







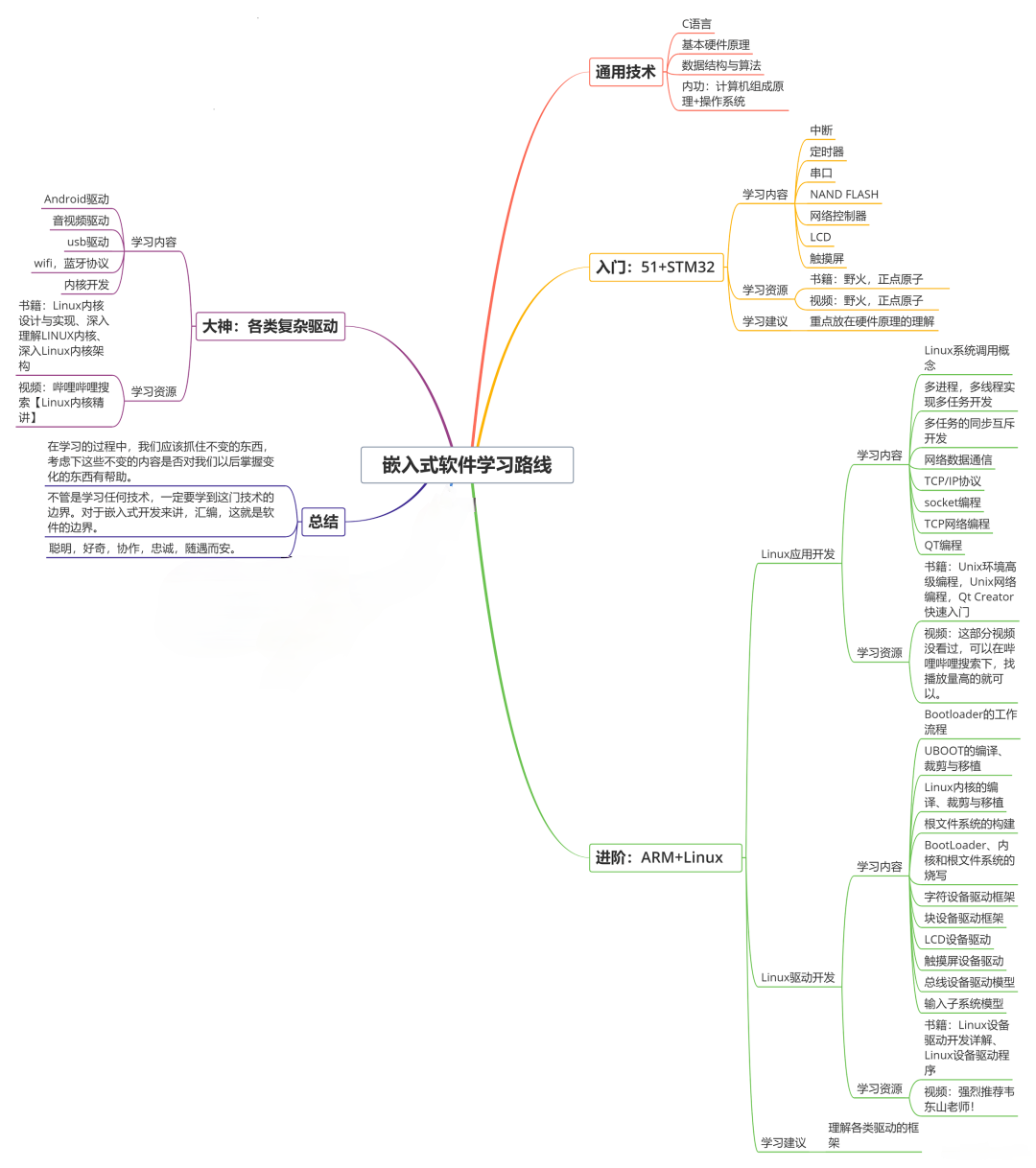
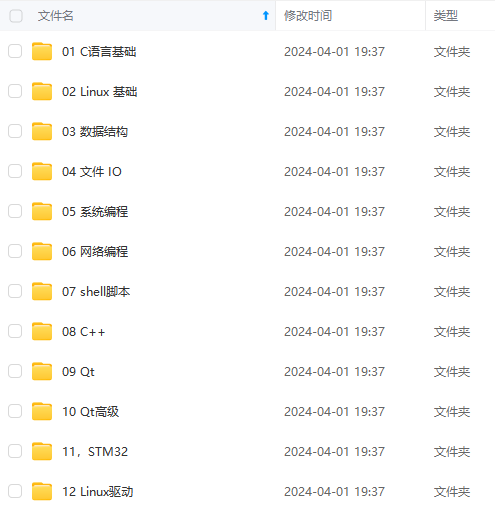
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
| ml | 机器学习库(Machine Learning Library, MLL)是一组可用于分类、回归和聚类目的的类和方法 |
| flann | 快速近似近邻库(Fast Library for Approximate Nearest Neighbors, FLANN)是一组非常适合快速近邻搜索的算法,用于多维空间中的聚类和搜索 |
| photo | 计算摄影,提供一些计算摄影的函数 |
| stitching | 图像拼接,实现了一个自动拼接全景图像的拼接流水线 |
| shape | 形状距离和匹配模块,可用于形状匹配、检索或比较 |
| superres | 超分辨率,包含一组可用于提高分辨率的类和方法 |
| videostab | 视频稳定,包含一组用于视频稳定的类和方法 |
| viz | 三维可视化工具,用于显示与场景交互的小部件 |
(3) OpenCV的工业应用
OpenCV 可以应用但不仅限于以下场景:二维和三维特征提取、街景图像拼接、人脸识别系统、手势识别、人机交互、动作识别、物体识别、自动检查和监视、分割与识别、医学图像分析、运动跟踪、增强现实、视频/图像搜索与检索、机器人与无人驾驶汽车导航与控制、驾驶员疲劳驾驶检测等。
1.2 OpenCV中像素关系
(1)坐标系
为了更好的展示 OpenCV 中的坐标系以及如何访问各个像素,查看以下低分辨率图像为例:
这个图片的尺寸是 32×41 像素,也就是说,这个图像有 1312 个像素。为了进一步说明,我们可以在每个轴上添加像素计数,如下图所示:
现在,我们来看看 ( x , y ) (x, y)(x,y) 形式的像素索引。请注意,像素索引起始值为零,这意味着左上角位于 ( 0 , 0 ) (0, 0)(0,0),而不是 ( 1 , 1 ) (1, 1)(1,1)。下面的图像,索引了 4 个单独的像素,图像的左上角是原点的坐标:
单个像素的信息可以从图像中提取,方法与 Python 中引用数组的单个元素相同。
(2)通道顺序
在 OpenCV 使用中,使用的颜色通道顺序为 BGR 颜色格式而不是 RGB 格式。可以在下图中看到三个通道的顺序:

BGR 图像的像素结构如下图所示,作为演示,图示详细说明了如何访问pixel(y=n, x=1):

Tips:OpenCV 的最初开发人员选择了 BGR 颜色格式(而不是 RGB 格式),是因为当时 BGR 颜色格式在软件供应商和相机制造商中非常流行,因此选择 BGR 是出于历史原因。
此外,也有其他 Python 包使用的是 RGB 颜色格式(例如,Matplotlib 使用 RGB 颜色格式,Matplotlib 是最流行的 2D Python 绘图库,提供多种绘图方法,可以查看 Python-Matplotlib 可视化获取更多详细信息)。因此,我们需要知道如何将图像从一种格式转换为另一种格式。
(3)在不同颜色空间中访问和操作OpenCV中的像素
本节将介绍如何使用 OpenCV 访问和读取像素值以及如何修改它们。此外,还将学习如何访问图像属性。如果想一次处理多个像素,则需要创建图像区域 (Region of Image, ROI)。
在 Python 中,图像表示为 NumPy 数组。因此,示例中包含的大多数操作都与 NumPy 相关,建议需要对 NumPy 包一些了解,才能更好明白示例代码的原理,但即使不了解也没关系,必要时会对所用函数进行讲解。
(4) 彩色图像访问和操作OpenCV中的像素
