







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
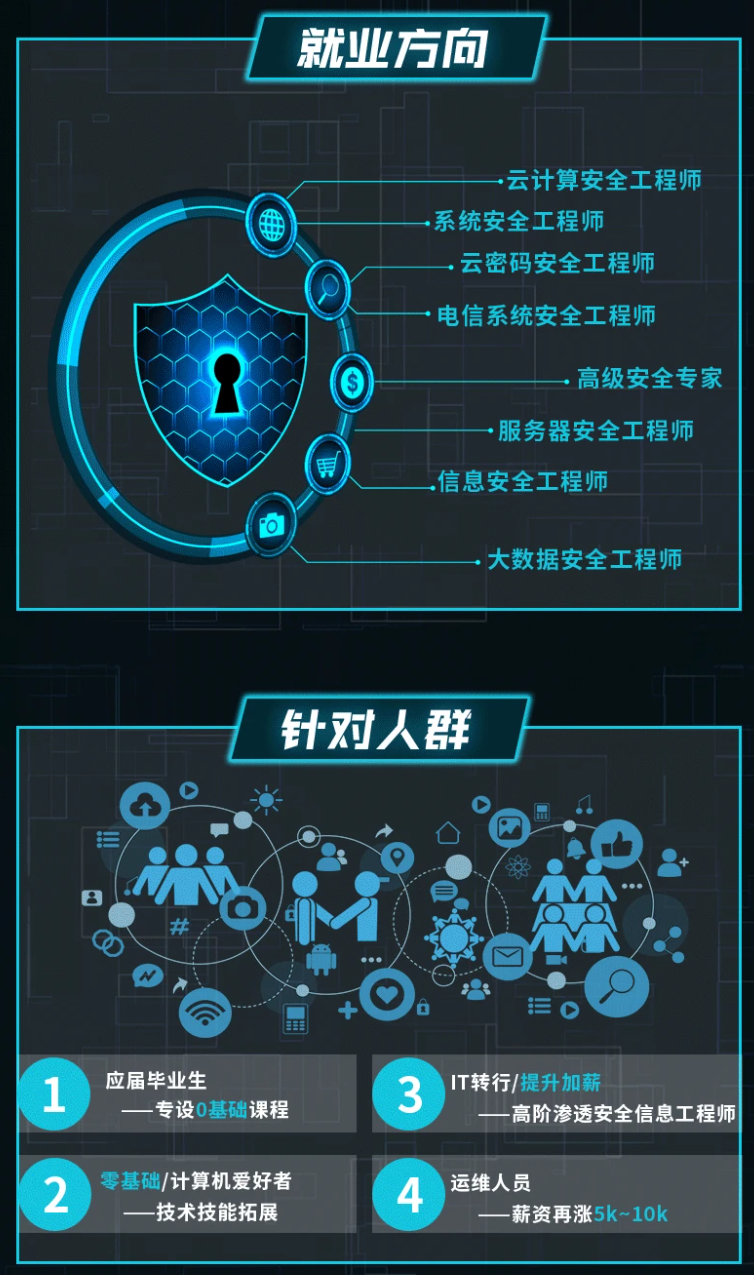
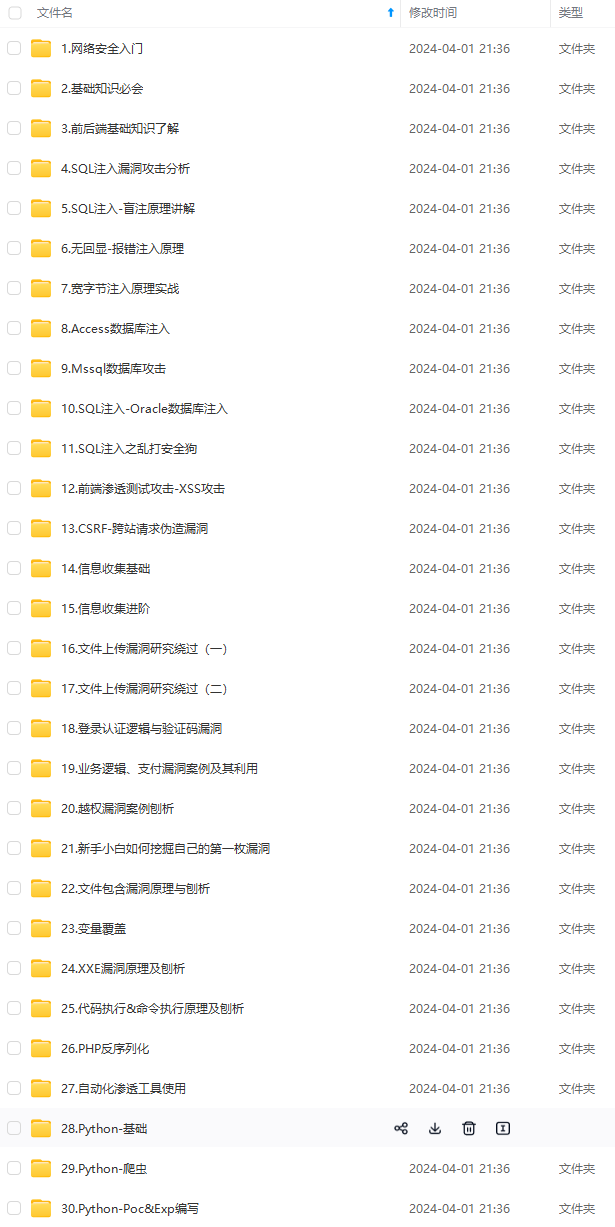
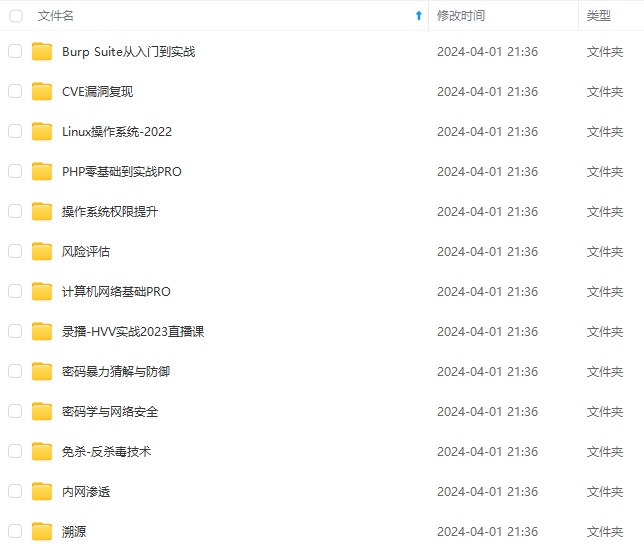
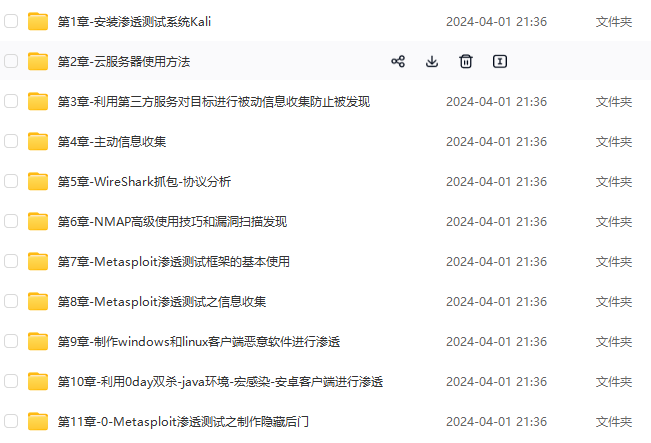
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
我导师直接一句话:“你实验了吗?出结果了再汇报。” ̄. ̄
我又马不停蹄回去做实验。ㄟ( ▔, ▔ )ㄏ
搭建完模型,没报错,OK!能跑通,nice!接下来就是见证奇迹的时刻啦!<( ̄︶ ̄)↗

(当时还很兴奋地跟同门炫耀)
然后。。。很快被打脸——不增反降!!!┗|`O′|┛ 嗷~~w(Д)w
我就想,一定是加的不够多,不够新。 ̄へ ̄
于是我就使劲加,玩命加,加加加!(▼へ▼メ)
结果就是越来越低。。。┗( T﹏T )┛
后来突然想到一个问题:
一个浑身戴着金银首饰、浓妆艳抹、穿得雍容华贵的女生,远远不如白T+牛仔裤,扎着马尾素面朝天的少女更得人心。

(图片源自《甄嬛传》,如有侵权立删)
不停地加改进方法反而会适得其反。
我开始一边实验一边摸索规律,总共进行了48次实验,才终于得到我想要的涨点效果!^o^/
接下来分享我实验中踩坑经历~
🌻2.1 实验平台
如果实验室没有足够强的设备,建议大家还是租服务器训练。
不要用自己的笔记本去硬扛,耗时间而且效果不好,出现意外又一切重来(别问我咋知道的)。
👍租服务器的方法看我这篇就好→手把手教你使用AutoDL云服务器训练yolov5模型-CSDN博客
这里不再过多阐述~
🌻2.2 数据集处理
现在很多论文都用到这点,也是我导师提出让我加的创新点。
因为我们做的是特殊的场景,一些公共数据集并不是所有图片都符合,另外还有一部分图像质量不高,所以要做一定的筛选。筛选一波过后数据集的数量可能就不是很够量了,那么就可以通过数据增强来扩充样本。
👍数据增强方法可以看我的这篇→YOLO数据集实现数据增强的方法(裁剪、平移 、旋转、改变亮度、加噪声等)
另外,还可以选取多个数据集,将模型在每个数据集上都跑一遍,这样也可以成为一组对比实验,更有说服力。
