






前言
最近可灵悄悄的在抱抱脸空间上线了AI换装,结果被老外玩出花儿来。


也有老实的给自己AI换装的

界面是这样的。

已经预设了一些范例图片,也可以自己上传。只需要传一张人物图片和一张服装图片,就能生成换装照。速度也非常快,只要35秒。
我前面文章已经介绍过一个AI换装的网站,那个是有积分限制,可灵这个目前还是免费随便玩。
我上手试玩一下,还是给里面4个老熟人换一下装。




效果不错,衣服上身很自然。
我以前说过,AI换装不是新鲜事物了。早在5年前就有相关论文和项目出现。

只是随着各个基于其理论的模型不断迭代,现在AI换装已经慢慢可以应用于实际需求了。不论是恶搞整蛊,自拍显摆,还是商业化的电商产业应用。
4年前虚拟试衣的相关论文发表后,不断出现很多类似衍生项目和模型。
2020年首尔国立科技大学的CP-VTON+: Clothing Shape and Texture Preserving Image-Based Virtual Try-On基于图像的服装形状和纹理保留虚拟试穿。

2021年香港大学的Parser-Free Virtual Try-on via Distilling Appearance Flows通过提炼外观流实现无解析器虚拟试穿。

2022年英国萨里大学的Style-Based Global Appearance Flow for Virtual Try-On基于风格的虚拟试穿全局外观流程。

2023年中山大学的GP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning通过协作局部流全局解析学习实现通用虚拟试穿。

今年更是呈爆发式发布。比较知名的有OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on基于服装融合的潜空间扩散技术,实现可控虚拟试穿,IDM-VTON: Improving Diffusion Models for Authentic Virtual Try-on in the Wild改进扩散模型,实现真实的野外虚拟试穿,Magic Clothing: Controllable Garment-Driven Image Synthesis可控服装驱动的图像合成,等等。
可灵没有说明其用的什么底模,我用本地部署的CatVTON模型生成结果与之对比,发现两者相差不大,我猜这大概是可灵类似于VTON的一种自研模型。
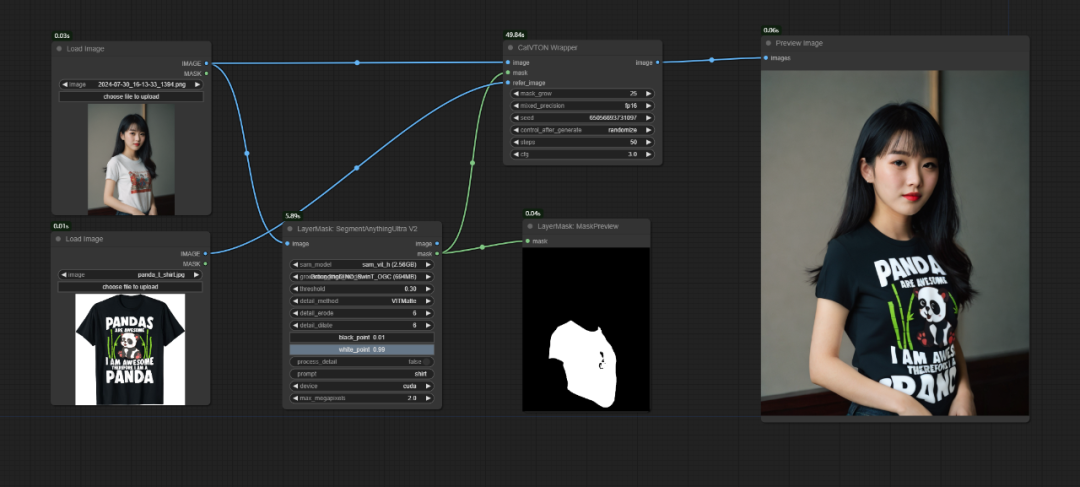
排列的第三张是可灵AI换装生成,最后一张是我用本地部署的CatVTON模型生成的。



