








一、导言
PP-LCNet是一种专为Intel CPU设计的轻量级卷积神经网络,旨在提升在多任务上的性能表现。该网络通过结合MKLDNN加速策略,优化了在CPU上的推理速度,同时保持了模型的准确性。论文中提出了一系列技术改进措施,在几乎不增加延迟的前提下提高了网络的准确度,使得PP-LCNet在分类任务上显著超越了以往具有相同推理时间的网络结构,并且在对象检测、语义分割等计算机视觉下游任务上也展现出优越性能。
PP-LCNet基于MobileNetV1的深度可分离卷积(DepthSepConv)作为基本构建模块,这种模块不含捷径操作,避免了如concat或elementwise-add这类会降低推理速度的操作,而且已被Intel CPU加速库深入优化,其推理速度超越了其他轻量级网络结构。通过堆叠这些模块形成了一个基础网络(BaseNet),并结合一些现有技术进一步发展成更强大的网络——PP-LCNet。
研究中探索的提升准确度而不增加延迟的方法包括使用更好的激活函数(例如h-swish)、引入大尺寸卷积核、添加Squeeze-and-Excitation(SE)模块以及调整最后的1x1卷积层并采用dropout策略。实验结果显示,这些技术的累积应用显著提升了模型的准确率,同时保持了较快的推理速度。
在不同任务上的评估结果表明,PP-LCNet在COCO数据集上的目标检测任务中,与MobileNetV3相比,以更低的延迟实现了更高的mAP值;在Cityscapes数据集的语义分割任务中,PP-LCNet-0.5x不仅提高了mIoU指标,还大幅降低了推理时间。
该网络利用MKLDNN加速策略,在保持低延迟的同时,显著提高了轻量级模型在多种任务上的性能。主要优点总结如下:
-
高性能与低延迟并重:PP-LCNet在不增加推理时间的前提下,通过一系列技术改进提升了网络的准确性,超越了同类网络结构在分类任务上的表现,并且在计算机视觉下游任务,如目标检测、语义分割等方面也展现出了优越性能。
-
针对CPU优化设计:考虑到MKLDNN在Intel CPU上的限制,研究重新思考了适用于Intel CPU的轻量化模型设计元素,解决了如何在不增加延迟的情况下增强特征表示能力、提高轻量模型准确性的关键问题,并探索了有效结合不同轻量化设计策略的方法。
-
综合策略提升精度与速度平衡:论文总结了一系列在不增加推理时间前提下提高精度的方法,并展示了如何组合这些方法以获得更好的精度-速度平衡。提出了设计轻量级CNN的一般规则,为基于CPU构建CNN的研究人员提供了新思路。
-
影响与启示:PP-LCNet不仅在多个视觉任务上显示了强大的性能,还缩小了神经架构搜索(NAS)的搜索空间,为快速获取轻量级模型提供了可能。未来工作将探索利用NAS进一步获得更快、更强大的模型。
-
实验验证与实现细节:研究通过广泛实验验证了方法的有效性,并公开了基于PaddlePaddle框架实现的代码及预训练模型,便于其他研究人员复现和进一步研究。
论文地址:PP-LCNet论文地址
代码地址:PP-LCNet代码地址

二、准备工作
首先在YOLOv5/v7项目文件下的models文件夹下创建新的文件pplcnet.py
导入如下代码
from models.common import *
NET_CONFIG = {
"blocks2":
# k, in_c, out_c, s, use_se
[[3, 16, 32, 1, False]],
"blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
"blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
"blocks5": [[3, 128, 256, 2, False], [5, 256, 256, 1, False],
[5, 256, 256, 1, False], [5, 256, 256, 1, False],
[5, 256, 256, 1, False], [5, 256, 256, 1, False]],
"blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True]]
}
BLOCK_LIST = ["blocks2", "blocks3", "blocks4", "blocks5", "blocks6"]
def make_divisible_LC(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class HardSwish(nn.Module):
def __init__(self, inplace=True):
super(HardSwish, self).__init__()
self.relu6 = nn.ReLU6(inplace=inplace)
def forward(self, x):
return x * self.relu6(x + 3) / 6
class HardSigmoid(nn.Module):
def __init__(self, inplace=True):
super(HardSigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=inplace)
def forward(self, x):
return (self.relu6(x + 3)) / 6
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
HardSigmoid()
)
def forward(self, x):
b, c, h, w = x.size()
y = self.avgpool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class DepthwiseSeparable(nn.Module):
def __init__(self, inp, oup, dw_size, stride, use_se=False):
super(DepthwiseSeparable, self).__init__()
self.use_se = use_se
self.stride = stride
self.inp = inp
self.oup = oup
self.dw_size = dw_size
self.dw_sp = nn.Sequential(
nn.Conv2d(self.inp, self.inp, kernel_size=self.dw_size, stride=self.stride,
