






前言
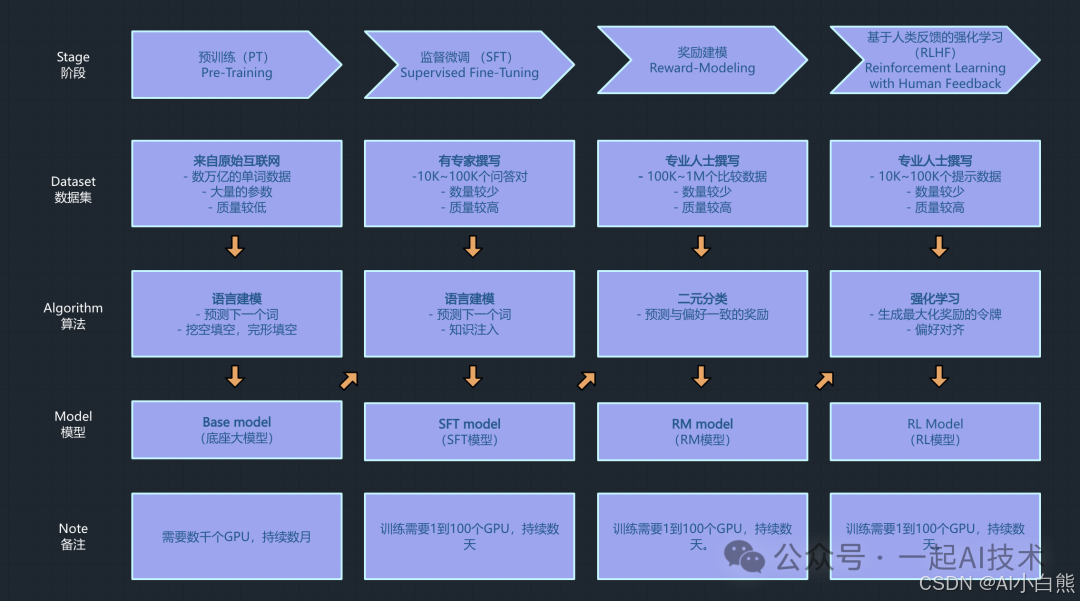
本章我们将通过 LLaMA-Factory 具体实践大模型训练的三个阶段,包括:预训练、监督微调和偏好纠正。
大模型训练回顾
训练目标
训练一个医疗大模型
训练过程实施
准备训练框架
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架,GitHub星标超过2万。
运行环境要求
-
• 硬件:
-
• GPU:推荐使用24GB显存的显卡或者更高配置
-
• 软件:
-
• python:3.10
-
• pytorch:2.1.2 + cuda12.1
-
• 操作系统:Ubuntu 22.04
推荐选择DSW官方镜像:
modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04
下载训练框架
第一步:登录ModelScope平台,启动PAI-DSW的GPU环境,并进入容器。
第二步:在容器中,通过命令行拉取代码。
# 拉取代码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入代码目录
cd LLaMA-Factory
# 安装依赖
pip install -e ".[torch,metrics]"
第三步:检查环境是否安装成功。
llamafactory-cli version
正常安装成功显示如下:

- 如果安装不成功,需要根据提示信息进行逐个问题解决。
- 一般情况下,在ModelScope平台中,一般会出现
Keras版本不匹配的问题,可以运行pip install tf-keras解决。
第四步:进行端口映射命令 由于阿里云平台的端口映射似乎存在问题,这会导致启动LLaMA Factory的Web界面显示异常,所以需要手动在命令行运行如下命令:
export GRADIO_SERVER_PORT=7860 GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/
第五步:命令行下运行命令,启动WebUI界面
llamafactory-cli webui
启动后,点击返回信息中的http://0.0.0.0:7860,可以看到Web界面。
