








一、导言
论文《VanillaNet: 极简主义在深度学习中的力量》由华为诺亚方舟实验室和悉尼大学的研究人员合作完成,主要贡献是提出了一种新的神经网络架构——VanillaNet。该架构的核心设计理念是追求极简主义,即在不依赖高深度、捷径连接(如残差连接)和复杂的自注意力机制的情况下,依然能够达到与先进深度神经网络及视觉变换器相媲美的性能。
VanillaNet的每层设计都旨在保持结构的紧凑和直接,通过训练后对非线性激活函数进行剪枝,使得模型在保持原始架构的同时,能够有效提升效率和性能。论文展示了这种简化设计如何克服深度学习模型固有的复杂性挑战,使其成为资源有限环境下的理想选择。此外,VanillaNet的易理解性和高度简化的特性为模型的高效部署开辟了新途径。
实验部分在COCO数据集上进行了评估,涵盖了目标检测和语义分割任务,结果显示,尽管VanillaNet在计算量(FLOPs)和参数量上可能高于某些轻量级模型(如Swin Transformer),但它实现了更高的推理速度(FPS),验证了极简架构在实际应用中的有效性和潜力。
-
简约而强大:VanillaNet通过避免深度过深、捷径连接以及复杂的自注意力机制等设计,展现了简洁却强大的性能。每一层都被精心设计为紧凑且直接,旨在以最少的计算成本保持特征图信息。
-
优化与复杂性挑战:该研究针对优化难度和Transformer模型固有的复杂性,倡导向简单化范式的转变。VanillaNet通过其简洁的架构克服了这些内在复杂性挑战,非常适合资源受限环境。
-
易于理解和部署:VanillaNet的架构简单易懂且高度简化,为高效部署开辟了新可能。这种高可解释性和简化设计降低了实现难度,有利于实际应用。
-
性能表现:实验表明,VanillaNet在图像分类任务上的性能可与知名深度神经网络及视觉变换器相媲美,证明了极简主义在深度学习中的潜力。
-
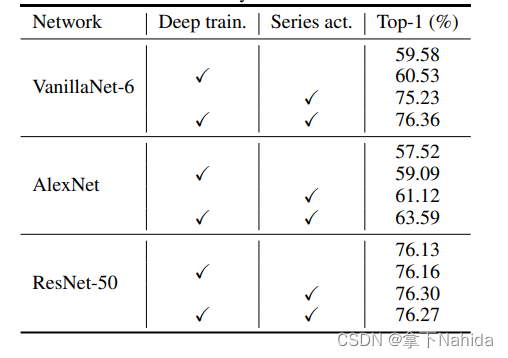
深度训练策略:提出了一种深度训练技术,通过初始阶段训练两个带有激活函数的卷积层而非单一卷积层,随着训练轮次增加,逐步将激活函数简化为恒等映射。这增强了网络的非线性,提高了训练和测试性能。
-
无捷径设计:VanillaNet未采用捷径连接,不仅简化了网络结构,而且实验证明添加捷径对性能提升不大,进一步简化了实现过程。
-
实时处理能力:VanillaNet-9仅用2.91毫秒即可完成GPU推理,比类似性能的ResNet-50和ConvNextV2-P快50%以上,显示了在实时处理上的巨大潜力。
-
扩展性与灵活性:通过调整通道数和池化大小,VanillaNet-13-1.5×达到了83.11%的Top-1准确率,表明即使在大规模图像分类任务中,通过扩展VanillaNet仍能获得与深网络相似的高性能。
-
速度与精度权衡:研究表明,在计算能力充足的情况下,VanillaNet在所有架构中实现了最佳的速度-精度平衡,低GPU延迟彰显了其优越性。
综上所述,该论文不仅提出了一个创新的神经网络架构,还对当前深度学习领域中追求复杂度以换取性能提升的趋势提出了挑战,为未来的模型设计提供了新的方向,即通过极简设计同样能达到顶尖的性能表现。
二、准备工作
首先在YOLOv5/v7项目文件下的models文件夹下创建新的文件vanillanet.py
导入如下代码
from models.common import *
class activation(nn.ReLU):
def __init__(self, dim, act_num=3, deploy=False):
super(activation, self).__init__()
self.act_num = act_num
self.deploy = deploy
self.dim = dim
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))
if deploy:
self.bias = torch.nn.Parameter(torch.zeros(dim))
else:
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6)
nn.init.trunc_normal_(self.weight, std=.02)
def forward(self, x):
if self.deploy:
return torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, self.bias, padding=self.act_num, groups=self.dim)
else:
return self.bn(torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, padding=self.act_num, groups=self.dim))
def _fuse_bn_tensor(self, weight, bn):
kernel = weight
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (0 - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)
self.weight.data = kernel
self.bias = torch.nn.Parameter(torch.zeros(self.dim))
self.bias.data = bias
self.__delattr__('bn')
self.deploy = True
class VanillaStem(nn.Module):
def __init__(self, in_chans=3, dims=96,
k=0, s=0, p=None, g=0, act_num=3, deploy=False, ada_pool=None, **kwargs):
super().__init__()
self.deploy = deploy
stride, padding = (4, 0) if not ada_pool else (3, 1)
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims, kernel_size=k, stride=stride, padding=padding),
