






使用尖端优化技术加速推理的实用指南

欢迎来到雲闪世界。大型语言模型非常耗电,需要大量 GPU 资源才能发挥良好性能。然而,Transformer 架构并没有充分利用 GPU。
从设计上讲,GPU 可以并行处理,但 Transformer 架构是自回归的。为了生成下一个 token,它必须查看之前的所有 token。Transformer 不允许您并行预测下一个 token。最终,这会使 LLM 的生成阶段非常缓慢,因为必须n按顺序生成每个新 token 。推测解码是一种旨在解决此问题的新型优化技术。
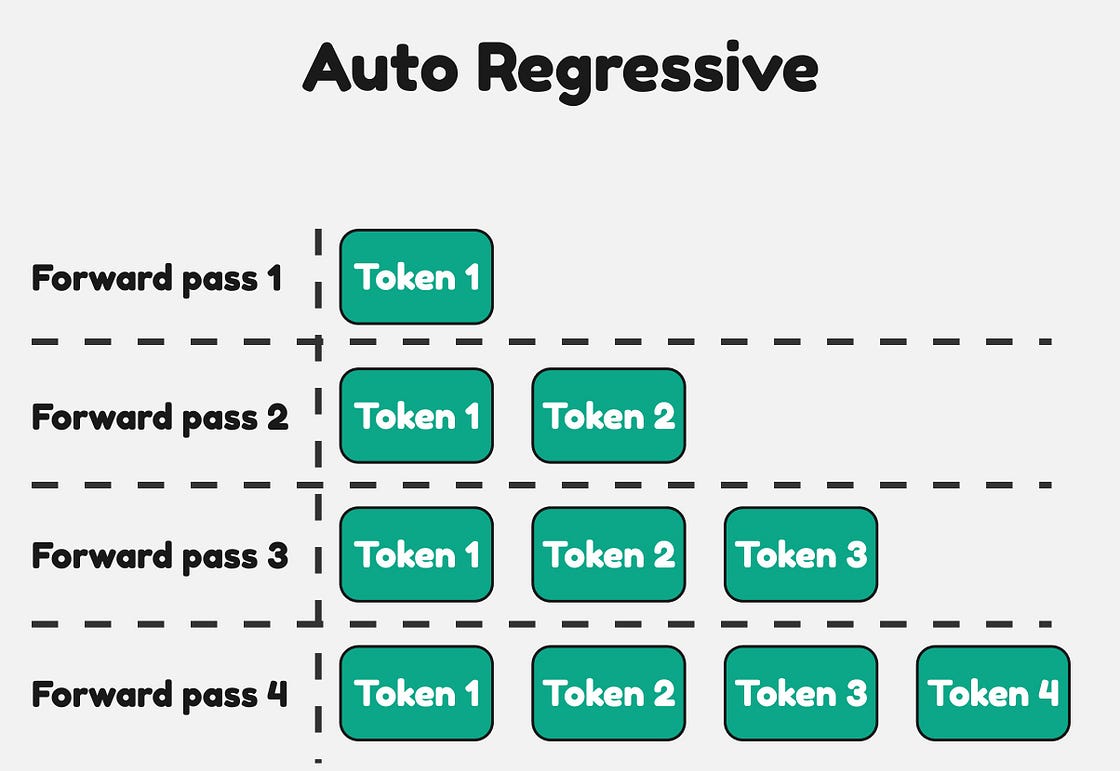
每次前向传递都会产生一个由 LLM 生成的新 token
推测解码有几种不同的方法。本文介绍的技术采用双模型方法。
推测解码
推测解码的工作原理是使用两个模型,一个大型主模型和一个较小的辅助模型。较小的辅助模型首先生成一个由 n 个 token 组成的序列。然后,主模型在一次前向传递中验证 token 序列。
这个想法是,由于辅助模型很小,因此它会快速生成 token。主模型更大、更准确,不需要生成每一个 token。它只需要验证辅助模型生成的 token。
例如,假设助手模型产生以下 5 个 token。
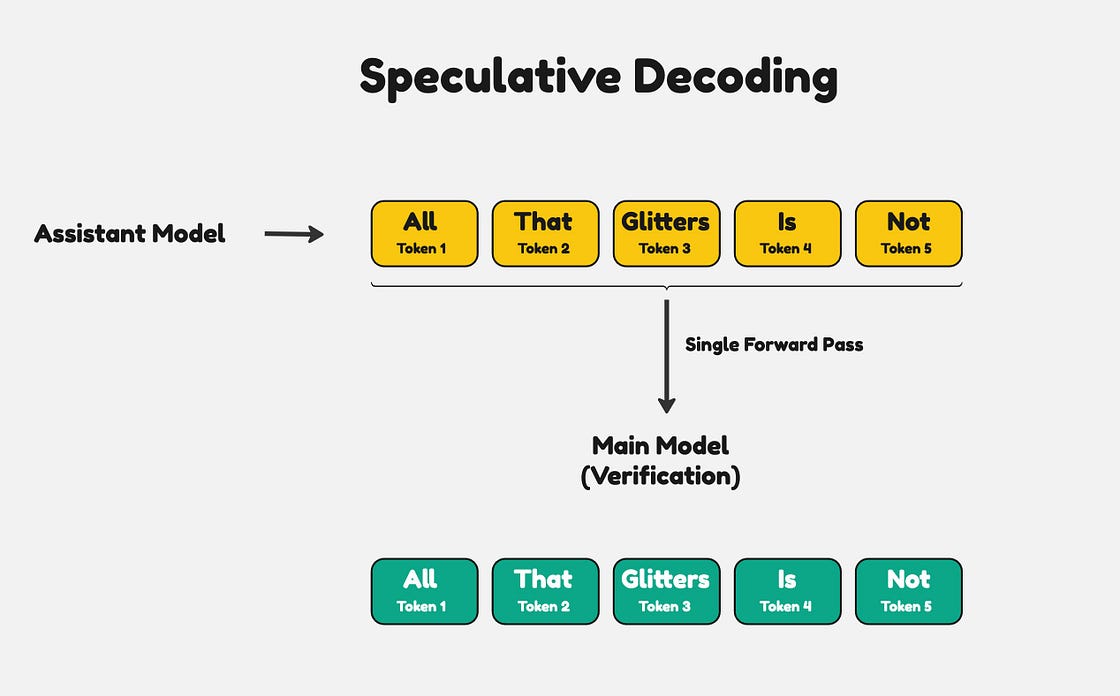
辅助模型自动回归生成 token,而主模型一次性验证所有 token