🌻2.3 Backbone(特征提取)的替换
主干网络是模型的核心,影响着模型的速度和精度。
目前主干网络可以分为三类:
- **传统CNN:**VGG-16、ResNet-50、DenseNet等等
- **轻量级CNN:**MobileNet、EfficientNet、ShuffleNet、GhostNet等等
- **ViT系列:**Swin Transformer、Repvit、MobileViT等等
传统的CNN网络精度高但参数量巨大,计算慢,如果场景对精度要求非常高且不用管速度可以使用;
轻量级CNN参数量小,速度提升非常多,但是精度下降也很多;
ViT系列参数量也很大,建议大家如果选择ViT系列作为主干网络选择轻量级的,如MobileViT。
具体怎么选取,要根据自己实际场景和数据集的需要。
总的来说,对于现在的趋势,主干网络的选取规则:
使主干网络在提取特征时能够获取更多的有用信息,尽量保持精度的前提下,避免过度地使用轻量化骨干网络而导致精度的损失。
👍本人主干网络替换系列:
YOLOv5改进系列(5)——替换主干网络之 MobileNetV3
YOLOv5改进系列(6)——替换主干网络之 ShuffleNetV2
YOLOv5改进系列(9)——替换主干网络之EfficientNetv2
YOLOv5改进系列(10)——替换主干网络之GhostNet
YOLOv5改进系列(19)——替换主干网络之Swin TransformerV1(参数量更小的ViT模型)
YOLOv5改进系列(21)——替换主干网络之RepViT(清华 ICCV 2023|最新开源移动端ViT)
YOLOv5改进系列(22)——替换主干网络之MobileViTv1(一种轻量级的、通用的移动设备 ViT)
YOLOv5改进系列(23)——替换主干网络之MobileViTv2(移动视觉 Transformer 的高效可分离自注意力机制)
🌻2.4 Neck(特征融合)的更换
在YOLO中,Neck端主要负责融合不同层级的特征图,并提供更高层次的语义信息。
在YOLOv5s原模型中使用经典的**FPN+PAN(自上而下和自下而上相结合)**的特征金字塔网络,然而,这种网络会削弱了非相邻提取层的融合效果,导致特征信息的丢失或退化。
因此在实验时我们常常会更换Neck端。常用的有:
- **BiFPN:****加权双向特征金字塔。**加强特征图的底层信息,使不同尺度的特征图进行信息融合,从而加强特征信息。