准备训练模型
选择模型
在开展大模型训练之前,由于我们不能从零开始训练一个大模型(时间及资源都不允许!),所以我们需要选择一个已经训练好的模型,作为基础模型进行训练。
在ModelScope平台,我们选择Qwen2-0.5B模型作为底座模型。
下载模型
第一步:拉取代码
git clone https://www.modelscope.cn/qwen/Qwen2-0.5B.git
第二步:在LLaMA-Factory下创建models目录,方便后续模型都维护在该目录下。
第三步:移动模型目录到LLaMA-Factory的models目录下。
LLaMA-Factory/
|-models/
|-Qwen2-0.5B/
验证模型
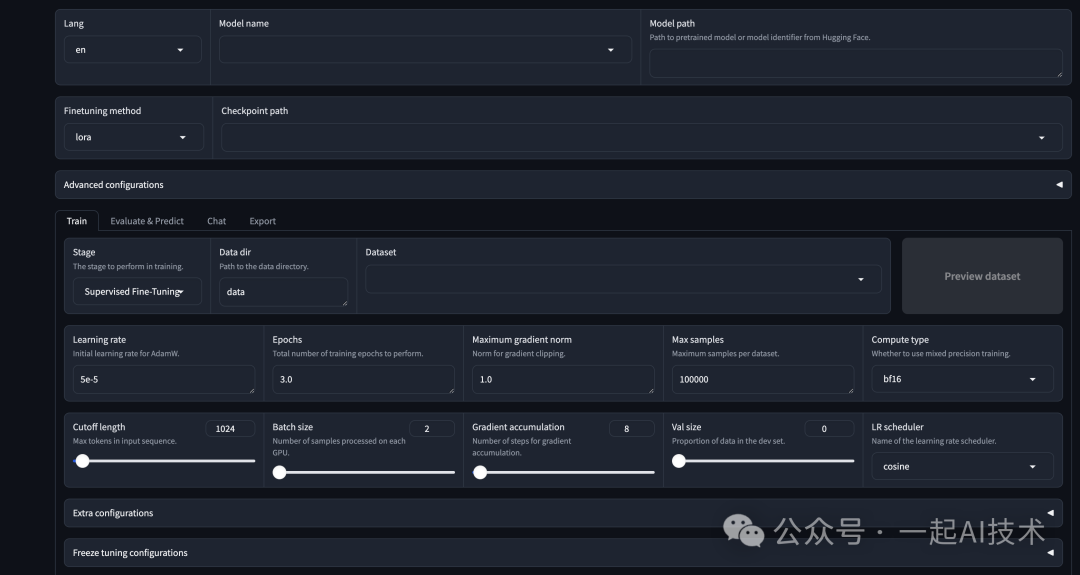
第一步:在LLaMA-Factory的WebUI界面,进行相关配置。
-
• Model name:
Qwen2-0.5B -
• Model path:
models/Qwen2-0.5Bmodels/Qwen2-0.5B对应下载模型第三步中的路径。由于Linux系统是大小写敏感,所以需要特别注意页面配置路径与实际路径大小写要保持一致。
第二步:切换Tab为 Chat , 点击 Load model按钮。 模型加载成功后,会显示如下界面。
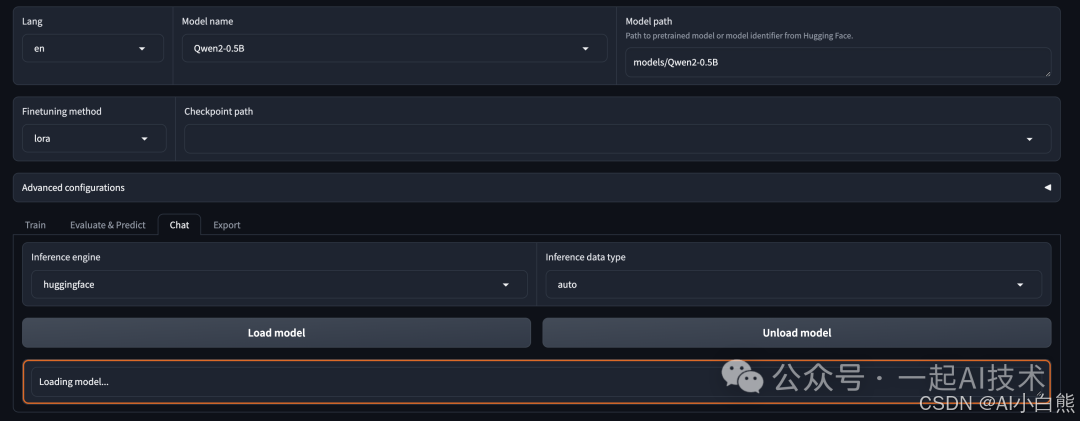
如果出现错误,可以通过切换到启动
LLaMA Factory的命令行查看日志信息排查问题。
第三步:在Chat的对话框中,输入简单信息验证模型能否使用。
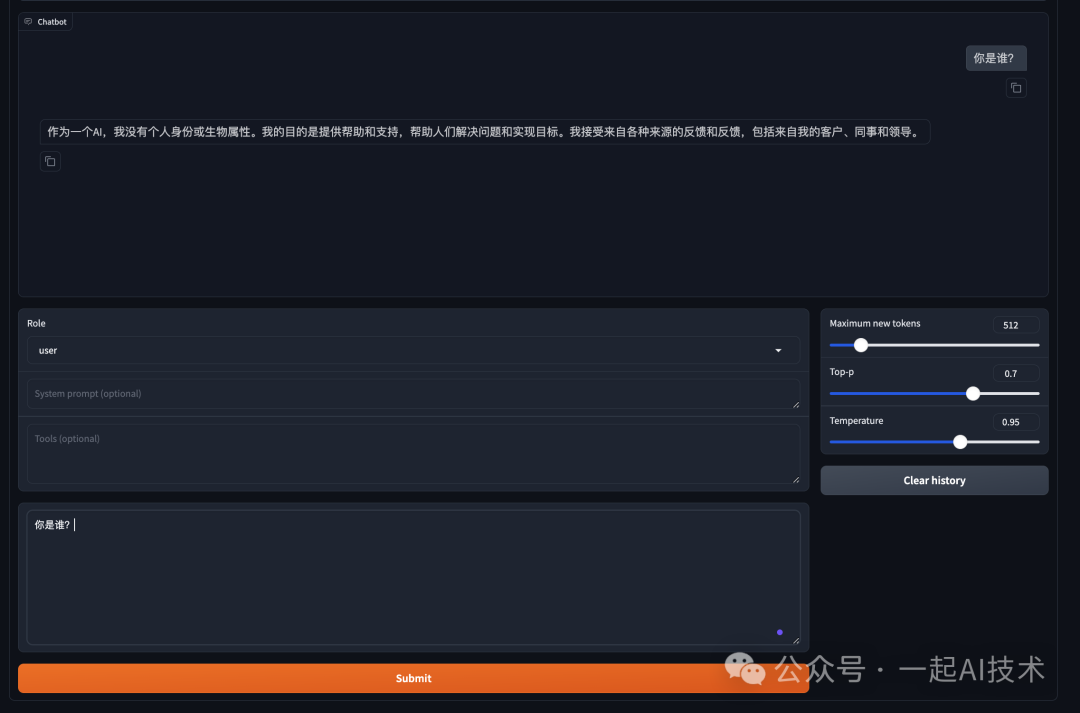
由于当前加载的
Qwen2-0.5B是一个基础模型,所以其对话能力会非常弱,这里我们主要是验证模型加载的整体流程是否通顺。

第1阶段:预训练
❗由于大模型的预训练需要数千个GPU并持续数月的时间,所以一般情况下实际工作中并不会涉及到预训练,本篇文章我们只做的简单流程体验。
准备训练数据
说明:LLaMa-Factory的Github上有训练数据格式的详细说明,请见README_zh。
-
• 预训练数据格式:
[ {"text": "document"}, {"text": "document"} ] -
