






构建一个可用于生产环境的 RAG 系统需要经过一系列精心设计且反复迭代的步骤:
-
数据清洗与准备:首先要对数据进行清洗和整理,然后测试不同的数据切分策略,包括传统方法和逻辑方法,以确定最适合具体应用场景的方案。
-
匿名化处理:通过去除敏感或无关信息,匿名化步骤有助于减少模型的幻觉(hallucinations)。
-
子图构建:为了进一步提升检索器(retriever)的性能,可以构建子图(subgraphs),帮助检索器聚焦于最相关的信息,同时过滤掉噪声。
-
规划与执行系统:在检索层之上,我们引入了一个由大模型驱动的规划与执行系统。它类似于一个智能代理,能够从之前的步骤中学习,并决定下一步的行动。
-
性能评估:最后,当 RAG 系统生成响应后,我们会使用一系列指标对其性能进行评估。
在本文中,我们将从零开始,逐步展示如何构建这样一个完整的 RAG 系统。
我们将使用 LangChain、LangGraph 和 RAGAS(评估工具),模拟真实世界的挑战,并展示开发者在构建 RAG 机器人时可能遇到的实际问题及其解决方案。
所有代码均可在我的 GitHub 仓库中获得:https://github.com/FareedKhan-dev/complex-RAG-guide
目录
-
理解我们的 RAG 流水线
-
环境搭建
-
数据切分策略(传统 / 逻辑)
-
数据清洗
-
数据重构
-
数据向量化
-
构建上下文检索器
-
过滤无关信息
-
查询重写
-
思维链(COT)推理
-
相关性检查与事实依据
-
测试 RAG 流水线
-
使用 LangGraph 可视化 RAG 流水线
-
子图方法与知识蒸馏
-
构建用于检索与蒸馏的子图
-
构建用于解决幻觉问题的子图
-
创建并测试计划执行器
-
重新规划的逻辑思考
-
创建任务处理器
-
问题的匿名化与去匿名化
-
编译与可视化 RAG 流水线
-
测试最终流水线
-
使用 RAGAS 进行评估
-
总结回顾
理解我们的 RAG 流水线
在开始编写代码之前,我们先直观地了解一下 RAG 流水线的整体结构。随着后续步骤的推进,我们会逐步对每个组件进行可视化展示。
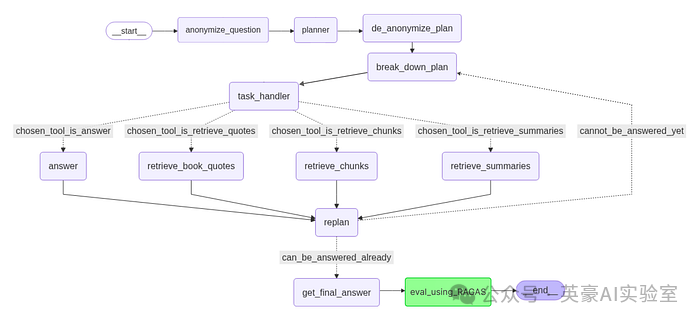
我们的 RAG 流水线,Fareed Khan 制作
首先,我们调用anonymize_question函数。这一步会将具体的人名(例如“哈利 · 波特”、“伏地魔”)替换为占位符(如人物X、反派Y),以避免大模型预训练知识带来的偏见。
接下来,planner(规划器)会制定一个高层次的策略。例如,对于问题“X是如何击败Y的?”,规划器可能会制定如下计划:
-
确定
X和Y的身份 -
找到他们最终对决的地点
-
分析
X的行动 -
撰写答案草稿
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

接下来,我们运行de_anonymize_plan函数,将匿名的名称还原为真实名称,使计划变得具体且可用。更新后的计划会传递给break_down_plan,后者将每个高层步骤细化为具体任务。
随后,task_handler会为每个任务选择合适的工具,可用工具包括:
-
chosen_tool_is_retrieve_quotes:查找具体的引文或对话片段 -
chosen_tool_is_retrieve_chunks:获取一般信息和上下文 -
chosen_tool_is_retrieve_summaries:对整章内容进行摘要 -
chosen_tool_is_answer:在已有足够上下文时直接给出答案
使用检索工具(如retrieve_book_quotes、retrieve_chunks或retrieve_summaries)后,新获取的信息会发送给replan。
replan会审视当前进度、目标和新输入的信息,以决定是否需要更新或扩展计划。
上述循环task_handler -> tool -> replan会不断重复,直到系统判断问题can_be_answered_already(已经可以回答)为止。此时,get_final_answer会综合所有证据,形成完整的回答。
最后,eval_using_RAGAS 会检查答案的准确性和来源忠实度。如果通过检查,流程以 __end__ 结束,输出经过验证、推理充分的答案。
环境搭建
LangChain、LangGraph 等模块共同构成了一个完整的 RAG 系统架构。
为了更好地学习,我们只在需要时才导入相应模块。
首先,我们需要创建环境变量,用于存储敏感信息,如 API 密钥等。
# 从环境变量中设置OpenAI API密钥(用于调用OpenAI的LLM)
# os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
# 从环境变量中设置Together API密钥(用于调用Together AI的LLM)
os.environ["TOGETHER_API_KEY"] = os.getenv('TOGETHER_API_KEY')
# 从环境变量中获取Groq API密钥(用于调用Groq的LLM)
groq_api_key = os.getenv('GROQ_API_KEY')
这里我们使用了两个 AI 模型提供商。Together AI 提供开源模型,这些模型在大多数 RAG 系统中广泛使用,因其成本效益高(开源模型通常更便宜)。
Groq 和 Together AI 都提供免费额度,足够你跟随本教程进行探索和实践。
Groq 的输出结构非常清晰。不过,如果你能优化提示模板,引导 LLM 生成结构化输出,甚至可以完全不使用 Groq,而仅依靠 Together AI 或 Hugging Face 的本地 LLM,尤其是 LangChain 生态系统本身就具备丰富的功能支持。
数据切分策略(传统 / 逻辑)
首先,我们需要一个数据集。RAG 管道通常使用大量原始文本数据构建,这些数据一般为 PDF、CSV 或 TXT 格式。然而,文本数据的挑战在于,它们通常需要大量清理工作,每个文件可能都需要不同的处理方式。
我们将使用《哈利 · 波特》系列书籍作为数据集,这些书籍包含各种字符串格式问题,更贴近真实场景。你可以从这里 (https://github.com/sukanyabag/QnA-Langchain-VectorDB/blob/main/Harry%20Potter%20-%20Book%201%20-%20The%20Sorcerers%20Stone.pdf) 下载书籍。下载完成后,我们可以开始第一步,即对文档进行拆分。

哈利 · 波特书籍的示例页面
下面我们定义 PDF 文件的路径。
# 数据路径(哈利·波特电子书)
book_path = "Harry Potter - Book 1 - The Sorcerers Stone.pdf"
在对数据进行 RAG 预处理或清理之前,最关键的一步是对文档进行合理且符合传统习惯的拆分。
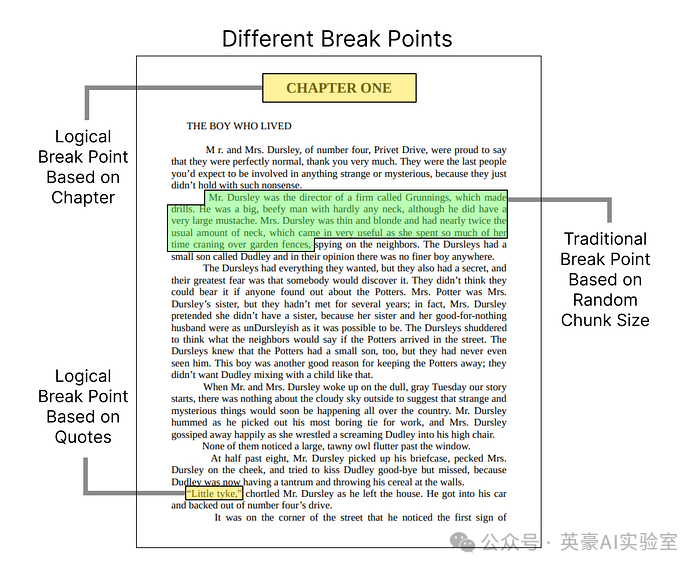
数据的不同拆分点示意图,Fareed Khan 制作
在我们的案例中,这本 PDF 电子书由多个章节组成,因此最合适的逻辑拆分方式就是按章节进行拆分。下面我们就来实现这一点。
首先,我们需要将 PDF 文件加载为一个完整的文本字符串:
import re
import PyPDF2
from langchain.docstore.document import Document
# 以二进制模式打开并读取PDF文件
with open(book_path, 'rb') as pdf_file:
# 创建PDF阅读器对象
pdf_reader = PyPDF2.PdfReader(pdf_file)
# 提取所有页面的文本,并合并为单个字符串
full_text = " ".join([page.extract_text() for page in pdf_reader.pages])
既然我们决定以章节为单位拆分 PDF,我们可以使用正则表达式来实现。下面定义一个合适的正则模式:
# 使用章节标题作为分隔符,将全文拆分为多个部分
# 正则模式匹配以"CHAPTER"开头,后跟大写单词的标题
chapter_sections = re.split(r'(CHAPTER\s[A-Z]+(?:\s[A-Z]+)*)', full_text)
通过上述正则模式,我们可以轻松地将整本书的文本拆分成多个章节:
# 为每个章节创建Document对象
chapters = []
# 成对遍历章节标题和对应内容
for i in range(1, len(chapter_sections), 2):
# 将章节标题与其内容合并
chapter_text = chapter_sections[i] + chapter_sections[i + 1]
# 创建带有章节元数据的Document对象
doc = Document(page_content=chapter_text, metadata={"chapter": i // 2 + 1})
chapters.append(doc)
我们来打印一下总共提取了多少个章节,并查看一下章节内容的示例:
# 提取的章节总数
print(f"总共提取的章节数量:{len(chapters)}")
#### 输出结果 ####
总共提取的章节数量:17
这样,我们就从 PDF 中成功提取了 17 个章节。不过,通常情况下,我们不会只依赖单一的拆分方式,而是倾向于使用 3 到 4 个甚至更多的拆分点,以便更好地捕捉每个文本片段中的关键信息。
在我们的书籍案例中,引号(引用语句)是第二个重要的拆分点,因为引号通常包含了关键的总结性信息。而在财务文档中,重要的拆分点可能是表格或财务报表,因为它们包含了关键的数据。
接下来,我们再根据引号对文档进行一次新的逻辑拆分:
# 定义正则表达式模式,用于查找长度超过min_length字符的引号内容
# re.DOTALL允许'.'匹配换行符
min_length = 50
quote_pattern_longer_than_min_length = re.compile(rf'"(.{{{min_length},}}?)"', re.DOTALL)
# 初始化一个空列表,用于存储提取的引号文档
book_quotes_list = []
# 遍历每个章节文档,查找并提取引号内容
for doc in tqdm(chapters, desc="正在提取引号"):
content = doc.page_content
# 查找所有符合模式的引号内容
found_quotes = quote_pattern_longer_than_min_length.findall(content)
# 为每个找到的引号创建Document对象并添加到列表中
for quote in found_quotes:
quote_doc = Document(page_content=quote)
book_quotes_list.append(quote_doc)
我们先打印一下提取的引文总数,并随机抽取一条引文看看效果如何:
# 引文总数
print(f"提取的引文总数:{len(book_quotes_list)}")
# 随机打印一条引文的内容
print(f"随机引文内容示例:{book_quotes_list[5].page_content[:500]}...")