- **AFPN:渐进特征金字塔。**以渐进的方式将低层特征与高层特征的语义信息和详细信息直接相互融合,避免了多级传输中的信息丢失或退化,提高特征尺度的不变性。适用于提高小目标的漏检率。
- **CARAFE:**轻量级通用上采样算子。具有感受野大、内容感知、轻量级、计算速度快的特点。适用于移动设备检测任务。
- **EVC:****中心化特征金字塔。**关注不同层之间的特征交互,还考虑了同一层内的特征调节。适用于密集预测任务。
- **增加小目标层:**参考多尺度特征图的特征信息,同时兼顾了较强的语义特征和位置特征。适用于小目标较多的数据集。
本人Neck端更换系列:
🌻2.5 添加注意力机制
注意力机制是块宝,现在绝大部分论文里改进模型都添加注意力机制。
不了解注意力机制的可以先看看这篇→【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解_注意力机制和自注意力机制的区别
BUT,
“增加注意力机制一定涨点吗?”
“那么多注意力机制我该选哪个?”
“注意力机制要添加到哪个位置? ”
“注意力机制是加的越多越好吗?”
这些是我文章评论区最常见的问题,今天谈谈我个人理解(不对请指正)
🎄**(1)增加注意力机制不增反降问题**
YOLO算法旨在通过全局特征来预测边界框和分类结果,而不是依赖于局部特征。再一个,YOLO算法本身已经足够强可以应对目标检测任务。
注意力机制是让模型更加关注一张图像中某个区域更细节特征,所以对于YOLO算法来说,可能还不如不加。但是对于一些其他任务,例如图像分割或者更细粒度的分类问题,注意力机制可能会表现出更好的效果。
另外,引入注意力机制也会增加模型参数量,可能会导致训练和推理过程变得更加慢。
除此之外,加入注意力机制不增反降还有可能是以下原因:
(1)数据集过小(300张以内的就不要加了)
(2)添加位置不对
(3)数据集和选用的注意力机制相克(比如小目标不适用加CBAM)
(4)过拟合和欠拟合
🎄**(2)注意力机制的选取问题**
这个问题就像我每次吃自助一样,五花八门的美味盛宴,光是看也看不出那个最好吃,得尝一尝才知道。有可能今天想吃个甜口,觉得小蛋糕最好吃,但明天可能就想吃炸串红烧肉了,后天可能觉得海鲜才是自助之王。。。一抬头,到吃午饭点了(★ ω ★)。
(咱先继续唠,怕我回来灵感没了,废寝忘食ing。。。)