padding=autopad(self.dw_size, None), groups=self.inp, bias=False),
nn.BatchNorm2d(self.inp),
HardSwish(),
nn.Conv2d(self.inp, self.oup, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(self.oup),
HardSwish(),
)
self.se = SELayer(self.oup)
def forward(self, x):
x = self.dw_sp(x)
if self.use_se:
x = self.se(x)
return x
class PPLC_Conv(nn.Module):
def __init__(self, scale):
super(PPLC_Conv, self).__init__()
self.scale = scale
self.conv = nn.Conv2d(3, out_channels=make_divisible_LC(16 * self.scale),
kernel_size=3, stride=2, padding=1, bias=False)
def forward(self, x):
return self.conv(x)
class PPLC_Block(nn.Module):
def __init__(self, scale, block_num):
super(PPLC_Block, self).__init__()
self.scale = scale
self.block_num = BLOCK_LIST[block_num]
self.block = nn.Sequential(*[
DepthwiseSeparable(inp=make_divisible_LC(in_c * self.scale),
oup=make_divisible_LC(out_c * self.scale),
dw_size=k, stride=s, use_se=use_se)
for i, (k, in_c, out_c, s, use_se) in enumerate(NET_CONFIG[self.block_num])
])
def forward(self, x):
return self.block(x)

其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.pplcnet import *并搜索def parse_model(d, ch)
定位到如下行添加以下代码
elif m is PPLC_Conv:
c2 = args[0]
args = args[1:]
elif m is PPLC_Block:
c2 = args[0]
args = args[1:]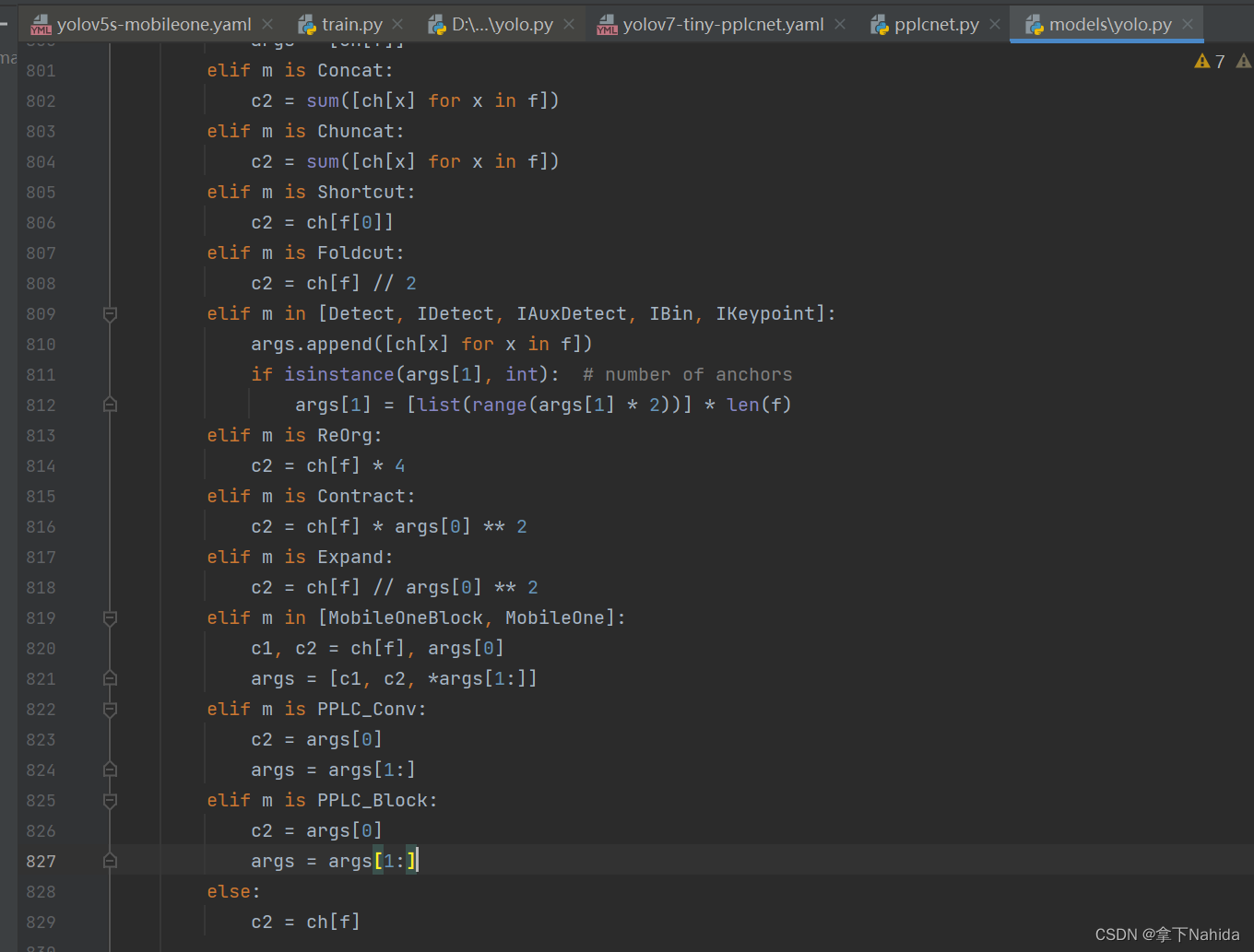
三、YOLOv7-tiny改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov7-tiny-pplcnet.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
[[-1, 1, PPLC_Conv, [16, 1]],#0
[-1, 1, PPLC_Block, [32, 1, 0]],
[-1, 1, PPLC_Block, [64, 1, 1]],
[-1, 1, PPLC_Block, [128, 1, 2]],
[-1, 1, PPLC_Block, [256, 1, 3]],
[-1, 1, PPLC_Block, [512, 1, 4]],#5
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[4, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 24
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[3, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 34
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 24], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 42
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 14], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 50
[34, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[42, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[50, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[51,52,53], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 432 models.pplcnet.PPLC_Conv [1]
1 -1 1 880 models.pplcnet.PPLC_Block [1, 0]
2 -1 1 8480 models.pplcnet.PPLC_Block [1, 1]
3 -1 1 31296 models.pplcnet.PPLC_Block [1, 2]
4 -1 1 448640 models.pplcnet.PPLC_Block [1, 3]
5 -1 1 481536 models.pplcnet.PPLC_Block [1, 4]
6 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
7 -2 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
8 -1 1 0 models.common.SP [5]
9 -2 1 0 models.common.SP [9]
10 -3 1 0 models.common.SP [13]
11 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