• 数据集样例:
按照数据集样例,我们准备如下的自定义预训练数据集,保存到data/custom_pt_train_data.json。
[
{"text":"患者在过去的五年中多次出现头痛症状。"},
{"text":"研究表明,适量运动有助于改善心血管健康。"},
{"text":"高血压患者需定期监测血压水平。"},
{"text":"糖尿病患者应注意饮食控制和胰岛素使用。"},
{"text":"流感疫苗每年接种可以有效预防流感。"},
{"text":"保持良好的睡眠习惯对心理健康至关重要。"},
{"text":"慢性咳嗽可能是肺部疾病的早期征兆。"},
{"text":"定期体检可以帮助早期发现健康问题。"},
{"text":"心理咨询对缓解焦虑和抑郁症状有效。"},
{"text":"饮食中增加纤维素有助于消化系统健康。"},
{"text":"适量饮水对维持身体正常功能非常重要。"},
{"text":"戒烟可以显著降低患肺癌的风险。"},
{"text":"高胆固醇水平可能导致心脏病。"},
{"text":"保持健康体重有助于降低多种疾病风险。"},
{"text":"心理健康与身体健康密切相关。"},
{"text":"儿童应定期进行视力和听力检查。"},
{"text":"老年人易患骨质疏松症,需注意补钙。"},
{"text":"过度饮酒会对肝脏造成严重损害。"},
{"text":"心脏病患者应遵循医生的治疗方案。"},
{"text":"良好的饮食习惯可以改善生活质量。"},
{"text":"运动可以帮助减少压力和焦虑。"},
{"text":"戒烟后,肺部功能会逐渐恢复。"},
{"text":"高血糖可能导致多种并发症。"},
{"text":"定期锻炼有助于提高免疫力。"},
{"text":"适量的社交活动可以提高生活满意度。"},
{"text":"健康的生活习惯可以改善整体健康状况。"},
{"text":"心理健康教育应引起全社会的重视。"}
]
注册自定义数据
根据LLaMa-Factory的README,我们需要在dataset_info.json中按照以下格式注册自定义的数据集。
- • 数据集注册格式:
"数据集名称": { "file_name": "data.json", "columns": { "prompt": "text" } }
