



在人工智能浪潮席卷全球的今天,大模型(Large Language Models, LLMs)无疑是最炙手可热的技术方向之一。然而,对于大多数普通人而言,学习大模型并非易事——不是因为技术门槛高不可攀,而是因为“信息差”这个隐形壁垒让人屡屡碰壁。我自己就是活生生的例子:一开始盲目自学、东拼西凑看教程,结果浪费了大量时间却收效甚微;直到后来调整策略、系统规划,才在短短三个月内实现从零基础到斩获大厂Offer的飞跃。今天,我想以自己的经历为反面教材,给刚踏入大模型领域的你提个醒:别再走弯路,信息闭塞真的会吃大亏。

一、别被碎片化内容误导,系统学习才是正道
刚开始接触大模型时,我和很多人一样,习惯性地在B站、知乎、公众号上搜“大模型入门教程”。结果呢?今天看一个Transformer原理视频,明天学一段Prompt Engineering技巧,后天又去研究LangChain怎么调用API……看似每天都在进步,实则知识零散、逻辑混乱,根本无法形成体系。更糟糕的是,很多免费教程为了吸引眼球,刻意简化甚至曲解概念,导致我一度对“微调”“RAG”“Agent”等核心术语的理解出现严重偏差。
这种碎片化学习方式最大的问题在于:它让你误以为自己“懂了”,实际上只是记住了几个名词。而大模型领域恰恰是一个高度依赖底层逻辑和工程实践的方向——如果你连基本架构都不清楚,后面的学习只会越走越偏。
二、三个月高效学习路线:从原理到实战闭环
痛定思痛之后,我重新梳理了学习路径,并严格按照以下四个阶段推进,最终实现了质的飞跃:
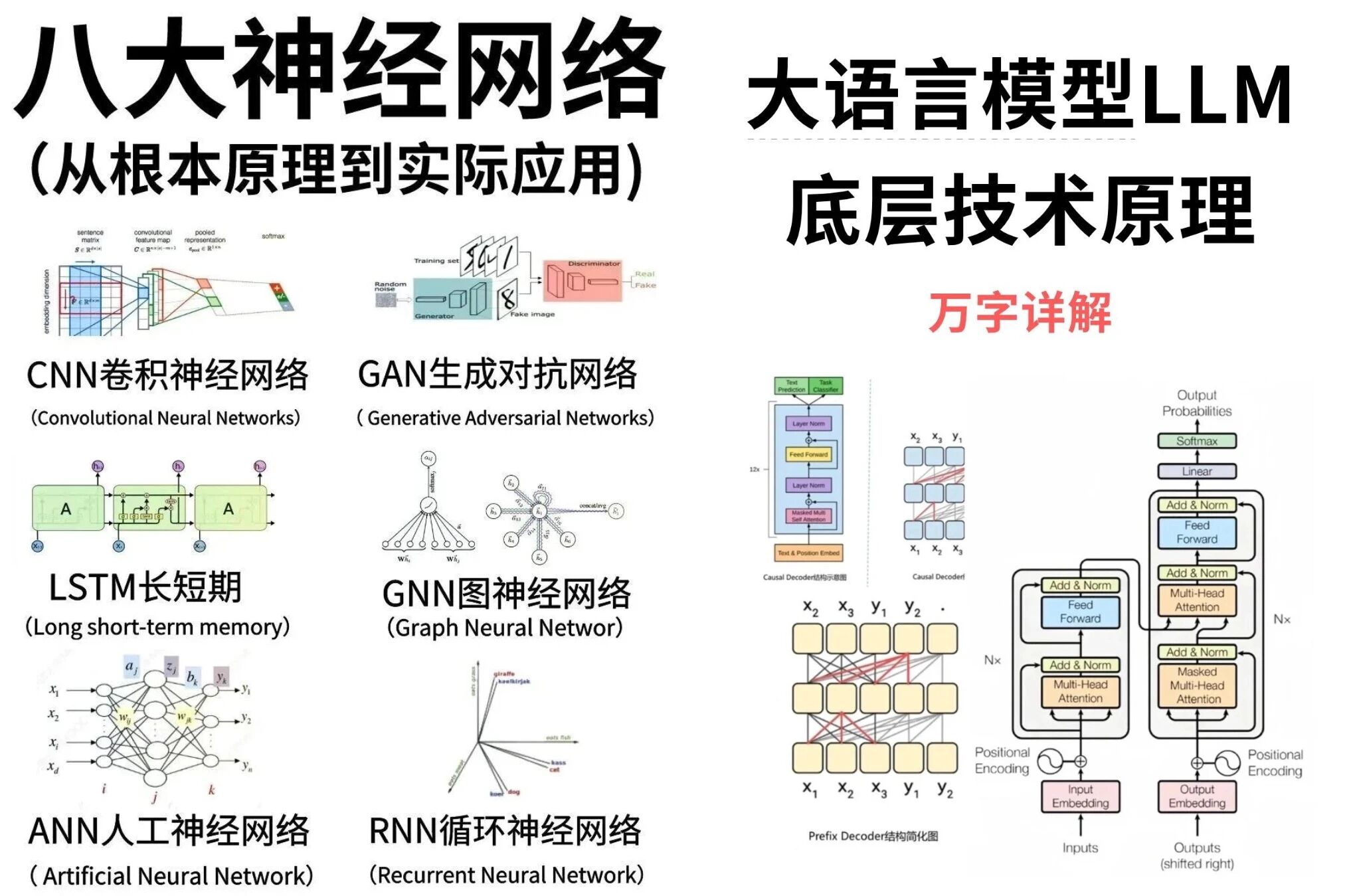
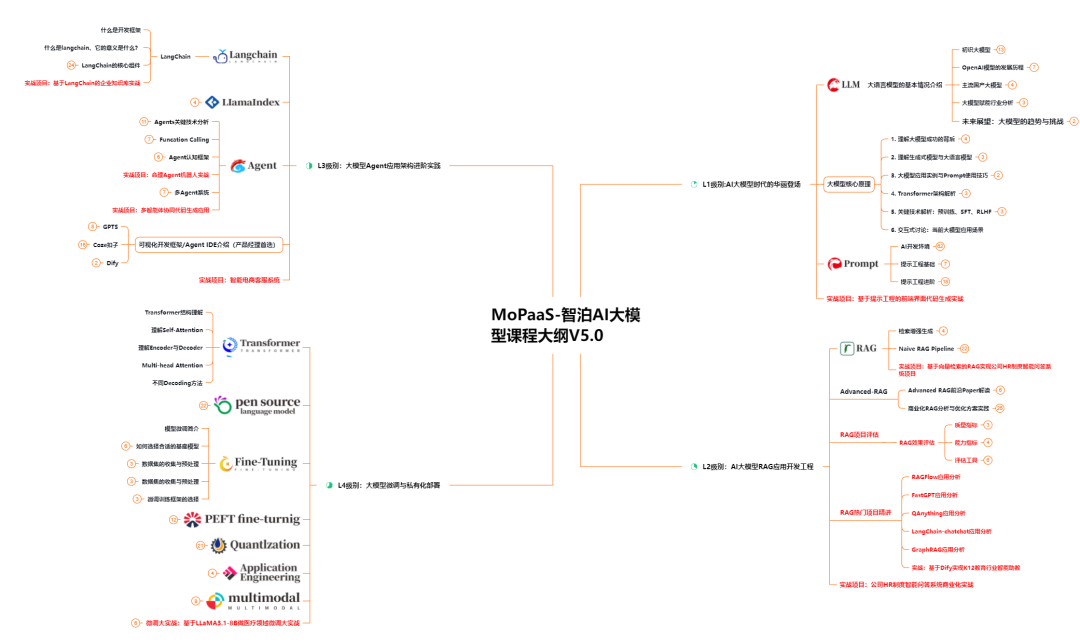
第一阶段:夯实基础(第1-2周) 目标是建立对大模型的整体认知。