12 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
13 [-1, -7] 1 0 models.common.Concat [1]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
15 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
16 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
17 4 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
18 [-1, -2] 1 0 models.common.Concat [1]
19 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
20 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
21 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
22 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
23 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
24 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
25 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
26 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
27 3 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
28 [-1, -2] 1 0 models.common.Concat [1]
29 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
30 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
31 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
32 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
33 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
34 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
35 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
36 [-1, 24] 1 0 models.common.Concat [1]
37 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
38 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
39 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
40 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
41 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
42 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
43 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
44 [-1, 14] 1 0 models.common.Concat [1]
45 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
46 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
47 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
48 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
49 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
50 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
51 34 1 8448 models.common.Conv [64, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
52 42 1 33280 models.common.Conv [128, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
53 50 1 132096 models.common.Conv [256, 512, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
54 [51, 52, 53] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 411 layers, 3145580 parameters, 3145580 gradients, 6.2 GFLOPS运行后若打印出如上文本代表改进成功。
四、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-pplcnet.yaml,导入如下代码。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
[[-1, 1, PPLC_Conv, [16, 1]],
[-1, 1, PPLC_Block, [32, 1, 0]],
[-1, 1, PPLC_Block, [64, 1, 1]],
[-1, 1, PPLC_Block, [128, 1, 2]],
[-1, 1, PPLC_Block, [256, 1, 3]],