#### 输出结果 ####
提取的引文总数:1337
随机引文内容示例:Most mysterious. And now, over to JimMcGuffin ...
我们从书中一共提取了约 1300 条引文。接下来,我们再介绍一种常见的数据拆分方法——文本分块(chunking)。这种方法简单易行,开发者广泛使用。我们继续往下看:
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 1000 # 每个文本块的字符数
chunk_overlap = 200 # 相邻文本块之间重叠的字符数
# 创建一个文本分割器,将文档拆分为指定大小且有重叠的文本块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len
)
# 将清理后的文档拆分成更小的文本块,以便后续处理(如嵌入、检索)
document_splits = text_splitter.split_documents(documents)
我们可以简单地将数据拆分成小块,但 LangChain 提供了更强大的TextSplitter工具,能实现更多高级功能。
这里我们使用了递归字符文本分割器(Recursive Character TextSplitter),它能创建带有重叠的文本块。这种重叠设计使每个文本块都能与前后文本块保持一定的上下文联系。
print(f"拆分后的文档总数:{len(document_splits)}")
#### 输出结果 ####
拆分后的文档总数:612
现在,我们一共得到了612个文本块。到目前为止,我们已经以章节、引文以及传统的文本分块方法对数据进行了逻辑拆分。接下来,我们需要对数据进行清理。
数据清洗
我们查看一下某个章节的示例内容,发现字母之间存在大量额外的空格,这种情况会影响后续处理。因此,我们将使用正则表达式(regex)去除这些多余空格,并清理掉文本中的特殊字符。
# 打印第一个章节的内容和元数据
print(f"第一个章节的原始内容:{chapters[0].page_content[:500]}...")
#### 输出结果 ####
第一个章节的原始内容:CHAPTER ONE
THE BOY WHO LIVED
M
r. and M r s. D u r s l e y , o f n u m b e r ...
这些字母之间额外的空格实际上是制表符(\t)。我们首先需要去除这些制表符:
# 为提高效率,预先编译匹配制表符的正则表达式
tab_pattern = re.compile(r'\t')
# 遍历每个章节文档,清理其中的内容
for doc in chapters:
# 使用预编译的正则表达式,将制表符('\t')替换为空格(' ')
# 这是数据清理步骤,用于规范化空白字符,便于后续处理
doc.page_content = tab_pattern.sub(' ', doc.page_content)
我们再打印一下清理后的内容,看看效果如何:
# 打印第一个清理后的章节内容和元数据
print(f"第一个章节清理后的内容:{chapters[0].page_content[:500]}...")
#### 输出结果 ####
第一个章节清理后的内容:CHAPTER ONE
THE BOY WHO LIVED
M
r. and Mrs. Dursley, of number f ....
尽管我们已经去除了多余的空格,但数据中仍然存在换行符。这并不好,因为在将文本传入嵌入模型或 LLM 时,这些换行符会增加 token 的数量。
因此,我们需要进一步清理数据,去除各种类型的换行符和不必要的字符。
# 此模式用于将多个连续的空行压缩为单个空行,以提高文本的可读性。
multiple_newlines_pattern = re.compile(r'\n\s*\n')
# 此模式用于识别被错误地拆分到两行的单词(即单词中间插入了换行符)。
word_split_newline_pattern = re.compile(r'(\w)\n(\w)')
# 此模式用于查找连续出现的多个空格,以便将它们合并为单个空格,确保文本间距统一。
multiple_spaces_pattern = re.compile(r' +')
# 遍历每个章节文档,进行进一步清理
for doc in chapters:
# 1. 将多个连续换行符替换为单个换行符
page_content = multiple_newlines_pattern.sub('\n', doc.page_content)
# 2. 修复单词中间被错误插入的换行符(如 "mag-\nic" -> "magic")
page_content = word_split_newline_pattern.sub(r'\1\2', page_content)
# 3. 将剩余的单个换行符(通常位于段落内部)替换为空格
page_content = page_content.replace('\n', ' ')
# 4. 将多个连续空格合并为单个空格
page_content = multiple_spaces_pattern.sub(' ', page_content)
doc.page_content = page_content
现在我们打印一下最终清理后的数据:
# 随机打印一个清理后的章节内容
print(f"First cleaned chapter content: {chapters[15].page_content[:500]}...")
#### 输出结果 ####
First cleaned chapter content:
THE BOY WHO LIVED Mr. and Mrs. Dursley, of number f ....
现在数据的格式明显改善了。同样的方法,我们也可以对之前分块的数据(chunked data)进行清理:
# 对分块后的文档执行上述所有的清理步骤
for doc in document_splits:
# 将制表符替换为空格
doc.page_content = tab_pattern.sub(' ', doc.page_content)
# 将多个连续换行符压缩为单个换行符
doc.page_content = multiple_newlines_pattern.sub('\n', doc.page_content)
# 修复单词中间被错误插入的换行符
doc.page_content = word_split_newline_pattern.sub(r'\1\2', doc.page_content)
# 将多个连续空格合并为单个空格
doc.page_content = multiple_spaces_pattern.sub(' ', doc.page_content)
我们已经尽可能地减少了不必要的字符。接下来,我们对数据进行一些统计分析:
# 通过空格分割每个章节的内容,计算每个章节的单词数
chapter_word_counts = [len(doc.page_content.split()) for doc in chapters]
# 找出章节中单词数量的最大值
max_words = max(chapter_word_counts)
# 找出章节中单词数量的最小值
min_words = min(chapter_word_counts)
# 计算章节单词数量的平均值
average_words = sum(chapter_word_counts) / len(chapter_word_counts)
# 打印统计结果
print(f"章节单词数最多为: {max_words}")
print(f"章节单词数最少为: {min_words}")
print(f"章节单词数平均为: {average_words:.2f}")
#### 输出结果 ####
章节单词数最多为: 6343
章节单词数最少为: 2915
章节单词数平均为: 4402.18
每个章节的最大字数大约为 6000 字。虽然在我们当前的案例中,这个分析并不特别重要,但在其他情境下却可能至关重要,因为大模型的上下文窗口对输入长度非常敏感,这可能会影响我们的处理方式。
目前来看,我们的情况还算理想,因为章节的字数远低于大多数 LLM 的上下文长度限制。不过,我们仍需考虑可能超出限制的情形。
数据重构
我们的引文数据本身已经非常精简,只包含一些通常较短的关键引文。但章节内容却相当庞大,而《哈利 · 波特》系列书籍中包含大量无关紧要的信息,比如日常对话,因此我们可以对章节内容进行重构,以进一步缩减其规模。

上下文数据的摘要化,Fareed Khan 制作
为实现这一点,我们可以利用 LLM 对章节内容进行详细的摘要提炼,保留其中重要且相关的信息。
from langchain.prompts import PromptTemplate
# 创建一个用于文本摘要的提示模板
# 此模板定义了生成摘要的结构
template = """请对以下内容撰写一份详细的摘要:
{text}
摘要:"""
# 使用模板和输入变量初始化PromptTemplate
# 此模板期望一个名为"text"的输入变量
summarization_prompt = PromptTemplate(
template=template,
input_variables=["text"]
)
现在,我们使用 DeepSeek V3 模型为每个章节生成摘要:
# 初始化摘要链
chain = load_summarize_chain(deepseek_v3, chain_type="stuff", prompt=summarization_prompt)
# 初始化一个列表用于存储摘要
chapter_summaries = []
# 遍历每个章节生成摘要
for chapter in chapters:
# 使用链生成摘要
summary = chain.invoke([chapter])
# 清理输出文本,去除多余的换行符
cleaned_text = re.sub(r'\n\n', '\n', summary["output_text"])
# 创建摘要的Document对象,保留原始元数据
doc_summary = Document(page_content=cleaned_text, metadata=chapter.metadata)
chapter_summaries.append(doc_summary)
这里使用的chain_type为stuff。我们之所以选择它,是因为在我们的案例中,每个章节最多约 6000 字,这远低于大多数 LLM(包括 DeepSeek-V3)的上下文长度限制。
然而,在其他可能超出模型上下文窗口的情境下,我们就需要选择不同的chain_type:
-
stuff:将所有文档合并成一个整体提示,一次性进行摘要。
-
map_reduce:分别对每个文档进行摘要(map 阶段),然后再将这些摘要合并成最终摘要(reduce 阶段)。