所以总结就是,注意力机制没有谁好谁坏,只是看哪个更适合你自己的数据集,你需要亲自尝试。
常见注意力机制:
- SE:在通道维度增加注意力机制,关键操作是squeeze和excitation。
- **CBAM:由通道注意力机制(channel)**和 **空间注意力机制(spatial)**组成。
- CA:通过精确的位置信息对通道关系和长期依赖性进行编码,具体操作分为Coordinate信息嵌入和Coordinate Attention生成 2个步骤。
- ECA:****通道注意力机制的一种实现形式,是基于SE的扩展。
- SimAM:一种无参数注意力模块,只使用了一个全局池化层和几个全连接层。
- SOCA:可训练二阶注意力模块,通过使用二阶特征统计来自适应地重新调整信道方向特征,以获得更具鉴别性的表示。
- EMA:高效多尺度注意力模块,通过新的跨空间学习方法融合两个并行子网络的输出特征图,设计了一个多尺度并行子网络来建立短和长依赖关系。
🎄**(3)注意力机制的位置问题**
🌲1.首先加在Backbone部分
也就是要加在特征提取那里。因为Neck端的作用是对特征进行融合,Head是基于特征进行预测。在这两个阶段特征已经提取完毕,如果我们这个图像本身提取的特征就不太好,那么在这后面两个阶段再努力也始终有一定的局限。基础不牢,地动山摇。
所以,注意力机制通常加在Backbone部分,这样才能提取到更好的特征,提升上限。
🌲2.SPPF(池化层)前后问题
像我最初的几篇,SE、CBAM、ECA等,是加在SPPF上一层的。
首先是作者实验(用ResNet)源码就是放在这个位置上的。
再一个就拿CBAM举例,它包括空间和通道注意力,这两个主要都是利用全局平均池化将feature map的特征抽象到一系列点注意力权重,然后建立这些权重的联系并附加到原空间或通道特征上。如果加在后面,就会引起过拟合了。
其实这些通道注意力,都不适合加在靠近输入端或者靠近head层的地方,这样反而会降点,最近研究ViT,发现self-attention也差不多。
空间注意力放在网络前面,通道注意力放在后面。
🌲3.如果要加在Neck部分
Neck可以根据数据集的特征加在大中小三层,具体看你的更需要注意力机制关注哪个层特征。
emmm,你们看晕了没?
