






1. 前言
基于ID Embed主导的传统深度推荐系统, 在新冷内容推荐上由于新冷内容用户行为非常稀疏, ID Embed欠学习导致经常表现不佳。因此, 对于这部分新冷内容, 业界一般会更多的结合内容(如本文讨论的多模态信息)本身来做推荐。但是, 将多模态信息应用于推荐系统可能会面临两个挑战:
-
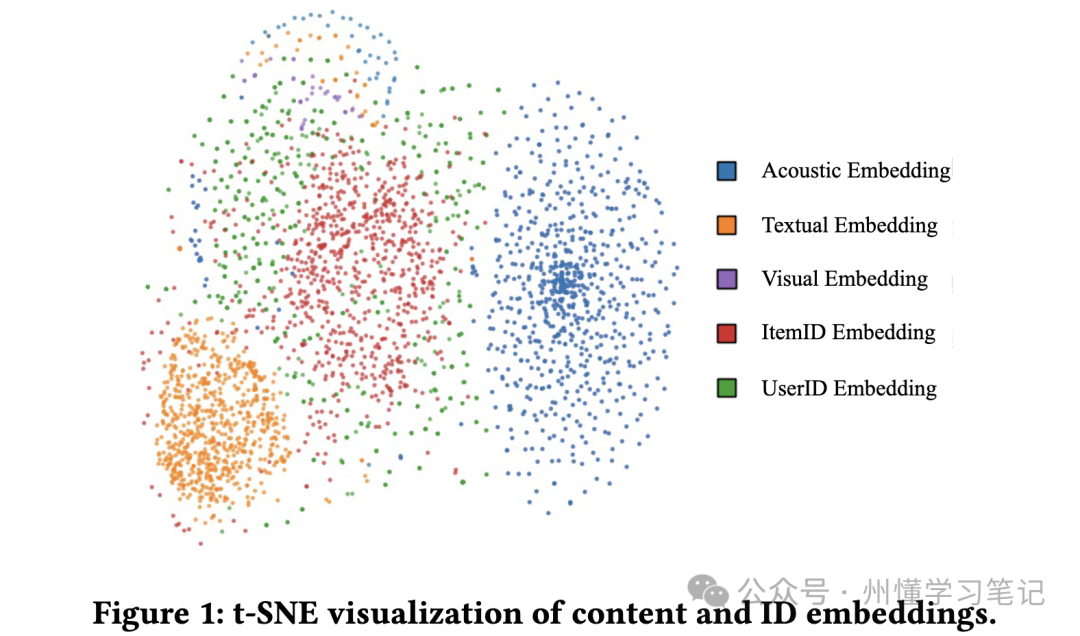
表征空间不一致问题: 推荐系统的ID Embed是用户行为(协同过滤)驱动的, 而一般的多模态表征(如使用Bert的文本表征)是基于内容本身来学习的, 它们的表征空间是不一致的, 是有Gap的。而这也是业界大家一般不会将ID Embed与多模态原始表征直接Concat的主要原因。
-
用户对多模态的偏好不一: 这个也很好理解, 就比如有些人喜欢一首歌曲是因为歌曲动听的旋律, 而有些人喜欢一首歌曲可能是因为歌曲的歌词让人共情。而快手这里则提出要显式建模用户对内容的不同模态(文本、视觉和音频)的不同偏好。
为了克服这两个问题, 快手提出了M3CSR方法, 下面详细介绍。
2. 方法
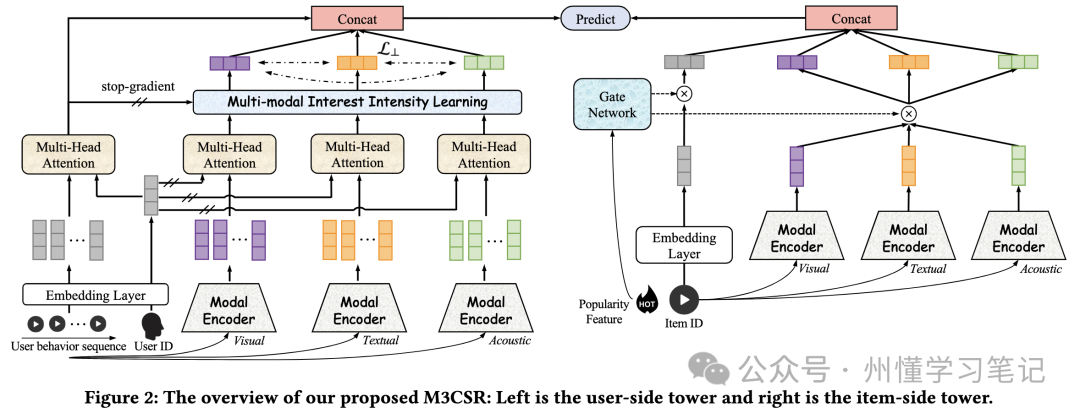
快手所提方法的整体框架如下图所示, 其主体框架是双塔结构, 在User塔和Item塔都引入了多模态信息以提升新冷内容推荐上的效果。
2.1 预处理
快手这里的多模态推荐遵循着业界的一般实践, 也是一种Two-Stage方案。即对于新内容, 会先提取出多模态表征存下来, 然后再使用这预先提取的多模态表征用于下游推荐任务的学习。