-
refine:先生成一个初始摘要,然后逐步对其进行迭代优化,每次加入新的文档内容进行精炼。
完成数据重构后,我们接下来可以对数据进行向量化并存储。
数据向量化
在前文的环境搭建部分,我们初始化了一些模型,其中包括一个嵌入模型,即 ML2 BERT 模型,其上下文窗口长度为 32k。
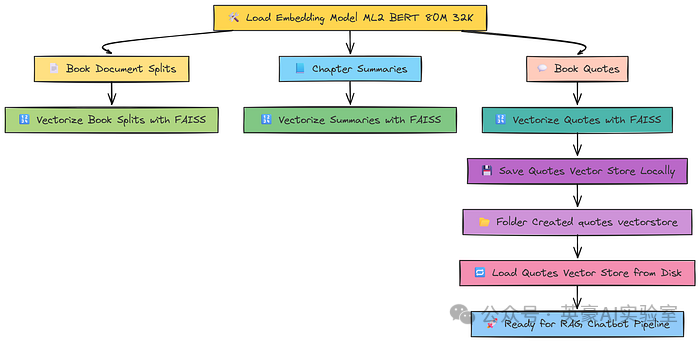
数据向量化,Fareed Khan
在数据存储方面,FAISS 是 Meta 公司开发的最流行的框架之一,以其高效的相似性搜索能力而著称。
许多流行的框架,比如 Qdrant、Pinecone 等,也都广泛使用这种方法。接下来,我们就把数据向量化,并存储到一个向量数据库中。
from langchain.vectorstores import FAISS
# 使用嵌入模型,将文档切分后的内容存入FAISS向量数据库
book_splits_vectorstore = FAISS.from_documents(document_splits, m2_bert_80M_32K)
# 使用嵌入模型,将章节摘要存入FAISS向量数据库
chapter_summaries_vectorstore = FAISS.from_documents(chapter_summaries, m2_bert_80M_32K)
# 使用嵌入模型,将书籍引用语句存入FAISS向量数据库
quotes_vectorstore = FAISS.from_documents(book_quotes_list, m2_bert_80M_32K)
现在我们已经有了三种不同的分割数据集,并且全部都进行了向量化处理。我们还可以将这些向量数据库保存到本地,以便日后使用。比如,要保存引用语句的数据,可以这样操作:
# 将引用语句的向量数据库保存到本地,以便日后使用
quotes_vectorstore.save_local("quotes_vectorstore")
执行上述代码后,你会发现当前目录下生成了一个名为quotes_vectorstore的文件夹。之后,我们可以通过以下方式加载这个本地保存的向量数据库:
# 这样就能高效地对书籍引用语句进行相似性搜索,使用指定的嵌入模型。
quotes_vectorstore = FAISS.load_local(
"quotes_vectorstore", # 引用语句FAISS索引的本地路径
m2_bert_80M_32K, # 用于编码查询和文档的嵌入模型
allow_dangerous_deserialization=True # 允许加载可能存在安全风险的对象(FAISS加载时需要)
)
由于许多云端向量数据库平台都支持 FAISS,我们可以轻松地将这个向量数据库推送到不同的云端数据库平台。现在数据已经向量化完毕,下一步就是搭建一个逻辑清晰的 RAG 聊天机器人的管道(pipeline)。
构建上下文检索器
我们核心 RAG 管道的第一步,就是创建一个检索器(Retriever),它能从我们已有的数据集中(章节摘要、引用语句、传统切分数据)检索出与用户问题最相关的数据片段。不过在此之前,我们需要先将向量化的数据转换成检索器。
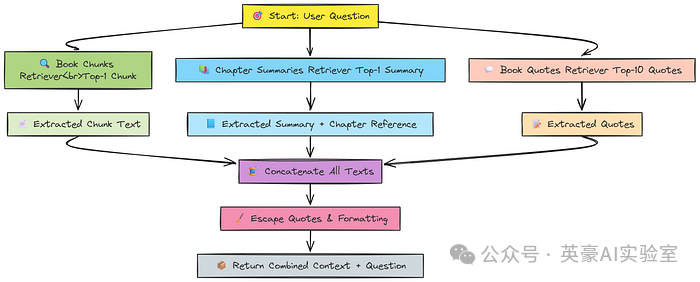
检索器工作流程示意图,Fareed Khan 制作
# 书籍内容切分数据的检索器,返回最相关的1个数据片段
book_chunks_retriever = book_splits_vectorstore.as_retriever(search_kwargs={"k": 1})
# 章节摘要的检索器,返回最相关的1个摘要
chapter_summaries_retriever = chapter_summaries_vectorstore.as_retriever(search_kwargs={"k": 1})
# 书籍引用语句的检索器,返回最相关的10条引用语句
book_quotes_retriever = quotes_vectorstore.as_retriever(search_kwargs={"k": 10})
这里我将章节摘要和传统数据片段的检索数量(top-k)设为 1,因为它们通常较长且信息密集;而书籍引用语句则较短,因此将 top-k 设为 10,以便检索更多相关信息。接下来,我们需要编写一个检索函数,使用上述设置来获取上下文:
def retrieve_context_per_question(state):
"""
根据给定的问题,从书籍内容片段、章节摘要和引用语句中检索相关的上下文信息。
参数:
state: 一个字典,包含待回答的问题。
"""
# 检索相关的书籍内容片段
print("正在检索相关内容片段...")
question = state["question"]
docs = book_chunks_retriever.get_relevant_documents(question)
# 将检索到的书籍内容片段拼接成上下文
context = " ".join(doc.page_content for doc in docs)
# 检索相关的章节摘要
print("正在检索相关章节摘要...")
docs_summaries = chapter_summaries_retriever.get_relevant_documents(state["question"])
# 将章节摘要与章节引用合并
context_summaries = " ".join(
f"{doc.page_content}(第{doc.metadata['chapter']}章)"for doc in docs_summaries
)
# 检索相关书籍引用内容
print("正在检索相关书籍引用内容...")
docs_book_quotes = book_quotes_retriever.get_relevant_documents(state["question"])
book_quotes = " ".join(doc.page_content for doc in docs_book_quotes)
# 将所有上下文内容合并:书籍片段、章节摘要和引用内容
all_contexts = context + context_summaries + book_quotes
# 对引号进行转义处理,以便后续处理
all_contexts = all_contexts.replace('"', '\\"').replace("'", "\\'")
# 返回合并后的上下文内容和原始问题
return {"context": all_contexts, "question": question}
以上就是本指南中的第一个函数。它采用了一种非常简单的方法来检索相关文档,并将它们合并成一个统一的上下文,以便传递给下一步处理。
此外,我们还对合并后的文本做了一些简单的清理,比如去除转义字符和类似的格式问题。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

过滤无关信息
在检索到相关信息后,我们还需要一个过滤器来去除其中的无关内容。实现过滤的方法有很多种,但使用 LLM 是最常见且有效的方法之一。
首先,我们需要定义一个提示模板(Prompt Template),指导 LLM 如何进行过滤。下面我们来定义这个模板:
# 定义一个提示模板,用于过滤从向量存储中检索到的文档中的无关信息。
keep_only_relevant_content_prompt_template = """
你收到一个查询:{query},以及从向量存储中检索到的文档:{retrieved_documents}。
你需要过滤掉所有与{query}无关的信息,只保留与查询密切相关的重要内容。
你可以删除句子中与查询无关的部分,也可以删除整个与查询无关的句子。
请勿添加任何未在检索到的文档中出现的新信息。
输出过滤后的相关内容。
"""
现在,我们可以使用这个提示模板来初始化我们的相关性检查模型。在本例中,我们使用的是 LLaMA 3.3 70B 模型。
from langchain_core.pydantic_v1 import BaseModel, Field
# 定义一个Pydantic模型,用于结构化LLM的输出,明确指定输出内容仅包含与查询相关的信息。
class KeepRelevantContent(BaseModel):
relevant_content: str = Field(description="从检索到的文档中提取的与查询相关的内容。")
# 使用上述定义的模板字符串创建一个提示模板,用于过滤检索文档中仅与查询相关的内容。
keep_only_relevant_content_prompt = PromptTemplate(
template=keep_only_relevant_content_prompt_template,
input_variables=["query", "retrieved_documents"],
)
# 初始化用于过滤相关内容的LLM模型实例。
keep_only_relevant_content_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 创建一个链(chain),将提示模板、LLM模型和结构化输出解析器组合起来。
# 该链接收查询和检索到的文档,过滤掉无关信息,并返回由KeepRelevantContent模型指定的相关内容。
keep_only_relevant_content_chain = (
keep_only_relevant_content_prompt
| keep_only_relevant_content_llm.with_structured_output(KeepRelevantContent)
)
我们还需要将之前的相关性检查链封装成一个专门的函数,以结构化的方式返回每个内容片段与查询的相关性情况。
from pprint import pprint
def keep_only_relevant_content(state):
"""
从检索到的文档内容中筛选并保留与查询相关的部分。
参数:
state (dict): 包含以下键值的字典:
- "question": 用户提出的查询问题。
- "context": 检索到的文档内容(字符串形式)。
返回:
dict: 包含以下键值的字典:
- "relevant_context": 筛选后的相关内容(字符串形式)。
- "context": 原始文档内容。
- "question": 原始查询问题。
"""
question = state["question"]
context = state["context"]
# 为LLM链准备输入数据
input_data = {
"query": question,
"retrieved_documents": context
}
print("正在筛选相关内容...")