其实我觉得吧,这些理论知识是我个人理解+大佬经验分享整合的,大家了解个大概就行,它不是百分百正确的定理,有可能同一个模块别人加这个位置好使,你加就降点。所以啊,还是需要大家自己做实验滴~(这就是为啥我实验了48次orz)
🎄**(4)注意力机制数量问题**
通过上面安小鸟的例子,大家应该也明白,这玩意儿再好,也不是越多越好。
先不说随意加反而影响全局效果,别忘了,注意力机制也是有参数的,引进过多会导致模型复杂、计算量大。
另外,我还真有一个朋友这么试了,审核人的意见是:**“**存在技术方案以复杂结构实现简单功能、采用常规或简单特征进行组合或堆叠等明显不符合技术改进常理的行为”。
注意力机制这块真的特有意思,等我以后研究研究有啥新发现了再来补充。(‘ω’)/
👍本人添加注意力机制系列:
🌻2.6 改进IoU
大家先看看IoU介绍,我先去吃个饭~
👍IoU详解→损失函数:IoU、GIoU、DIoU、CIoU、EIoU、alpha IoU、SIoU、WIoU超详细精讲及Pytorch实现
其实每个的特点文章介绍的很清楚了,我也没有做过多实验,总结一下,还是亲自试一试。
👍本人改进IoU系列:
YOLOv5改进系列(11)——添加损失函数之EIoU、AlphaIoU、SIoU、WIoU
YOLOv5改进系列(17)——更换IoU之MPDIoU(ELSEVIER 2023|超越WIoU、EIoU等|实测涨点)
🌻2.7 改进NMS和激活函数
因为我的实验没涉及这两块,所以这里先留个坑,以后有经验了再来填。
想尝试的同学可以看我之前教程:
👍本人改进激活函数教程:
YOLOv5改进系列(13)——更换激活函数之SiLU,ReLU,ELU,Hardswish,Mish,Softplus,AconC系列等
👍本人改进NMS教程:
YOLOv5改进系列(14)——更换NMS(非极大抑制)之 DIoU-NMS、CIoU-NMS、EIoU-NMS、GIoU-NMS 、SIoU-NMS、Soft-NMS
🌻2.8 优化参数
作为一个炼丹师,我本来想尝试一下调参,无奈高估了自己。
这本来就是玄学中的玄学,干嘛为难我这个小白?!o(TヘTo)
哈哈,开玩笑,其实到这时我的实验已经成了,于是调参这块没有过多研究,和大家分享一些大佬们的文章吧,希望有帮助呀~
**总结一下,没有trick可以绝对涨点,实验必须根据自己的数据集亲自做,不增反降是常态,每一次尝试总结加进一步摸索,慢慢地就有经验了,祝大家都能高效涨点!**❤️

🚀三、如何写论文?
