






有朋友提到,在项目中调用 deepseek api 是花钱的,既然能在本地搭建私有知识库了,能否调用本地呢?答案是肯定的!
本次小栈将deepseek部署本地,并通 python 调用本地的 deepseek 模型 api,实现本地 AI 驱动智能问答,让使用者不受网络的限制,让开发的过程变的更加方便。
本地环境
系统环境
windows 10、windows 11
软件环境
Pycharm 2024(Professional 版)
Python 3.9.16
这两个是基础软件,安装过程在这里就不再赘述。
本地部署deepseek
1. 下载Ollama并安装
首先,打开网站
https://ollama.com/下载:
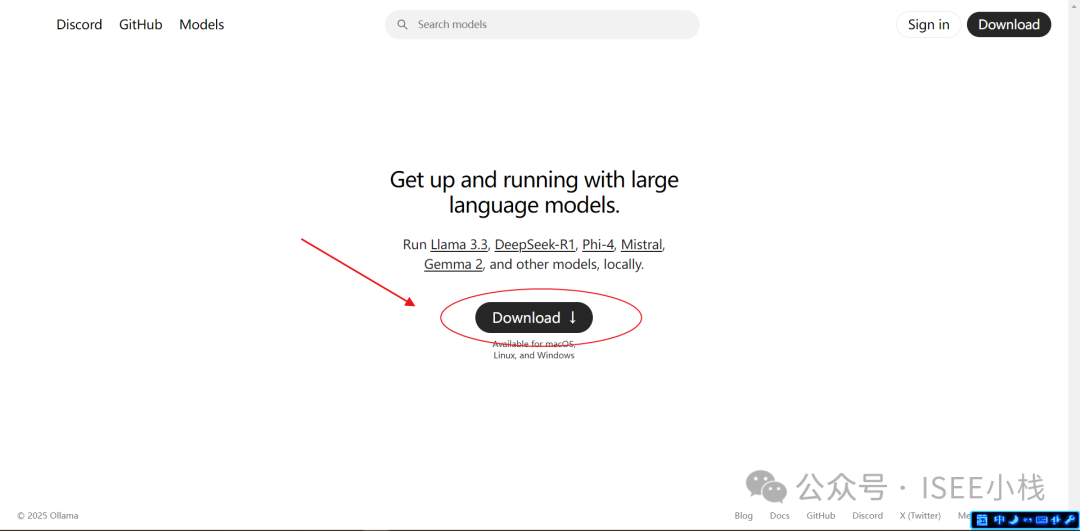
选择与系统匹配的版本
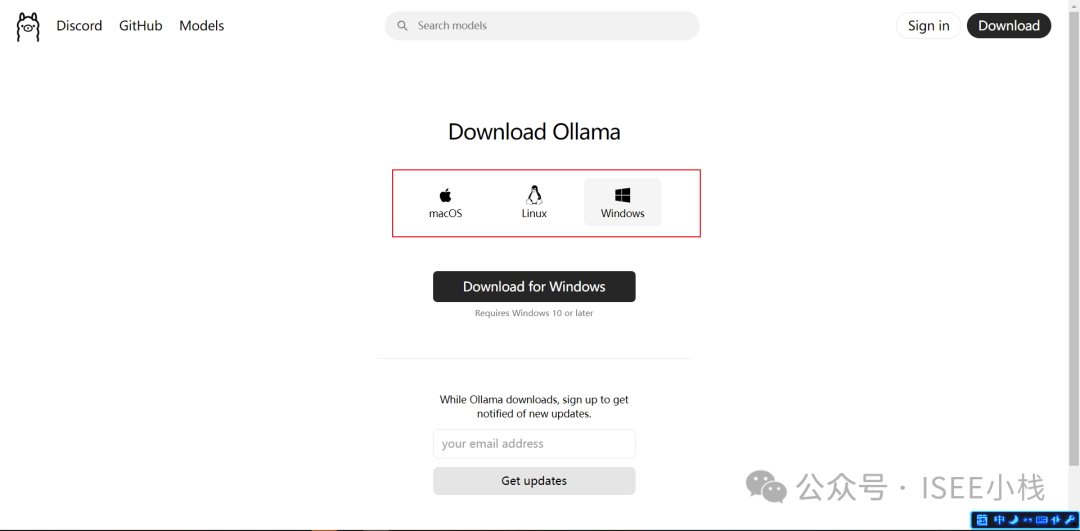
小栈是 windows 系统,本次就以此为例
安装:
找到下载的Ollama软件

右击 【以管理员身份运行】

点击【Install】默认安装即可
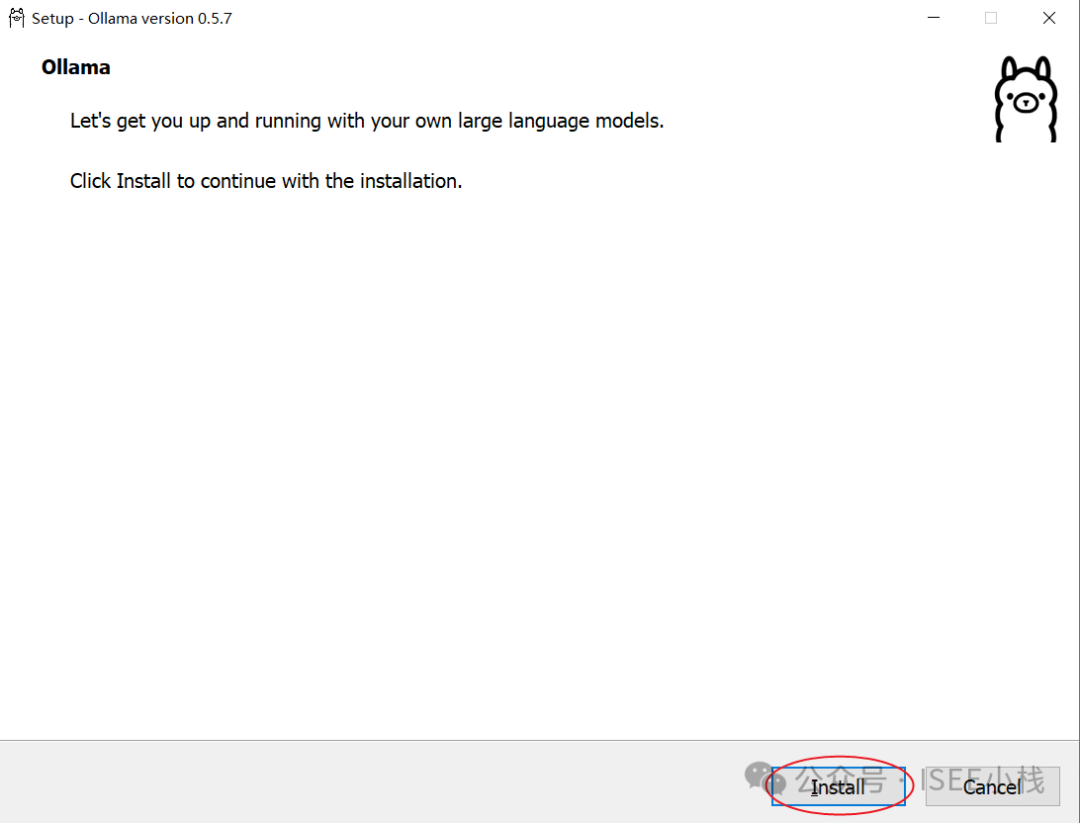
安装过程完全是自动的,安装完成后,在cmd命令窗口输入ollama list命令

由于电脑并没有安装过其他的,刚安装ollama现在执行这条命令应该是空的,这个已经表明安装成功!
