






性能超越 Llama-3,主要用于合成数据。
英伟达的通用大模型 Nemotron,开源了最新的 3400 亿参数版本。
本周五,英伟达宣布推出 Nemotron-4 340B。它包含一系列开放模型,开发人员可以使用这些模型生成合成数据,用于训练大语言模型(LLM),可用于医疗健康、金融、制造、零售等所有行业的商业应用。
高质量的训练数据在自定义 LLM 的响应性能、准确性和质量中起着至关重要的作用 —— 但强大的数据集经常是昂贵且难以访问的。通过独特的开放模型许可,Nemotron-4 340B 为开发人员提供了一种免费、可扩展的方式来生成合成数据,从而帮助人们构建强大的 LLM。
Nemotron-4 340B 系列包括基础、Instruct 和 Reward 模型,它们形成了一个 pipeline,用于生成训练和改进 LLM 的合成数据。这些模型经过优化,可与 NVIDIA NeMo 配合使用,后者是一个用于端到端模型训练的开源框架,包括数据管理、定制和评估。它们还针对开源 NVIDIA TensorRT-LLM 库的推理进行了优化。
英伟达表示,Nemotron-4 340B 现已可从 Hugging Face 下载。开发人员很快就能在 ai.nvidia.com 上访问这些模型,它们将被打包为 NVIDIA NIM 微服务,并带有可在任何地方部署的标准应用程序编程接口。
Hugging Face 下载:huggingface.co/collections…
导航 Nemotron 以生成合成数据
大语言模型可以帮助开发人员在无法访问大型、多样化标记数据集的情况下生成合成训练数据。
Nemotron-4 340B Instruct 模型创建了多样化的合成数据,模仿了现实世界数据的特征,有助于提高数据质量,从而提高自定义 LLM 在各个领域的性能和鲁棒性。
为了提高 AI 生成的数据的质量,开发人员可以使用 Nemotron-4 340B Reward 模型来筛选高质量的响应。Nemotron-4 340B Reward 根据五个属性对响应进行评分:可用性、正确性、连贯性、复杂性和冗长性。它目前在 AI2 创建的 Hugging Face RewardBench 排行榜上名列第一,用于评估奖励模型的能力、安全性和缺陷。

在这个合成数据 pipeline 中,(1)Nemotron-4 340B Instruct 模型用于生成基于文本的合成输出。然后,评估模型(2) Nemotron-4 340B Reward 评估生成的文本并提供反馈,从而指导迭代改进并确保合成数据的准确。
研究人员还可以使用自己的专有数据,结合已包含的 HelpSteer2 数据集,来定制 Nemotron-4 340B 基础模型,从而创建自有的 Instruct 模型或奖励模型。

论文地址:d1qx31qr3h6wln.cloudfront.net/publication…
方法介绍
Nemotron-4-340B-Base 模型架构是一种标准的仅解码器 Transformer 架构,具有因果注意力掩码、旋转位置嵌入 (RoPE)、SentencePiece tokenizer 等。Nemotron-4-340B-Base 的超参数如表 1 所示。它有 94 亿个嵌入参数和 3316 亿个非嵌入参数。

下表为 Nemotron-4-340B-Base 模型的一些训练细节,表中总结了批大小渐变的 3 个阶段,包括每次迭代时间和模型 FLOP/s 利用率。

为了开发强大的奖励模型,英伟达收集了一个包含 10k 人类偏好数据的数据集,称为 HelpSteer2,并公开发布了这个数据集 。
数据集地址:huggingface.co/datasets/nv…
回归奖励模型 Nemotron-4-340B-Reward 建立在 Nemotron-4-340B-Base 模型之上,并用新的奖励头替换最后的 softmax 层。这个头是一个线性投影,它将最后一层的隐藏状态映射到 HelpSteer 属性(有用性、正确性、连贯性、复杂性、冗长性)的五维向量中。在推理过程中,这些属性值可以通过加权和聚合为总体奖励。这种奖励模式为训练 Nemotron-4-340B-Instruct 提供了坚实的基础。
该研究发现这样的模型在 RewardBench 上表现非常出色:

用 NeMo 微调,用 TensorRT-LLM 优化推理
使用开源的 NVIDIA NeMo 和 NVIDIA TensorRT-LLM,开发者可以优化他们的指导模型和奖励模型的效率,从而生成合成数据并对响应进行评分。
所有 Nemotron-4 340B 模型都使用 TensorRT-LLM 进行了优化,以利用张量并行性,这是一种模型并行性,其中单个权重矩阵在多个 GPU 和服务器上分割,从而实现大规模的高效推理。
Nemotron-4 340B Base 经过 9 万亿个 token 的训练,可以使用 NeMo 框架进行定制,以适应特定的用例或领域。这种微调过程受益于大量的预训练数据,并为特定的下游任务提供更准确的输出。
在这当中,NeMo 框架提供了多种定制方法,包括监督微调和参数高效微调方法,如低秩自适应 (LoRA)。
为了提升模型质量,开发者可以使用 NeMo Aligner 和由 Nemotron-4 340B Reward 注释的数据集对其模型进行对齐。对齐是训练大型语言模型的一个关键步骤,其中模型行为通过使用类似 RLHF 算法进行微调,以确保其输出安全、准确、符合上下文且与其既定目标一致。
寻求企业级支持和生产环境安全的企业也可以通过云原生的 NVIDIA AI Enterprise 软件平台访问 NeMo 和 TensorRT-LLM。该平台为生成式 AI 基础模型提供了加速和高效的运行时环境。
评测数据
图 1 突出显示了 Nemotron-4 340B 模型家族在选定任务中的准确性。具体来说:
Nemotron-4-340B-Base 在 ARC-Challenge、MMLU 和 BigBench Hard 基准等常识推理任务上与 Llama-3 70B、Mixtral 8x22B 和 Qwen-2 72B 等开放访问基础模型相媲美。
在指令遵循和聊天功能方面,Nemotron-4-340B-Instruct 超越了相应的指令模型。Nemotron-4-340B Reward 在 RewardBench 上实现了最高准确率,甚至超越了 GPT-4o-0513 和 Gemini 1.5 Pro-0514 等专有模型。

在 Nemotron-4-340B 推出后,评测平台立即放出了它的基准成绩,可见在 Arena-Hard-Auto 等硬基准测试中它的成绩超越了 Llama-3-70b

这是否意味着,新的业界最强大模型已经出现?
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
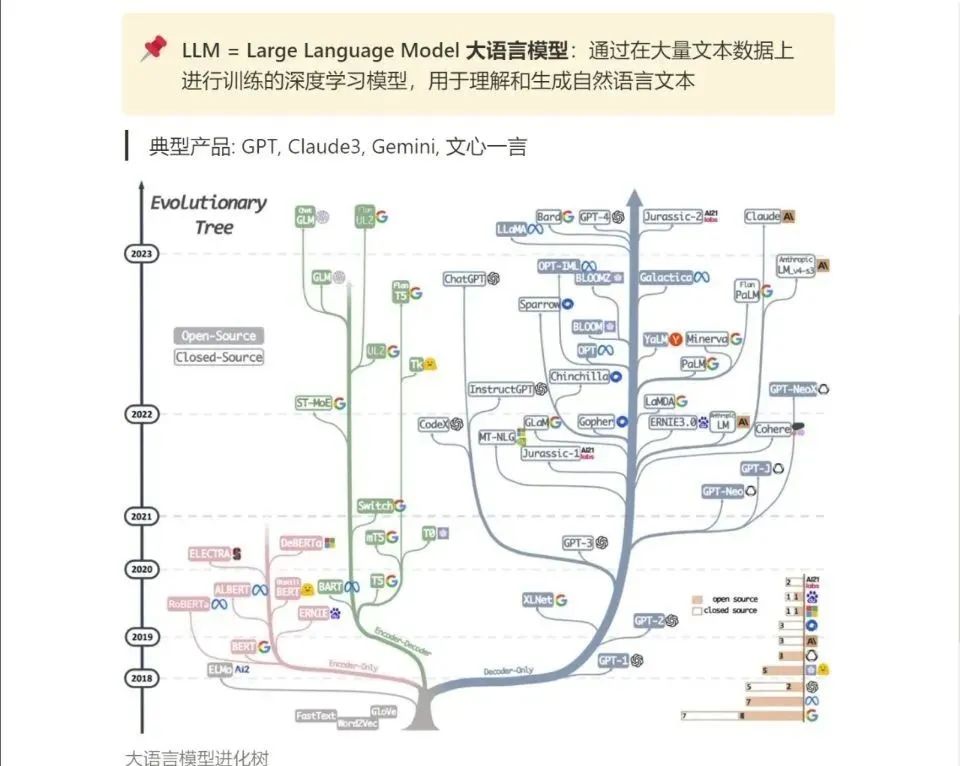
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