[-1, 1, PPLC_Block, [512, 1, 4]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 6], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 432 models.pplcnet.PPLC_Conv [1]
1 -1 1 880 models.pplcnet.PPLC_Block [1, 0]
2 -1 1 8480 models.pplcnet.PPLC_Block [1, 1]
3 -1 1 31296 models.pplcnet.PPLC_Block [1, 2]
4 -1 1 448640 models.pplcnet.PPLC_Block [1, 3]
5 -1 1 481536 models.pplcnet.PPLC_Block [1, 4]
6 -1 1 131584 models.common.Conv [512, 256, 1, 1]
7 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
8 [-1, 4] 1 0 models.common.Concat [1]
9 -1 1 361984 models.common.C3 [512, 256, 1, False]
10 -1 1 33024 models.common.Conv [256, 128, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 3] 1 0 models.common.Concat [1]
13 -1 1 90880 models.common.C3 [256, 128, 1, False]
14 -1 1 147712 models.common.Conv [128, 128, 3, 2]
15 [-1, 10] 1 0 models.common.Concat [1]
16 -1 1 296448 models.common.C3 [256, 256, 1, False]
17 -1 1 590336 models.common.Conv [256, 256, 3, 2]
18 [-1, 6] 1 0 models.common.Concat [1]
19 -1 1 1182720 models.common.C3 [512, 512, 1, False]
20 [13, 16, 19] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 367 layers, 3822134 parameters, 3822134 gradients, 8.2 GFLOPs运行后若打印出如上文本代表改进成功。
五、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-pplcnet.yaml,导入如下代码。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
[[-1, 1, PPLC_Conv, [16, 1]],
[-1, 1, PPLC_Block, [32, 1, 0]],
[-1, 1, PPLC_Block, [64, 1, 1]],
[-1, 1, PPLC_Block, [128, 1, 2]],
[-1, 1, PPLC_Block, [256, 1, 3]],
[-1, 1, PPLC_Block, [512, 1, 4]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 6], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 432 models.pplcnet.PPLC_Conv [1]
1 -1 1 880 models.pplcnet.PPLC_Block [1, 0]
2 -1 1 8480 models.pplcnet.PPLC_Block [1, 1]
3 -1 1 31296 models.pplcnet.PPLC_Block [1, 2]
4 -1 1 448640 models.pplcnet.PPLC_Block [1, 3]
5 -1 1 481536 models.pplcnet.PPLC_Block [1, 4]
6 -1 1 65792 models.common.Conv [512, 128, 1, 1]
7 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
8 [-1, 4] 1 0 models.common.Concat [1]
9 -1 1 107264 models.common.C3 [384, 128, 1, False]
10 -1 1 8320 models.common.Conv [128, 64, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 3] 1 0 models.common.Concat [1]
13 -1 1 27008 models.common.C3 [192, 64, 1, False]
14 -1 1 36992 models.common.Conv [64, 64, 3, 2]
15 [-1, 10] 1 0 models.common.Concat [1]
16 -1 1 74496 models.common.C3 [128, 128, 1, False]
17 -1 1 147712 models.common.Conv [128, 128, 3, 2]
18 [-1, 6] 1 0 models.common.Concat [1]
19 -1 1 296448 models.common.C3 [256, 256, 1, False]
20 [13, 16, 19] 1 8118 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]
Model Summary: 367 layers, 1743414 parameters, 1743414 gradients, 4.2 GFLOPs运行后打印如上代码说明改进成功。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!
















 6295
6295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