重点学习Transformer架构、注意力机制、Tokenization原理等核心概念,同时掌握提示词工程(Prompt Engineering)的基本技巧。这一阶段不需要深入代码,但必须理解“为什么大模型能工作”以及“如何有效与模型对话”。
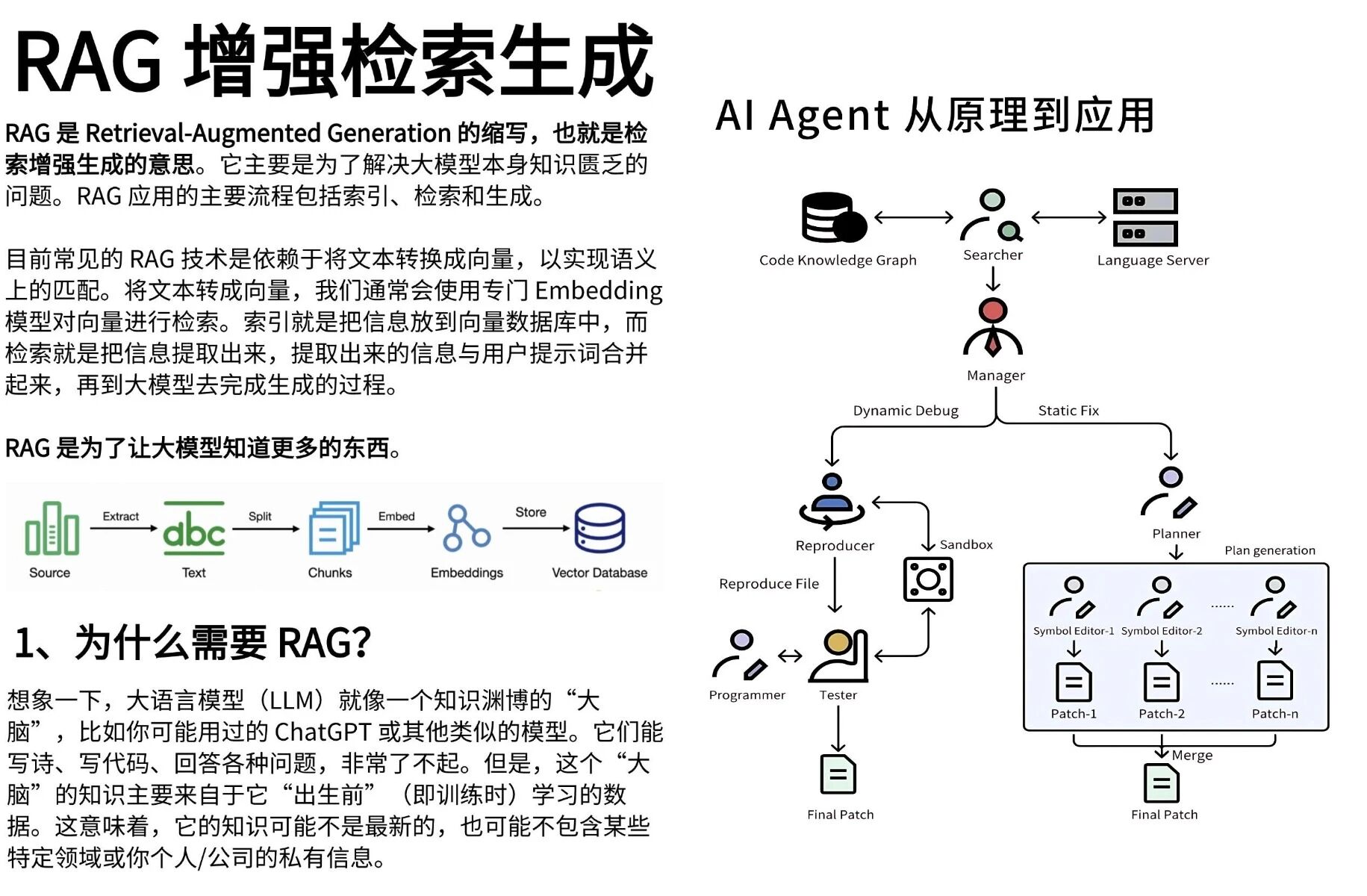
第二阶段:进阶应用(第3-6周) 聚焦当前工业界最主流的三大技术栈:RAG(检索增强生成)、Agent(智能体)和LangChain框架。RAG解决的是模型知识滞后的问题,Agent则是构建自动化任务流的关键,而LangChain作为连接大模型与外部工具的桥梁,几乎是所有项目开发的标配。这一阶段要动手写代码,搭建简单的问答系统或任务调度器,把理论转化为能力。

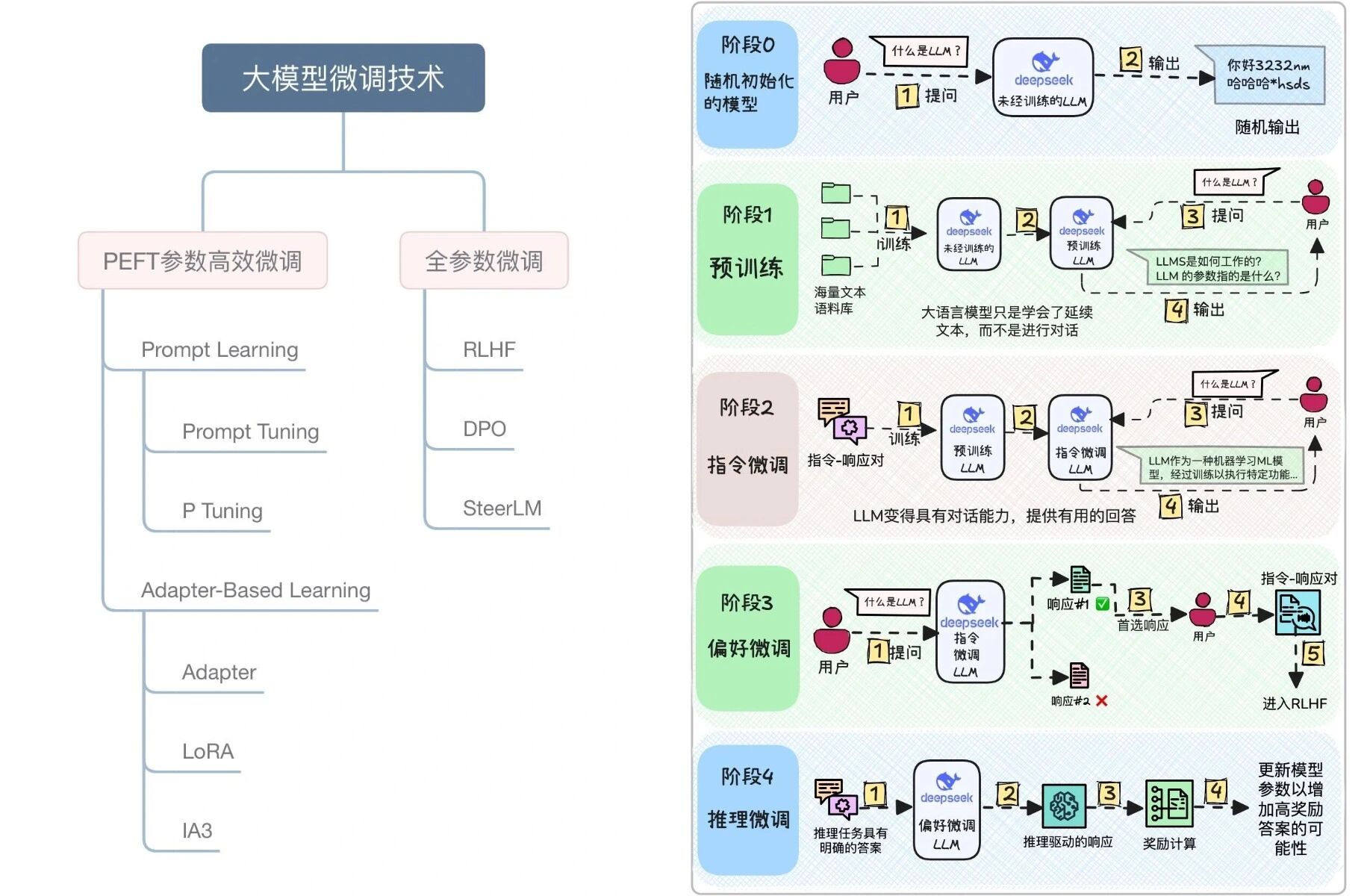
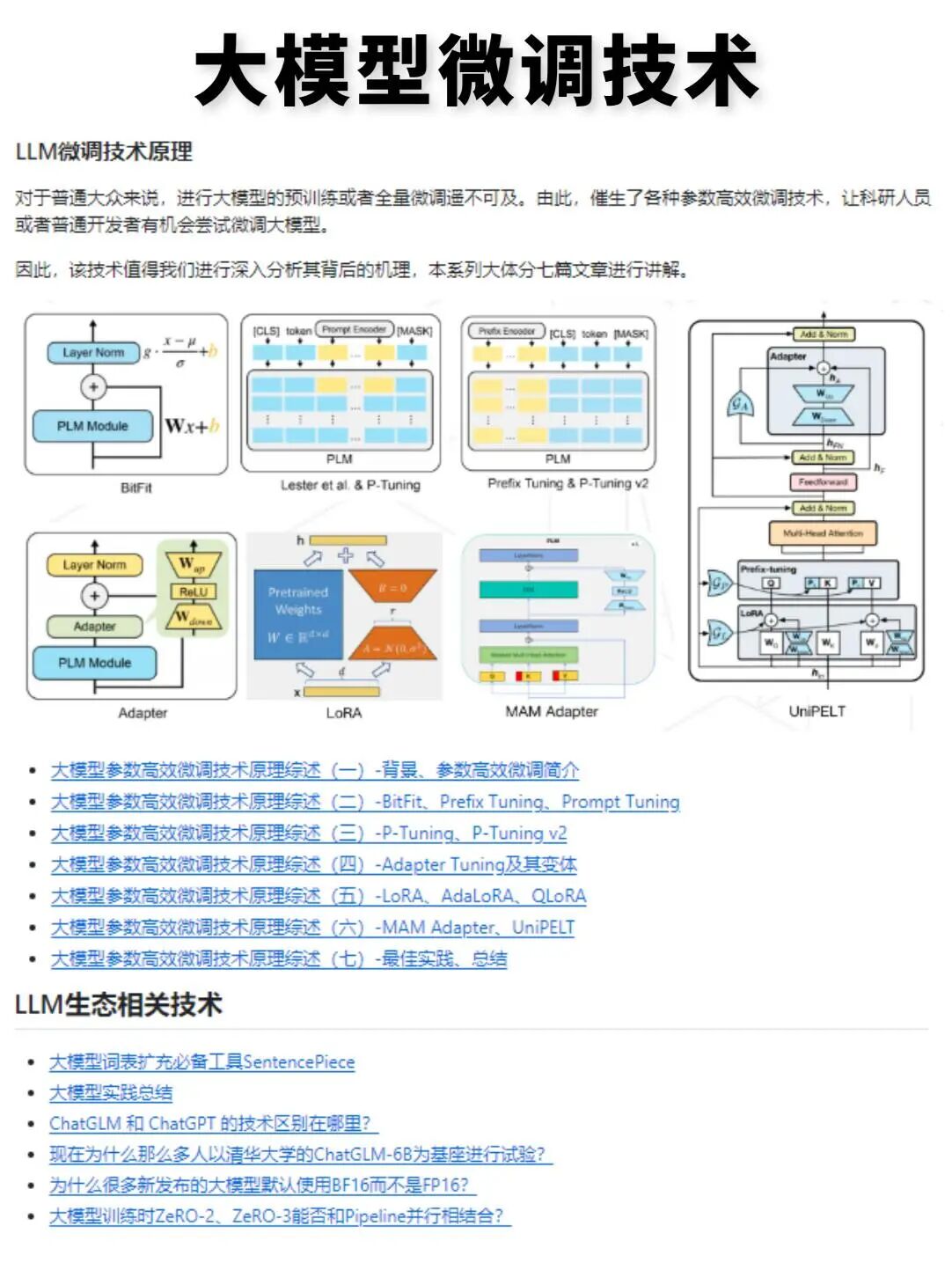