主模型将对所有 5 个 token 执行一次前向传递。主模型的目的是验证每个 token 的正确性。如果根据主模型,其中一个 token 不正确,它会丢弃错误 token 后的整个序列。然后,主模型会以自回归方式用正确的 token 填充序列的其余部分。
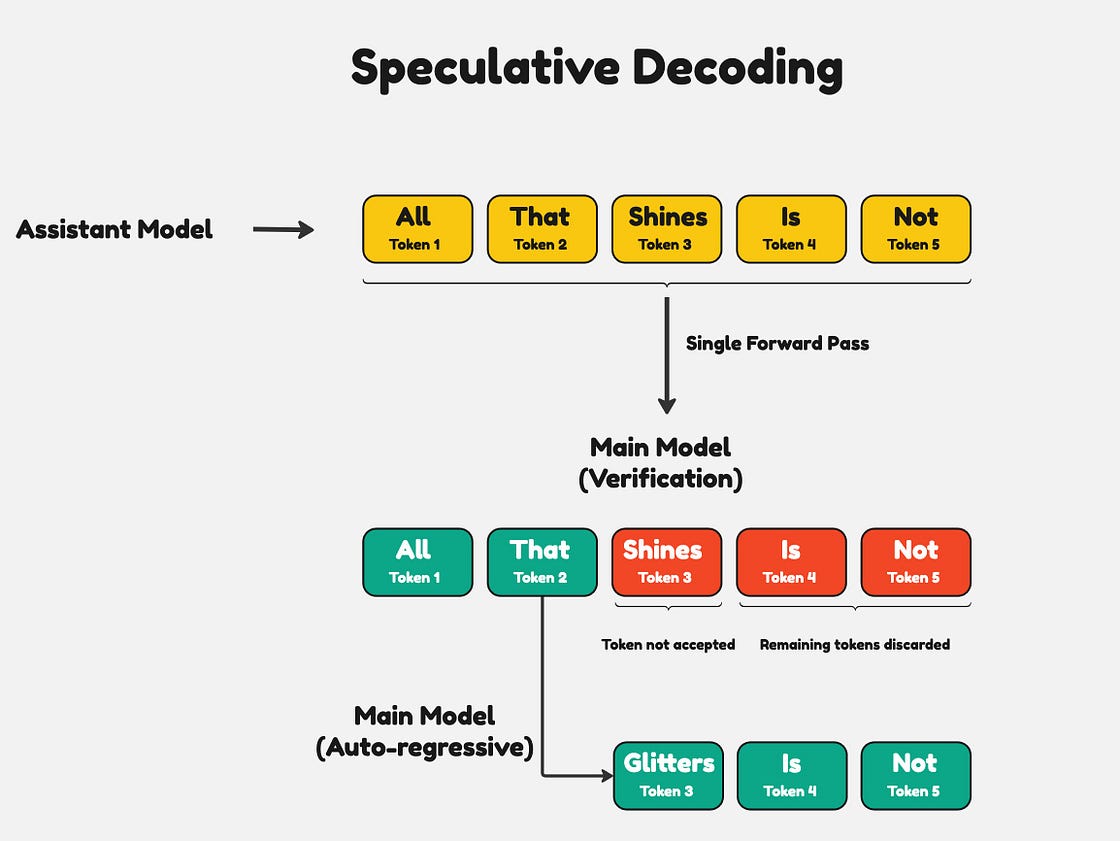
主模型丢弃从第一个不正确的 token 开始的序列输出
使用推测解码,您一定能获得与单独运行主模型完全相同的输出。这是因为主模型会验证每个 token 并替换它认为不正确的 token。在理想情况下,如果辅助模型正确生成了大多数 token,主模型将能够快速验证 token,从而缩短端到端生成时间。
推测解码的实践
许多流行的推理服务(如 TGI 和 vLLM)都支持开箱即用的推测解码。挑战在于找到正确的辅助模型和主模型对。一般来说,最好选择具有相同架构和词汇表的模型。
在本教程中,我们将使用Llama 3.1 70B Instruct作为主模型,使用Llama 3.1 8B Instruct作为辅助模型。vLLM 为这两种模型提供支持,因此我们将使用它作为推理服务。
安装 Python 要求并导入包
!pip install vllm== 0.5 .4
从vllm导入SamplingParams
从vllm.engine.arg_utils导入AsyncEngineArgs
从vllm.engine.async_llm_engine导入AsyncLLMEngine下载模型
model_args = AsyncEngineArgs(
模型 = “meta-llama/Meta-Llama-3.1-70B-Instruct”,
speculative_model = “meta-llama/Meta-Llama-3.1-8B-Instruct”,
trust_remote_code = True,
tensor_parallel_size = 4,
max_num_seqs = 8,
dtype = “half”,
use_v2_block_manager = True,
enforce_eager = True
)
llm_engine = AsyncLLMEngine.from_engine_args(model_args)- 在引擎参数中,指定作为助手
model时要使用的主模型。speculative_model - 由于 70B 型号占用约 140 GB 的 VRAM,我决定使用四个 GPU(A100 80GB),因此
tensor_parallel_size设置为 4。 - 使用
dtype=halfFP16 精度加载权重,与完整的 FP32 位精度相比,其内存量只有一半。 - 该推测模型需要参数
use_v2_block_manager和enforce_eager才能正确运行。 - 使用 vLLM 而非常规 LLM 类的主要原因
AsyncLLMEngine是 AsyncEngine 可以处理并发请求。
使用推测解码运行推理
import uuid
import asyncio
prompt = "Why is the earth flat?"