2. 下载DeepSeek-r1模型
我们先看以下deepseek的版本,打开Ollama官网,点击左上角菜单【Models】
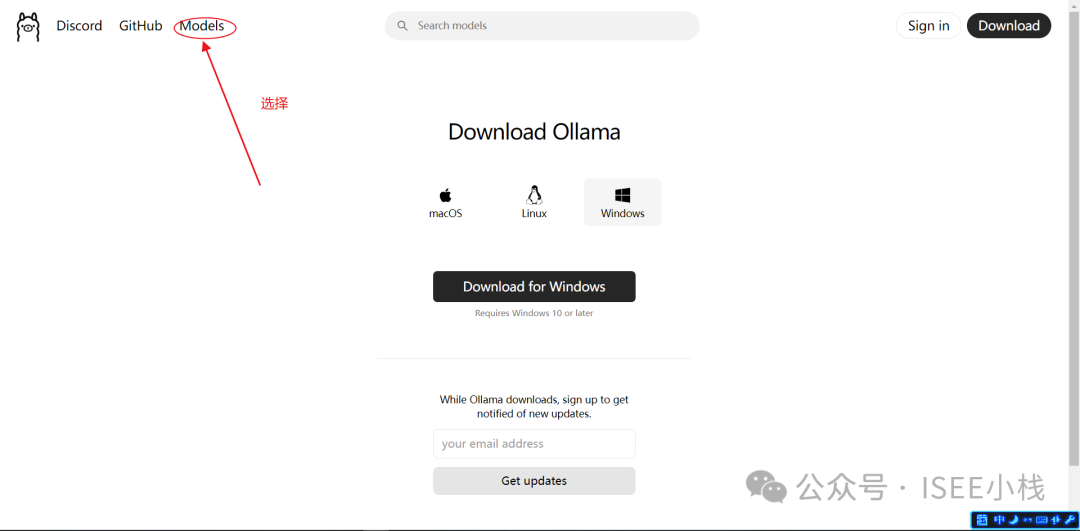
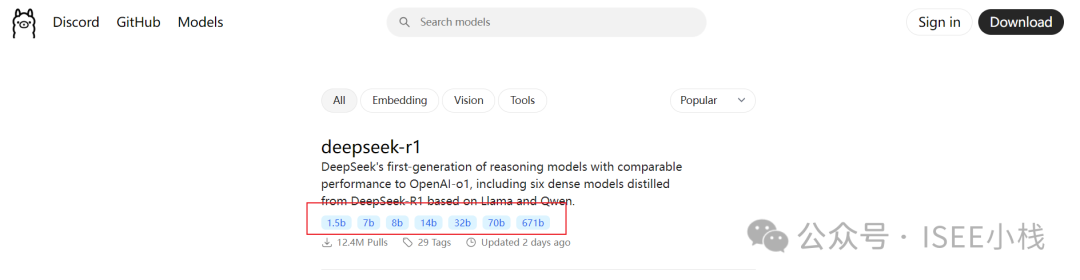
deepseek-r1 目前一共有7个不同版本,随着尺寸参数变大对电脑要求也会变高,电脑没有大显存GPU的朋友,推荐安装1.5b的。
这版尺寸,即使是无GPU的普通电脑也能流畅运行。
如果电脑配置较高,建议更高版本的,使用效果会非常好!
小栈电脑就使用个1.5b的试一下,我们进行deepseek详细版本页面,复制命令
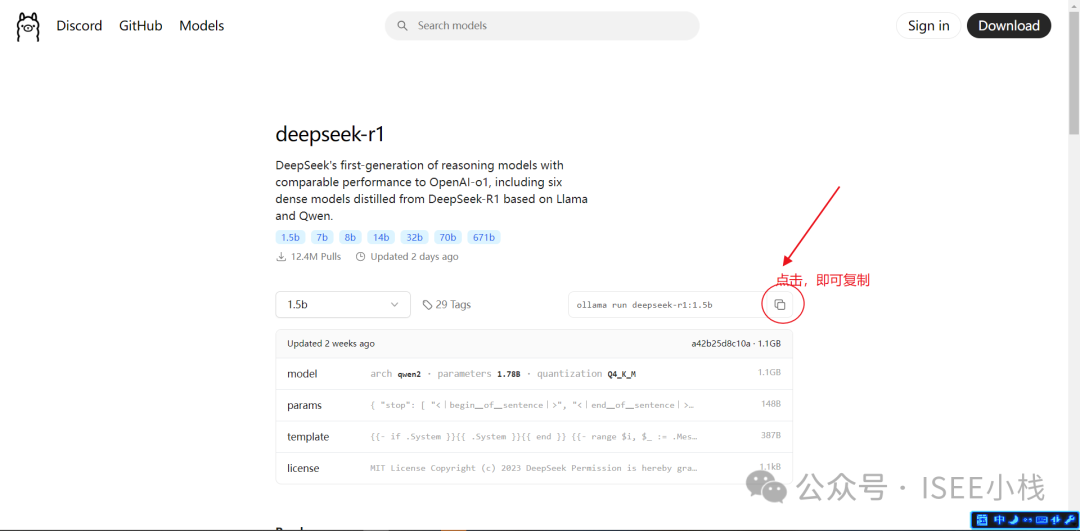
打开电脑cmd命令窗口
输入安装命令:
ollama pull deepseek-r1:1.5b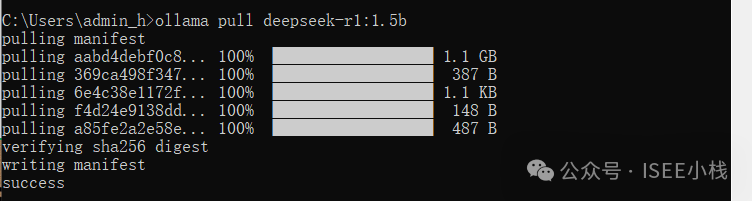