我们在data/dataset_info.json中添加如下数据集:
"custom_pt_train_data": {
"file_name": "custom_pt_train_data.json",
"columns": {
"prompt": "text"
}
}
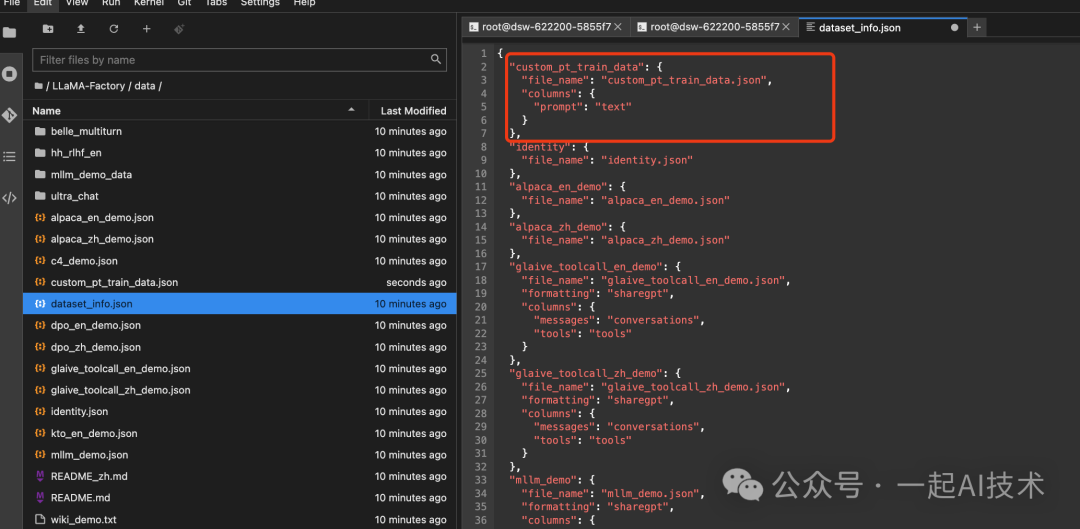
预览训练数据
在 LLaMa-Factory的WebUI界面上,选择Dataset为 custom_pt_train_data,点击Preview dataset按钮,预览数据集。
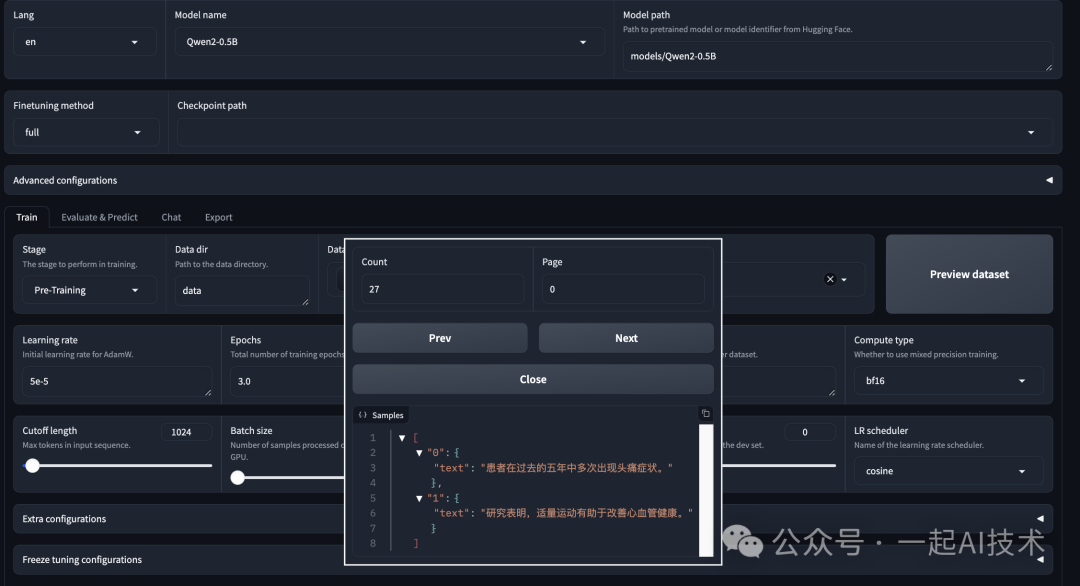
配置训练参数
-
• Model name:
Qwen2-0.5B -
• Model path:
models/Qwen2-0.5B -
• Finetuning method:
full -
• Stage :
Pre-Training -
• Dataset:
custom_pt_train_data,c4_demo,wikipedia_zh -
• Output dir:
Qwen2_pretrain_output_demo1
参数简要说明:
-
•
Finetuning method代表微调的方法: -
•
full: 完全微调模型的所有参数。 -
•
Freeze:冻结模型的某些层或所有层,仅微调特定的参数。 -
•
LoRA (Low-Rank Adaptation):在不改变原始模型参数的情况下,通过添加少量的可训练参数来适应新任务。 -
•
Stage代表训练的阶段: -
•
Pre-Training: 预训练阶段。 -
•
Supervised Fine-Tuning: 微调阶段。 -
•
Reward Model: 奖励模型是一个过程,通过构建一个模型来预测给定输入的奖励值,通过训练奖励模型,可以为后续的强化学习提供一个目标。 -
•
PPO (Proximal Policy Optimization): PPO是一种强化学习算法,旨在优化策略(即模型的行为),以最大化预期奖励。 -
•
DPO (Direct Preference Optimization): DPO是一种直接优化偏好的方法,通常用于根据人类反馈直接调整模型的输出。 -