CatVTON的效果跟可灵这个AI换装效果非常接近,偶尔甚至比可灵的服装还原度更好。这个也是中山大学的项目,全称是CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models只需要串联使用扩散模型进行虚拟试穿。
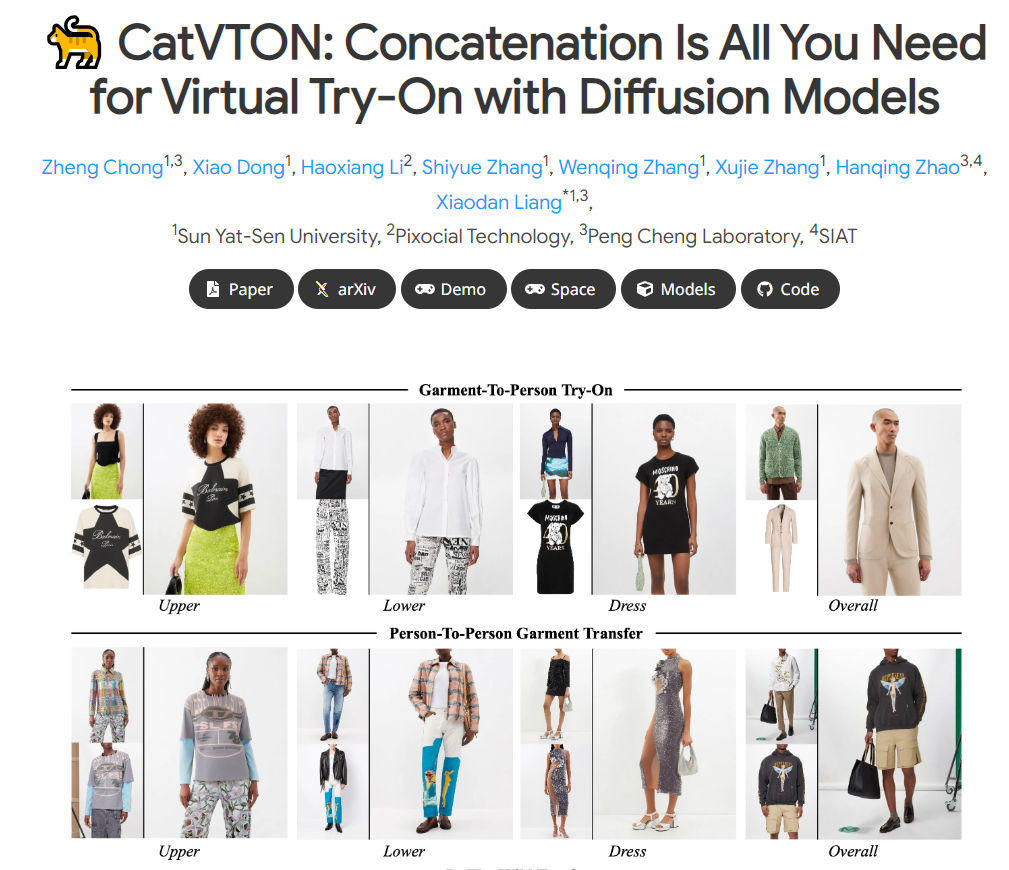
CatVTON的优点在于(1)轻量级网络。只使用原有的扩散模块,无需额外的网络模块。(2)参数高效训练。通过实验确定了与试穿相关的模块,仅训练了 49.57M 的参数(约占主干网络参数的 5.51%)就实现了高质量的试穿效果。(3)简化推理。CatVTON 消除了所有不必要的条件和预处理步骤,包括姿势估计、人体解析和文本输入,虚拟试穿过程只需要服装参考、目标人物图像和面具。大量实验表明,与基线方法相比,CatVTON 以更少的先决条件和可训练参数实现了卓越的定性和定量结果。此外,尽管使用只有 73K 个样本的开源数据集,CatVTON 在野外场景中仍表现出良好的泛化能力。
这个AI项目通过Comfyui本地部署需要8G显存,效果是目前我能找到的最好的AI换装工作流。
下面说一下在本地部署这个CatVTON工作流。
首先在Comfyui中安装CatVTON插件。这个插件有两个,一个是官方的插件,另一个是第三方大神开发的ComfyUI_CatVTON_Wrapper。我用的后一种,因为官方的插件安装把我的Comfyui干崩溃了。
这个ComfyUI_CatVTON_Wrapper插件的作者chflame163也是大名鼎鼎的ComfyUI_LayerStyle插件的作者,这个CatVTON工作流同时也需要用到ComfyUI_LayerStyle插件。
然后需要下载相关模型到Comfyui\models目录下,作者已经贴心的将模型文件放到百度网盘和谷歌网盘里。
衣服图片最好是只有单独服装的蒙版图片,如果不好找,也可以用ComfyUI_LayerStyle中的抠图工作流将服装蒙版抠出来。
最后补充一下,可灵和CatVTON的AI换装都还算不上完美,基本上半身生成效果较好,个别服装和身体细节生成效果会有差异。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
营销七
如何训练LorA
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!

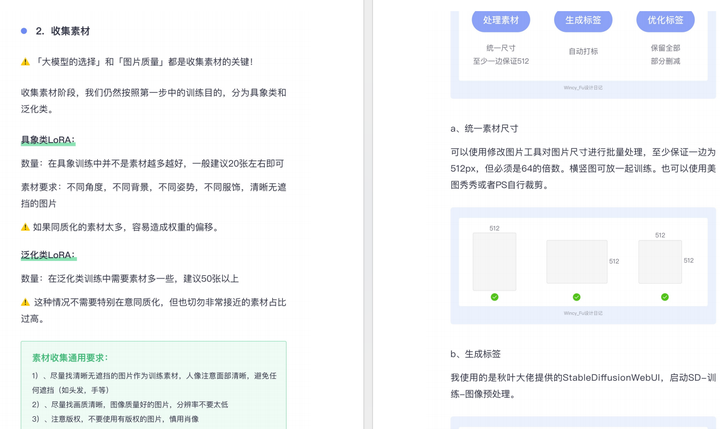
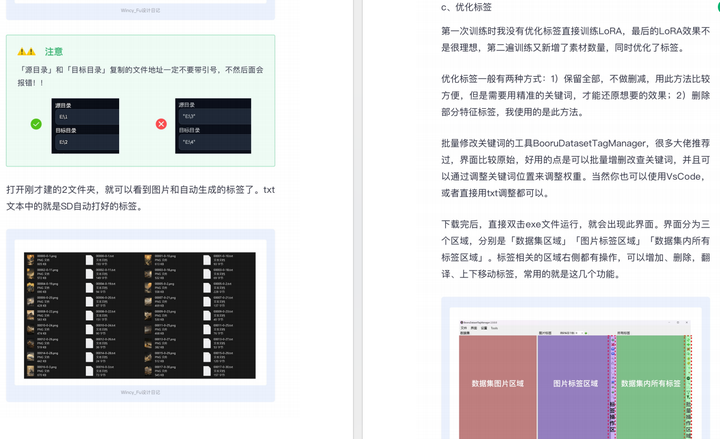
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