大约等10分钟左右的时间
出现success,则已经安装完成
3. 使用及验证
安装完成后,我们来使用,验证一下效果
在cmd命令窗口输入
ollama run deepseek-r1:1.5b
出现 Send a message,这个就是输入问题的地方
我们可以直接在这里提问
比如提问:“通过Python做数据分析,我们重点需要掌握哪些方面?请列出最核心的5个”
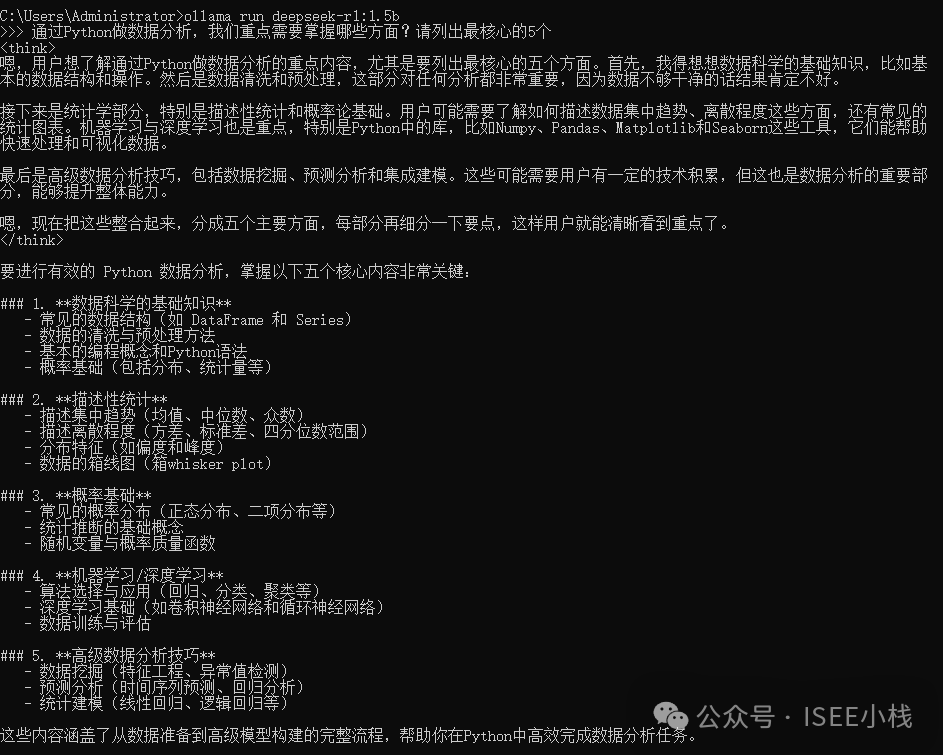
到这里,本地部署的模型就完全成功了!
Python代码调用
通过代码的方式调用本地模型api,其实非常简单,本质上就是向本地部署的ollama发出请求,最后得到反馈。
在这里,小栈分享常见的两种方式,都是用非流式返回,就是等模型回答完毕,最终返回一个总的结果:
一是利用 requests 方式请求,
二是使用 ollama 方式请求,
我们来简单看一下!