pprint("--------------------")
# 调用LLM链,过滤掉不相关的内容
output = keep_only_relevant_content_chain.invoke(input_data)
relevant_content = output.relevant_content
# 确保结果为字符串类型
relevant_content = "".join(relevant_content)
# 对引号进行转义,以便后续处理
relevant_content = relevant_content.replace('"', '\\"').replace("'", "\\'")
return {
"relevant_context": relevant_content,
"context": context,
"question": question
}
现在,我们可以在每个检索到的内容片段旁边添加一个键值参数,明确标记其是否与查询相关。
查询重写(Query Rewriter)
在 RAG 系统中,一个常见挑战是用户的查询往往不够具体,导致难以检索到相关内容。为缓解这一问题,我们可以先让 LLM 对用户查询进行重写,以便更有效地从向量存储中检索到相关内容。
类似于之前创建的内容过滤链,我们也可以创建一个专门用于查询重写的链。
from langchain_core.output_parsers import JsonOutputParser
# 使用Pydantic BaseModel定义重写问题的输出结构
class RewriteQuestion(BaseModel):
"""
重写后的问题输出结构。
"""
rewritten_question: str = Field(
description="优化后的问题,更适合向量存储检索。"
)
explanation: str = Field(
description="对重写后问题的解释说明。"
)
# 为RewriteQuestion结构创建JSON输出解析器
rewrite_question_string_parser = JsonOutputParser(pydantic_object=RewriteQuestion)
# 初始化用于问题重写的LLM,使用Groq的Llama3-70B模型
rewrite_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=4000
)
接下来,我们定义提示模板,并初始化查询重写组件:
# 定义问题重写的提示模板
rewrite_prompt_template = """你是一名问题重写专家,负责将用户输入的问题优化为更适合向量存储检索的版本。
请分析输入的问题:{question},并推断其背后的语义意图。
{format_instructions}
"""
# 创建提示模板,指定输入变量和部分变量
rewrite_prompt = PromptTemplate(
template=rewrite_prompt_template,
input_variables=["question"],
partial_variables={"format_instructions": rewrite_question_string_parser.get_format_instructions()},
)
# 将提示模板、LLM和输出解析器组合成可执行链
question_rewriter = rewrite_prompt | rewrite_llm | rewrite_question_string_parser
最后,我们还需要定义一个函数,以结构化的方式返回重写后的查询结果(类似于之前的过滤步骤):
def rewrite_question(state):
"""
使用question_rewriter链重写给定的查询问题。
参数:
state (dict): 包含以下键值的字典:
- "question": 用户提出的原始查询问题。
返回:
dict: 包含以下键值的字典:
- "rewritten_question": 重写后的优化问题。
- "explanation": 重写问题的解释说明。
- "question": 原始查询问题。
"""
question = state["question"]
print("正在重写查询问题...")
pprint("--------------------")
# 调用LLM链进行问题重写
output = question_rewriter.invoke({"question": question})
return {
"rewritten_question": output["rewritten_question"],
"explanation": output["explanation"],
"question": question
}
这样我们就得到了重写后的问题。接下来,我们进入下一步。
思维链(Chain-of-Thought,CoT)
我们不再直接让 LLM 直接回答问题,而是采用一种更好的方法,即通过多步骤的推理过程来得出答案,这种方法称为思维链(Chain of Thought,简称 CoT)。
我们将以类似之前实现其他组件的方式来实现这一方法。
# 定义一个Pydantic模型,用于思维链生成答案的输出。
class QuestionAnswerFromContext(BaseModel):
answer_based_on_content: str = Field(
description="基于给定上下文生成对问题的回答。"
)
# 初始化用于从上下文回答问题的LLM,使用Together平台的Llama-3.3-70B-Instruct-Turbo-Free模型。
question_answer_from_context_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
但更重要的是提示模板,它引导 LLM 采用逐步推理的方式得出答案。下面我们就来创建这个专门用于思维链的提示模板。
question_answer_cot_prompt_template = """
思维链示例
示例 1
上下文:玛丽比简高。简比汤姆矮。汤姆和大卫一样高。
问题:谁最高?
推理过程:
玛丽 > 简
简 < 汤姆 → 汤姆 > 简
汤姆 = 大卫
因此:玛丽 > 汤姆 = 大卫 > 简
最终答案:玛丽
示例 2
上下文:哈利读到了三种魔法咒语——一种能将人变成动物,一种能让物体漂浮,一种能制造光亮。
问题:如果哈利施展这些咒语,他能做什么?
推理过程:
咒语1:将人变成动物
咒语2:使物体漂浮
咒语3:制造光亮
最终答案:他可以将人变成动物、使物体漂浮并制造光亮。
示例 3
上下文:哈利·波特生日时收到了一把光轮2000飞天扫帚。
问题:哈利为什么收到一把飞天扫帚?
推理过程:
上下文只提到他收到了一把飞天扫帚
未说明原因或赠送者
也未提及他的兴趣爱好或用途
最终答案:上下文信息不足,无法确定他收到扫帚的原因。
现在,请按照上述模式进行推理。
上下文:
{context}
问题:
{question}
"""
LLM 在每次运行时可能会产生不同的推理风格,导致思维链(CoT)回答的不一致性。
为了解决这一问题,我们可以采用少样本(few-shot)CoT 方法,即向 LLM 提供多个示例,展示我们期望的回答结构和推理风格。这正是我们目前所实现的方法。
# 创建一个提示模板,用于基于上下文进行思维链回答问题。
question_answer_from_context_cot_prompt = PromptTemplate(
template=question_answer_cot_prompt_template, # 包含示例和逐步推理的说明
input_variables=["context", "question"], # 输入变量为上下文(context)和问题(question)
)
# 创建一个链(chain),将提示模板(prompt)、大模型和结构化输出解析器(structured output parser)组合起来。
# 该链将基于给定的上下文和问题,生成带有推理过程的答案。
question_answer_from_context_cot_chain = (
question_answer_from_context_cot_prompt
| question_answer_from_context_llm.with_structured_output(QuestionAnswerFromContext)
)
接下来,我们可以在此基础上封装一个函数,以结构化的格式返回响应,具体实现方式与之前类似:
def answer_question_from_context(state):
"""
使用思维链(chain-of-thought),根据给定的上下文回答问题。
参数:
state (dict): 包含以下键值的字典:
- "question": 待回答的问题。
- "context": 用于回答问题的上下文内容。
- 可选项 "aggregated_context": 如果存在,则使用聚合后的上下文。
返回:
dict: 包含以下键值的字典:
- "answer": 生成的答案。
- "context": 实际使用的上下文。
- "question": 原始问题。
"""
# 从状态中提取问题
question = state["question"]
# 如果存在聚合上下文,则使用聚合上下文,否则使用原始上下文
context = state.get("aggregated_context", state["context"])
# 为LLM链准备输入数据
input_data = {
"question": question,
"context": context
}
print("正在根据检索到的上下文回答问题...")
# 调用思维链生成答案
output = question_answer_from_context_cot_chain.invoke(input_data)
answer = output.answer_based_on_content
print(f'检查幻觉(hallucination)前的答案: {answer}')
# 返回包含答案、上下文和问题的字典
return {"answer": answer, "context": context, "question": question}
到此为止,我们已经实现了检索器(retriever)、无关内容检查器(irrelevant checker)、查询重写器(query rewriter)和思维链(CoT)。下一步,我们需要验证检索到的文档是否真正相关。
这是一个两步式的验证方法:我们之前已经移除了明显无关的文档,现在我们将对剩余文档进行第二次相关性检查,以提高 RAG 管道的效率和准确性。
相关性检查与事实依据验证(Grounded on Facts)
在获得初步筛选后的相关文档后,我们还需要进一步检查它们的事实依据相关性和传统意义上的相关性。
具体方法是:向 LLM 询问每个文档的内容是否与重写后的查询真正相关。这种方法与之前的步骤类似,都是基于提示模板(prompt-based)的方法来评估相关性。
# 定义一个Pydantic模型,用于输出相关性检查的结构化结果
class Relevance(BaseModel):
is_relevant: bool = Field(description="文档是否与查询相关。")
explanation: str = Field(description="解释文档为何相关或不相关的原因。")
# 创建一个JSON输出解析器,用于解析Relevance模型的输出
is_relevant_json_parser = JsonOutputParser(pydantic_object=Relevance)
# 初始化用于相关性检查的LLM,这里使用Groq平台的Llama3-70B模型
is_relevant_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=2000
)
# 定义用于相关性检查的提示模板
is_relevant_content_prompt = PromptTemplate(
template=is_relevant_content_prompt_template,
input_variables=["query", "context"],
partial_variables={"format_instructions": is_relevant_json_parser.get_format_instructions()},
)
# 将提示模板、LLM和输出解析器组合成一个可执行链
is_relevant_content_chain = is_relevant_content_prompt | is_relevant_llm | is_relevant_json_parser
我们可以将这个链封装到一个传统的相关性检查函数中,以结构化的格式返回结果:
def is_relevant_content(state):
"""
判断文档内容是否与查询相关。
参数:
state:一个字典,包含以下内容:
- "question":待查询的问题。
- "context":用于判断相关性的上下文信息。
"""
# 从state字典中提取问题和上下文
question = state["question"]
context = state["context"]
# 为相关性检查链准备输入数据
input_data = {
"query": question,
"context": context
}
# 调用链路判断文档是否相关
output = is_relevant_content_chain.invoke(input_data)
print("正在判断文档是否相关...")
