






前言
【条件】在整个AI绘画过程中至关重要,适当的条件可以让生图结果事半功倍,在ComfyUI中,【条件】充当了指挥官的角色,画质如何,画风如何,场景如何等等,都可以通过【条件】来进行精准控制。我们以最简文生图工作流为例,简要回顾一下文生图的流程。
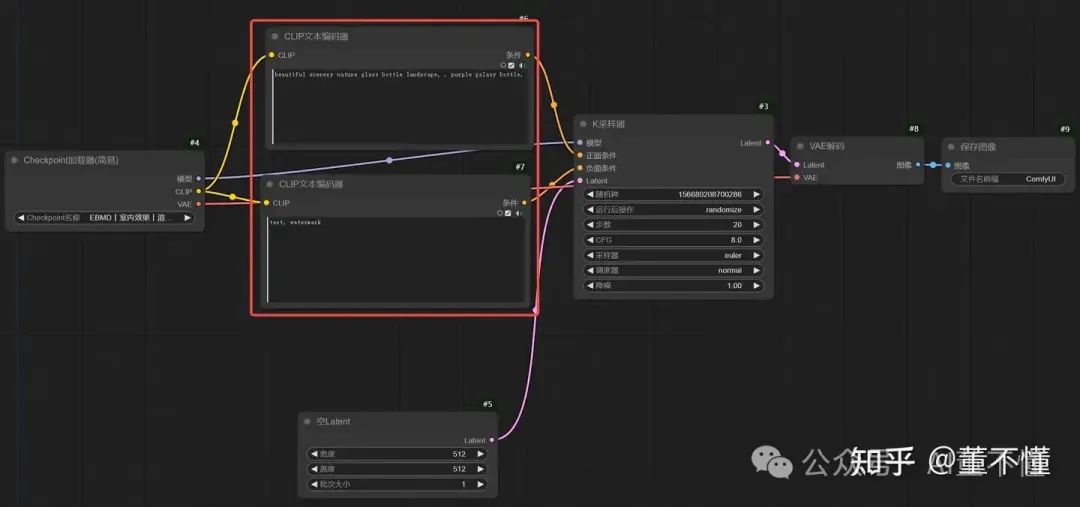
可以看到,【CLIP文本编码器】就是一个我们最常见最常用的条件节点,告诉采样过程,我要什么,我不要什么。K采样器就会按照我们的要求进行采样工作,最终生成我们想要的画面。除了【CLIP文本编码器】这个条件节点,我们再来看看其他条件节点。
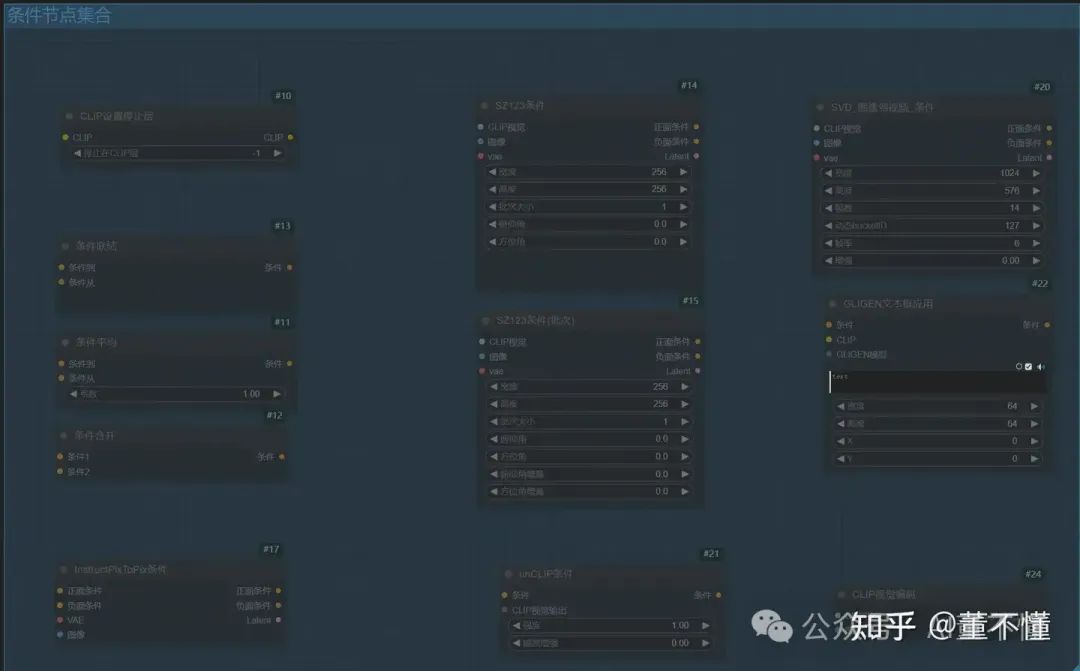
以上是我们本篇要探讨的节点集合,其他节点如controlnet,我们将在之后更高级阶段进行讲解。在开始之前,我们需要明确一个总原则,就是【条件】在生图工作流中的位置或者角色:在K采样器之前,也就是说在采样之前我们就要把条件设置好。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