activation(dims, act_num, deploy=self.deploy)
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims, kernel_size=k, stride=stride, padding=padding),
nn.BatchNorm2d(dims, eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims, dims, kernel_size=1, stride=1),
nn.BatchNorm2d(dims, eps=1e-6),
activation(dims, act_num)
)
self.act_learn = 1
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
if self.deploy:
x = self.stem(x)
else:
x = self.stem1(x)
x = torch.nn.functional.leaky_relu(x, self.act_learn)
x = self.stem2(x)
return x
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
self.stem2[2].switch_to_deploy()
kernel, bias = self._fuse_bn_tensor(self.stem1[0], self.stem1[1])
self.stem1[0].weight.data = kernel
self.stem1[0].bias.data = bias
kernel, bias = self._fuse_bn_tensor(self.stem2[0], self.stem2[1])
self.stem1[0].weight.data = torch.einsum('oi,icjk->ocjk', kernel.squeeze(3).squeeze(2),
self.stem1[0].weight.data)
self.stem1[0].bias.data = bias + (self.stem1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)
self.stem = torch.nn.Sequential(*[self.stem1[0], self.stem2[2]])
self.__delattr__('stem1')
self.__delattr__('stem2')
self.deploy = True
class VanillaBlock(nn.Module):
def __init__(self, dim, dim_out, k=0, stride=2, p=None, g=0, ada_pool=None, act_num=3, deploy=False):
super().__init__()
self.act_learn = 1
self.deploy = deploy
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
if not ada_pool:
self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)
else:
self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))
self.act = activation(dim_out, act_num, deploy=self.deploy)
def forward(self, x):
if self.deploy:
x = self.conv(x)
else:
x = self.conv1(x)
# We use leakyrelu to implement the deep training technique.
x = torch.nn.functional.leaky_relu(x, self.act_learn)
x = self.conv2(x)
x = self.pool(x)
x = self.act(x)
return x
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.conv1[0], self.conv1[1])
self.conv1[0].weight.data = kernel
self.conv1[0].bias.data = bias
# kernel, bias = self.conv2[0].weight.data, self.conv2[0].bias.data
kernel, bias = self._fuse_bn_tensor(self.conv2[0], self.conv2[1])
self.conv = self.conv2[0]
self.conv.weight.data = torch.matmul(kernel.transpose(1, 3),
self.conv1[0].weight.data.squeeze(3).squeeze(2)).transpose(1, 3)
self.conv.bias.data = bias + (self.conv1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)
self.__delattr__('conv1')
self.__delattr__('conv2')
self.act.switch_to_deploy()
self.deploy = True
其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.vanillanet import *并搜索def parse_model(d, ch)
定位到如下行添加以下代码
VanillaBlock, VanillaStem, # VanillaNet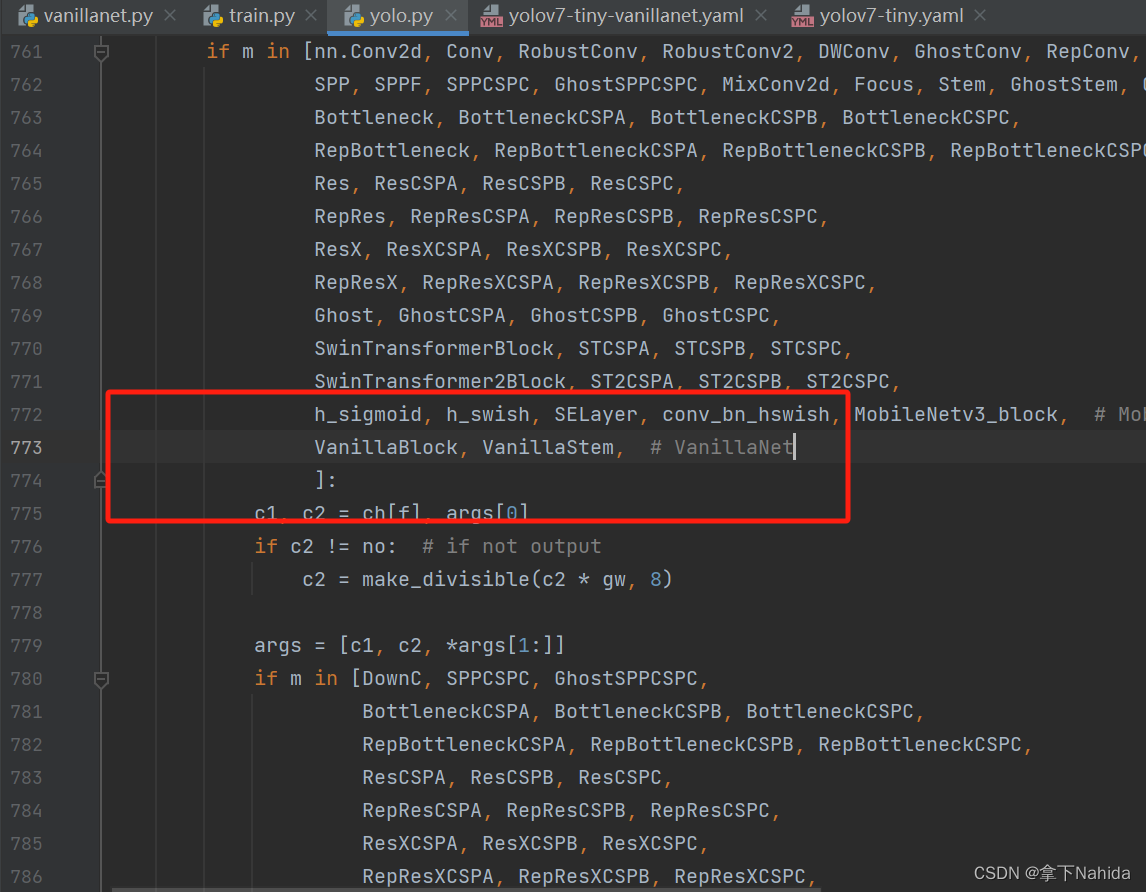
三、YOLOv7-tiny改进工作
