







我们在 Amazon Web Services re:Invent 2023 上预览的 Amazon Bedrock 模型评估功能现已正式上线。这项新功能可帮助您通过选择为您的特定用例提供最佳结果的基础模型,将生成式AI纳入您的应用程序。正如我的同事 Antje 在她的文章中解释的那样(在Amazon Bedrock中评估、比较和选择最佳基础模型以满足您的用例):
模型评估在开发的各个阶段都至关重要。作为开发人员,您现在可以使用评估工具来构建生成式人工智能 (AI) 应用程序。您可以从在游乐场环境中尝试不同模型开始。为了加快迭代速度,可以添加模型的自动评估。然后,当您准备进行初始发布或有限发布时,可以纳入人工评审以帮助确保质量。
在预览期间,我们收到了许多宝贵和有用的反馈,并将其用于完善这项新功能的特性,为今天的发布做好准备 —— 我稍后会讲到这些。快速回顾一下基本步骤(参考Antje的文章获取完整演练):
创建模型评估作业 —— 选择评估方法(自动或人工)、选择一种可用的基础模型、选择任务类型并选择评估指标。对于自动评估,您可以选择准确性、鲁棒性和有毒性;对于人工评估,您可以选择任何所需的指标(如友好度、风格以及品牌语音的遵循度等)。如果您选择人工评估,可以使用自己的工作团队,或者选择由 亚马逊云科技 管理的团队。有四种内置的任务类型,以及一种自定义类型(未显示):