•
KTO (Knowledge Transfer Optimization): KTO指的是知识迁移优化,旨在从一个任务或模型中迁移知识到另一个任务或模型。
启动训练
点击Preview Command预览命令行无误后,点击Start即可开启训练。
如果启动训练失败,可以通过切换到启动
LLaMA Factory的命令行查看日志信息排查问题。 例如:我首次启动时报错如下:
# ConnectionError: Couldn't reach 'pleisto/wikipedia-cn-20230720-filtered' on the Hub (ConnectionError)
这个问题是因为加载wikipedia-cn-20230720-filtered数据集时,由于网络问题,导致无法加载。因此,本着将训练流程跑通,我将数据集改为
wiki_demo后运行,即可正常训练。
正常训练过程:
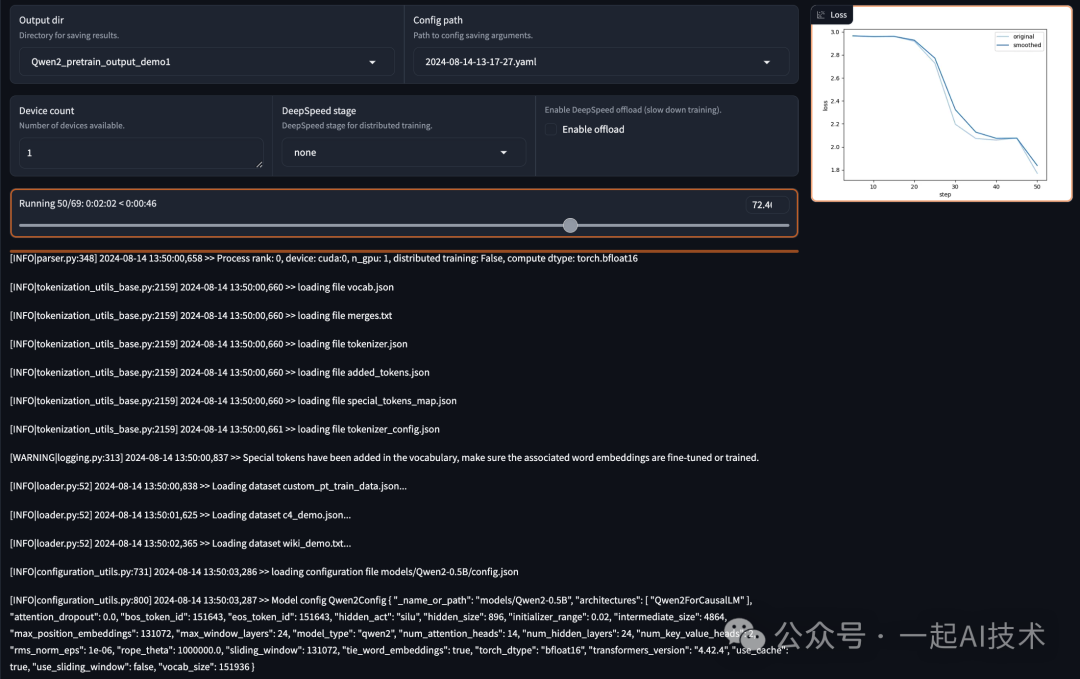
第2阶段:监督微调
准备训练数据
SFT 的数据格式有多种,例如:Alpaca格式、OpenAI格式等。
其中Alpaca格式如下:
[
{
"instruction":"human instruction (required)",
"input":"human input (optional)",
"output":"model response (required)",
"system":"system prompt (optional)",
"history":[
["human instruction in the first round (optional)","model response in the first round (optional)"],
["human instruction in the second round (optional)","model response in the second round (optional)"]
]
}
]
根据以上的数据格式,我们在ModelScope的数据集找到中文医疗对话数据-Chinese-medical-dialogue符合上述格式。