快手所提方法在预处理阶段, 主要处理两个事情:
1. 多模态表征提取
对于新内容, 快手这里会基于内容的三种模态提取出三种模态表征:
-
对于文本模态: 使用Sentence-BERT提取文本表征,记为
-
对于视觉模态: 使用ResNet提取视觉表征,记为
-
对于音频模态: 使用VGGish提取音频表征,记为
2. 多模态聚类
在获取视频的多模态表征后, 快手这里还会做-means聚类处理以得到新视频的聚类ID信息。具体地, 作者将多模态表征都concat起来, 再使用数千万的多模态表征做-means聚类, 共1000个聚类中心, 每个新视频都可以得到对应的聚类中心标签。
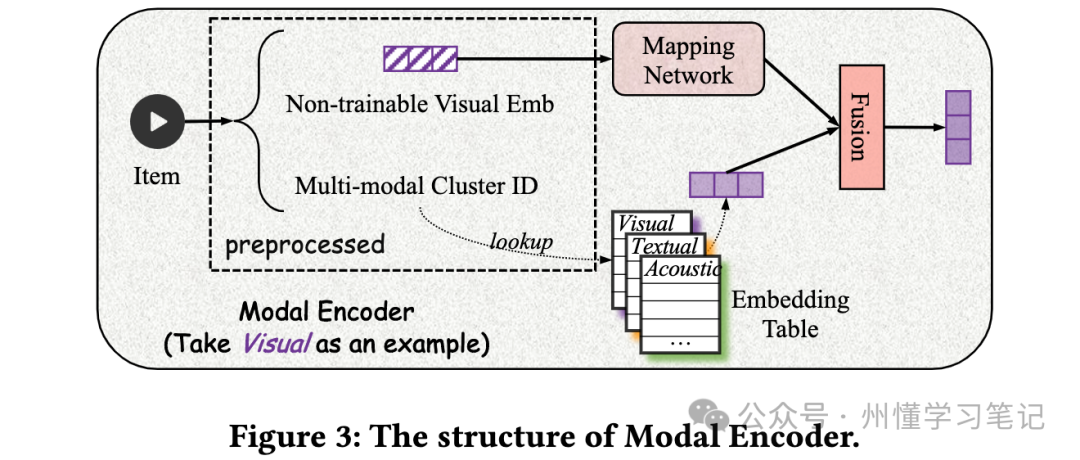
2.2 模态Encoder
模态Encoder包含两个操作, 如下图所示:
-
降维映射: 对于每种模态表征, 单独过个映射网络函数, 实现模态空间到用户行为空间的映射, 记映射后对应模态的表征为。笔者去年DataFun推荐峰会上也提出同样的方法, 在这问题上, 看来大家都想到一块去了。
-
多模态聚类处理: 前面提到, 每个短视频都对应着一个聚类ID, 这样可以再过个embedding layer, 将聚类ID转换成低维的可学习的隐向量, 这种方式的好处是它的聚类ID Embed是可学习的, 以克服原始多模态Embed不可学习的缺点。