# 根据输出结果返回相应标签
if output["is_relevant"]:
print("文档相关。")
return"relevant"
else:
print("文档不相关。")
return"not relevant"
类似的,我们也可以利用即将传递给 LLM 的上下文,检查查询的事实依据。
为此,我们还需要一个提示模板,用于评估查询与提供的上下文之间的事实一致性,并根据信息是否正确匹配,简单返回一个 **"yes"或"no"**。
# 使用Pydantic定义事实检查的输出模式
class is_grounded_on_facts(BaseModel):
"""
用于检查答案是否基于提供上下文事实的输出模式。
"""
grounded_on_facts: bool = Field(description="答案是否基于事实,'yes' 或 'no'")
# 使用Together的Llama-3.3-70B-Instruct-Turbo-Free模型初始化事实检查LLM
is_grounded_on_facts_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 定义事实检查的提示模板
is_grounded_on_facts_prompt_template = """你是一名事实检查员,判断给定的答案 {answer} 是否基于给定的上下文 {context}。
即使答案本身不合逻辑也没关系,只要它与上下文内容相符即可。
请以json格式输出问题的答案,除了json格式外不要输出任何额外文本。
"""
# 创建提示对象
is_grounded_on_facts_prompt = PromptTemplate(
template=is_grounded_on_facts_prompt_template,
input_variables=["context", "answer"],
)
# 构建链路:提示 -> LLM -> 结构化输出
is_grounded_on_facts_chain = (
is_grounded_on_facts_prompt
| is_grounded_on_facts_llm.with_structured_output(is_grounded_on_facts)
)
我们同样可以为事实依据链创建一个简单函数,根据给定的查询及其上下文,返回 **"useful"或"no"**。
def grade_generation_v_documents_and_question(state):
"""
对答案进行评分:检查答案是否基于上下文事实,以及问题是否能被完整回答。
返回:"hallucination"(幻觉)、"useful"(有用)或"not_useful"(无用)。
"""
context = state["context"]
answer = state["answer"]
question = state["question"]
# 检查答案是否基于上下文事实
grounded = is_grounded_on_facts_chain.invoke({"context": context, "answer": answer}).grounded_on_facts
ifnot grounded:
print("答案存在幻觉(未基于事实)。")
return"hallucination"
print("答案基于事实。")
# 检查上下文是否能完整回答问题
can_be_answered = can_be_answered_chain.invoke({"question": question, "context": context})["can_be_answered"]
if can_be_answered:
print("问题可以被完整回答。")
return"useful"
else:
print("问题无法被完整回答。")
return"not_useful"
至此,我们已经实现了 RAG 流水线的核心组件,接下来可以通过一个简单的问题来测试一下流水线的表现。
测试 RAG 流水线
到目前为止,我们已经完成了 RAG 流水线以下几个核心组件的实现:
-
检索上下文
-
过滤无用的上下文文档
-
查询重写
-
相关性检查与事实真伪验证

核心 RAG 流水线,Fareed Khan 制作
我们先提出一个简单的问题,看看效果如何:
# 初始化状态,设置待回答的问题
init_state = {"question": "who is fluffy?"}
# 第一步:从向量存储中检索与问题相关的上下文
context_state = retrieve_context_per_question(init_state)
# 第二步:过滤检索到的上下文,仅保留与问题相关的内容
relevant_content_state = keep_only_relevant_content(context_state)
# 第三步:检查过滤后的内容是否与问题相关
is_relevant_content_state = is_relevant_content(relevant_content_state)
# 第四步:利用相关上下文生成问题的答案
answer_state = answer_question_from_context(relevant_content_state)
# 第五步:对生成的答案进行事实依据和实用性评分
final_answer = grade_generation_v_documents_and_question(answer_state)
# 输出最终答案
print(answer_state["answer"])
我们得到的响应如下:
Retrieving relevant chunks...
Retrieving relevant chapter summaries...
keeping only the relevant content...
--------------------
Determining if the document is relevant...
The document is relevant.
--------------------
Answering the question from the retrieved context...
answer before checking hallucination: Fluffy is a three-headed dog.
--------------------
Checking if the answer is grounded in the facts...
The answer is grounded in the facts.
--------------------
Determining if the question is fully answered...
The question can be fully answered.
Fluffy is a three-headed dog.
我们的问题是:“Fluffy 是谁?” 如果你看过《哈利 · 波特》,你一定知道 Fluffy 是该系列中一只虚构的三头犬。
我们的 RAG 流水线采用了逐步推进的方法:先检索相关上下文、过滤文档、重写查询、检查相关性,最后验证答案的事实依据。
它正确地识别出 Fluffy 确实是一只三头犬,这表明我们的流水线运行正常。
使用 LangGraph 可视化 RAG 流水线
我们目前编写的代码可能对某些人来说通过阅读理解起来较为容易,但如果能可视化 RAG 流水线,则更容易直观地理解各个组件如何协同工作。因此,我们接下来创建一个图形来直观地展示这一流水线。
from typing import TypedDict
from langgraph.graph import END, StateGraph
from langchain_core.runnables.graph import MermaidDrawMethod
from IPython.display import display, Image
# 定义图状态的数据结构
class QualitativeRetievalAnswerGraphState(TypedDict):
question: str; context: str; answer: str
# 初始化工作流图
wf = StateGraph(QualitativeRetievalAnswerGraphState)
# 添加节点:(节点名称, 处理函数)
for n, f in [("retrieve", retrieve_context_per_question),
("filter", keep_only_relevant_content),
("rewrite", rewrite_question),
("answer", answer_question_from_context)]:
wf.add_node(n, f)
# 定义图的流程
wf.set_entry_point("retrieve") # 从检索上下文开始
wf.add_edge("retrieve", "filter") # 进入内容过滤步骤
wf.add_conditional_edges("filter", is_relevant_content, {
"relevant": "answer", # 若内容相关 → 回答问题
"not relevant": "rewrite" # 若内容不相关 → 重写问题
})
wf.add_edge("rewrite", "retrieve") # 重写问题后重新检索
wf.add_conditional_edges("answer", grade_generation_v_documents_and_question, {
"hallucination": "answer", # 若答案存在幻觉 → 重新回答
"not_useful": "rewrite", # 若答案不实用 → 重写问题
"useful": END # 若答案有效 → 结束流程
})
# 编译并可视化工作流
display(Image(wf.compile().get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))
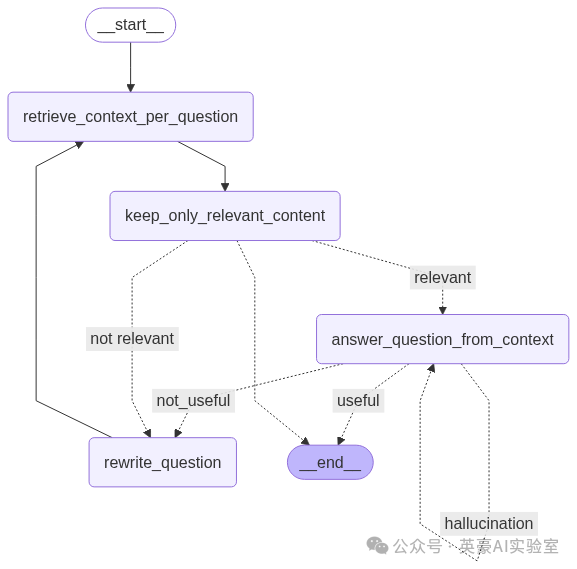
我们的 RAG 流水线,Fareed Khan 制作
这张图的流程非常清晰易懂:首先检索上下文,然后筛选出相关内容,必要时还会重写查询语句以提高上下文检索的质量。如果检索到的答案不够有用,我们会进一步使用思维链和事实核验来优化最终答案。
子图方法与知识蒸馏
但作为开发者,我们都清楚 RAG 并不像表面看起来那么简单。在实际应用中,尤其面对复杂的用户任务时,单纯依靠基本的语义相似性检索是无法解决所有问题的。这时,子图方法就显得尤为重要。
对于需要更深入推理或多步理解的任务,我们可以将主 RAG 流程拆分成多个子图,每个子图专注于特定功能,比如查询重写、文档筛选、事实核验和推理。这些子图相互协作,形成一个更加模块化、可扩展的解决方案。
对于蒸馏步骤,我们可以沿用之前的模式:
-
创建一个提示模板(prompt template)
-
基于模板构建一个链(chain)
-
将链封装成一个函数(function)
现在,我们首先创建一个提示模板,并严格规定其输出只能是true或false,以明确蒸馏后的内容是否有事实依据。
# 用于检查蒸馏内容是否基于原始上下文的提示模板
is_distilled_content_grounded_on_content_prompt_template = """
你收到了一段蒸馏后的内容:{distilled_content},以及原始上下文:{original_context}。
请判断蒸馏后的内容是否基于原始上下文。
如果蒸馏后的内容基于原始上下文,请将 grounded 字段设为 true。
如果蒸馏后的内容未基于原始上下文,请将 grounded 字段设为 false。
{format_instructions}
"""
接下来,我们使用这个提示模板来构建一个链:
# 定义输出模式的Pydantic模型
class IsDistilledContentGroundedOnContent(BaseModel):
grounded: bool = Field(
description="蒸馏后的内容是否基于原始上下文。"
)
explanation: str = Field(
description="解释蒸馏后的内容为何基于或未基于原始上下文。"
)
# LLM响应的输出解析器
is_distilled_content_grounded_on_content_json_parser = JsonOutputParser(
pydantic_object=IsDistilledContentGroundedOnContent
)
# 为LLM构建的提示模板
is_distilled_content_grounded_on_content_prompt = PromptTemplate(
template=is_distilled_content_grounded_on_content_prompt_template,
input_variables=["distilled_content", "original_context"],
partial_variables={
"format_instructions": is_distilled_content_grounded_on_content_json_parser.get_format_instructions()
},
)
# 用于此任务的LLM实例
is_distilled_content_grounded_on_content_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=4000
)
# 将提示模板、LLM和输出解析器组合成链
is_distilled_content_grounded_on_content_chain = (
is_distilled_content_grounded_on_content_prompt
| is_distilled_content_grounded_on_content_llm
| is_distilled_content_grounded_on_content_json_parser
)
最后,我们可以使用这个链创建一个主蒸馏函数,确保处理的数据一定是基于事实依据的:
def is_distilled_content_grounded_on_content(state):
"""
判断蒸馏后的内容是否基于原始上下文。
参数:
state (dict): 包含以下内容的字典:
- "relevant_context": 待检查的蒸馏内容。
- "context": 用于比对的原始上下文。
返回:
str: 如果内容有事实依据则返回 "grounded on the original context",否则返回 "not grounded on the original context"。
"""
pprint("--------------------")
print("正在判断蒸馏后的内容是否基于原始上下文...")