# 在data目录下使用git命令拉取数据集
git clone https://www.modelscope.cn/datasets/xiaofengalg/Chinese-medical-dialogue.git
注册自定义数据
在dataset_info.json中添加如下数据集:
"custom_sft_train_data":{
"file_name":"Chinese-medical-dialogue/data/train_0001_of_0001.json",
"columns":{
"prompt":"instruction",
"query":"input",
"response":"output"
}
},
预览训练数据
通过Preview dataset按钮预览数据集。
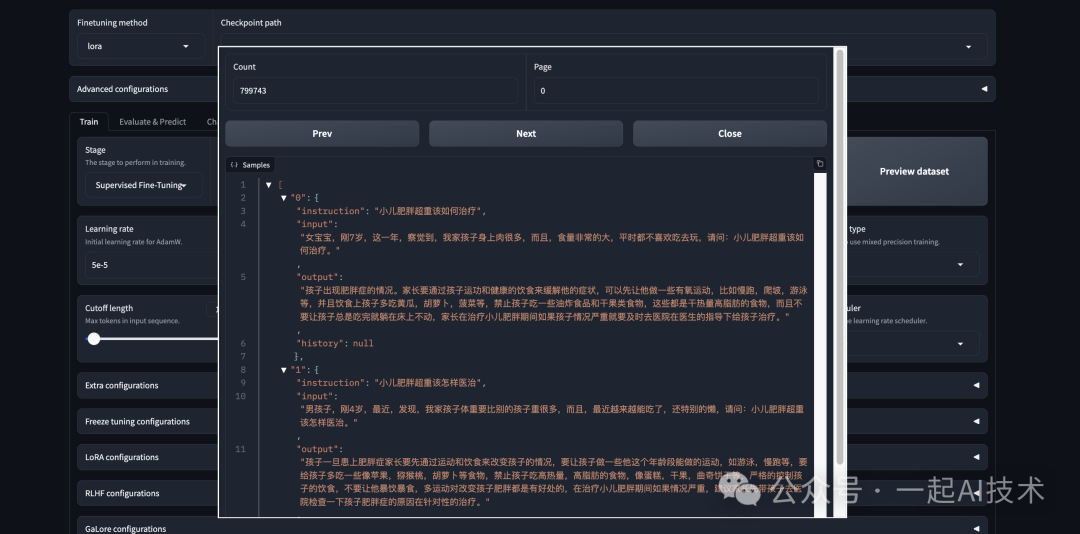
配置训练参数
-
• Model name:
Qwen2-0.5B -
• Model path:
saves/Qwen2-0.5B/full/Qwen2_pretrain_output_demo1 -
• Finetuning method:
full -
• Stage :
Supervised Fine-Tuning -
• Dataset:
custom_sft_train_data -
• Output dir:
Qwen2_sft_output_demo1
配置参数说明:
-
•
Model path:我们选择第1阶段预训练模型的输出目录。 -
•
Stage:这一阶段,因为我们要进行微调,选择Supervised Fine-Tuning。 -
•
Output dir: 更换一个新的输出路径,以便后续开展第3阶段训练,例如:Qwen2_sft_output_demo1
启动训练
点击Preview Command预览命令行
llamafactory-cli train
--stage sft
--do_train True
--model_name_or_path saves/Qwen2-0.5B/full/Qwen2_pretrain_output_demo1
--preprocessing_num_workers 16
--finetuning_type full
--template default