现在,我们来看看如何在 OpenCV 中处理BGR图像。如上所述,OpenCV 加载彩色图像时,蓝色通道是第一个,绿色通道是第二个,红色通道是第三个。
首先,使用 cv2.imread() 函数读取图像。图像应该在工作目录中,或者应该提供图片的完整路径。在本例中,读取 sigonghuiye.jpeg 图像并将其存储在img变量中:
img = cv2.imread('sigonghuiye.jpeg')
图像加载到 img 后,可以获得图像的一些属性。我们要从加载的图像中提取的第一个属性是 shape,它将告诉我们行、列和通道的数量(如果图像是彩色的)。我们将此信息存储在 dimensions 变量中:
dimensions = img.shape
第二个属性是图像的大小(img.size=图像高度 × 图像宽度 × 图像通道数):
total_number_of_elements= img.size
第三个属性是图像数据类型,可以通过 img.dtype 获得。因为像素值在 [0-255] 范围内,所以图像数据类型是 uint8 (unsigned char):
image_dtype = img.dtype
上面示例中,我们已经使用了 cv2.imshow() 函数来在窗口中显示图像,这里我们对其进行更详细的介绍,使用 cv2.imshow() 函数显示图像时,窗口会自动适应图像大小。此函数的第一个参数是窗口名,第二个参数是要显示的图像。在这种情况下,由于加载的图像已存储在 img 变量中,因此使用此变量作为第二个参数:
cv2.imshow("original image", img)
显示图像后,我们来介绍下键盘绑定函数——cv2.waitKey(),它为任何键盘事件等待指定的毫秒数。参数是以毫秒为单位的时间。当执行到此函数时,程序将暂停执行,当按下任何键后,程序将继续执行。如果毫秒数为 0 (cv2.waitKey(0)),它将无限期地等待键盘敲击事件:
cv2.waitKey(0)
要访问(读取)某个像素值,我们需要向 img 变量(包含加载的图像)提供所需像素的行和列,例如,要获得 ( x = 40 , y = 6 ) (x=40, y=6)(x=40,y=6) 处的像素值 :
(b, g, r) = img[6, 40]
我们在三个变量 (b, g, r) 中存储了三个像素值。请牢记 OpenCV 对彩色图像使用 BGR 格式。另外,我们可以一次仅访问一个通道。在本例中,我们将使用所需通道的行、列和索引进行索引。例如,要仅获取像素 ( x = 40 , y = 6 ) (x=40, y=6)(x=40,y=6) 处的蓝色值:
b = img[6, 40, 0]
像素值也可以以相同的方式进行修改。例如,要将像素 (x=40, y=6) 处设置为红色:
img[6, 40] = (0, 0, 255)
有时,需要处理某个区域而不是一个像素。在这种情况下,应该提供值的范围(也称切片),而不是单个值。例如,要获取图像的左上角:
top_left_corner = img[0:50, 0:50]
变量 top_left_corner 可以看做是另一个图像(比img小),但是我们可以用同样的方法处理它。
最后,如果想要关闭并释放所有窗口,需要使用 cv2.destroyAllWindows() 函数:
cv2.destroyAllWindows()
(5) 灰度图像访问和操作OpenCV中的像素
灰度图像只有一个通道。因此,在处理这些图像时会引入一些差异。我们将在这里重点介绍这些差异,相同的部分不再赘述。
同样,我们将使用 cv2.imread() 函数来读取图像。在这种情况下,需要第二个参数,因为我们希望以灰度加载图像。第二个参数是一个标志位,指定读取图像的方式。以灰度加载图像所需的值是 cv2.IMREAD_grayscale:
gray_img = cv2.imread('logo.png', cv2.IMREAD_GRAYSCALE)
在这种情况下,我们将图像存储在gray_img变量中。如果我们打印图像的尺寸(使用 gray_img.shape ),只能得到两个值,即行和列。在灰度图像中,不提供通道信息:
dimensions = gray_img.shape
shape将以元组形式返回图像的维度 —— (828, 640)。
像素值可以通过行和列坐标来访问。在灰度图像中,只获得一个值(通常称为像素的强度)。例如,如果我们想得到像素 ( x = 40 , y = 6 ) (x=40, y=6)(x=40,y=6) 处的像素强度:
i = gray_img[6, 40]
图像的像素值也可以以相同的方式修改。例如,如果要将像素 ( x = 40 , y = 6 ) (x=40, y=6)(x=40,y=6) 处的值更改为黑色(强度等于0):
gray_img[6, 40] = 0
1.4 数字图像处理基础
(1) 主要研究目标
我们看可以把图像看作是三维世界的二维视图,那么数字图像作为2D图像,可以使用称为像素的有限数字集进行表示(像素的概念将在像素、颜色、通道、图像和颜色空间部分中详细解释)。我们可以,将计算机视觉的目标定义为将这些2D数据转换为以下内容:
- 新的数据表示(例如,新图像)
- 决策目标(例如,执行具体决策任务)
- 目标结果(例如,图像的分类)
- 信息提取(例如,目标检测)
在进行图像处理时,经常会遇到以下问题:
- 图像的模糊性,由于受到透视的影响,从而会导致图像视觉外观的变化。例如,从不同的角度看同一个物体会产生不同的图像;
- 图像通常会受许多自然因素的影响,如光照、天气、反射和运动;
- 图像中的一部分对象也可能会被其他对象遮挡,使得被遮挡的对象难以检测或分类。随着遮挡程度的增加,图像处理的任务(例如,图像分类)可能非常具有挑战性。
为了更好的解释上述问题,我们假设需要开发一个人脸检测系统。该系统应足够鲁棒,以应对光照或天气条件的变化;此外,该系统应该可以处理头部的运动——用户头部可以在坐标系中每个轴上进行一定程度的动作(抬头、摇头和低头,用户可以离相机稍近或稍远的情况)。而许多人脸检测算法在人脸接近正面时表现出良好的性能,但是,如果一张脸不是正面的(例如,侧面对着镜头),算法就无法检测到它。此外,算法需要即使在用户戴着眼镜或太阳镜时,也可能需要检测面部(即使这会在眼睛区域产生遮挡)。综上所述,当开发一个计算机视觉项目时,我们必须综合考虑到所有这些因素,一个很好的表征方法是有使用大量测试图像来验证算法。我们也可以根据测试图像的不同困难程度来对它们进行分类,以便于检测算法的弱点,提高算法的鲁棒性。
(2) 主要研究方法
完整的图像处理程序通常可以分为以下三个步骤:
- 读取图像,图像的获取可以有多种不同的来源(相机、视频流、磁盘、在线资源),因此图像的读取可能涉及多个函数,以便可以从不同的来源读取图像;
- 图像处理,通过应用图像处理技术来处理图像,以实现所需的功能(例如,检测图像中的猫);
- 显示结果,将图像处理完成后的结果以人类可读的方式进行呈现(例如,在图像中绘制边界框,有时也可能需要将其保存到磁盘)。
此外,上述第2步图像处理可以进一步分为三个不同的处理级别:
- 低层处理(或者在不引起歧义的情况下可以称为预处理),通常将一个图像作为输入,然后输出另一个图像。可在此步骤中应用的步骤包括但不限于以下方法:噪声消除、图像锐化、光照归一化以及透视校正等;
- 中层处理:是将预处理后的图像提取其主要特征(例如采用 DNN 模型得到的图像特征),输出某种形式的图像表示,它提取了用于图像进一步处理的主要特征。
- 高层处理:接受中层处理得到的图像特征并输出最终结果。例如,处理的输出可以是检测到的人脸.