# 从状态中提取精炼内容和原始上下文
distilled_content = state["relevant_context"]
original_context = state["context"]
# 为LLM链准备输入数据
input_data = {
"distilled_content": distilled_content,
"original_context": original_context
}
# 调用LLM链检查内容是否有依据
output = is_distilled_content_grounded_on_content_chain.invoke(input_data)
grounded = output["grounded"]
# 根据检查结果返回相应信息
if grounded:
print("精炼内容有原始上下文依据。")
return"grounded on the original context"
else:
print("精炼内容缺乏原始上下文依据。")
return"not grounded on the original context"
我们已经为 RAG 机器人添加了内容精炼组件,接下来可以开始实现子图(sub-graph)方法,以处理更复杂的任务。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

构建用于检索与蒸馏的子图(Sub Graph)
既然我们要开始创建子图,就需要为每个数据源分别定义独立的检索函数:
-
章节摘要
-
引用语句
-
传统的文本分块数据
首先从章节摘要开始,我们的目标是创建一个单独的检索函数,以便后续用于构建图结构。
def retrieve_chunks_context_per_question(state):
"""
根据问题从书籍文本块和章节摘要中检索相关上下文。
参数:
state: 包含待回答问题的字典。
"""
# 检索相关文档
print("正在检索相关文本块...")
question = state["question"]
docs = book_chunks_retriever.get_relevant_documents(question)
# 拼接文档内容
context = " ".join(doc.page_content for doc in docs)
context = context.replace('"', '\\"').replace("'", "\\'") # 转义引号,便于后续处理
return {"context": context, "question": question}
这个函数相对简单,获取所有相关上下文并稍作清理。接下来,我们以类似方式实现另外两个检索函数:
def retrieve_summaries_context_per_question(state):
print("正在检索相关章节摘要...")
question = state["question"]
docs_summaries = chapter_summaries_retriever.get_relevant_documents(state["question"])
# 拼接章节摘要并附带章节引用信息
context_summaries = " ".join(
f"{doc.page_content}(第{doc.metadata['chapter']}章)"for doc in docs_summaries
)
context_summaries = context_summaries.replace('"', '\\"').replace("'", "\\'") # 转义引号,便于后续处理
return {"context": context_summaries, "question": question}
def retrieve_book_quotes_context_per_question(state):
question = state["question"]
print("正在检索相关书籍引用语句...")
docs_book_quotes = book_quotes_retriever.get_relevant_documents(state["question"])
book_quotes = " ".join(doc.page_content for doc in docs_book_quotes)
book_quotes_context = book_quotes.replace('"', '\\"').replace("'", "\\'") # 转义引号,便于后续处理
return {"context": book_quotes_context, "question": question}
另外两个检索函数的输出结构与章节摘要函数保持一致。现在,我们可以并排绘制每个检索器的图结构,看看整体效果如何。
class QualitativeRetrievalGraphState(TypedDict):
"""
定义定性检索工作流的状态结构。
属性:
question (str): 待检索上下文的问题。
context (str): 从数据源(如书籍文本块、摘要或引用语句)检索到的原始上下文。
relevant_context (str): 经精炼或过滤后,仅包含与问题相关信息的上下文。
"""
question: str
context: str
relevant_context: str
现在,我们可以在即将绘制的检索工作流图中使用这个类。接下来,我们先创建这个高层次的工作流函数。
def build_retrieval_workflow(node_name, retrieve_fn):
graph = StateGraph(QualitativeRetrievalGraphState)
graph.add_node(node_name, retrieve_fn)
graph.add_node("keep_only_relevant_content", keep_only_relevant_content)
graph.set_entry_point(node_name)
graph.add_edge(node_name, "keep_only_relevant_content")
graph.add_conditional_edges(
"keep_only_relevant_content",
is_distilled_content_grounded_on_content,
{
"grounded on the original context": END,
"not grounded on the original context": "keep_only_relevant_content",
},
)
app = graph.compile()
display(Image(app.get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))
return graph
我们可以直接调用这个函数,分别针对三种不同的检索方式构建工作流,看看每个图的结构如何。
# 创建三种检索方式的工作流
build_retrieval_workflow("retrieve_chunks_context_per_question", retrieve_chunks_context_per_question)
build_retrieval_workflow("retrieve_summaries_context_per_question", retrieve_summaries_context_per_question)
build_retrieval_workflow("retrieve_book_quotes_context_per_question", retrieve_book_quotes_context_per_question)
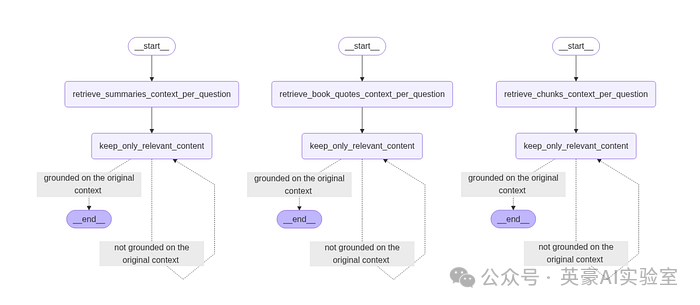
检索子图,Fareed Khan 制作
我们刚刚创建的检索函数可以进一步测试,但最好稍后在运行完整的子图 RAG 流水线时再用复杂查询进行测试。
构建用于解决幻觉问题的子图(Hallucinations)
我们还需要创建一个子图,用于减少生成答案时的幻觉现象,这一点非常重要。为此,我们首先需要单独编写一个函数,用于验证生成的答案是否基于事实,我们来实现这个函数:
def is_answer_grounded_on_context(state):
"""
判断生成的答案是否基于给定的上下文事实。
参数:
state: 包含上下文(context)和答案(answer)的字典。
返回:
如果答案未基于上下文事实,返回"hallucination";
如果答案基于上下文事实,返回"grounded on context"。
"""
print("正在检查答案是否基于事实...")
context = state["context"]
answer = state["answer"]
# 使用is_grounded_on_facts_chain链判断答案是否基于上下文
result = is_grounded_on_facts_chain.invoke({"context": context, "answer": answer})
grounded_on_facts = result.grounded_on_facts
ifnot grounded_on_facts:
print("答案存在幻觉现象。")
return"hallucination"
else:
print("答案基于事实。")
return"grounded on context"
这个函数背后的逻辑与我们之前创建子图时的检查方式类似,即通过 LLM 判断答案是否存在幻觉。
接下来,我们需要编写最后一个子图,用于在给定上下文的基础上回答问题,并避免产生幻觉。我们来绘制这个子图:
# 定义图状态
class QualitativeAnswerGraphState(TypedDict):
question: str; context: str; answer: str
# 构建子图
wf = StateGraph(QualitativeAnswerGraphState)
wf.add_node("answer", answer_question_from_context)
wf.set_entry_point("answer")
wf.add_conditional_edges("answer", is_answer_grounded_on_context, {
"hallucination": "answer",
"grounded on context": END
})
# 编译并展示子图
display(Image(wf.compile().get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))
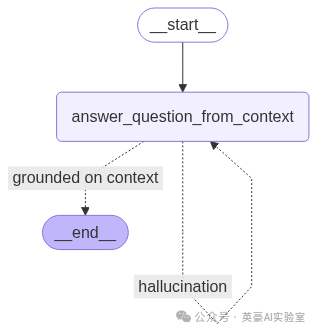
幻觉检测子图,Fareed Khan 制作
在继续之前,我们先测试一下这个幻觉检测流水线。我们故意制造一个幻觉场景,看看 LLM 是否能检测出来:
question = "who is harry?" # 待回答的问题
context = "Harry Potter is a cat."# 提供的上下文
init_state = {"question": question, "context": context} # 初始状态
for output in qualitative_answer_workflow_app.stream(init_state):
for _, value in output.items():
pass# 节点处理
# ... (你的现有代码)
pprint("--------------------")
print(f'answer: {value["answer"]}')
#### 输出结果 ####
Answering the question from the retrieved context...
answer before checking hallucination: Harry Potter is a cat.
Checking if the answer is grounded in the facts...
The answer is grounded in the facts.
--------------------
answer: Harry Potter is a cat.