stream = True
max_tokens = 512
model_input = {"max_tokens": max_tokens}
sampling_params = SamplingParams(**model_input)
idx = str(uuid.uuid4().hex)
vllm_generator = llm_engine.generate(prompt, sampling_params, idx)
async def stream_tokens():
full_text = ""
async for request_output in llm_engine.generate(prompt, sampling_params, idx):
if len(request_output.outputs) > 0:
text = request_output.outputs[0].text
delta = text[len(full_text):]
full_text = text
print(delta, end='', flush=True)
print()
await stream_tokens()- 在顶部,我们指定常规参数,例如
prompt、max_tokens和stream。为了轻松直观地看到性能提升,我们将设置stream=True。 - 在
stream_tokens函数中,我们有一个从调用返回的生成器对象llm_engine.generate。为了打印生成器的输出,我们需要异步循环它,因为我们的 LLM 引擎被定义为异步。最后,我们获取生成的标记并打印它们。
性能结果
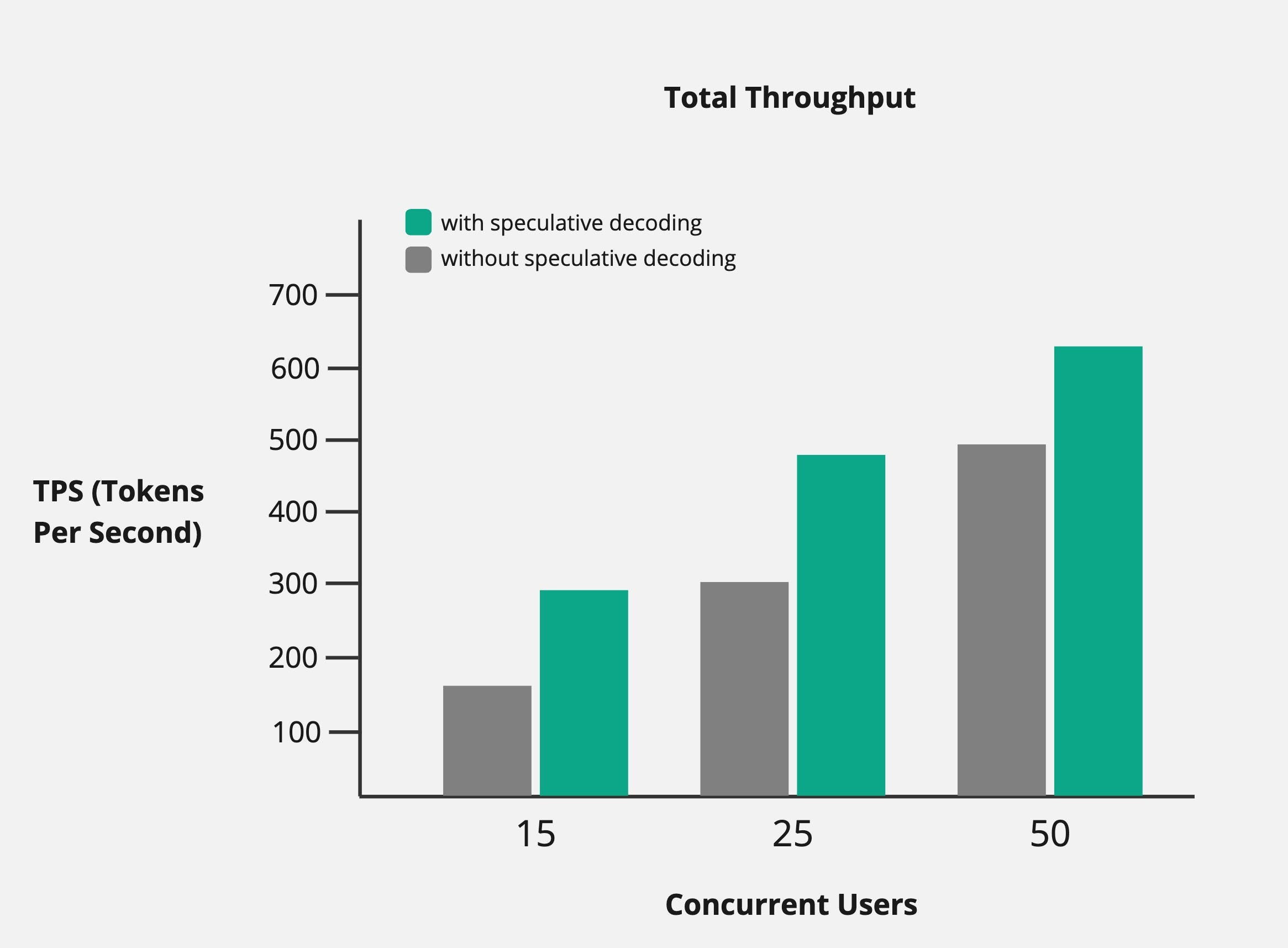
vLLM Llama 3.1 70B 基准
TPSA
- 在较低的并发性下,我们看到了近 2 倍的改进。
- 在更高的并发性下,性能提升约30%。
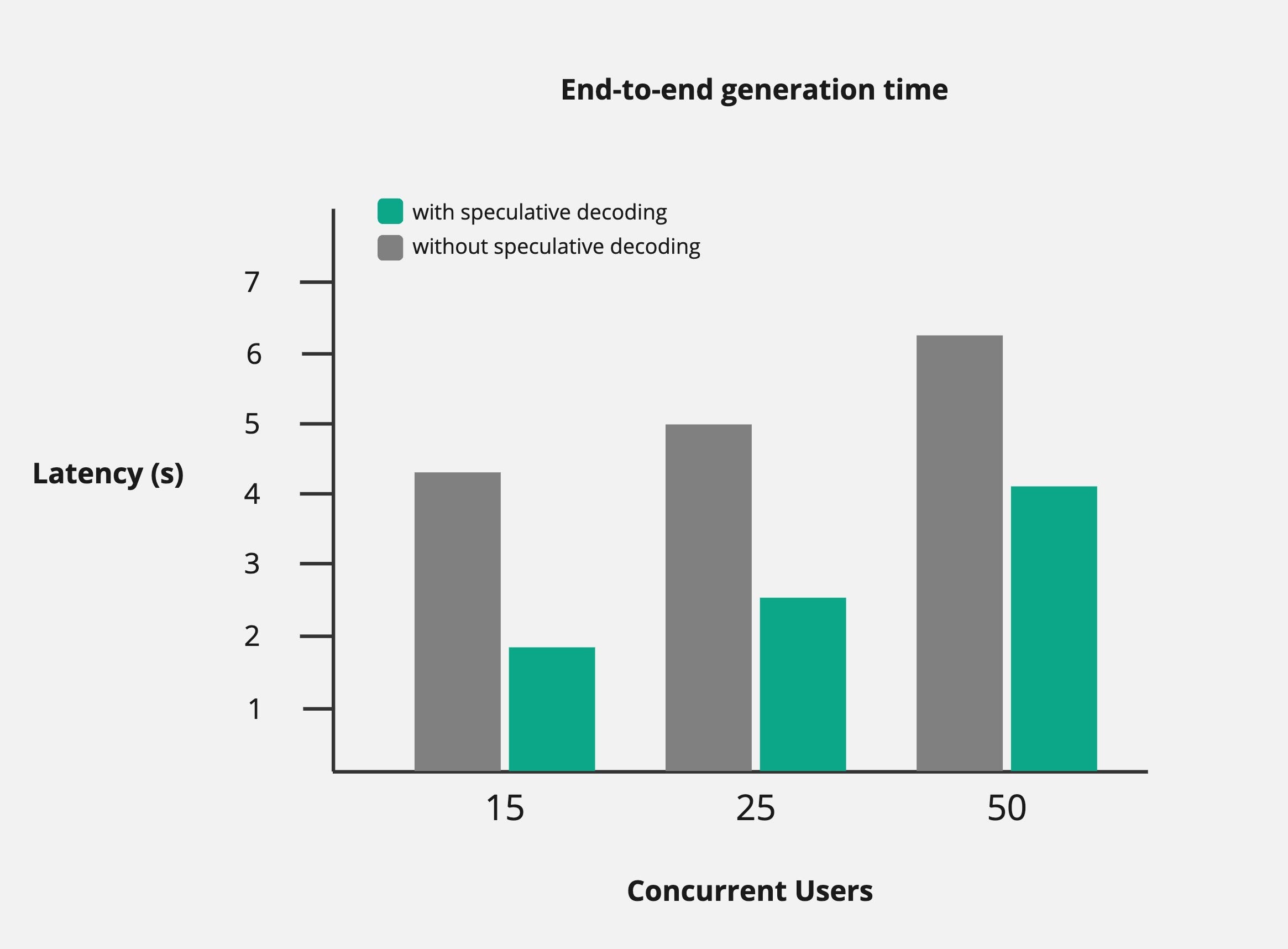
生成时间
- 与 TPS 的性能提升类似,使用推测解码时,端到端延迟会减少一半。
- 随着并发用户数量的增加,生成时间确实会慢慢增加,但仍然比不使用 spec-dec 时要低得多。
