







 文章探讨了词嵌入技术如何通过神经网络学习单词之间的语义关系,如性别差异和翻译对应,以及如何将这种表示应用于NLP任务和跨语言学习。作者指出,这些表示在深度学习中扮演着关键角色,尤其是在图像和文本的融合表示中。
文章探讨了词嵌入技术如何通过神经网络学习单词之间的语义关系,如性别差异和翻译对应,以及如何将这种表示应用于NLP任务和跨语言学习。作者指出,这些表示在深度学习中扮演着关键角色,尤其是在图像和文本的融合表示中。
What words have embeddings closest to a given word? From Collobert et al. (2011)
对于一个网络来说,让具有相似含义的词具有相似的向量似乎是很自然的。如果你用一个词换一个同义词(eg. “a few people sing well” -> “a couple people sing well”),句子的有效性就不会改变。然而,从天真的角度来看,输入句已经发生了很大的变化,如果 W W W 把同义词(例如”few”和”couple”)精密地联系在一起,那么从RRR的角度来看,变化不大。
这是非常强大的。5-grams的数量可能是巨大的,我们有相对较少的数据点去试图学习。相似的词放在一起使我们可能把一个句子概括为一类相似的句子。这不仅意味着将一个单词转换为同义词,还意味着在类似的类型中将一个单词转换为一个单词(例如,”the wall is blue” -> “the wall is red”)。此外,我们还可以更改多个单词(例如. “the wall is blue” -> “the ceiling is red”)。这对单词数量的影响是指数级的。
所以,很明显,这对 W W W来说是一件非常有用的事情。但它是如何学会这样做的呢?似乎在很多情况下,它看到像 “the wall is blue” 这样的句子,并且在看到 “the wall is red”这样的句子之前就知道它是有效的。因此,将”red” 向 “blue”移动一点会对网络表现更好。
我们仍然需要看到每一个词被使用的例子,但类比允许我们将其推广到新的单词组合。你看过所有你以前理解的单词,但你没有看过你以前理解的所有句子。神经网络也是如此。
单词嵌入显示了一个更显著的特性:单词之间的类比似乎被编码在单词之间的差异向量中。例如,似乎存在一个恒定的male-female 差异向量:
W(‘‘woman")−W(‘‘man") ≃ W(‘‘aunt")−W(‘‘uncle")W(‘‘woman")−W(‘‘man") ≃ W(‘‘aunt")−W(‘‘uncle")W(``\text{woman}\!“) - W(``\text{man}\!”) \simeq W(``\text{aunt}\!“) - W(``\text{uncle}\!”)
W(‘‘woman")−W(‘‘man") ≃ W(‘‘queen")−W(‘‘king") W ( ‘ ‘ woman " ) − W ( ‘ ‘ man " ) ≃ W ( ‘ ‘ queen " ) − W ( ‘ ‘ king " ) W(``\text{woman}\!“) - W(``\text{man}\!”) \simeq W(``\text{queen}\!“) - W(``\text{king}\!”)
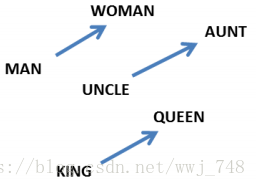
这似乎并不太令人惊讶。毕竟,性别代词意味着转换一个单词会使句子在语法上不正确。你写道,“she is the aunt”,但“he is the uncle。”类似地,“he is the King”,但“she is the Queen”。如果有人看到“she is the uncle”,最有可能的解释是语法错误。如果有一半的时间是随机转换的话,很有可能发生在这里。
“当然!” 事后我们说:“嵌入这个词将学会以一致的方式编码性别。事实上,可能有一个性别层面。单数和复数也是一样的。很容易找到这些琐碎的关系!”
然而,事实证明,更复杂的关系也是用这种方式编码的。简直是奇迹!
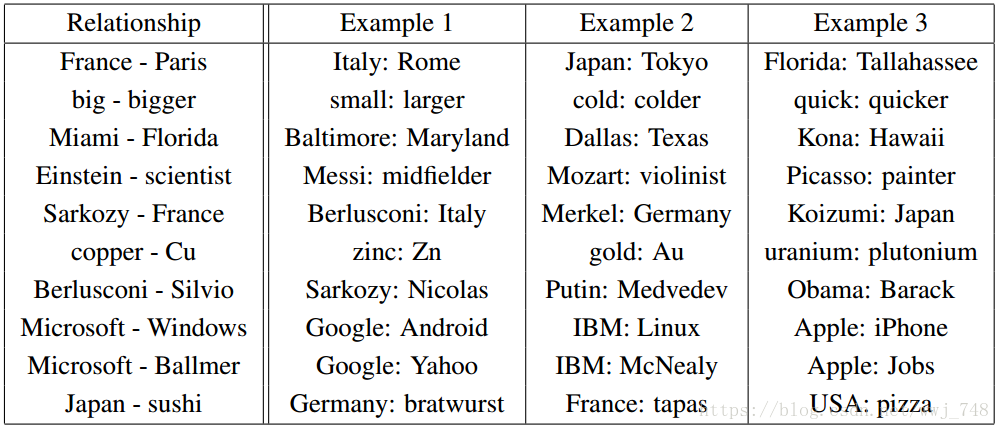
Relationship pairs in a word embedding. From Mikolov et al. (2013b).
认识到 W W W的所有这些性质都是副作用是很重要的。我们并没有试图把相似的词放在一起。我们没有尝试不同的向量进行编码。我们所要做的只是执行一个简单的任务,比如预测一个句子是否有效。这些属性或多或少地出现在优化过程中。
这似乎是神经网络的一大优势:它们学会了更好的自动表示数据的方法。反过来,很好地表示数据似乎是许多机器学习问题成功的关键。词嵌入只是学习表示法的一个特别引人注目的例子。
共享表示
单词嵌入的属性当然是有趣的,但是我们能用它们做一些有用的事情吗?除了预测一些愚蠢的事情,比如5-gram是否“有效”?
我们学习单词嵌入是为了更好地完成一个简单的任务,但是根据我们在单词嵌入中观察到的良好特性,您可能会怀疑它们在NLP任务中通常是有用的。事实上,像这样的单词表示是非常重要的:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