选择任务类型后,您可以选择要使用的指标和数据集来评估模型的性能。例如,如果选择文本分类,您可以使用自己的数据集或内置数据集来评估准确性和/或鲁棒性:
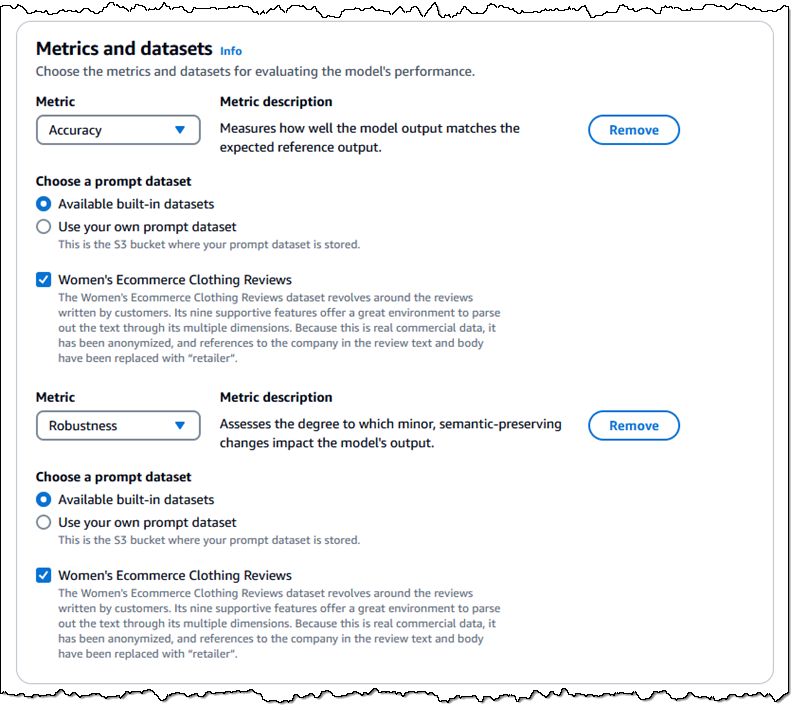
如上所示,您可以使用内置数据集,或者以JSON Lines (JSONL) 格式准备新的数据集。每个条目必须包含一个提示,并且可以包含一个类别。对于所有人工评估配置以及某些任务类型和指标组合的自动评估,参考响应是可选的:
{
"prompt" : "Bobigny是什么地方的首都",
"referenceResponse" : "Seine-Saint-Denis",
"category" : "首都"
}
您(或您的本地主题专家)可以创建一个使用特定于您的组织和用例的客户支持问题、产品描述或销售宣传材料的数据集。内置数据集包括 Real Toxicity、BOLD、TREX、WikiText-2、Gigaword、BoolQ、Natural Questions、Trivia QA 和 Women’s Ecommerce Clothing Reviews。这些数据集旨在测试特定类型的任务和指标,可根据需要进行选择。
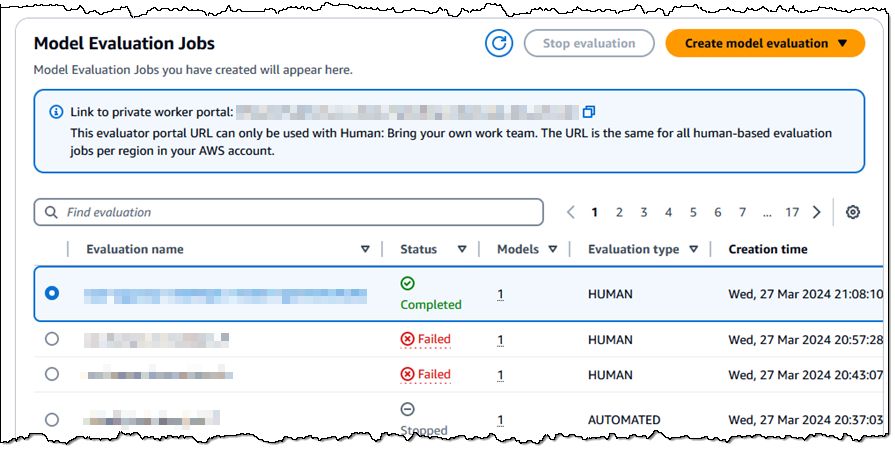
运行模型评估作业 —— 启动作业并等待完成。您可以从控制台查看每个模型评估作业的状态,也可以使用新的 GetEvaluationJob API 函数访问状态:
检索和查看评估报告 —— 获取报告并查看模型针对您之前选择的指标的性能。再次参考Antje的文章,以详细了解样本报告。
GA的新特性
话不多说,让我们来看看为今天的发布而添加的新特性:
改进的作业管理 —— 您现在可以使用控制台或新的模型评估API停止正在运行的作业。
模型评估API —— 您现在可以以编程方式创建和管理模型评估作业。以下函数可用:
- CreateEvaluationJob —— 使用API请求中指定的参数(包括evaluationConfig和inferenceConfig)创建并运行模型评估作业。
- ListEvaluationJobs —— 列出模型评估作业,可选择根据创建时间、评估作业名称和状态进行过滤和排序。
- GetEvaluationJob —— 检索模型评估作业的属性,包括状态(InProgress、Completed、Failed、Stopping或Stopped)。作业完成后,评估结果将存储在提供给CreateEvaluationJob的outputDataConfig属性中指定的S3 URI。
- StopEvaluationJob —— 停止正在进行的作业。一旦停止,作业将无法恢复,如果需要重新运行,必须重新创建。
这个模型评估API是预览期间最受欢迎的特性之一。您可以使用它大规模执行评估,也许是作为开发或测试您的应用程序的一部分。
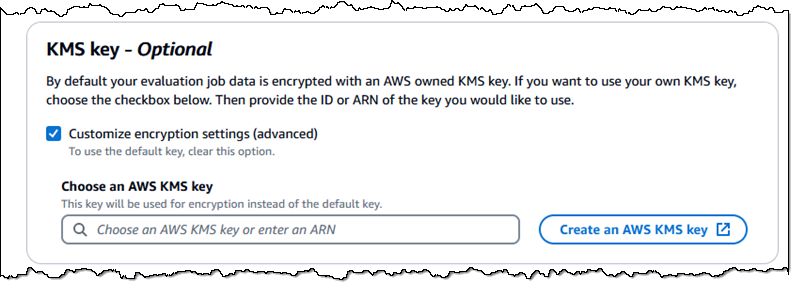
增强的安全性 —— 您现在可以使用客户管理的KMS密钥来加密您的评估作业数据(如果不使用此选项,您的数据将使用亚马逊云科技拥有的密钥进行加密):
访问更多模型 —— 除了来自 AI21 Labs、Amazon、Anthropic、Cohere 和 Meta 的现有文本模型之外,您现在还可以访问Claude 2.1:
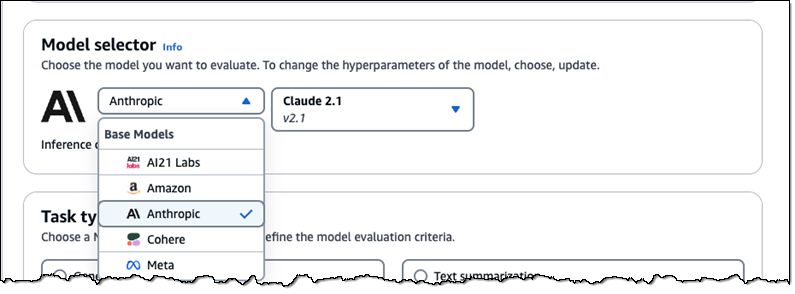
在选择模型后,您可以设置将用于模型评估作业的推理配置:
需要注意的事项
关于这一酷炫的新Amazon Bedrock功能,您需要注意以下几点:
定价 —— 您需为模型评估过程中执行的推理付费,不需为算法生成的分数额外付费。如果使用人工评估并采用您自己的团队,您需要为推理付费,并为每个已完成的任务(人工工作者在人工评估用户界面中提交一个提示及其关联推理响应的评估)支付$0.21。由亚马逊云科技管理的工作团队执行评估的定价基于您评估所需的数据集、任务类型和指标。更多信息,请查阅 Amazon Bedrock Pricing 页面。
区域 —— 模型评估在美国东部(弗吉尼亚北部)和美国西部(俄勒冈州)亚马逊云科技区域提供。
更多生成式AI —— 访问我们新的 GenAI空间,了解我们今天发布的这一内容以及其他公告!
— Jeff

Jeff Barr
Jeff Barr是亚马逊云科技首席布道师。他在2004年创办了这个博客,从那时起就一直在不间断地撰写博文。















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









