






1.神经元
在生物学中,神经元细胞有兴奋与抑制两种状态。大多数神经元细胞在正常情况下处于抑制状态,一旦某个神经元受到刺激并且电位超过一定的阈值后,这个神经元细胞就被激活,处于兴奋状态,并向其他神经元传递信息。基于神经元细胞的结构特性与传递信息方式,神经科学家 Warren McCulloch 和逻辑学家 Walter Pitts 合作提出了“McCulloch–Pitts (MCP) neuron”模型。在人工神经网络中,MCP模型成为人工神经网络中的最基本结构。MCP模型结构如 图1 所示。
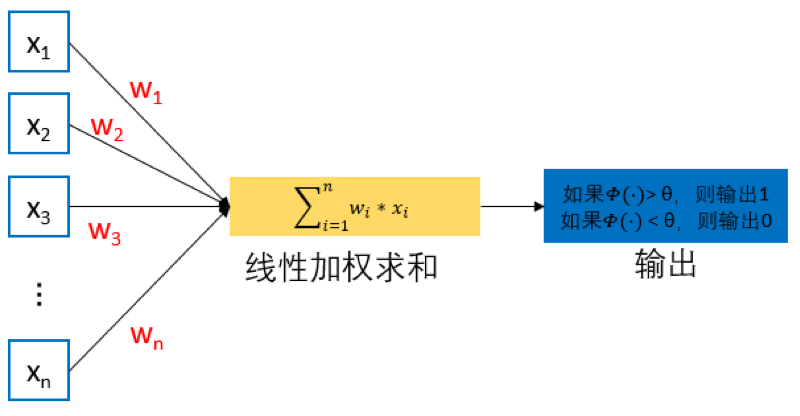
从 图1 可见,给定 n 个二值化(0或1)的输入数据 x _ i x\_i x_i(1≤i≤n)与连接参数 w _ i w\_i w_i(1≤i≤n),MCP 神经元模型对输入数据线性加权求和,然后使用函数 Φ()将加权累加结果映射为 0 或 1 ,以完成两类分类的任务: y = Φ ( ∑ _ n _ i = 1 w _ i x _ i ) y=Φ(∑\_{n\_i=1}w\_ix\_i) y=Φ(∑_n_i=1w_ix_i)
其中 w _ i w\_i w_i为预先设定的连接权重值(一般在 0 和 1 中取一个值或者 1 和 -1 中取一个值),用来表示其所对应输入数据对输出结果的影响(即权重)。Φ()将输入端数据与连接权重所得线性加权累加结果与预先设定阈值 θ进行比较,根据比较结果输出 1 或 0。
具体而言,如果线性加权累加结果(即 ∑mi=1wixi)大于阈值 θ,则函数 Φ()的输出为1、否则为0。也就是说,如果线性加权累加结果大于阈值 θ,则神经元细胞处于兴奋状态,向后传递 1 的信息,否则该神经元细胞处于抑制状态而不向后传递信息。
从另外一个角度来看,对于任何输入数据 x _ i x\_i x_i(1≤i≤n),MCP 模型可得到 1 或 0 这样的输出结果,实现了将输入数据分类到 1 或 0 两个类别中,解决了二分类问题。
2.单层感知机
2.1单层感知机模型¶
1957年 Frank Rosenblatt 提出了一种简单的人工神经网络,被称之为感知机。早期的感知机结构和 MCP 模型相似,由一个输入层和一个输出层构成,因此也被称为“单层感知机”。感知机的输入层负责接收实数值的输入向量,输出层则为1或-1两个值。单层感知机可作为一种二分类线性分类模型,结构如 图2 所示。

单层感知机的模型可以简单表示为: f ( x ) = s i g n ( w ∗ x + b ) f(x)=sign(w∗x+b) f(x)=sign(w∗x+b)
对于具有 n个输入
x
_
i
x\_i
x_i以及对应连接权重系数为
w
_
j
w\_j
w_j的感知机,首先通过线性加权得到输入数据的累加结果
z
z
z:
z
=
w
_
1
x
_
1
+
w
_
2
x
_
2
+
.
.
.
+
b
z=w\_1x\_1+w\_2x\_2+...+b
z=w_1x_1+w_2x_2+...+b。这里
x
_
1
,
x
_
2
,
.
.
.