1、CLIP设置停止层
我们先来看下官方对CLIP的解释
CLIP is a very advanced neural network that transforms your prompt text into a numerical representation. Neural networks work very well with this numerical representation and that’s why devs of SD chose CLIP as one of 3 models involved in stable diffusion’s method of producing images. As CLIP is a neural network, it means that it has a lot of layers. Your prompt is digitized in a simple way, and then fed through layers. You get numerical representation of the prompt after the 1st layer, you feed that into the second layer, you feed the result of that into third, etc, until you get to the last layer, and that’s the output of CLIP that is used in stable diffusion. This is the slider value of 1. But you can stop early, and use the output of the next to last layer - that’s slider value of 2. The earlier you stop, the less layers of neural network have worked on the prompt.
翻译成中文就是
CLIP 是一种非常先进的神经网络,可以将提示文本转换为数字表示。神经网络可以很好地处理这种数值表示,这就是为什么 SD 的开发人员选择 CLIP 作为涉及稳定扩散生成图像方法的 3 个模型之一。由于 CLIP 是一个神经网络,这意味着它有很多层。您的提示以简单的方式数字化,然后通过层传递。您在第一层之后获得提示的数字表示,将其输入第二层,将结果输入第三层,依此类推,直到到达最后一层,这就是 stable 中使用的 CLIP 的输出扩散。这是滑块值 1。但是您可以提前停止,并使用倒数第二层的输出 - 即滑块值 2。您停止得越早,处理提示的神经网络层数就越少。
我们将这一段文字翻译成图形化表示

CLIP神经网络有12层,从0到11,上层处理的结果会输入到下一层,逐层处理直到最后一层,深度越深,信息越精准,深度越浅,信息越缺少,CLIP-SKIP是一种提前终止处理的机制,告诉CLIP,我在哪一层终止处理。
我们通过效率节点更深入的理解CLIP-SKIP机制
正面提示词:1 chinese painting, montains, boats, red leaves, waterfall, trees, birds, people,
负面提示词:NSFW,(worst quality:2),(low quality:2),(normal quality:2),lowres,normal quality,((grayscale)),skin spots,acnes,skin blemishes,age spot,(ugly:1.331),(duplicate:1.331),(morbid:1.21),(mutilated:1.21),(tranny:1.331),mutated hands,(poorly drawn hands:1.5),blurry,(bad anatomy:1.21),(bad proportions:1.331),extra limbs,(disfigured:1.331),(missing arms:1.331),(extra legs:1.331),(fused fingers:1.61051),(too many fingers:1.61051),(unclear eyes:1.331),lowers,bad hands,missing fingers,extra digit,bad hands,missing fingers,(((extra arms and legs))),(((there are interesting art paintings hanging on the wall)))Frames,decorative paintings,nsfw,

可以发现,随着CLIP层的深入,提示词中物体越来越多,这就验证了“深度越深,信息越精准,深度越浅,信息越缺少”这句话。我们还发现大概在CLIP-SKIP=-4的时候,信息元素基本都出现了。
现在我们知道【CLIP设置停止层】可以影响提示词对最终生图的效果,同时我们也知道CFG值也会影响提示词对最终生图的效果,它们有什么关系?是否相互作用呢?