完成二后,在YOLOv7项目文件下的cfg/training文件夹下创建新的文件yolov7-tiny-vanillanet.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
activation: nn.ReLU()
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, VanillaStem, [64, 4, 4, None, 1]], # 0-P1/4
[-1, 1, VanillaBlock, [256, 1, 2, None, 1]], # 1-P2/8
[-1, 1, VanillaBlock, [512, 1, 2, None, 1]], # 2-P3/16
[-1, 1, VanillaBlock, [1024, 1, 2, None, 1]], # 3-P4/32
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], #4
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 12
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 22
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 32
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 22], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 40
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 12], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 48
[32, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[40, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[48, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[49,50,51], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
最后,修改train.py的cfg参数为刚刚创建的yolov7-tiny-vanillanet.yaml,运行。
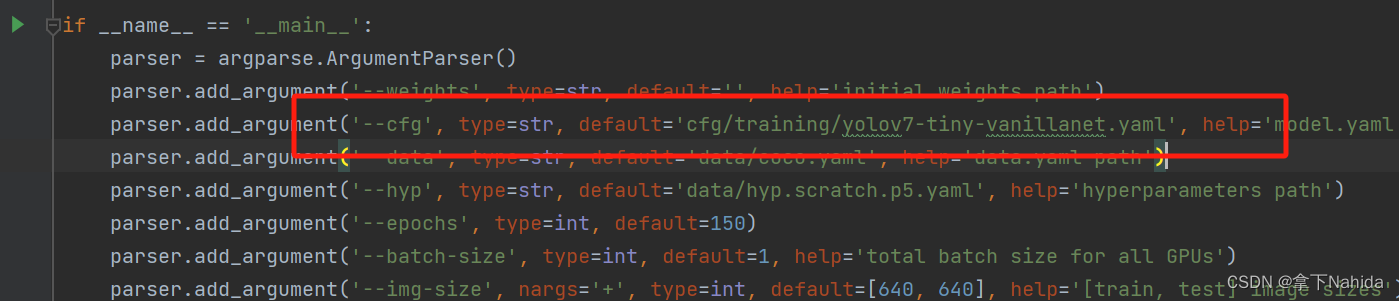
from n params module arguments
0 -1 1 10816 models.vanillanet.VanillaStem [3, 64, 4, 4, None, 1]
1 -1 1 34496 models.vanillanet.VanillaBlock [64, 256, 1, 2, None, 1]
2 -1 1 225024 models.vanillanet.VanillaBlock [256, 512, 1, 2, None, 1]
3 -1 1 843264 models.vanillanet.VanillaBlock [512, 1024, 1, 2, None, 1]
4 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
5 -2 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
6 -1 1 0 models.common.SP [5]
7 -2 1 0 models.common.SP [9]
8 -3 1 0 models.common.SP [13]
9 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
10 -1 1 262656 models.common.Conv [1024, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
11 [-1, -7] 1 0 models.common.Concat [1]
12 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
13 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
16 [-1, -2] 1 0 models.common.Concat [1]
17 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
18 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
19 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
20 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
21 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
22 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
23 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
24 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
25 1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
26 [-1, -2] 1 0 models.common.Concat [1]
27 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
28 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
29 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