,
x
_
n
x\_1,x\_2,...,x\_n
x_1,x_2,...,x_n为感知机的输入,w1,w2,…,wn
为网络的权重系数,b为偏置项(
b
i
a
s
bias
bias)。然后将
z
z
z作为激活函数 Φ(⋅)的输入,这里激活函数 Φ(⋅)为
s
i
g
n
sign
sign函数,其表达式为:
KaTeX parse error: Expected 'EOF', got '&' at position 18: …begin{cases}+1 &̲ x \\geq0 \\-1 …
Φ(⋅)会将 z z z 与某一阈值(此例中,阈值为0)进行比较,如果大于等于该阈值则感知器输出为 1,否则输出为 −1。通过这样的操作,输入数据被分类为 1或 −1这两个不同类别。
2.2 训练过程
给定一个 n维数据集,如果它可以被一个超平面完全分割,那么我们称这个数据集为线性可分数据集,否则,则为线性不可分的数据集。单层感知机只能处理线性可分数据集,其任务是寻找一个线性可分的超平面将所有的正类和负类划分到超平面两侧。单层感知机与 M C P MCP MCP模型在连接权重设置上是不同的,即感知机中连接权重参数并不是预先设定好的,而是通过多次迭代训练而得到的。单层感知机通过构建损失函数来计算模型预测值与数据真实值间的误差,通过最小化代价函数来优化模型参数。
其具体的训练过程为:

2.3 单层感知机存在的问题¶
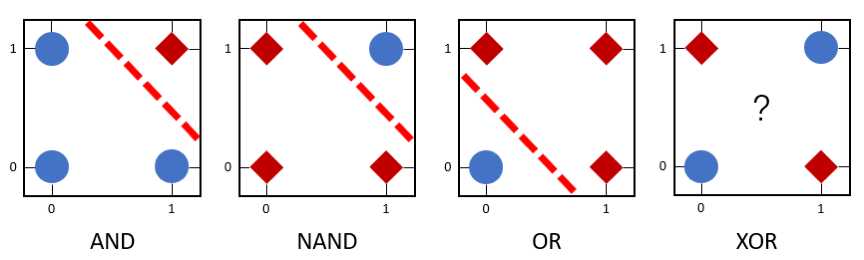
单层感知机可被用来区分线性可分数据。在 图3 中,逻辑与(AND)、逻辑与非(NAND)和逻辑或(OR)为线性可分函数,所以可利用单层感知机来模拟这些逻辑函数。但是,由于逻辑异或(XOR)是非线性可分的逻辑函数,因此单层感知机无法模拟逻辑异或函数的功能。
3. 多层感知机
由于无法模拟诸如异或以及其他复杂函数的功能,使得单层感知机的应用较为单一。一个简单的想法是,如果能在感知机模型中增加若干隐藏层,增强神经网络的非线性表达能力,就会让神经网络具有更强拟合能力。因此,由多个隐藏层构成的多层感知机被提出。
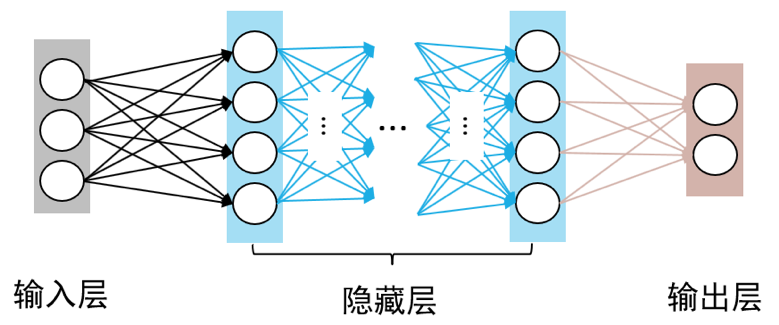
如 图5所示,多层感知机由输入层、输出层和至少一层的隐藏层构成。网络中各个隐藏层中神经元可接收相邻前序隐藏层中所有神经元传递而来的信息,经过加工处理后将信息输出给相邻后续隐藏层中所有神经元。
在多层感知机中,相邻层所包含的神经元之间通常使用“全连接”方式进行连接。所谓“全连接”是指两个相邻层之间的神经元相互成对连接,但同一层内神经元之间没有连接。多层感知机可以模拟复杂非线性函数功能,所模拟函数的复杂性取决于网络隐藏层数目和各层中神经元数目。
4.向量距离与相似度
假设当前有两个 n n n维向量 x x x和 y y y(除非特别说明,本文默认依此写法表示向量),可以通过两个向量之间的距离或者相似度来判定这两个向量的相近程度,显然两个向量之间距离越小,相似度越高;两个向量之间距离越大,相似度越低。
4.1 常见的距离计算方式¶
4.1.1 闵可夫斯基距离(Minkowski Distance)
Minkowski Distane 是对多个距离度量公式概括性的表述,当p=1时,Minkowski Distane 便是曼哈顿距离;当p=2时,Minkowski Distane 便是欧式距离;Minkowski Distane 取极限的形式便是切比雪夫距离。
t e x t M i n k o w s k i D i s t a n c e = l e f t ( s u m _ i = 1 n l e f t ∣ x _ i − y _ i r i g h t ∣ p r i g h t ) f r a c 1 p \\text { Minkowski Distance }=\\left(\\sum\_{i=1}n\\left|x\_i-y\_i\\right|p\\right)^{\\frac{1}{p}} textMinkowskiDistance=left(sum_i=1nleft∣x_i−y_iright∣pright)frac1p
4.1.2 曼哈顿距离(Manhattan Distance)
t e x t M a n h a t t a n D i s t a n c e = l e f t ( s u m _ i = 1 n l e f t ∣ x _ i − y _ i r i g h t ∣ r i g h t ) \\text { Manhattan Distance }=\\left(\\sum\_{i=1}^n\\left|x\_i-y\_i\\right|\\right) textManhattanDistance=left(sum_i=1nleft∣x_i−y_iright∣right)
4.1.3 欧式距离/欧几里得距离(Euclidean distance)