因此,我们限制了上下文范围,以测试大模型是否会产生幻觉(hallucination)。测试结果表明,模型仅根据提供的上下文进行回答,没有出现幻觉现象,这是一个积极的信号。
创建并测试计划执行器(Plan Executor)
现在,我们已经完成了 RAG 流水线的核心组件开发,但最关键的部分——流水线的逻辑实现——还尚未完成。我们首先需要定义一个类对象,后续将根据我们在规划器(planner)中编写的逻辑进一步扩展。
计划执行器,Fareed Khan 制作
class PlanExecute(TypedDict):
curr_state: str # 当前状态
question: str # 用户原始问题
anonymized_question: str # 匿名化后的问题
query_to_retrieve_or_answer: str # 用于检索或回答的查询
plan: List[str] # 执行计划步骤列表
past_steps: List[str] # 已执行步骤列表
mapping: dict # 映射关系字典
curr_context: str # 当前上下文
aggregated_context: str # 聚合后的上下文
tool: str # 使用的工具
response: str # 最终回答
接下来,我们需要定义如何执行计划。这意味着我们的 RAG 流水线由多个组件协同工作。
这里的“逻辑”指的是如何执行计划,以解决那些需要深入思考的复杂问题。为此,我们再次利用 LLM 的能力来帮助我们生成计划。
# 使用Pydantic定义计划结构的数据模型
class Plan(BaseModel):
"""未来执行的计划"""
steps: List[str] = Field(
description="需要按顺序执行的步骤列表"
)
# 定义用于生成逐步计划的提示模板
planner_prompt = """针对给定的问题 {question},请制定一个简单、逐步的计划,以便找到答案。
该计划应包含若干个独立的任务,每个任务正确执行后将最终得出正确答案。不要添加任何多余的步骤。
最后一步的结果应为最终答案。确保每一步骤都包含必要的信息,不要跳过任何步骤。
"""
# 创建PromptTemplate实例
planner_prompt = PromptTemplate(
template=planner_prompt,
input_variables=["question"],
)
# 初始化用于规划的LLM
planner_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 构建规划器链路:提示模板 -> LLM -> 结构化输出(Plan)
planner = planner_prompt | planner_llm.with_structured_output(Plan)
这里最关键的部分是提示模板(prompt template)。基于用户的查询,LLM 会确定 RAG 流水线中需要执行的具体任务。最终一步应生成最终答案。由于我们依赖 LLM 生成计划,因此在提示模板中明确要求 LLM 不要跳过任何步骤。
我们拥有三种类型的检索信息:摘要(summaries)、引用(quotes)和分块内容(chunked)。我们需要以一种精细化的格式定义一个计划,以便根据用户的查询相应地执行。因此,接下来我们将定义这个计划。
# 用于细化计划的提示模板,确保每个步骤都能通过检索或回答操作执行
break_down_plan_prompt_template = """你收到一个计划 {plan},其中包含一系列步骤,用于回答用户提出的问题。
请你根据以下要求对该计划进行细化:
1. 每个步骤必须能够通过以下任一方式执行:
i. 从书籍片段的向量数据库中检索相关信息;
ii. 从章节摘要的向量数据库中检索相关信息;
iii. 从书籍引用的向量数据库中检索相关信息;
iv. 根据给定的上下文回答问题。
2. 每个步骤必须明确包含执行该步骤所需的全部信息。
请输出细化后的计划。
"""
# 创建用于细化计划的PromptTemplate实例
break_down_plan_prompt = PromptTemplate(
template=break_down_plan_prompt_template,
input_variables=["plan"],
)
# 初始化用于细化计划的LLM模型
break_down_plan_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 构建执行链:提示模板 -> LLM模型 -> 结构化输出(Plan)
break_down_plan_chain = break_down_plan_prompt | break_down_plan_llm.with_structured_output(Plan)
在上述提示模板中,我们向 LLM 提供了关于我们检索数据库的具体信息和额外说明,以便它能够据此细化原有计划。
接下来,我们测试一下刚刚实现的计划执行器,看看它如何逐步解决用户提出的问题:
question = {"question": "主角是如何击败反派的?"} # 待回答的问题
my_plan = planner.invoke(question) # 生成初始计划
print(my_plan)
refined_plan = break_down_plan_chain.invoke(my_plan.steps) # 细化计划
print(refined_plan)
#### 输出结果 ####
steps = [
'从向量数据库中检索信息,确定故事中的主角和反派。',
'从向量数据库中检索信息,找到故事的高潮或最终对决场景。',
'从向量数据库中检索信息,分析主角在最终对决中的具体行动。',
'从向量数据库中检索信息,确定主角击败反派的关键行动或策略。',
'根据以上检索到的上下文,总结主角击败反派的具体过程。'
]
从输出结果可以看出,模型成功地以逐步推理(CoT)的方式生成了清晰的步骤链条,最后一步即为最终答案。这表明我们的计划执行器工作正常。
重新规划的逻辑思考
此外,我们还需要实现一个逻辑,用于根据已执行步骤、当前计划和已收集的信息,动态更新计划。下面我们来实现这一功能:
# 用于根据进展和上下文重新规划或更新计划的提示模板
replanner_prompt_template = """
针对给定的目标,请你制定一个清晰、逐步的计划,以便最终得出正确答案。
该计划应包含一系列独立任务,只要正确执行这些任务,就能得到正确答案。
不要添加任何多余的步骤,最后一步的结果应即为最终答案。
确保每个步骤都明确包含执行该步骤所需的全部信息,不要跳过任何必要的步骤。
假设尚未找到答案,你需要据此更新计划,因此计划绝不能为空。
你的目标是:
{question}
你原来的计划是:
{plan}
你目前已经完成了以下步骤:
{past_steps}
你当前已有的上下文信息:
{aggregated_context}
请据此更新你的计划。如果还需要进一步步骤,请仅列出尚未完成的步骤,不要重复列出已完成的步骤。
输出格式为JSON,因此需要对引号和换行符进行转义。
{format_instructions}
这个提示模板的作用是帮助我们逐步理解 RAG 流水线的每个环节进展情况。通过引入这个模板,我们的流水线得到了显著增强,现在可以实时跟踪和理解每个步骤的执行情况。
接下来,我们将基于这个提示模板创建一个重新规划(re-planner)模块:
# 定义一个Pydantic模型,用于表示行动(重新规划)的可能结果
class ActPossibleResults(BaseModel):
"""行动可能产生的结果"""
plan: Plan = Field(description="后续要执行的计划。")
explanation: str = Field(description="对该行动的解释说明。")
# 为ActPossibleResults模型创建一个JSON输出解析器
act_possible_results_parser = JsonOutputParser(pydantic_object=ActPossibleResults)
# 使用之前定义的replanner_prompt_template创建重新规划的提示模板
replanner_prompt = PromptTemplate(
template=replanner_prompt_template,
input_variables=["question", "plan", "past_steps", "aggregated_context"],
partial_variables={"format_instructions": act_possible_results_parser.get_format_instructions()},
)
# 初始化用于重新规划的LLM
replanner_llm = ChatTogether(temperature=0, model_name="LLaMA-3.3-70B-Turbo-Free", max_tokens=2000)
# 构建重新规划链:提示模板 -> LLM -> 结构化输出(ActPossibleResults)
replanner = replanner_prompt | replanner_llm | act_possible_results_parser
很好!现在我们已经完成了整个计划执行逻辑的编码,可以继续下一步:创建任务处理器(Task Handler)逻辑。
创建任务处理器(Task Handler)
虽然我们已经完成了计划执行的代码,但我们还需要一个单独的任务处理器,用于决定每个任务应当调用哪个子流程(sub-graph)。
我们将采用类似的方法:首先创建一个提示模板,然后基于该模板构建一个链式处理流程。
# 任务处理器的提示模板,用于决定计划中的某个任务应使用哪个工具
tasks_handler_prompt_template = """
你是一个任务处理器,当前收到的任务是:{curr_task},你需要决定使用哪个工具来执行该任务。
你可以使用以下工具:
工具A:根据给定查询,从书籍片段的向量存储中检索相关信息。
- 当当前任务需要在书籍片段中搜索信息时,使用工具A。
工具B:根据给定查询,从章节摘要的向量存储中检索相关信息。
- 当当前任务需要在章节摘要中搜索信息时,使用工具B。
工具C:根据给定查询,从书籍引用的向量存储中检索相关信息。
- 当当前任务需要在书籍引用中搜索信息时,使用工具C。
工具D:根据给定的上下文回答问题。
- 仅当当前任务可以通过已有的聚合上下文(aggregated_context)直接回答时,才使用工具D。
决策过程的额外上下文:
- 你还会收到上一次使用的工具:{last_tool}
- 如果上一次使用的工具是retrieve_chunks,则避免再次使用工具A,应优先选择其他工具。
- 你还拥有过去的步骤:{past_steps},以帮助理解任务的上下文。
- 你还拥有用户最初提出的问题:{question},作为额外的上下文信息。
输出说明:
- 如果你决定使用工具A、B或C,请输出用于该工具的查询,并明确指出所用工具。
- 如果你决定使用工具D,请输出用于该工具的问题、上下文,并明确指出所用工具为工具D。
我们定义了四个工具,每个工具对应一个单独的子图检索器,可以根据需要调用。这正是我们提示模板中每个工具所代表的含义。最后一个工具用于生成最终答案。
接下来,我们在此基础上创建一个链式结构:
# 定义任务处理器输出的Pydantic模型
class TaskHandlerOutput(BaseModel):
"""任务处理器的输出模式"""
query: str = Field(description="用于从向量存储中检索的查询,或需要根据上下文回答的问题。")
curr_context: str = Field(description="用于回答查询的上下文信息。")
tool: str = Field(description="所使用的工具,应为retrieve_chunks、retrieve_summaries、retrieve_quotes或answer_from_context之一。")
# 为任务处理器创建PromptTemplate,使用之前定义的tasks_handler_prompt_template
task_handler_prompt = PromptTemplate(
template=tasks_handler_prompt_template,
input_variables=["curr_task", "aggregated_context", "last_tool", "past_steps", "question"],
)
# 初始化任务处理器的LLM
task_handler_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 组合任务处理器链:prompt → LLM → 结构化输出(TaskHandlerOutput)
task_handler_chain = task_handler_prompt | task_handler_llm.with_structured_output(TaskHandlerOutput)
到目前为止,我们已经实现了子图、计划执行器和任务处理器,用于决定执行哪个子图。
然而,我们仍需一种方法来生成不带偏见或幻觉的计划,这正是我们下一步要实现的功能。
问题的匿名化与去匿名化
为了生成一个通用的计划,避免 LLM 基于先验知识产生偏见,我们首先对输入问题进行匿名化处理,将其中的命名实体替换为变量。
# --- 匿名化 ---
class AnonymizeQuestion(BaseModel):
anonymized_question: str
mapping: dict
explanation: str
anonymize_question_chain = (
PromptTemplate(
input_variables=["question"],
partial_variables={