30 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
31 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
32 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
33 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
34 [-1, 22] 1 0 models.common.Concat [1]
35 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
36 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
37 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
38 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
39 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
40 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
41 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
42 [-1, 12] 1 0 models.common.Concat [1]
43 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
44 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
45 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
46 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
47 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
48 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
49 32 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
50 40 1 295424 models.common.Conv [128, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
51 48 1 1180672 models.common.Conv [256, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
52 [49, 50, 51] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 204 layers, 4967276 parameters, 4967276 gradients, 13.0 GFLOPS若打印出如上文本代表改进成功。
四、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5n-vanillanet.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, VanillaStem, [64, 4, 4, None, 1]], # 0-P1/4
[-1, 1, VanillaBlock, [256, 1, 2, None, 1]], # 1-P2/8
[-1, 1, VanillaBlock, [512, 1, 2, None, 1]], # 2-P3/16
[-1, 1, VanillaBlock, [1024, 1, 2, None, 1]], # 3-P4/32
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 7
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 1], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 11 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 14 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 4], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 17 (P5/32-large)
[[11,14,17], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
train.py修改
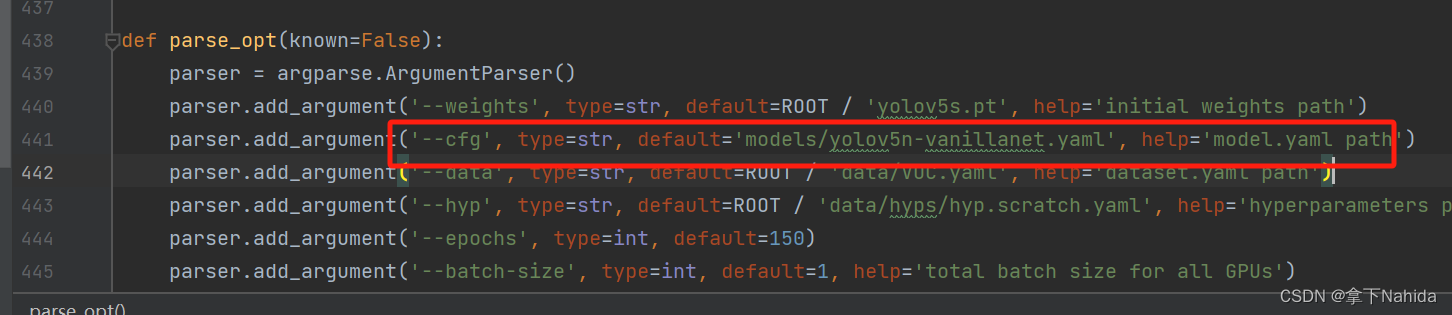
from n params module arguments
0 -1 1 1936 models.vanillanet.VanillaStem [3, 16, 4, 4, None, 1]
1 -1 1 4784 models.vanillanet.VanillaBlock [16, 64, 1, 2, None, 1]
2 -1 1 19392 models.vanillanet.VanillaBlock [64, 128, 1, 2, None, 1]
3 -1 1 63360 models.vanillanet.VanillaBlock [128, 256, 1, 2, None, 1]
4 -1 1 33024 models.common.Conv [256, 128, 1, 1]
5 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
6 [-1, 2] 1 0 models.common.Concat [1]
7 -1 1 90880 models.common.C3 [256, 128, 1, False]
8 -1 1 8320 models.common.Conv [128, 64, 1, 1]