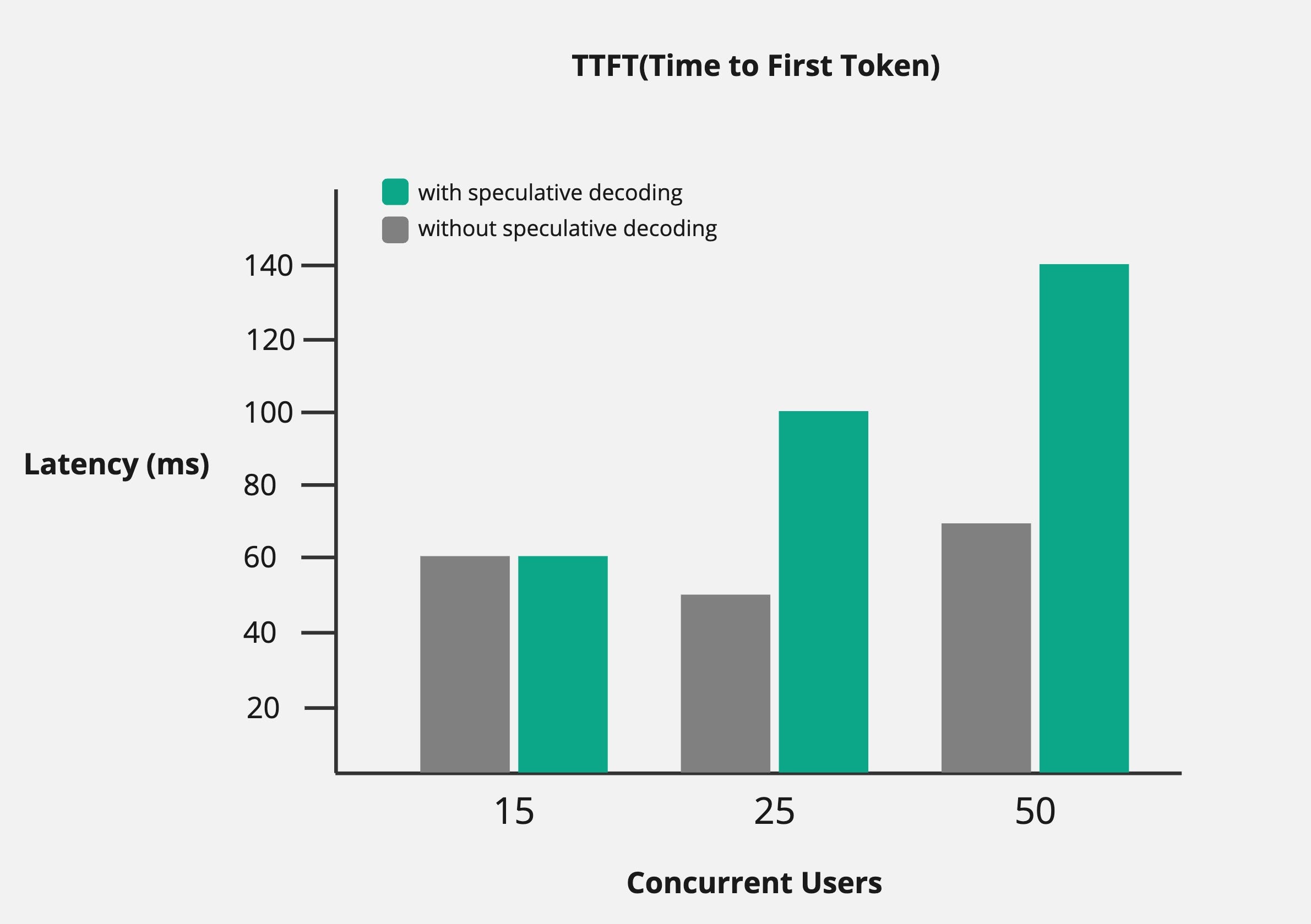
薄膜晶体管
- TTFT 在推测解码的情况下实际上表现更差。
- 原因是,在主模型验证生成的 token 之前,辅助模型必须生成 token。这会浪费一些时间,导致 TTFT 更高。
潜在挑战
推测解码似乎是一个本垒打,特别是因为它使用 vLLM 非常容易设置。然而,在使用这种推理加速技术时,需要注意一些事项。
- 选择合适的助手和主模型
使用 spec-dec 时,并非所有大型语言模型都相互兼容。例如,您不能使用 llama 2 7B 作为辅助模型,而使用 llama 3 70B 作为主模型。
这是因为辅助模型和主模型必须共享相同的词汇表。Llama 2 的词汇表大小为 32K 个标记,而 llama 3 的词汇表大小为 128K 个标记。
2.助手模型的尺寸很重要
由于推测解码依赖辅助模型来完成大部分繁重的工作,因此选择更快的辅助模型可以获得更高的性能。
理想情况下,辅助模型应该具有很少的参数,以便能够快速生成 token。但代价是较小的模型往往不太准确,这引出了我的第三点。
3.主要型号合格率
主模型的高接受率至关重要。如果主模型继续拒绝助手生成的大部分标记,它(较大的模型)现在必须自动回归生成其余的序列。
这会导致 TPS 和整体生成时间的性能大幅下降,因为相同的工作必须重复两次。最好尝试各种模型,看看哪一对模型的接受率最高。
对于上例中的 llama 3.1 70B 和 8B 对,主模型的接受率约为 70%。
结论
对于 LLM 推理而言,速度是一个重要因素,因为没有人愿意让用户久等。推测解码之类的工具可以成为一种很好的解决方案,同时保持较高的输出质量。
在这篇博文中,我们介绍了推测解码的工作原理以及如何使用 vLLM 实现它。虽然它不是每个 LLM 用例的完美解决方案,但它总是好工具。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)

















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