第三阶段:模型定制与部署(第7-9周) 进入微调(Fine-tuning)和私有化部署环节。虽然现在很多人说“不需要微调也能用好大模型”,但在实际工作中,企业往往需要针对特定业务场景优化模型表现。因此,掌握LoRA、QLoRA等高效微调方法,以及使用vLLM、FastAPI、Docker等工具完成本地或云端部署,是求职时的重要加分项。
第四阶段:项目实战与简历打磨(第10-12周) 最后三周集中做2-3个完整项目,比如基于RAG的企业知识库问答系统、支持多工具调用的AI Agent助手、或结合微调的垂直领域客服模型。每个项目都要有清晰的问题定义、技术选型、效果评估和可视化展示。这些项目不仅是学习成果的体现,更是面试时打动HR和面试官的关键素材。

三、信息差的本质:知道“该学什么”比“努力学”更重要
回顾整个过程,我最大的感悟是:在技术快速迭代的时代,方向比努力更重要。很多人不是不努力,而是努力错了方向。比如,花一个月死磕PyTorch底层实现,却忽略了Prompt Engineering这种能立刻提升产出效率的技能;或者沉迷于复现论文,却不了解企业真正需要的是能快速落地的解决方案。
而打破信息差的方法,其实很简单:找到已经成功的人走过的路,照着走一遍,再根据自身情况微调。不要迷信“自由探索”,尤其是在时间有限的情况下。系统化的课程、结构化的项目模板、真实的行业需求洞察——这些才是真正值得投资的资源。
结语
如今回头看,那三个月的高强度学习虽然辛苦,但每一步都踩在了关键节点上。正是因为及时纠正了学习策略,我才得以在竞争激烈的大模型赛道中脱颖而出。如果你也正在起步阶段,请记住:别再被碎片信息牵着鼻子走。制定清晰计划,聚焦核心技能,用项目验证能力——风口不会等人,但准备好的人,永远能抓住机会。
资源分享:


👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}