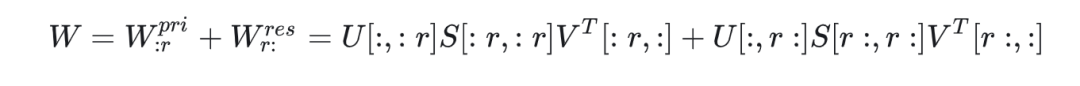
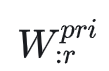 是前r个主奇异值表示的矩阵
是前r个主奇异值表示的矩阵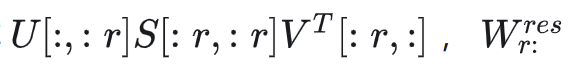 是其余奇异值组成的矩阵
是其余奇异值组成的矩阵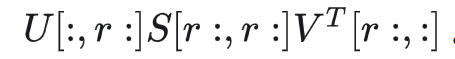
那么再将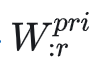 再拆分成两部分,得
再拆分成两部分,得
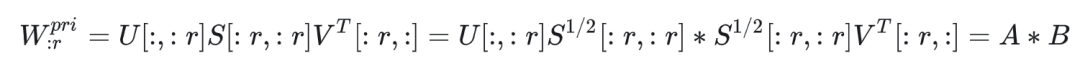
那么原始的矩阵W最终被拆分成
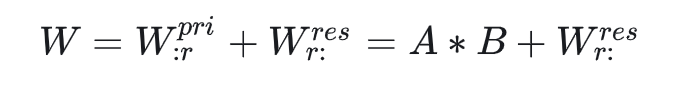
这和LoRA的方法一摸一样。只不过LoRA是假设权重更新矩阵为低秩,用A和B相乘拟合(实际上秩可能没这么小,因此拟合的精度会下降)。而PiSSA是将矩阵奇异值分解后得到的低秩矩阵A和B。没有前提条件,相对而言效果更好。
且此时的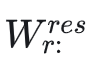 分布更加集中,离群值更少,量化损失也更低。
分布更加集中,离群值更少,量化损失也更低。
Figures
从评测结果可以看出,PiSSA的效果全部好于LoRA,很多场景下甚至优于全量微调。
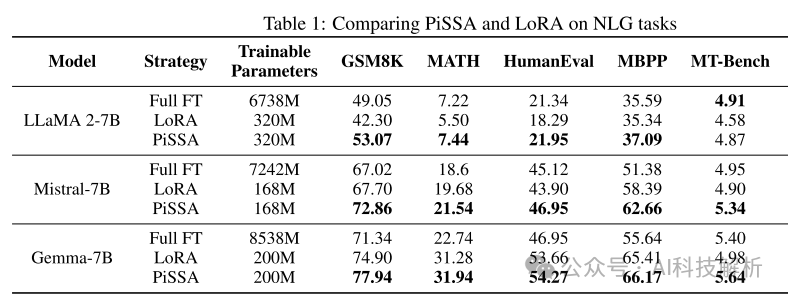
Comparing PiSSA and LoRA on NLG tasks
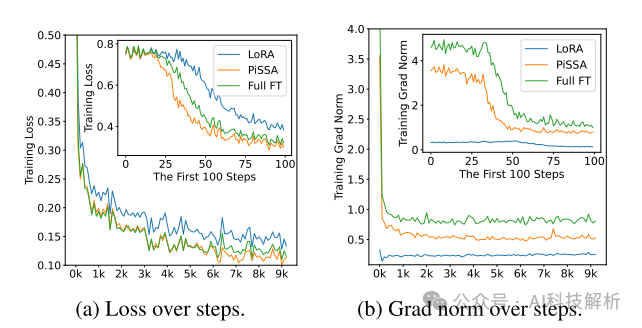
微调的Loss也很低,甚至低于Full FT。