(3) 像素、颜色、通道、图像和颜色空间
在表示图像时,有多种不同的颜色模型,但最常见的是红、绿、蓝 (RGB) 模型。
RGB 模型是一种加法颜色模型,其中原色 (在RGB模型中,原色是红色 R、绿色 G 和蓝色 B) 混合在一起就可以用来表示广泛的颜色范围。
每个原色 (R, G, B) 通常表示一个通道,其取值范围为[0, 255]内的整数值。因此,每个通道有共256个可能的离散值,其对应于用于表示颜色通道值的总比特数 (2 8 = 256 2^8=25628=256)。此外,由于有三个不同的通道,使用 RGB 模型表示的图像称为24位色深图像:

在上图中,可以看到 RGB 颜色空间的“加法颜色”属性:
- 红色加绿色会得到黄色
- 蓝色加红色会得到品红
- 蓝色加绿色会得到青色
- 三种原色加在一起得到白色
因此,如前所述,RGB 颜色模型中,特定颜色可以由红、绿和蓝值分量合成表示,将像素值表示为 RGB 三元组 (r, g, b)。典型的 RGB 颜色选择器如下图所示:

分辨率为 800×1200 的图像是一个包含800列和1200行的网格,每个网格就是称为一个像素,因此其中包含 800×1200=96 万像素。应当注意,图像中有多少像素并不表示其物理尺寸(一个像素不等于一毫米)。相反,像素的大小取决于为该图像设置的每英寸像素数 (Pixels Per Inch, PPI)。图像的 PPI 一般设置在 [200-400] 范围内。
计算PPI的基本公式如下:
- PPI=宽度(像素) / 图像宽度(英寸)
- PPI=高度(像素) / 图像高度(英寸)
例如,一个4×6英寸图像,图像分辨率为 800×1200,则PPI是200。
(4) 图像的定义
图像可以描述为2D函数 f ( x , y ) f(x, y)f(x,y),其中 ( x , y ) (x, y)(x,y) 是空间坐标,而 f ( x , y ) f(x, y)f(x,y) 是图像在点 ( x , y ) (x, y)(x,y) 处的亮度或灰度或颜色值。另外,当f(x, y)和(x, y)值都是有限离散量时,该图像也被称为数字图像,此时:
- x ∈ [ 0 , h − 1 ] x∈ [0, h-1]x∈[0,h−1],其中 h hh 是图像的高度
- y ∈ [ 0 , w − 1 ] y∈ [0, w-1]y∈[0,w−1],其中 w ww 是图像的宽度
- f ( x , y ) ∈ [ 0 , L − 1 ] f(x, y)∈ [0,L-1]f(x,y)∈[0,L−1],其中 L = 256 L=256L=256 (对于8位灰度图像)
彩色图像也可以用同样的方式表示,只是我们需要定义三个函数来分别表示红色、绿色和蓝色值。这三个单独的函数中的每一个都遵循与为灰度图像定义的 f ( x , y ) f(x, y)f(x,y) 函数相同的公式。我们将这三个函数的子索引 R、G 和 B 分别表示为 f R ( x , y ) f_R(x, y)f**R(x,y)、f G ( x , y ) f_G(x, y)f**G(x,y) 和 f B ( x , y ) f_B(x, y)f**B(x,y)。
同样,黑白图像也可以表示为相同的形式,其仅需要一个函数来表示图像,且 f ( x , y ) f(x, y)f(x,y) 只能取两个值。通常,0 表示黑色、1 表示白色。
下图显示了三种不同类型的图像(彩色图像、灰度图像和黑白图像):
数字图像可以看作是真实场景的近似,因为 f ( x , y ) f(x, y)f(x,y) 值是有限的离散量。此外,灰度和黑白图像每个点只对应有一个值,彩色图像每个点需要三个函数对应于图像的红色、绿色和蓝色分量。
(5) 图像文件的类型
尽管在 OpenCV 中处理的图像时,可以将图像看作 RGB 三元组的矩阵(在 RGB 图像模型情况下),但它们不一定是以这种格式创建、存储或传输的。有许多不同的文件格式,如GIF、PNG、位图或JPEG,使用不同形式的压缩(无损或有损)来更有效地表示图像。
下表列示了 OpenCV 支持的文件格式及其关联的文件扩展名:
| 文件格式 | 文件扩展名 |
|---|---|
| Windows bitmaps | .bmp和.dib |
| JPEG files | .JPEG、.jpg 和 *.jpe |
| JPEG 2000 files | *.jp2 |
| Portable Network Graphics | *.png |
| Portable image format | .pbm、.pgm 和 *.ppm |
| TIFF files | *.TIFF 和 *.tif |
对图像应用无损或有损压缩算法,可以得到比未压缩图像占据存储空间小的图像。其中,在无损压缩算法中,得到的图像与原始图像等价,也就是说,经过反压缩过程后,得到的图像与原始图像完全等价(相同);而在有损压缩算法中,得到的图像并不等同于原始图像,这意味着图像中的某些细节会丢失,在许多有损压缩算法中,压缩级别是可以调整的。
2. Opencv基础操作代码
2.1 打开照片:
import numpy as np //python的矩阵库
import matplotlib.pyplot //加入窗口的库
import cv2 as cv
img = cv.imread("Picture\love.jpg")
#要在项目工作空间的文件夹里的照片才行
"""img = cv2.imread("Picture\love.jpg",cv2.IMREAD\_GRAYSCALE)"""
#后面的第二参数是转化成灰度图
# C:\Users\zhaohaobing\PycharmProjects\python-opencv-project\picture
img = cv.resize(img,None,fx = 0.5,fy = 0.5)
#控制输出图像尺寸(图像,要输出的尺寸大小,长宽各变成几倍)
img_dog = cv2.resize(img_dog, (500, 414))
#输出指定长宽
cv.imshow("love",img)
#照片名字不能用中文的
cv.waitKey(0)
#等待时间,毫米级,0代表任意键才终止
cv.destroyAllWindows()
#任意键关闭
cv.imwrite('picture\ mylove.png',img)
#将照片保存
#res = np.hstack((img1,img2,img3))
#把()里这n张照片放一起
print(img.shape)
#(1200, 1920, 3) h w c(3层还是1层)
print(type(img))
#格式
print(img.size)
#像素点个数
print(img.dtype)
#uint8 数据类型 8位
2.2 读取视频:
import numpy as np
import matplotlib.pyplot
import cv2 as cv
vc = cv.VideoCapture("video\How do you use your time.mp4")
if vc.isOpened():
open,frame = vc.read()
#open返回一个True或False,vc.read()是取第一帧第二帧...赋给frame
else:
open = False
while open:
ret,frame = vc.read()
if frame is None:
break
if ret == True:
#gray = cv.cvtColor(frame,cv.COLOR\_BGRA2GRAY)
#灰度处理
cv.imshow("mytime",frame)
if cv.waitKey(10) == ord("q"):
#按q键退出键推出视频