--flash_attn auto
--dataset_dir data
--dataset custom_sft_train_data
--cutoff_len 1024
--learning_rate 5e-05
--num_train_epochs 3.0
--max_samples 100000
--per_device_train_batch_size 2
--gradient_accumulation_steps 8
--lr_scheduler_type cosine
--max_grad_norm 1.0
--logging_steps 5
--save_steps 100
--warmup_steps 0
--optim adamw_torch
--packing False
--report_to none
--output_dir saves/Qwen2-0.5B/full/Qwen2_sft_output_demo1
--bf16 True
--plot_loss True
--ddp_timeout 180000000
--include_num_input_tokens_seen True
补充说明:
-
•
--logging_steps 5: 每 5 步记录一次训练日志。 -
•
--save_steps 100: 每 100 步保存一次模型检查点。这里最好将
save_steps设置大一点,否则训练过程会生成非常多的训练日志,导致硬盘空间不足而训练终止。
命令行确认无误后,点击Start即可开启训练。
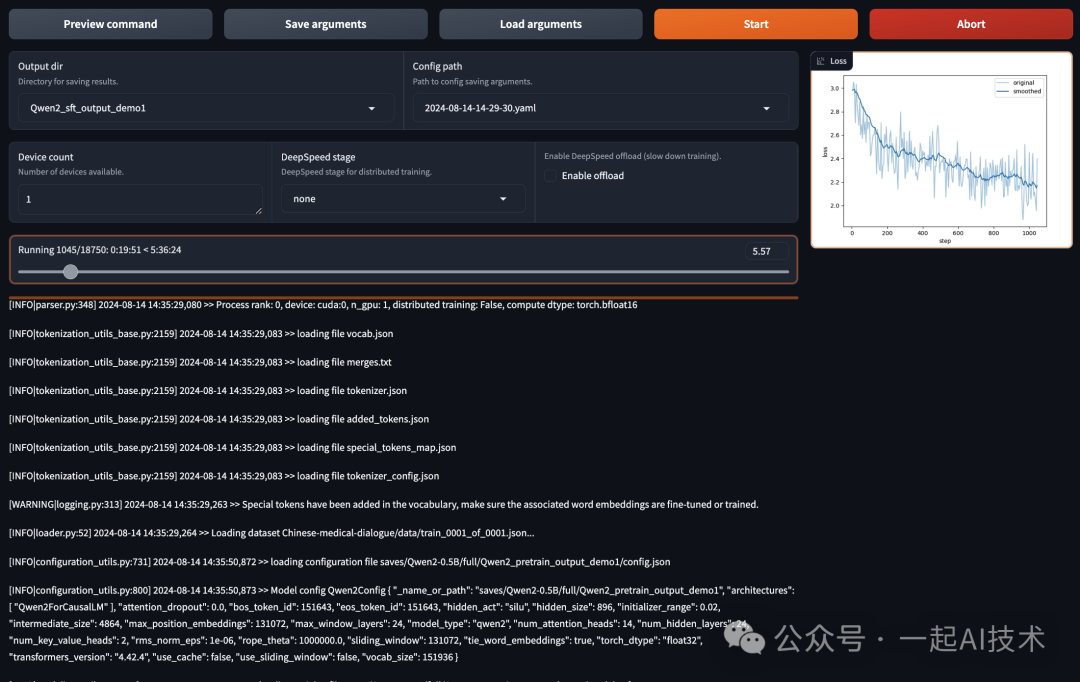
训练过程中,记得实时关注资源的消耗情况:
• 显存:使用
watch -n 1 nvidia-smi实时查看显存开销。• 硬盘:使用
watch -n 1 df -h /mnt实施查看/mnt分区的磁盘使用情况。
历时5小时30分钟后,模型终于训练完毕。(大模型的训练果然是一个烧钱💰的过程)
验证模型
-
- 在LLaMA Factory的WebUI界面上,切换至
Chat界面
- 在LLaMA Factory的WebUI界面上,切换至
-
- Model path: 输入刚才训练模型的输出目录,即
saves/Qwen2-0.5B/full/Qwen2_sft_output_demo1