Double Dipper:增强超长上下文的模型能力
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
实际场景中的prompt可能会特别长,包含了很多信息,会在一定程度上分散模型的注意力,影响模型生成结果的质量。
据分析,模型对起始位置和结束位置的prompt响应效果较好,对中间部分prompt的响应极差。
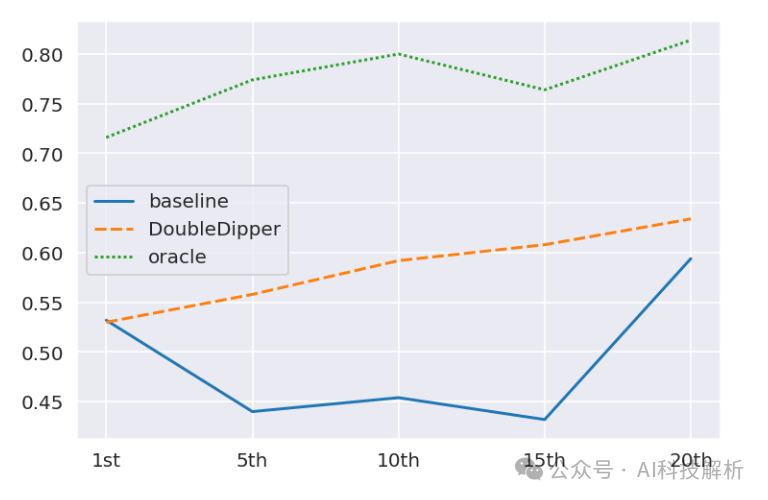
Performance of Gemini Pro (v1.0) on a sam-ple of the Lost-in-the-middle datase
DOUBLEDIPPER原理如下

随机选择某些段落,输入prompt让模型根据内容自动生成相关问题,再根据问题生成答案。这样就有多个问题+段落+答案的pair数据。将相关数据作为Few shot数据添加进去,显示引导模型进行数据定位,从而生成更加刚高质量的回答。
相比长段落的输入prompt来说,生成的问题、答案以及段落ID的总长度很短,因此不会明显增加模型的负担。
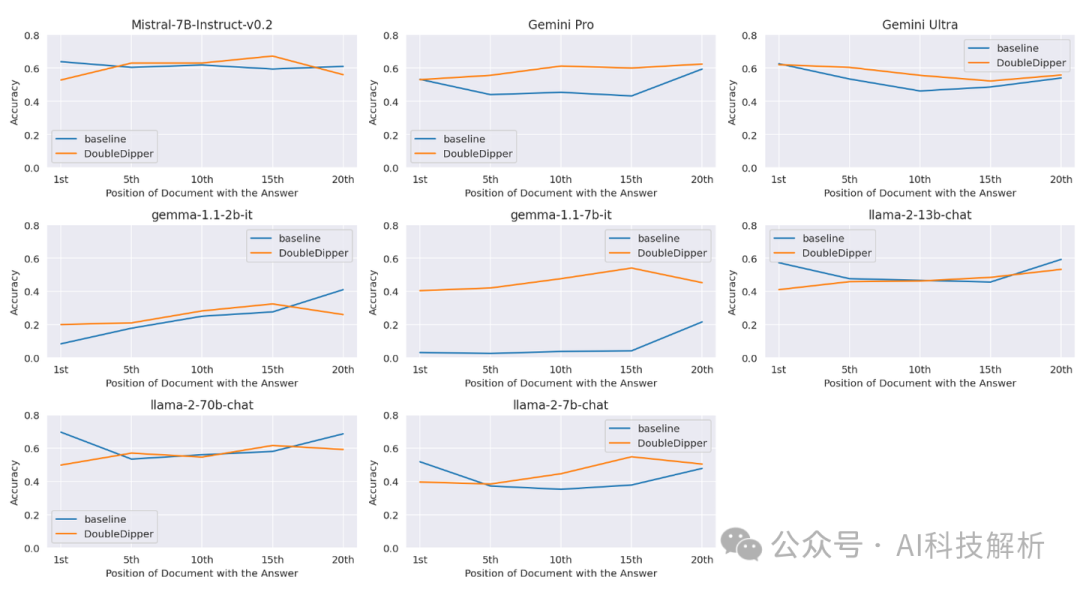
从图中可看出,模型的性能大部分场景下都有一定程度的提高。
Ps:开局一张图,LLM在中间位置的表现极差,所以要提升。结果最后评测的LLM,没几个模型在中间位置差那么离谱的。早放这些图,这篇论文就没多少研究的价值了。。。
结论就是:费半天劲,有那么一点效果。
Found in the Middle:增强超长上下文的模型能力
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization
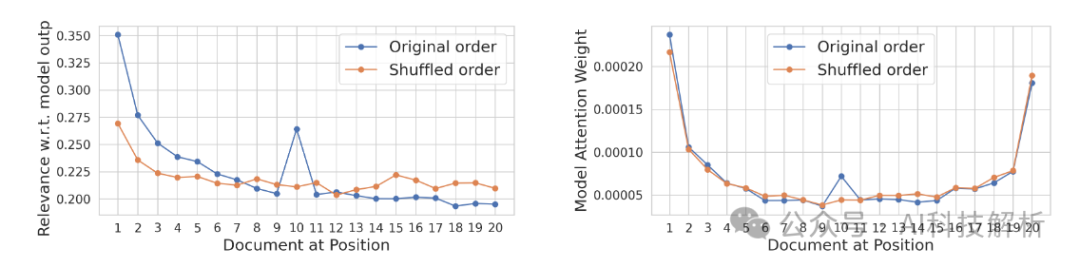