可以发现,构图没有发生大的变化,只能在图像中看到轻微的变化,CLIP Skip和CFG之间没有直接的相互作用。调整一个参数不会影响另一个参数的效果。
【CLIP设置停止层】影响文本编码的深度,【CFG】影响整个生成过程对文本提示的依赖程度。
【注意】在ComfyUI中,CLIP-SKIP默认为-2,如果没有特殊需求,我们不必理会这个参数。为什么设置为-2,而不是其他值呢?-1是最深层,难道不好吗?-2应该是一个经验值,设置为-1画面会很凝重。
2、条件联结
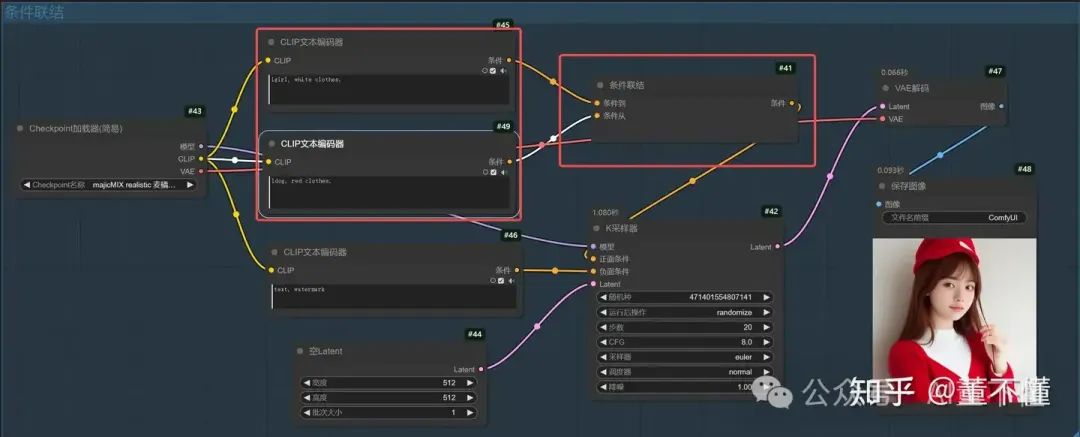
条件1:1girl, white clothes,
条件2:1dog, red clothes,
【条件联结】在合并提示词的时候,如果存在不同角色,会随机抽取主体角色进行绘制。
3、条件合并
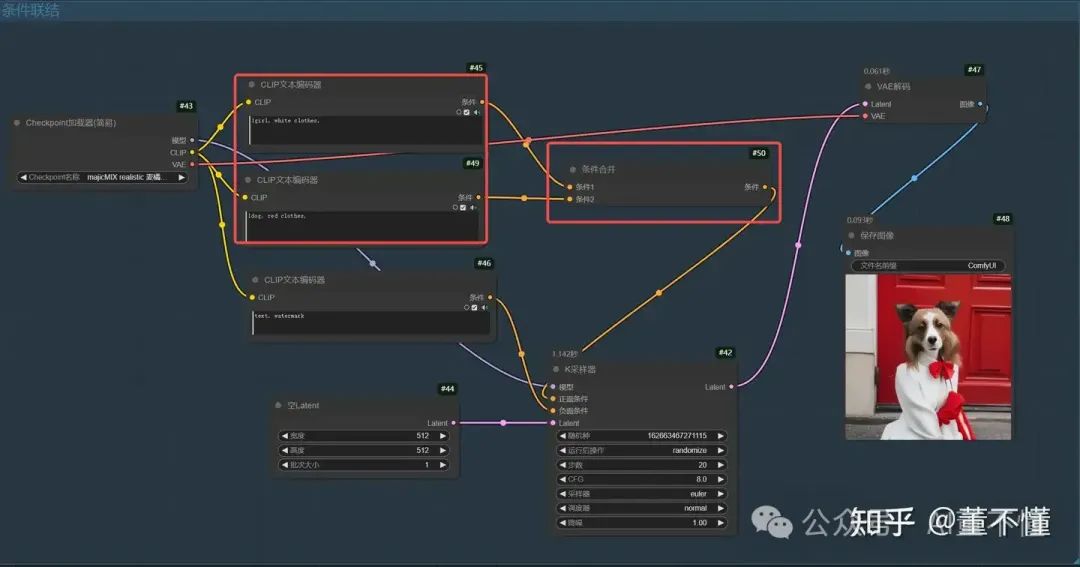
条件1:1girl, white clothes,
条件2:1dog, red clothes,
【条件合并】在合并提示词的时候,如果存在不同角色,会将两个角色进行融合,生成人不人狗不狗的画面。
4、条件平均

【条件平均】的系数为1,第一个条件生效,系数=0,第二个条件生效。介于0和1之间,则两个条件融合生效。
5、unCLIP条件
可以将一种风格或内容从一张图像传递到另一张图像,这在艺术创作和设计中非常有用,也就是说它可以参考其他图像的风格,结合提示词生成参考图风格的画面
需要用到的节点