9 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
10 [-1, 1] 1 0 models.common.Concat [1]
11 -1 1 22912 models.common.C3 [128, 64, 1, False]
12 -1 1 36992 models.common.Conv [64, 64, 3, 2]
13 [-1, 8] 1 0 models.common.Concat [1]
14 -1 1 74496 models.common.C3 [128, 128, 1, False]
15 -1 1 147712 models.common.Conv [128, 128, 3, 2]
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 296448 models.common.C3 [256, 256, 1, False]
18 [11, 14, 17] 1 8118 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]
Model Summary: 160 layers, 808374 parameters, 808374 gradients, 1.9 GFLOPs若打印出如上文本代表改进成功。
五、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-vanillanet.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, VanillaStem, [64, 4, 4, None, 1]], # 0-P1/4
[-1, 1, VanillaBlock, [256, 1, 2, None, 1]], # 1-P2/8
[-1, 1, VanillaBlock, [512, 1, 2, None, 1]], # 2-P3/16
[-1, 1, VanillaBlock, [1024, 1, 2, None, 1]], # 3-P4/32
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 7
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 1], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 11 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 14 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 4], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 17 (P5/32-large)
[[11,14,17], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
train.py修改
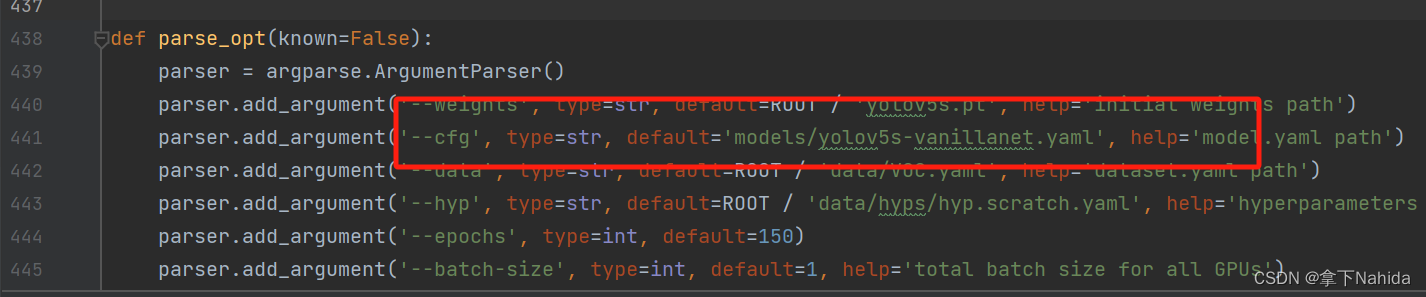
from n params module arguments
0 -1 1 4384 models.vanillanet.VanillaStem [3, 32, 4, 4, None, 1]
1 -1 1 12128 models.vanillanet.VanillaBlock [32, 128, 1, 2, None, 1]
2 -1 1 63360 models.vanillanet.VanillaBlock [128, 256, 1, 2, None, 1]
3 -1 1 225024 models.vanillanet.VanillaBlock [256, 512, 1, 2, None, 1]
4 -1 1 131584 models.common.Conv [512, 256, 1, 1]
5 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
6 [-1, 2] 1 0 models.common.Concat [1]
7 -1 1 361984 models.common.C3 [512, 256, 1, False]
8 -1 1 33024 models.common.Conv [256, 128, 1, 1]
9 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
10 [-1, 1] 1 0 models.common.Concat [1]
11 -1 1 90880 models.common.C3 [256, 128, 1, False]
12 -1 1 147712 models.common.Conv [128, 128, 3, 2]
13 [-1, 8] 1 0 models.common.Concat [1]
14 -1 1 296448 models.common.C3 [256, 256, 1, False]
15 -1 1 590336 models.common.Conv [256, 256, 3, 2]
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 1182720 models.common.C3 [512, 512, 1, False]
18 [11, 14, 17] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 160 layers, 3155766 parameters, 3155766 gradients, 7.2 GFLOPs
打印如上代码说明改进成功。

下一篇文章:【YOLOv5/v7改进系列】替换骨干网络为MobileOne
将会进行手把手的改进教学。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!



















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