很多时候实验好不容易做出来了,但是论文却迟迟无法下笔,说的是不是你?
反正不是我(傲娇脸.jpg)
也许是我一直做论文带读博主的原因,刚开始写论文的时候,要写哪几部分?每部分怎么写?整个框架清晰地出现在我脑海里。网上大部分论文带读只讲网络结构,省略摘要、引言等等,后来想想我立志要做全网最详细的博主,所以每次全篇逐段讲解。轮到我自己写的时候,就自然而然有思路了。
**在学习的道路上,每一份付出都有回报,也许现在看不到任何成果,但在你今后的人生里,它会像一个礼物一样突然出现,也许这就是努力的意义吧!**❤️
鸡汤结束,我们言归正传~
⭐3.1 Abstract—摘要
论文摘要就是整篇文章和浓缩预览,它被排放在论文的首要位置,也是审稿人首先看的地方。
公式:研究的目的和重要性**+研究的方法+得到的研究结果****+结论**
⚡️At:
- 摘要是一整段
- 不要在摘要里出现感情色彩的评价
- 一般在200-300字左右,具体看期刊
⭐3.2 Introduction—引言
引言的作用就是系统性地向读者介绍该篇论文的研究背景、创新点、采用理论及方法等,核心是吸引读者阅读,通常是对于全文内容的高度概括!
公式:背景和需求+介绍之前研究方法+ 前人研究(并指出不足)+本文的贡献
① 背景和需求:先写为什么要研究这个领域,介绍人们对大的领域、行业、学科等背景问题有何期待,说明实现这些期待对背景问题的重要性。通常采用的是一般现在时、现在完成时或现在进行时。
② 介绍之前研究方法:其次介绍这个领域的常见研究方法,并且一步步缩小这个领域的范围一直到自己的那个层次。具体文献综述部分通常采用一般过去时,其他高度概括部分或常识介绍部分通常采用一般现在时或现在完成时。
③ 前人研究(并指出不足):第三就是写之前大佬在该领域怎么研究的也就是研究现状,并且说明存在什么问题没有解决(自己解决了)。通常采用的是一般过去时或现在完成时。
④ 本文的贡献:最后引出自己的东西,说明自己解决了什么问题作出了什么贡献,论文余下部分是如何安排的。通常采用的是一般现在时。
可以想象一个镜头,由远慢慢拉近到你眼前的感觉。
⚡️At:
- 避免背景介绍遗漏,提到的关键信息都要有说明,详略得当
- 避免段与段之间逻辑混乱
- 引用文献要是最新的
⭐3.3 Related Work—相关工作
相关工作时详细地写和自己最相关的研究,但不是一味地说之前的工作做了什么,主要说清楚我们提出的算法和之前算法有何不同,为接下来讲故事做铺垫。
就那最新带读的MobileViT v3举栗子:
它就是先将ViT,再介绍CNN,最后介绍近来两者混合的一些研究。
⚡️At:
- 不要罗列论文,而是从一个整体上介绍其思想,可以展开这些论文思路上的差异。