CLIP视觉加载器:用于加载clip模型,提供学习图像特征基础能力
CLIP视觉编码:学习图像特征引擎
unCLIP条件:将学习到的图像特征输送到正面条件
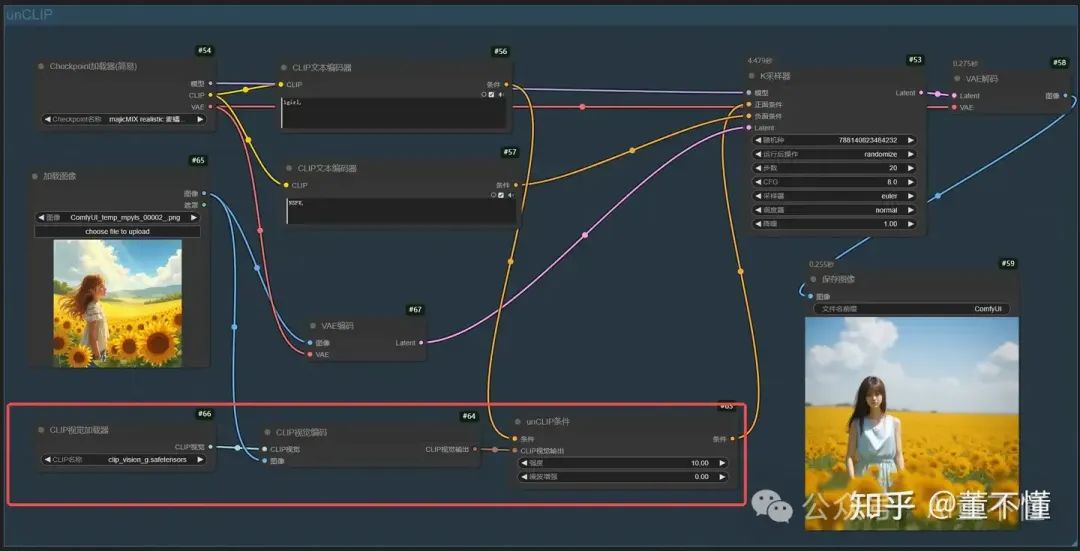
可以看到,生成的图像和原图的风格是一致的。
6、SVD_图像到视频_条件
安装插件【ComfyUI-VideoHelperSuite】,用于合成图像批次形成视频。
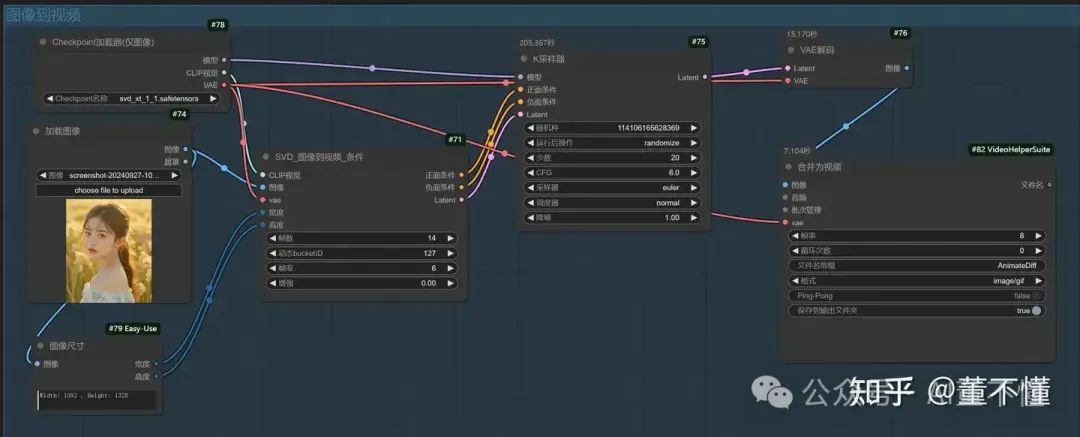
视频路径:ComfyUI_windows_portable_nvidia\ComfyUI\output
7、SZ123条件
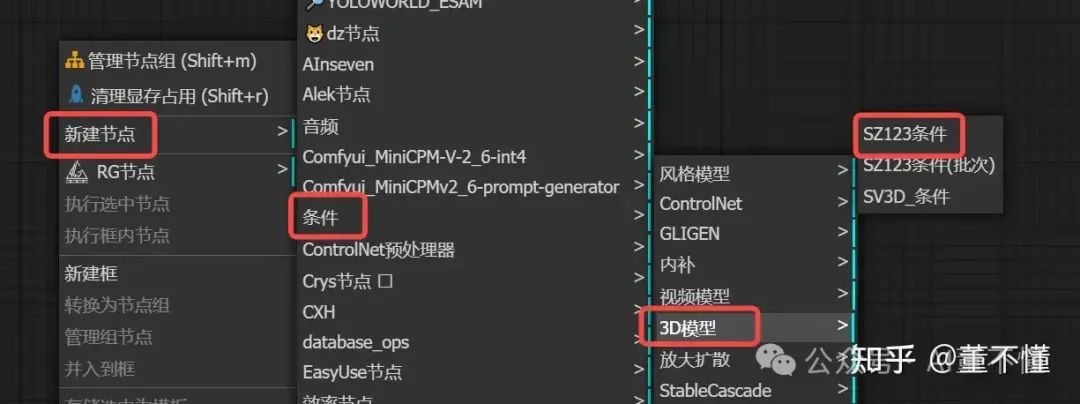

