






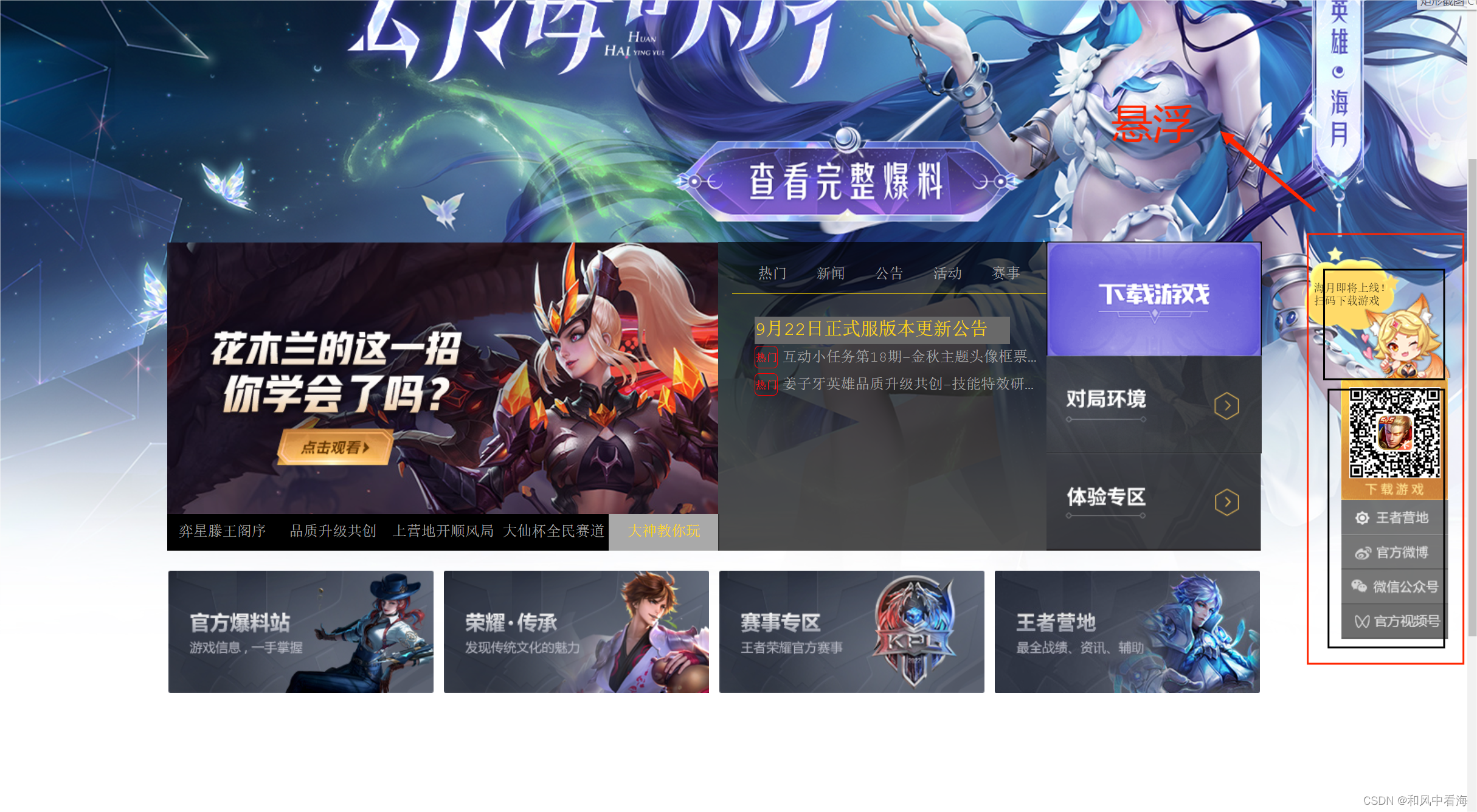
可以分为两个部分来完成:分为上妲己,下列表
悬浮需要先给body一个相对定位:position:relative,然后给悬浮模块盒子一个固定定位
Position:fixed,再给层级z-index:10,这里值越大说明层级越高,再给模块一个top:30%
使其与页面高度一直保持30%,再给妲己一个background-image,设置图片,background-repeat:no-repeat,图片不重复,再给绝对定位position:absolute
设置列表部分:给列表一个绝对定位position:absolute,设置宽高,用无序列表来完成下面的给li节点分别li:nth-child分别完成li的图片偏移。















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