- 可以依据相关性,递进式分类地介绍相关工作,或者总分形式。对于每类工作都要点出其主要共性问题,以及本文所提出的对应解决方案。
- 前期的调研要充分,并且做的过程中也要关注最新的文章,做到一半发现idea撞车了就比较麻烦了。
- 如果是技术类的相关工作,一定要体现为了把该技术应用到本领域所做出的改进,而不能是仅仅将该技术迁移到本领域,具体看你咋讲故事了。
⭐3.4 Method—方法
(不同方向的Method写法不同,这里仅对深度学习的论文写作介绍)
Method这一部分是记录你的研究基础和研究方法,就是非常详细的介绍你的创新点。一般采用总—分形式:先画出你搭建的模型,然后总体介绍,接下来再逐一介绍创新点。
**总:**单独一段介绍你的搭建模型,用到了哪些方法,概括地介绍就行。然后画出模型的总体网络结构图(我导是建议再加上方法流程图)。
分:接下来就是分小节逐一、详细地介绍每个方法(创新点)。首先介绍前置的知识、算法结构、流程(可以用伪代码表示)、公式、网络结构图、为什么这么设计等等,没有绝对的格式,最终的目的是为了说清楚算法的设计思路,让别人能够看懂。
⚡️At:
- 方法介绍大家可以先去读原论文(了解前置知识),然后扒源代码(了解网络结构和算法流程),最后自己就很清楚了。
- 不知道该怎么总结可以看看同样使用这个方法的论文(搜关键字就能找到,只看这一块就行),学学大佬是如何介绍的。
- 写法上可以去网上找现成的英文模板,表达更为高级。
⭐3.5 Experiments—实验
(不同方向的Experiments写法不同,这里仅对深度学习的论文写作介绍)
实验这一块用我导的话来说就是:“其实你啥都做好了,只要把它们描述出来就行。”
在实验写作之前,先确保我们基本上把论文的实验数据全都整理出来了,这样我们就可以根据现有的实验结果,直接来描述实验结果就行~
实验基本三个部分:实验设置(Experimental Setting/Experimental Setup/Implementation details)、对比实验(Comprason with previous method/ Comprason with other method/ Comprason with prior work)、消融实验(Ablation Study)
✨**(1)实验设置(Experimental Setting/Experimental Setup/Implementation details)**
- 实验配置
- 实验参数
- 实验数据集
✨**(2)对比实验(Comprason with previous method/ Comprason with other method/ Comprason with prior work)**
按任务分:
- 图像分类(Image Classification)