t e x t E u c l i d e a n D i s t a n c e = s q r t s u m _ i = 1 n l e f t ( x _ i − y _ i r i g h t ) 2 \\text { Euclidean Distance }=\\sqrt{\\sum\_{i=1}n\\left(x\_i-y\_i\\right)2} textEuclideanDistance=sqrtsum_i=1nleft(x_i−y_iright)2
4.1.4 切比雪夫距离(Chebyshev Distance)
l i m p r i g h t a r r o w i n f t y l e f t ( s u m n l e f t ∣ x _ i − y _ i r i g h t ∣ p r i g h t ) f r a c 1 p = m a x l e f t ( l e f t ∣ x _ i − y _ i r i g h t ∣ r i g h t ) \\lim _{p \\rightarrow \\infty}\\left(\\sum_n\\left|x\_i-y\_i\\right|p\\right)^{\\frac{1}{p}}=\\max \\left(\\left|x\_i-y\_i\\right|\\right) limprightarrowinftyleft(sumnleft∣x_i−y_iright∣pright)frac1p=maxleft(left∣x_i−y_iright∣right)
4.1.5 明距离(Hamming Distance)
在信息论中,两个等长字符串之间的海明距离是两个字符串对应位置的不同字符的个数。假设有两个字符串分别是:KaTeX parse error: Undefined control sequence: \[ at position 3: x=\̲[̲x1,x2,...,x\_n\…和KaTeX parse error: Undefined control sequence: \[ at position 3: y=\̲[̲y1,y2,...,y\_n\…,则两者的距离为:
\text { Hamming Distance }=\sum_{i=1}^n \mathrm{II}\left(x_i=y_i\right)
其中 I I II II表示指示函数,两者相同为1,否则为0。
4.1.6 KL散度
给定随机变量 X X X和两个概率分布 P P P和 Q Q Q,KL散度可以用来衡量两个分布之间的差异性,其公式如下:
K L ( P ∣ Q ) = s u m _ x i n X p ( x ) l o g f r a c P ( x ) Q ( x ) K L(P | Q)=\\sum\_{x \\in X} p(x) \\log \\frac{P(x)}{Q(x)} KL(P∣Q)=sum_xinXp(x)logfracP(x)Q(x)
5.常见的相似度函数
5.1 余弦相似度(Cosine Similarity)
t e x t C o s i n e S i m i l a r i t y = f r a c x c d o t y ∣ x ∣ c d o t ∣ y ∣ = f r a c s u m _ i = 1 n x _ i y _ i s q r t s u m _ i = 1 n x _ i 2 s q r t s u m _ i = 1 n y _ i 2 \\text { Cosine Similarity }=\\frac{x \\cdot y}{|x| \\cdot|y|}=\\frac{\\sum\_{i=1}^n x\_i y\_i}{\\sqrt{\\sum\_{i=1}^n x\_i^2} \\sqrt{\\sum\_{i=1}^n y\_i^2}} textCosineSimilarity=fracxcdoty∣x∣cdot∣y∣=fracsum_i=1nx_iy_isqrtsum_i=1nx_i2sqrtsum_i=1ny_i2
5.2皮尔逊相关系数 (Pearson Correlation Coefficient)
给定两个随机变量X和Y,皮尔逊相关系数可以用来衡量两者的相关程度,公式如下:
KaTeX parse error: Expected 'EOF', got '&' at position 34: … \\rho\_{x, y} &̲ =\\frac{\\oper…
其中 μ _ X μ\_X μ_X和 μ _ Y μ\_Y μ_Y分别表示向量X和Y的均值, σ _ X σ\_X σ_X和 σ _ Y σ\_Y σ_Y分别表示向量X和Y的标准差。
5.3Jaccard 相似系数(Jaccard Coefficient)
假设有两个集合X和Y(注意这里的两者不是向量),则其计算公式为:
o p e r a t o r n a m e J a c c a r d ( X , Y ) = f r a c X c u p Y X c a p Y \\operatorname{Jaccard}(X, Y)=\\frac{X \\cup Y}{X \\cap Y} operatornameJaccard(X,Y)=fracXcupYXcapY
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