break
vc.release()
cv.destroyAllWindows()
2.3 打开摄像头:
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
#一般电脑内置摄像头为0,可以通过设置成 1 或者其他的来选择别的摄像头
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# if frame is read correctly ret is True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
# Our operations on the frame come here
#gray = cv.cvtColor(frame, cv.COLOR\_BGR2GRAY)#你也可以注释掉这行颜色转换的代码
# Display the resulting frame
cv.imshow('myCamera', frame)
if cv.waitKey(1) == ord('q'):
break
# When everything done, release the capture
cap.release()
cv.destroyAllWindows()
2.4 保存视频:
#是从摄像头中捕获视频,沿水平方向旋转每一帧并保存它
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv.VideoWriter_fourcc(\*'XVID')
# ourCC 码以下面的格式传给程序,
# 以 MJPG 为例:cv.VideoWriter\_fourcc('M','J','P','G')或者 cv.VideoWriter\_fourcc(\*'MJPG')。
out = cv.VideoWriter('output.avi', fourcc, 20.0, (640, 480))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
frame = cv.flip(frame, 0)
# write the flipped frame
out.write(frame)
cv.imshow('frame', frame)
if cv.waitKey(1) == ord('q'):
break
# Release everything if job is finished
cap.release()
out.release()
cv.destroyAllWindows()
2.5 画线:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((512,512,3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
#(名字,起始点,终止点,颜色(opencv中是BGR),宽度)
cv.line(img,(0,0),(511,511),(255,0,0),5)
cv.imshow('img', img)
cv.waitKey(0)
2.6 画矩形:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((512,512,3), np.uint8)
#(名字,左上坐标,右下坐标,颜色(BGR),框线宽度)
#左上角为(0,0)点,向右x正方向,向下y正方向
cv.rectangle(img,(0,0),(100,100),(0,255,0),3)
cv.imshow('img', img)
cv.waitKey(0)
2.7 画圆:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((512,512,3), np.uint8)
#(名字,圆心,半径,颜色(BGR),框线厚度(-1及填鸭))
cv.circle(img,(100,100), 66, (0,0,255), -1)
cv.imshow('img', img)
cv.waitKey(0)
2.8 画椭圆:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((512,512,3), np.uint8)
#(名字,中心点,长轴短轴长度,整体沿逆时针方向旋转角度,
# 起始角度,终止角度(是不是完成椭圆),颜色,线框宽度
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
cv.imshow('img', img)
cv.waitKey(0)
2.9 画多边形:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((512,512,3), np.uint8)
#各个顶点坐标,数据类型int32
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
cv.imshow('img', img)
cv.waitKey(0)
2.10 写字:
import numpy as np
import cv2 as cv
# Create a black image
#((h,w,几层),np采用八进制)
img = np.zeros((500,500,3), np.uint8)
#调用函数,写的字赋给font
font = cv.FONT_HERSHEY_SIMPLEX
#(名字,要写的文字,位值,字,字体大小,颜色,字体笔画宽度
# cv.LINE\_AA(字体类型)
cv.putText(img,'OpenCV',(10,500), font, 8,(255,255,255),2,cv.LINE_AA)
cv.imshow('img', img)
cv.waitKey(0)
2.11 图像的基础操作:
import cv2 as cv
img = cv.imread("picture\me.jpg")
#像素的行和列的坐标获取他的像素值
print(img.item(10,10,2))
#修改像素值
img.itemset((10,10,2),100)
print(img.item(10,10,2))
#获取图像属性(行数,列数, 通道数)
print(img.shape)
#图像的像素数目
print(img.size)
#图像的数据类型
print(img.dtype)
2.12 截取选定区域:
import cv2 as cv
img = cv.imread("picture\me.jpg")
#截取选定区域
something = img[0:300, 70:350]
cv.imshow('something',something)
cv.waitKey(0)
2.13 Opencv中常用的颜色空间就三种BGR、HSV、灰度:
Opencv中最常用的两种颜色空间转换:BGR<->GRAY,BGR<->HSV
bgr先要变换成hsv再目标检测
import cv2 as cv
img1 = cv.imread("picture\me.jpg")
img2 = cv.imread("picture\me.jpg")
#BGR↔Gray 的转换
hsv1 = cv.cvtColor(img1, cv.COLOR_BGRA2GRAY)
#BGR↔HSV 的转换
hsv2 = cv.cvtColor(img1, cv.COLOR_BGR2HSV)
cv.imshow("img1",hsv1)
cv.imshow("img2",hsv2)
cv.waitKey(0)
H(色彩/色度)的取值范围是 [0,179], S(饱和度)的取值范围 [0,255],V(亮度)的取值范围 [0,255]。