- 目标检测(Object Detection)
- 实例分割(Semantic Segmentation)
需要做哪些对比?(Comparison with…)
1.不同模型的对比
以YOLOv8举栗子:
首先和同YOLO系列对比:YOLOv5/v6/v7(v4以下就没必要了),然后和其他深度学习模型RCNN系列、SSD、RT-DETR等等(YOLOv8 的代码库目前是可以训练 YOLOv5/v6/v8和 RT-DETR 的,直接换个 yaml 就训练了),以及两三个前人的实验。
放几篇优秀论文大家可以感受一下:
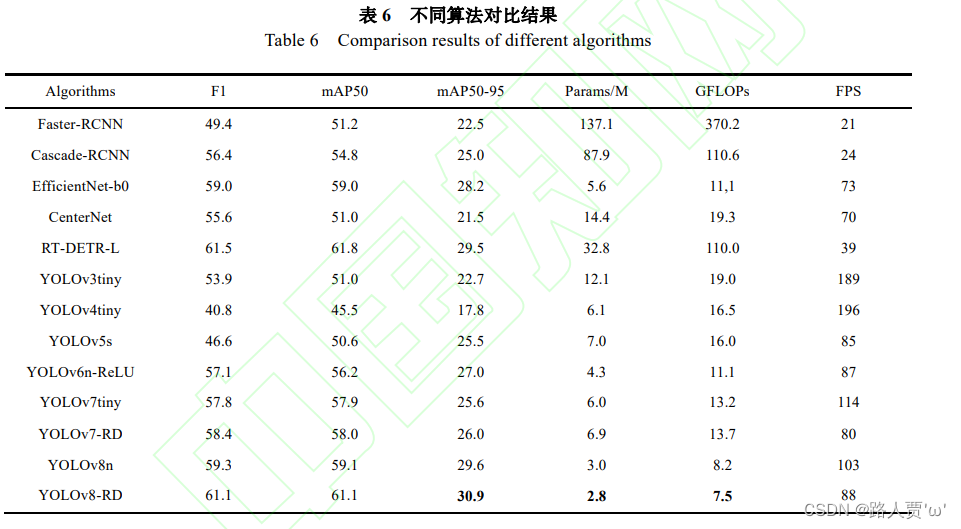
(对比不同算法)
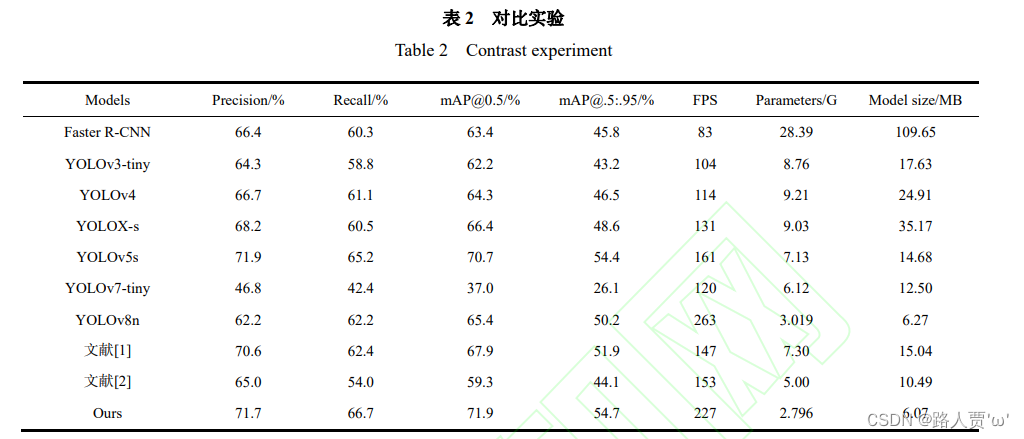
(引用前人文献)

(对比多个尺寸)
2.方法对比
这部分要和前面Method方法做一个呼应,目的就是证明你选择的方法是有效的。
举个栗子,你选择了CA注意力机制,就可以和CBAM、SE、SOCA等等做个对比。
还是看几篇优秀论文:
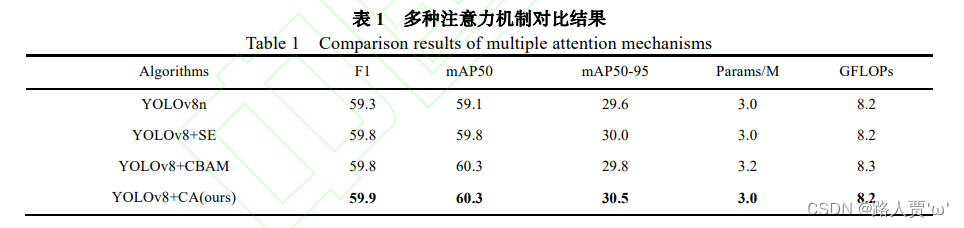

⚡️At:
- 个人感觉这部分就是夸,各种吹你的方法如何好、如何创新等等
- 如果你的论文的结果是state-of-the-art,那么你就可以把标题取为 Comprason with state-of-the-art
✨**(3)消融实验(Ablation Study)**
这部分是对你改进的各个模块进行具体的分析,目的是验证每个模块的有效性。
在深度学习中,特别是复杂的深度神经网络的背景下,通常采用“消融实验”来描述去除网络的某些部分的过程,以便更好地理解网络的行为。
举个栗子:
为了提升网络的性能,在网络架构上加了模块A,B两个方法,是这篇文章的创新点。
比如说这篇文章有3个亮点,消融实验就负责告诉你,
- 实验1:我只加A结果如何;
- 实验2:只加B结果如何;
- 实验3:A和B都加了又如何。
看3个实验的效果,然后结果可能是,实验1和实验2的结果都不如实验3,那么说明A、B都是有用的。
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
nimg.cn/img_convert/3fd39c2ba8ec22649979f245f4221608.webp?x-oss-process=image/format,png)
网络安全工程师企业级学习路线
如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。
一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