然后, 再将这两个表征做Fusion(其实就是直接Concat起来)作为内容最终的多模态表征, 形式化描述如下:
其中, 和是模态的映射矩阵参数。
2.3 User塔处理
2.3.1 用户序列建模
在User塔的序列建模上, 一方面, 会正常使用ID Embed做多头注意力计算:
其中, 表示用户历史交互序列的Id Embed。
另一方面, 作者会使用前面融合计算出的文本、图片、音频的多模态表征, 分别计算多头注意力:
这里, ID Embed会作为多头注意力计算的Query, 它是Stop Gradient的, 而为对应模态的模态表征, 会作为多头注意力的Key和Value。可以看出, 这种方式其实是让ID Embed去引导多模态表征的学习映射过程。
2.3.2 用户多模态兴趣强度
考虑到不同用户对不同模态的兴趣偏好/强度可能会有差异, 作者还使用了基于ID计算出来的注意力结果去做多模态注意力结果的缩放, 具体地:
首先, 计算各模态表征的缩放因子(兴趣强度)
再将对应的多模态表征进行缩放
然后, 再将缩放后的多模态表征与ID Embed直接Concat起来作为User 塔最后的表征
2.4 Item塔处理
考虑到新冷内容的ID Embedding可能学习不充分, 因此, 作者这里引入受欢迎程度的门控网络来控制ID Embed和多模态Embed的表达, 让热门内容更多依赖ID Embed, 而新冷内容则减少ID Embed, 以使在冷启阶段更好的捕获内容的多模态信号, 具体的:
作者使用了视频的交互次数来做分桶, 使用可学习的分桶embed, 即上面的。
其实, 理想情况下, 笔者认为使用Item被参与训练的次数作为这里门控机制的输入会可能会更合适, 因为离在线的可能存在的一些diff, 热门的Item在推理时它的Item Embedding可能学习的也不充分。可能这个被参与训练的次数信息在获取会比较麻烦, 但确实是可以直接在框架层去实现的, 笔者前阵子就借鉴LogQ实现了对应的方案, 有兴趣的同学也可以试试这个思路。
最后, 将门控的权重加上再拼接起来后, 就得到Item塔最后的表征:
2.5 训练与预测
对于多模态表征, 作者额外增加了多模态间的约束:
预测时, 令, 然后计算BPR Loss:
最终的Loss为:
其中, 和为对应的超参。
3. 实验部分
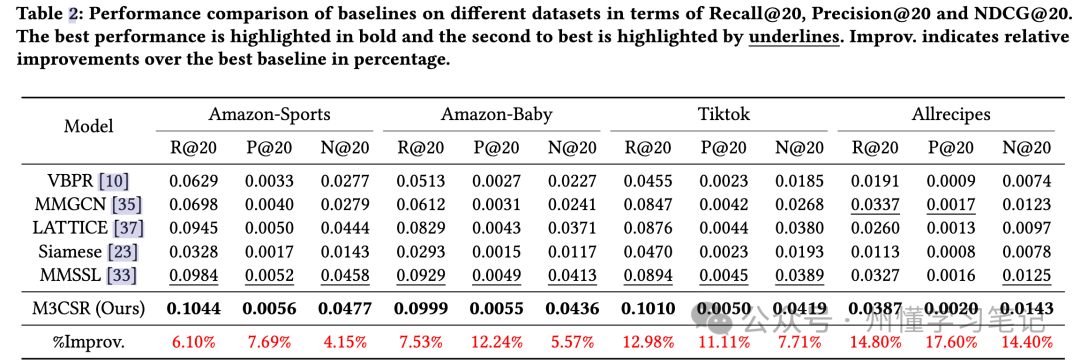
3.1 整体效果
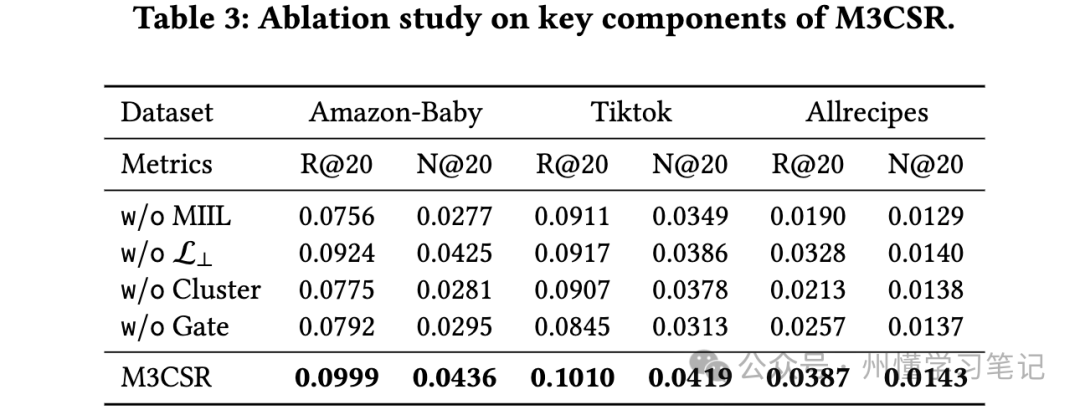
3.2 消融实验
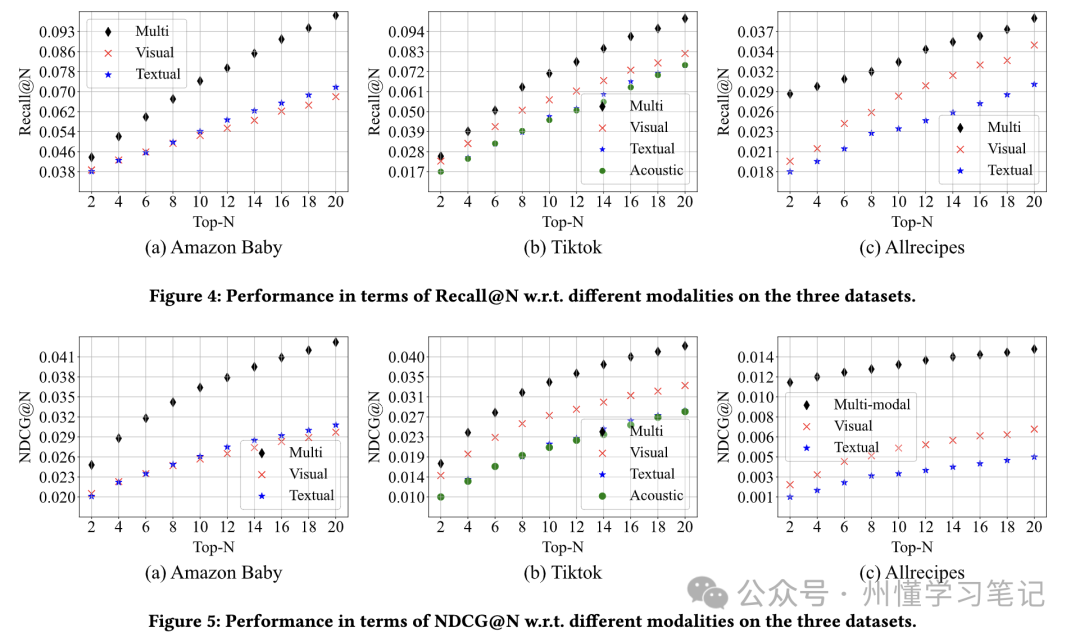
3.3 不同模态的对比
不同数据集上不同模态重要程度不一
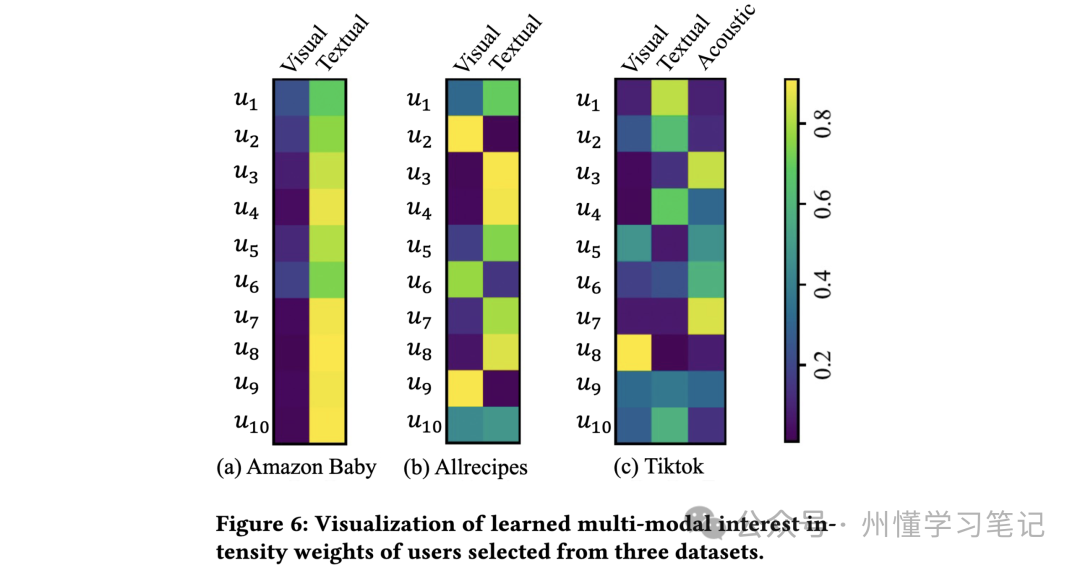
3.4 兴趣强度可视化
3.5 线上实验
新冷内容的表现

3.6 Case Study

AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