"format_instructions": JsonOutputParser(pydantic_object=AnonymizeQuestion).get_format_instructions()
},
template="""你需要通过将命名实体替换为变量来匿名化问题。
示例:
- "哈利·波特是谁?" → "X是谁?", {"X": "哈利·波特"}
- "坏人是如何和亚历克斯、罗尼一起玩的?" → "X是如何和Y、Z一起玩的?", {"X": "坏人", "Y": "亚历克斯", "Z": "罗尼"}
输入:{question}
{format_instructions}
""",
)
| ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
| JsonOutputParser(pydantic_object=AnonymizeQuestion)
)
在基于匿名化问题构建计划后,我们再对计划进行去匿名化处理,即用原始命名实体替换映射的变量。
class DeAnonymizePlan(BaseModel):
plan: List
de_anonymize_plan_chain = (
PromptTemplate(
input_variables=["plan", "mapping"],
template="将以下计划中的变量:{plan},根据映射关系:{mapping}进行替换,并以JSON格式输出更新后的列表。"
)
| ChatTogether(temperature=0, model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=together_api_key, max_tokens=2000).with_structured_output(DeAnonymizePlan)
)
很好!现在我们已经定义了专门用于子图的新型 RAG 流水线的所有主要组件,接下来只需初始化它,以便我们可以用示例用户查询进行测试。
编译与可视化 RAG 流水线
我们已经完成了所有组件的编码,现在我们将把 RAG 流水线的各个部分整合起来,并开始对其进行评估。
def execute_plan_and_print_steps(state):
# 设置当前状态标签
state["curr_state"] = "task_handler"
# 获取当前任务并从计划中移除
curr_task = state["plan"].pop(0)
# 为任务处理链准备输入参数
inputs = {
"curr_task": curr_task,
"aggregated_context": state.get("aggregated_context", ""),
"last_tool": state.get("tool"),
"past_steps": state.get("past_steps", []),
"question": state["question"]
}
# 调用任务处理链,决定下一步使用的工具和查询内容
output = task_handler_chain.invoke(inputs)
# 记录已完成的任务
state["past_steps"].append(curr_task)
# 保存查询内容和所选工具
state["query_to_retrieve_or_answer"] = output.query
state["tool"] = output.tool if output.tool != "answer_from_context"else"answer"
# 如果工具是直接从上下文中回答,则保存具体的上下文信息
if output.tool == "answer_from_context":
state["curr_context"] = output.curr_context
return state
现在,我们可以对这种子图检索 RAG 方法进行可视化展示。可视化流水线的代码较为复杂,这里不再赘述,但你可以在代码仓库中找到相关实现。下面是流水线的可视化示意图:
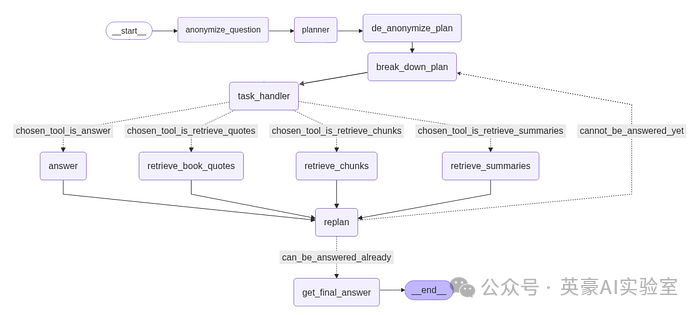
最终构建的智能体,Fareed Khan 制作
现在,我们从高层次上回顾一下我们最终构建的 RAG 流水线的整体流程:
-
首先,对用户提出的问题进行匿名化处理;
-
接着,由规划器(planner)制定高层次的策略;
-
然后,对规划进行去匿名化处理,重新引入具体上下文;
-
将规划拆解为更小的具体任务;
-
每个具体任务由任务处理器选择合适的工具来执行;
-
如果工具用于检索引用、文本片段或摘要,则执行数据检索;
-
检索完成后,系统可能根据新信息重新规划;
-
如果问题已具备足够信息,则生成最终答案;
-
整个流程结束。
以上就是我们目前所编写的 RAG 流水线的整体架构。
测试最终流水线
我们将使用三个不同的示例问题来测试最终构建的流水线。第一个示例问题特意设计为模型无法回答的情况,以便观察流水线如何处理上下文中不存在的问题。
# -----------------------------------------------------------
# 示例:运行计划执行智能体,处理一个示例问题
# -----------------------------------------------------------
# 定义智能体的输入问题
input = {
"question": "卢平教授教授的是什么课程?"
}
# 执行计划执行流程,并打印每一步的过程
final_answer, final_state = execute_plan_and_print_steps(input)
#### 输出结果 ####
...
...
最终答案为:未能在数据中找到该问题的答案。
这个示例的输出非常长,因为智能体反复尝试检索信息,但始终未能找到相关内容。
这实际上是一个积极的信号,说明系统在知识库缺乏相关信息时,不会凭空捏造(或称“幻觉”)答案。
接下来,我们来看一个原创的示例测试,这次我们确实希望系统给出答案,因为上下文中包含了相关信息。
# -----------------------------------------------------------
# 示例:运行计划与执行(Plan-and-Execute)智能体处理复杂问题
# -----------------------------------------------------------
# 为智能体定义输入问题。
# 该问题需要推理出帮助反派的教授是谁,以及他教授的课程是什么。
input = {
"question": "帮助反派的教授教的是什么课?"
}
# 执行计划与执行流程,并打印每个步骤。
# 该函数将打印推理过程和最终答案。
final_answer, final_state = execute_plan_and_print_steps(input)
#### 输出 ####
...
...
最终答案是:帮助反派的教授是奇洛教授,他教授的是黑魔法防御术。
这里我截取了部分输出,以避免混乱。但最终的回答验证了我们 RAG 管道的逻辑推理能力,证明当上下文包含与查询相关的信息时,系统能够正确地工作。
这个输出展示了智能体能够将复杂问题拆解为更简单、可解决的子问题,并有效地将它们串联起来的能力。
现在到了最后一步:测试管道的思维链(CoT)推理能力。
# -----------------------------------------------------------
# 示例:运行计划与执行智能体处理推理型问题
# -----------------------------------------------------------
# 为智能体定义输入问题。
# 该问题需要推理哈利是如何击败奇洛的。
input = {
"question": "哈利是如何击败奇洛的?"
}
# 执行计划与执行流程,并打印每个步骤。
# 该函数将打印推理过程和最终答案。
final_answer, final_state = execute_plan_and_print_steps(input)
#### 输出 ####
根据检索到的上下文回答问题...
在检查幻觉前的答案:推理链:
上下文提到,当哈利触碰奇洛时……并且灼伤了他。
上下文解释这是因为一种力量……爱。
因此,哈利击败奇洛并非使用咒语……被伏地魔附身。
最终答案:哈利击败奇洛是因为他母亲……接触时灼伤奇洛。
这个示例表明系统不仅能简单地提取事实,还能遵循结构化的推理过程,针对“如何”和“为什么”类型的问题,构建出完整而清晰的解释。
使用 RAGAS 进行评估
我们将使用 RAGAS 库来评估我们的 RAG 管道。RAGAS 提供了一系列工具,帮助我们轻松且可靠地评估基于大模型的应用。我们需要准备评估数据,具体而言,我们需要定义:
-
查询(Queries):即用于测试管道的用户问题
-
标准答案(Ground truths):即预期的正确答案
下面,我们正式定义这些问题和答案,以便对我们的流水线进行评估:
# -----------------------------------------------------------
# 定义评估问题及标准答案
# -----------------------------------------------------------
# 用于评估哈利·波特RAG流水线的问题列表
questions = [
"守护魔法石的三头狗叫什么名字?",
"是谁送给哈利·波特他的第一把飞天扫帚?",
"分院帽最初考虑将哈利分到哪个学院?",
]
# 与上述问题对应的标准答案列表
ground_truth_answers = [
"Fluffy",
"Professor McGonagall",
"Slytherin",
]
我们将使用以下五个指标来评估流水线的表现,每个指标的含义如下:
-
答案正确性(Answer Correctness):检查生成的答案是否在事实上正确无误。
-
忠实性(Faithfulness):确保答案严格基于给定的上下文,不包含虚构或额外的信息。
-
答案相关性(Answer Relevancy):衡量答案与问题之间的相关程度,是否切题。
-
上下文召回率(Context Recall):评估答案中包含了多少来自上下文的有用信息。
-
答案相似度(Answer Similarity):将生成的答案与标准答案进行比较,衡量二者的相似程度。
明确了这些指标的含义后,我们就可以开始进行评估了:
# -----------------------------------------------------------
# 准备数据并执行Ragas评估
# -----------------------------------------------------------
# 1. 为Ragas评估准备数据字典
data_samples = {
'question': questions, # 待评估的问题列表
'answer': generated_answers, # 流水线生成的答案列表
'contexts': retrieved_documents, # 每个问题对应的检索到的上下文内容
'ground_truth': ground_truth_answers # 用于评估的标准答案列表
}
# 2. 确保每个上下文都是字符串列表(Ragas要求的格式)
# 如果上下文为单个字符串,则将其包装成列表形式
data_samples['contexts'] = [
[context] if isinstance(context, str) else context
for context in data_samples['contexts']
]
# 3. 使用数据字典创建HuggingFace Dataset对象
dataset = Dataset.from_dict(data_samples)
# 4. 定义用于Ragas评估的指标列表
metrics = [
answer_correctness,
faithfulness,
answer_relevancy,
context_recall,
answer_similarity
]
# 5. 初始化用于Ragas评估的LLM模型(使用GPT-4o)
llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
# 6. 使用指定的指标和LLM模型对数据集进行Ragas评估
score = evaluate(dataset, metrics=metrics, llm=llm)
# 7. 将评估结果转换为pandas DataFrame并打印
results_df = score.to_pandas()
运行上述代码后,我们的流水线将开始对测试问题进行评估。接下来,我们可以查看评估后的 DataFrame 结果。
我们已成功地在一组示例问题上评估了我们的 RAG 流水线。虽然部分测试指标得分稍低(约 0.9 左右),但这是正常现象,随着测试问题数量增加到 100 个,这些指标可能还会进一步降低。
但目前的结果已充分展示了 RAGAS 的强大之处:仅需少量代码,我们便能高效、有效地评估一个复杂的 RAG 流水线。
总结回顾
回顾整个过程,我们从零开始,首先对数据进行了预处理和清洗。随后,我们构建了检索器(retriever)、过滤器(filter)、查询重写器(query rewriter)以及基于思维链(CoT)的流水线。为处理复杂查询,我们引入了子图(sub-graph)方法,为检索、精炼等各个组件分别构建了专用子图。
我们还开发了减少幻觉(hallucination)的组件,并设计了规划器(planner)和任务处理器(task handler),智能地决定执行哪些任务以及执行顺序。在整个过程中,我们逐步可视化了 RAG 流水线的每个环节。最后,我们使用 RAGAS 框架,通过五个不同的指标对整个系统进行了全面评估。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
二、如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