【注意】
1、宽高为256
2、俯仰角是垂直方向上的旋转,角度大于0,表示向上旋转,角度小于0,表示向下旋转
3、方位角是水平方向上的旋转,角度大于0,表示向右旋转,角度小于0,表示向左旋转
8、SZ123条件(批次)
这个节点可以按照一定的数值进行角度递增,从而实现批量旋转

这个节点比【SZ123条件】多了俯仰角增量和方位角增量,设置批次大小,就可以批量生成不同角度的图像了。
9、InstructPixToPix条件
这个条件可以让原图主体不变的情况下,改变风格,如下图,女孩出现在下雪场景
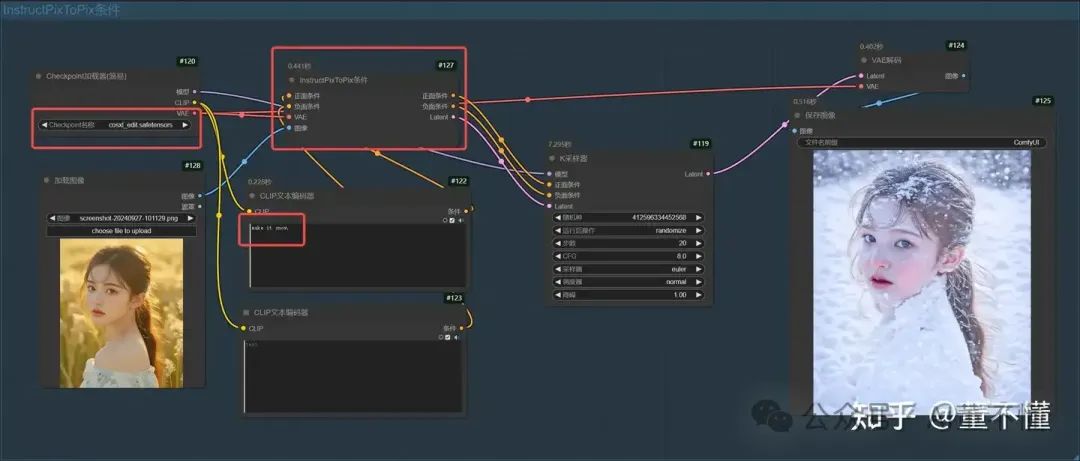
提示词:make it snow
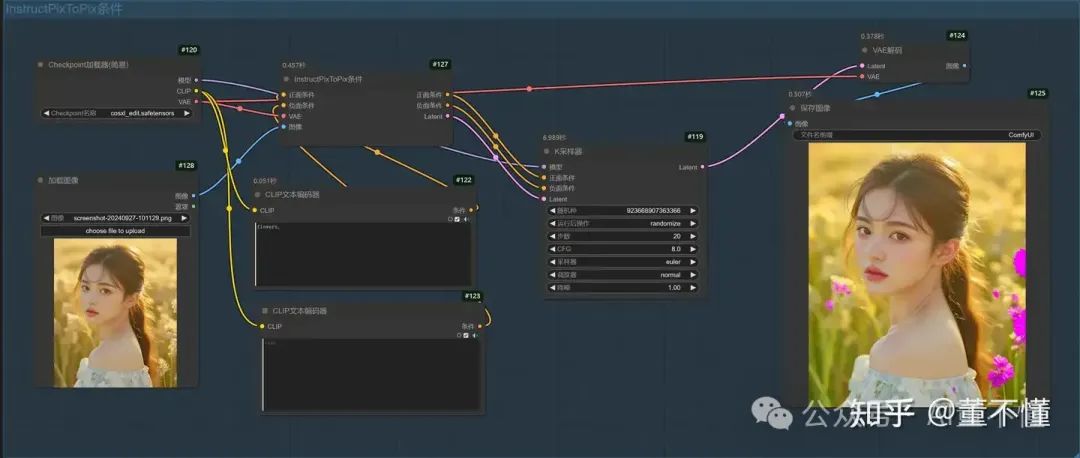
flowers,
1、大模型使用cosxl_edit.safetensors
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