2.14 颜色跟踪:
在 HSV 颜色空间中要比在 BGR 空间 中更容易表示一个特定颜色。
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
while True :
ret,frame = cap.read()
#每一帧先mask处理
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
#np.array 创建一个数组
lower_blue = np.array([110,50,50])
upper_blue = np.array([130,255,255])
#mask将符合数值区间的黑白提取出来
#mask掩膜1、创造一个与原图大小相同的全白图(像素全是1),原图中像素在设置区间里的赋为1,其他像素点赋为0,两张图片进行与运算(都为1才为1),则得到mask(全黑图提取部分为白色)
mask = cv.inRange(hsv,lower_blue,upper_blue)
#res将提取出来的在还原颜色
# frame和frame先取’与‘操作,在用其结果和mask取’与‘操作
# 将mask中白色地方的颜色在前面结果对应地方中显示出来)
res = cv.bitwise_and(frame,frame,mask = mask)
cv.imshow('frame', frame)
cv.imshow('mask', mask)
cv.imshow('res', res)
if cv.waitKey(5) & 0xff ==ord("q"):
break
cv.destroyAllWindows()
2.15 BGR通道分离和合并:
#通道分离
b,g,r = cv.split(frame)
cv.imshow("blue",b)
cv.imshow("green",g)
cv.imshow("red",r)
#第三个通道赋值为零,前面::表示取所有
frame[:,:,2] = 0
#合并
frame = cv.merge([b,g,r])
2.16 程序运行时间:
import cv2 as cv
e1 = cv.getTickCount()
#函数a
e2 = cv.getTickCount()
#可得函数a运行时间
time = (e2 - e1)/cv.getTickFrequency()
print(time)
与& 两个1才为1(黑色是0,白色是1,黑色区域不显示,白色区域显示另一张照片颜色)
and
或| 有1就1 (
not
非~ 0变1 1变0
2.17 数值操作:
#每个像素点都+10
img_cat2= img_cat +10
#取前五行,所有列,方面后面打印看部分像素值
img_cat[:5,:,0]
2.18 腐蚀操作:
1、先设置滤波器大小
2、设置迭代次数
3、滤波器从左上依次到右下,如果该地方滤波器内像素剧烈变化,对该地方进行腐蚀,即图形信息变细边小,去掉毛毛刺刺
kernel = np.ones((3,3),np.uint8) #设置he的大小,he越大每次腐蚀的范围就越大
erosion = cv2.erode(img,kernel,iterations = 1) #迭代次数,迭代此时越多腐蚀越多
cv2.imshow('erosion', erosion)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.19 膨胀操作:
与腐蚀操作相反,图像变胖
一般先腐蚀去噪,再膨胀恢复
kernel = np.ones((3,3),np.uint8)
dige_dilate = cv2.dilate(dige_erosion,kernel,iterations = 1)
cv2.imshow('dilate', dige_dilate)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.10 开运算、闭运算、梯度运算、礼帽、黑帽:(腐蚀、膨胀综合操作):
#例如图像
# 开:先腐蚀,再膨胀 (刺没了)
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
# 闭:先膨胀,再腐蚀 (刺变胖了)
kernel = np.ones((5,5),np.uint8)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
# 梯度=膨胀-腐蚀,取膨胀和腐蚀中间的部分
gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)
#礼帽 = 原始输入-开运算结果 (只剩刺)
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
#黑帽 = 闭运算-原始输入(只剩刺的轮廓,也可反应主体信息的轮廓)
blackhat = cv2.morphologyEx(img,cv2.MORPH_BLACKHAT, kernel)
2.21 两照片操作:
import cv2 as cv
import numpy as np
#res = 0.4\*cat + 0.6\*dog + 0
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)
#两图片相加
def add\_demo(m1,m2):
dst = cv.add(m1,m2)
cv.imshow("add\_demo",dst)
#两图片相减
def subtract\_demo(m1,m2):
dst = cv.subtract(m1,m2)
cv.imshow("subtract\_demo",dst)
#两照片相乘
def multiply\_demo(m1,m2):
dst = cv.multiply(m1,m2)
cv.imshow("multiply\_demo",dst)
#两照片相除
def divide\_demo(m1,m2):
dst = cv.divide(m1,m2)
cv.imshow("divide\_demo",dst)
#
def logic\_demo(m1,m2):
dst = cv.bitwise_and(m1,m2)
cv.imshow("bitwise\_and", dst)
img1 = cv.imread("picture\班徽(中文).jpg")
img2 = cv.imread("picture\班徽En.jpg")
cv.namedWindow('image', cv.WINDOW_NORMAL)
cv.imshow('image1', img1)
cv.imshow('image2', img2)
add_demo(img1,img2)
subtract_demo(img1,img2)
multiply_demo(img1,img2)
divide_demo(img1,img2)
cv.waitKey(0)
cv.destroyAllWindows()
2.22 图像阈值:
"""
语法:ret, dst = cv2.threshold(src, thresh, maxval, type)
- dst: 输出图
- src: 输入图,只能输入单通道图像,通常来说为灰度图
- thresh: 阈值
- maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
- type:二值化操作的类型,包含以下5种类型
"""
#cv2.THRESH\_BINARY:超过阈值部分取maxval(最大值),否则取0 (二值化)