测试也好测,三大段落文章调换顺序,查看不同顺序下模型的生成结果差异,应该就可以对比出来。
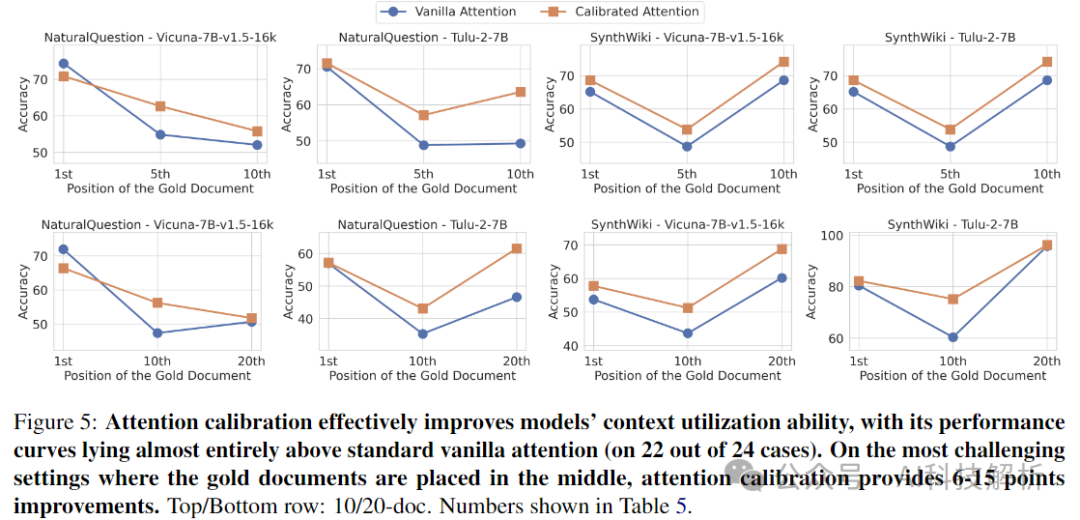
论文中认为是注意力偏差导致的,需要对注意力进行矫正。允许模型根据其相关性忠实地关注上下文。

校正后的注意力机制效果更好
T-FREE
T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings
分词器在LLMs中用于将文本分割成子词并转换成整型表示,但它存在计算开销大、词汇表使用效率低、嵌入层和头层过大等问题,并且对于代表性不足的语言性能下降。
提出了T-FREE,一种无需分词器的新型LLMs嵌入方法,通过稀疏表示实现内存效率。
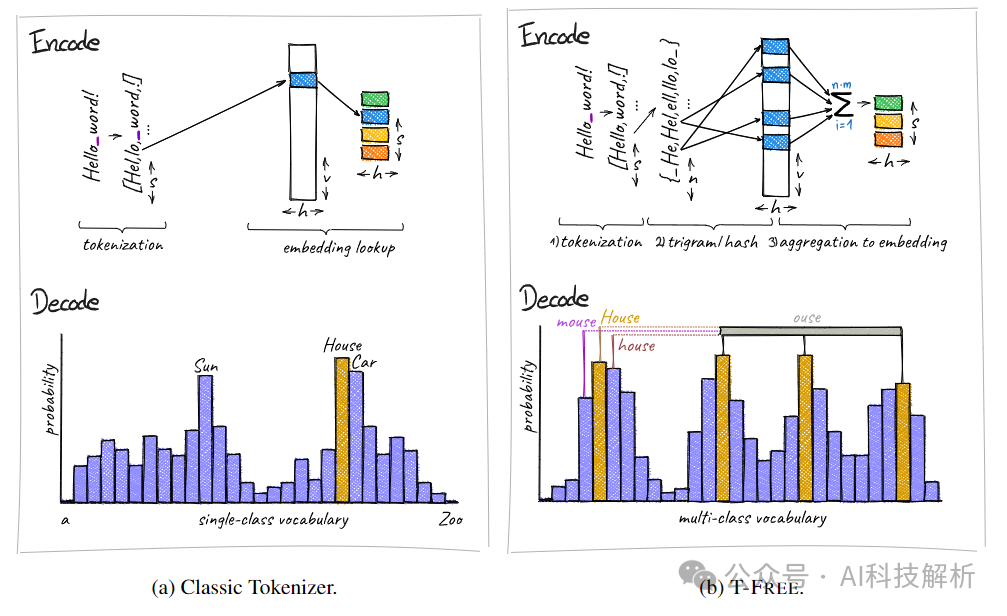
Classic Tokenizer vs T-FREE
总结就是ont-hot编码有大量的信息冗余。T-FREE 的一个关键动机是直觉上,拼写上的微小差异(例如前导空格或大写)没有足够的熵来证明完全独立的标记是合理的,因此通过multi-hot编码,既能更好的表示不同token之间的关联性,又可以大大降低embedding的大小,降低编码长度。
最终在不降低性能的情况下,减少了85%的词汇表。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/python122_/article/details/140681757?spm=1001.2014.3001.5501,如有侵权,请联系删除。















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