1. requests
首先,安装三方库
pip install requests==2.32.3具体实现:
import requests# API的URLurl = 'http://127.0.0.1:11434/api/chat'# 发送的请求数据体data = {"model": "deepseek-r1:1.5b","messages": [{"role": "system", "content": "你是一个资深的数据分析专家"},{"role": "user","content": "数据分析专家是一名具有丰富的分析经验的专业人士,掌握数据挖掘、数据分析、数据可视化等技能。那么掌握数据挖掘需要用到的技术和工具,请列出5-10种"}],"stream": False}try:# 向ollama发起POST请求response = requests.post(url, json=data)response.raise_for_status() # 检查请求是否成功result = response.json() # 直接解析响应的json内容# 输出响应内容print(result['message']['content'])except requests.exceptions.HTTPError as http_err:print(f"HTTP错误发生: {http_err}")except requests.exceptions.ConnectionError as conn_err:print(f"连接错误发生: {conn_err}")except requests.exceptions.Timeout as timeout_err:print(f"请求超时: {timeout_err}")except requests.exceptions.RequestException as req_err:print(f"请求错误发生: {req_err}")except KeyError as key_err:print(f"解析响应时发生键错误: {key_err}")except Exception as err:print(f"其他错误发生: {err}")
结果:
<think>好,我现在需要帮用户列出一些在数据挖掘过程中会用到的技能和技术。用户提到了数据分析专家,这让我想到他们可能希望看到的是具体的操作步骤或相关技术。首先,用户提到要列出5-10种,所以我要确保数量适中,不太多也不太少。接下来,我应该考虑数据分析的不同阶段,比如预处理、建模和优化这些部分,这样能够全面覆盖各种可能性。在预处理方面,数据清洗是个基本的步骤,数据缺失处理是后续操作的基础。接下来,特征工程也很重要,因为它影响到模型性能,需要详细讲解特征提取方法。分组分析也是必须涵盖的内容,因为它可以帮助发现模式或趋势。模型训练和评估同样不可忽视,这部分包括数据分割、算法选择、参数优化等,这些都是数据挖掘中非常常见的步骤。之后是模型应用与优化,确保模型在实际场景中的表现良好是关键。最后,部署与监控可以告诉我们如何持续改进,这是一个重要的方面。现在,我需要将这些点组织成结构化的回答,并且使用清晰的术语,比如预处理、特征工程、分组分析等。这样用户就能一目了然地看到在数据挖掘过程中涉及的各种技术。总的来说,我需要确保列出的技能和工具都是数据挖掘过程中核心的部分,并且覆盖了从预处理到部署的各个阶段,帮助用户全面了解所需的技术。</think>以下是掌握数据挖掘时常用的技能和技术:1. **数据清洗与预处理**- 数据缺失值的处理(插值、删除等)- 特殊值的识别和处理(异常值检测)- 不完整或不一致的数据校验2. **特征工程与提取**- 标准化与归一化(z-score, min-max)- 文本分类与抽取关键字段(NLP技术)- 时间序列数据的特征提取- 特征组合与生成(e.g., 条件指数、主成分分析)3. **分组分析**- 数据分组的统计描述(均值、中位数、标准差等)- 分组可视化(柱状图、热图、箱线图等)- 预处理后的数据进行分组,以发现潜在模式或趋势4. **模型训练与评估**- 数据分割(训练集/测试集)- 决策树和随机森林的构建- 草费算法(如k-近邻、SVM)- 部分类分类器(例如LSTM用于时间序列数据)5. **模型优化与调优**- 参数网格搜索与交叉验证- 正则化技术(L1/L2正则化)- 特征选择的评估(AUC、F1-score等)6. **模型应用与部署**- 预测或分类模型的集成(比如XGBoost的堆叠)- 业务相关的阈值优化(如A/B测试)- 将数据预处理后的结果传输到业务系统7. **时间序列建模**- 平滑方法(如指数平滑)- SARIMA与ARIMA模型的构建与评估- 神经网络的时间序列预测8. **图像识别与分析**- 图像增强、分割与分类- 使用深度学习技术(如CNN)进行图像分析这些技术在数据挖掘过程中起到关键作用,帮助你预处理数据、提取特征、构建模型并评估其性能。
2. ollama
首先,安装三方库
pip install ollama==0.4.7具体实现:
from ollama import chatfrom ollama import ChatResponse# 定义一个函数来获取chat响应def get_chat_response():try:response: ChatResponse = chat(model='deepseek-r1:1.5b',messages=[{"role": "system", "content": "你是一个资深的数据分析专家"},{"role": "user","content": "数据分析专家是一名具有丰富的分析经验的专业人士,掌握数据挖掘、数据分析、数据可视化等技能。那么 数据可视化 需要用到Python的哪些技术呢?,请列出5-10种"}],stream=False)# 提取并返回answerreturn response.message.contentexcept Exception as e:# 更具体的错误信息输出print(f"在与模型交互时发生错误: {e}")return None# 获取并打印answeranswer = get_chat_response()if answer:print(answer)else:print("没有获取到有效的回答。")
结果:
<think>嗯,用户问的是关于数据分析中使用的Python技术,特别是数据可视化部分。我需要先回想一下自己对这些技术的理解。首先,数据可视化通常包括图表、柱状图、饼图等,这些在各种报告和展示上都很有用。然后,思考一下常用的高级库,like Matplotlib 和 Seaborn。它们都是用于数据绘图的Python包,能够制作各种图形,并且有很多调整选项,适合不同类型的图表。接下来是Matplotlib 的具体功能,比如绘制条形图、折线图,这些是最基础的可视化工具。如果用户有特定的数据类型,可能需要更专业的库,但基本功能应该是适用的。数据预处理也很重要,因为它影响最终的分析结果和数据可视化的效果。在使用高级库之前,先整理数据集,去重、归一化等步骤都是必要的。柱状图和饼图是经典的可视化工具,尤其是当数据类别较多时,饼图可能不够直观,而柱状图则能清楚地显示每个类别的数值差异。这些图表通常放在项目中作为关键展示点。高级的图形库比如Tableau 和 Power BI 也能用于数据可视化,不过用户可能更关注Python中的技术。如果数据集很大,使用高级库可能会导致内存问题,所以需要考虑数据量和处理效率。最后,机器学习中的可视化工具,如ROC曲线、混淆矩阵等,虽然不是传统的数据可视化,但在分析模型时同样重要。这些工具帮助更好地理解模型的表现和效果。综上所述,我应该列出 Matplotlib 和 Seaborn 的基本功能、柱状图与饼图的常见应用、数据预处理步骤,以及在不同场景下使用的高级库,如 Tableau 或 Power BI,以满足用户的需求。</think>在 Python 中进行数据分析时,数据可视化是一个非常重要的部分。以下是涉及 Python 技术用于数据可视化的一些关键点和常用方法:1. **Matplotlib 和 Seaborn**- **基本功能**:使用 Matplotlib 绘制各种基础图表(如条形图、折线图、饼图等),并结合 Seaborn 的高级库进行更复杂的统计图表。- **常见应用**:柱状图、饼图、散点图等。2. **数据预处理**- 在使用高级绘图库之前,通常需要对数据集进行整理(如去重、归一化)和格式调整(如转换为分类变量或计算指标),以确保后续可视化效果更好。3. **柱状图与饼图**- **柱状图**:用于展示不同类别之间的数值差异。- **饼图**:用于展示各部分在整体中的占比,通常建议用 Seaborn 的 pie 函数而不是 Matplotlib 的 pie 函数,因为后者更容易控制颜色和格式。4. **高级图表库(如 Tableau 和 Power BI)**- 如果数据集较大或需要更高级的可视化效果,使用这些工具可能更有帮助。不过它们并不属于 Python 的基础技能。5. **机器学习中的可视化工具**- 在评估和解释模型时,可以绘制 ROC 曲线、混淆矩阵等图表,帮助更好地理解模型的表现。### 总结在 Python 中进行数据分析时,数据可视化需要结合 Matplotlib 和 Seaborn 等高级绘图库。此外,柱状图、饼图以及数据预处理步骤也是关键部分。这些技术可以帮助用户更直观地展示和分析数据,从而支持更深入的业务洞察。
总结
deepseek模型是本地部署的,无论是直接使用,或是通过 api 方式使用,都不会产生额外的费用,这种方式比较适合那种在只有内部网络的环境下使用,不受网络限制,还可以在项目中嵌入使用模型辅助的某些功能。
有朋友会有疑问,都是内部网络了,那如何下载与部署呢?这个小栈前期也分享过,如果有需要,可以看看
通常在内部网络的环境中,设备的配置应该不低,小栈建议可以下载部署高版本的模型,使用效果会非常好,比如像 deepseek-r1:70b、deepseek-r1:671b 这样的

,哈哈!
当然,这不是消耗资源,而是资源充分使用,还可以提高效率,你觉得呢?

两小段代码简单,也不多,有需要也分享,后台回复ollama_api即可获取!
注:本文分享的只是deepseek模型是这样使用,其实这种方式不限于此,本地部署的其他模型也可以这样使用哟,有兴趣的可以试试!

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