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
#cv2.THRESH\_BINARY\_INV:THRESH\_BINARY的反转,超过阈值部分取0,小于部分取最大值
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV)
#cv2.THRESH\_TRUNC:大于阈值部分设为阈值,小于的不变
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC)
#cv2.THRESH\_TOZERO:大于阈值部分不改变,小于的设为0
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO)
#cv2.THRESH\_TOZERO\_INV:THRESH\_TOZERO的反转,大于阈值部分设为0,小于的不变
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY\_INV', 'TRUNC', 'TOZERO', 'TOZERO\_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
- cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
3. 滤波操作:
3.1 图像梯度-Sobel算子:

Gx是水平方向上的检测,Gy是竖直方向上的检测,检测点是九宫格的中间点,距离中心点近的数值大,中心点梯度检测的权重大
X:右减左 A3-A1+2A6-2A4+A9-A7 得到的值越大梯度越大
"""
语法:
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
(输入照片、图像深度(一般为-1)、dxdy选择进行哪个方向的检测那个赋1另一个为0,ksize是sobel算子大小)
"""
#x方向检测
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
#对图像深度进行取绝对值,以为sobel运算结果可能为负值,在opencv中取值是0-255,为负值以后就变成0,所有要取决绝对值,把负值的部分也显示出来
sobelx = cv2.convertScaleAbs(sobelx)
cv_show(sobelx,'sobelx')
#Y方向检测
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobely = cv2.convertScaleAbs(sobely)
cv_show(sobely,'sobely')
#再求和,(x,权重,y,权重,0(这里是偏置项,设置为0))
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelxy')
3.2 均值滤波:
设置一个单位矩阵(he(滤波器)边长需为奇数)例3*3
该he从图像左上角滑动到右下角做内积(对应点相乘)
he的中心点的像素点变为为he内九个像素点的平均值。
# 均值滤波
# 简单的平均卷积操作
blur = cv2.blur(img, (3, 3))
cv2.imshow('blur', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.3 高斯滤波:
设置一个矩阵(he(滤波器)边长需为奇数)例3*3,中间是1,四种根据远近权重不同
该he从图像左上角滑动到右下角做内积 (对应点相乘)
he的中心点的像素点变为为he内九个像素点的平均值。
# 高斯滤波
# 高斯模糊的卷积核里的数值是满足高斯分布,相当于更重视中间的
aussian = cv2.GaussianBlur(img, (5, 5), 1)
cv2.imshow('aussian', aussian)
cv2.waitKey(0)
cv2.destroyAllWindows()
3.4 中值滤波:
设置一个he(滤波器)边长需为奇数例3*3
该he从图像左上角滑动到右下角
he的中心点的像素点变为为he内九个像素点的平均值。
# 中值滤波
# 相当于用中值代替
median = cv2.medianBlur(img, 5) # 中值滤波
cv2.imshow('median', median)
cv2.waitKey(0)
cv2.destroyAllWindows()
三种滤波比较:
中值滤波适合处理椒盐噪声;

3.5 模糊处理去噪:
#均值模糊-去随机噪声
def blur\_demo(image):
dst = cv.blur(image,(15,1))
#(1,3)定义一个滤波器一行三列,前值控制横方向的模糊,后值控制纵方向的模糊
dst = cv.resize(dst ,None,fx = 0.5,fy = 0.5)
#控制输出图像尺寸(图像,要输出的尺寸大小,长宽各变成几倍)
cv.imshow("blur\_demo",dst)
#中值模糊-去噪椒盐噪声(小黑点)
def median\_blur\_demo(image):
dst = cv.medianBlur(image,5)
cv.imshow("median\_blur\_demo",dst)
#自定义模糊
def custom\_blur\_demo(image):
kernel = np.ones([5,5],np.float32)/25
#ones([5,5] 5\*5大小的全是1的矩阵 /25结果除25保证不溢出
#kernel = np.array([0,-1,0],[-1,5,-1],[0,-1,0],np.float32)
#锐化,自定义滤波器总和要为奇数,或=1做增强,=0做边缘
dst = cv.filter2D(image,-1,kernel = kernel)
cv.imshow("custom\_blur\_demo",dst)
3.6 Carry边缘检测:
1、去噪,使用高斯滤波器,以平滑图像,滤除噪声。

2、利用sobel算子计算图像中每个像素点的梯度强度和方向。
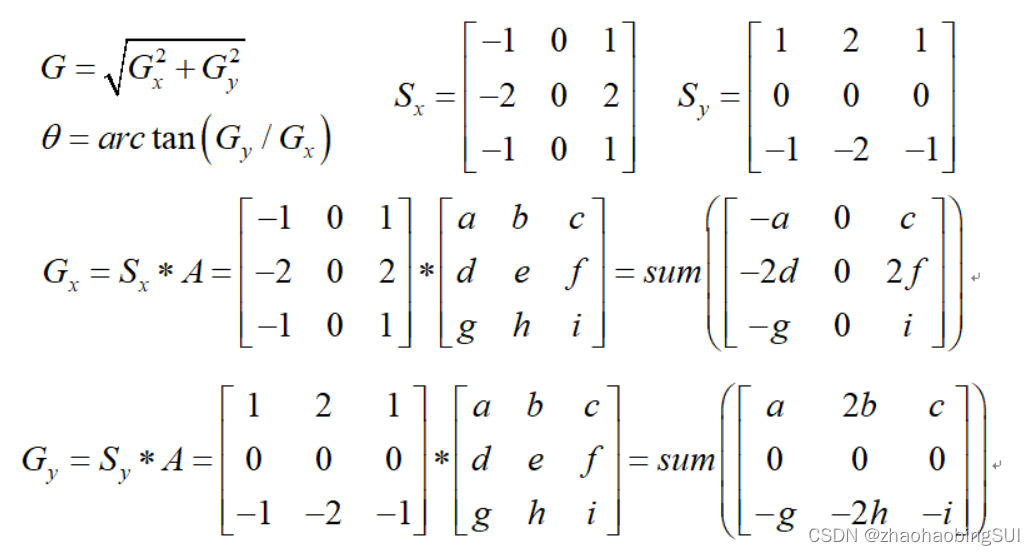
3、应用非极大值抑制,以消除边缘检测带来的杂散响应。
(非极大值抑制:即一张图像里有多个目标同时目标相互重叠,这时需要进行非极大值抑制保留概率最大的那个)
4、应用双阈值检测来确定真实的和潜在的边缘。
(即进行两次边界检测保证是边界)
5、通过抑制孤立的弱边缘最终完成边缘检测。
img=cv2.imread("lena.jpg",cv2.IMREAD_GRAYSCALE)
#(picture,minVal,maxval) minVal越小、maxVal越小,保留的边界信息越多
v1=cv2.Canny(img,80,150)
v2=cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')
3.7 上采样、下采样:
上采样(放大):
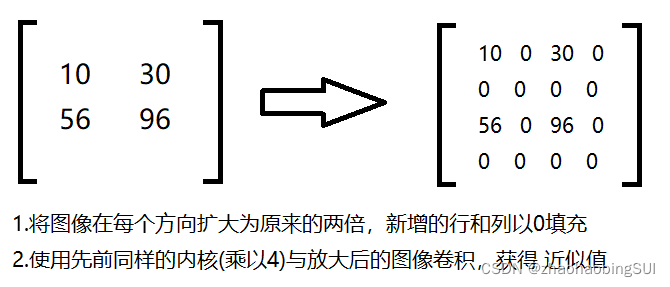
下采样(缩小):

#上采样,将照片放大
up=cv2.pyrUp(img)
cv_show(up,'up')
print (up.shape)
#下采样,将照片缩小
down=cv2.pyrDown(img)
cv_show(down,'down')
print (down.shape)
3.8 轮廓检测:
"""
语法:
cv2.findContours(img,mode,method)
mode:轮廓检索模式
-(默认是它)RETR\_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;
method:轮廓逼近方法,即画轮廓
- CHAIN\_APPROX\_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN\_APPROX\_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
"""
img = cv2.imread('contours.png')
#先灰度再二值
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv_show(thresh,'thresh')
#二值结果,轮廓信息,轮廓层级(传入预处理的图案,检索所有的轮廓,把所有点都画出来)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
#传入绘制图像,轮廓,轮廓索引,颜色模式,线条厚度
# 注意需要copy,要不原图会变。。。
#把原图像复制过来操作,避免添加了轮廓信息以后原图像被毁
draw_img = img.copy()
#(被画的图像,轮廓信息,默认-1即把所有轮廓都画上来,轮廓颜色,线条宽度)
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
cv_show(res,'res')
轮廓近似:
在一个图形中,任意两点间连一条线,两点间的曲线上距离该线的最远点的距该线的距离,与阈值作比较
最远距离<阈值:则用该直线代替;
最远距离>阈值:取该点为独立点,与上述两点进行连线,该点与上述两点间各种曲线上的点继续执行上述操作
#轮廓近似
img = cv2.imread('contours2.png')
#先灰度后二值
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
#做轮廓
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
#轮廓阈值设置 0.15\*周长
epsilon = 0.15\*cv2.arcLength(cnt,True)
#轮廓近似 = (输入的轮廓,阈值,true)
approx = cv2.approxPolyDP(cnt,epsilon,True)
draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')
3.9 高斯模糊:
浮点数计算,耗时耗资源
9*9滤波器 一般拆分成一个横3和一个竖3的两个滤波器,连续处理两次,减少运算量,加快速度
#保证加上噪音后数据还在0-255
def clamp(pv):
if pv > 255:
return 255
if pv < 0:
return 0
else :
return pv
#高斯模糊(均值模糊的拓展)基于权重的
#加噪声
def gaussian\_noise(image):
h,w,c = image.shape
for row in range(0,h,1):
#从0开始到h每次加1,(row排)
for col in range(w):#(col列)
s = np.random.normal(0,20,3)
#产生随机数的(从0开始到20产生3个
b = image[row, col, 0] #blue
g = image[row, col, 1]
r = image[row, col, 2]
image[row, col, 0] = clamp(b + s[0])
image[row, col, 1] = clamp(b + s[1])
image[row, col, 2] = clamp(b + s[2])
cv.imshow("noise\_image",src)
gaussian_noise(src)
#高斯处理
dst = cv.GaussianBlur(src,(0,0),15)
#15为高斯公式中的一个参值
cv.imshow("Gaussian",dst)
3.10 边缘保留滤波:(EPF)(美颜)
色彩边缘处,数据差异太大,不参与均值模糊,保留,即高斯双边模糊,差异位值的左右都模糊,差异位值保留
#双边高斯模糊(磨皮效果)
def bi\_demo(image):
dst = cv.bilateralFilter(image,0,100,15)
#sigmacolor 取大一点,小的差异模糊掉;sigmaspace取小一点,和会小一点,减小计算量
cv.imshow("bi\_demo",dst)
#均值迁移(会有地方过度模糊)(油画效果)
def shift\_demo(image):
dst = cv.pyrMeanShiftFiltering(image,10,50)
cv.imshow("bi\_demo",dst)
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新**
**需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)**
**[如果你需要这些资料,可以戳这里获取](https://bbs.csdn.net/topics/618679757)**
nge(0,h,1):
#从0开始到h每次加1,(row排)
for col in range(w):#(col列)
s = np.random.normal(0,20,3)
#产生随机数的(从0开始到20产生3个
b = image[row, col, 0] #blue
g = image[row, col, 1]
r = image[row, col, 2]
image[row, col, 0] = clamp(b + s[0])
image[row, col, 1] = clamp(b + s[1])
image[row, col, 2] = clamp(b + s[2])
cv.imshow("noise\_image",src)
gaussian_noise(src)
#高斯处理
dst = cv.GaussianBlur(src,(0,0),15)
#15为高斯公式中的一个参值
cv.imshow("Gaussian",dst)
3.10 边缘保留滤波:(EPF)(美颜)
色彩边缘处,数据差异太大,不参与均值模糊,保留,即高斯双边模糊,差异位值的左右都模糊,差异位值保留
#双边高斯模糊(磨皮效果)
def bi\_demo(image):
dst = cv.bilateralFilter(image,0,100,15)
#sigmacolor 取大一点,小的差异模糊掉;sigmaspace取小一点,和会小一点,减小计算量
cv.imshow("bi\_demo",dst)
#均值迁移(会有地方过度模糊)(油画效果)
def shift\_demo(image):
dst = cv.pyrMeanShiftFiltering(image,10,50)
cv.imshow("bi\_demo",dst)
[外链图片转存中...(img-FC8zRzrG-1715802192918)]
[外链图片转存中...(img-tyURHf9t-1715802192918)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新**
**需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)**
**[如果你需要这些资料,可以戳这里获取](https://bbs.csdn.net/topics/618679757)**















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