- Model path: 输入刚才训练模型的输出目录,即
-
- 其他配置保持默认不变;
-
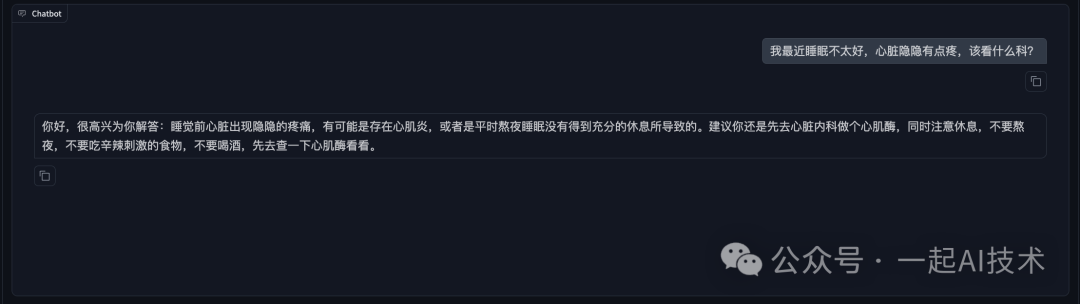
- 点击
Load model,待模型加载成功后,输入看病相关的信息,测试模型的能力。
- 点击
第3阶段:偏好纠正
准备训练数据
- • 纠正偏好数据格式:
[ { "instruction": "human instruction (required)", "input": "human input (optional)", "chosen": "chosen answer (required)", "rejected": "rejected answer (required)" } ]按照上述数据格式,我们借助其他的大模型生成20条训练数据并保存到data/custom_rlhf_train_data.json。[ { "instruction":"请提供一种常见的感冒药。", "input":"我需要一种能缓解咳嗽的药。", "chosen":"感冒药如对乙酰氨基酚可以缓解症状。", "rejected":"我不知道有什么药。" }, { "instruction":"解释一下高血压的危害。", "input":"高血压对身体有什么影响?", "chosen":"高血压会增加心脏病和中风的风险。", "rejected":"高血压没什么大不了的。" }, { "instruction":"推荐一种健康的饮食习惯。", "input":"我想减肥,应该吃什么?", "chosen":"建议多吃水果和蔬菜,减少糖分摄入。", "rejected":"只吃沙拉就可以了。" }, { "instruction":"描述糖尿病的症状。", "input":"糖尿病有什么明显的症状?", "chosen":"常见症状包括口渴、频繁排尿和疲劳。", "rejected":"没有什么特别的症状。" }, { "instruction":"如何预防流感?", "input":"我应该怎么做才能不得流感?", "chosen":"接种流感疫苗和勤洗手是有效的预防措施。", "rejected":"只要不出门就行了。" }, { "instruction":"解释一下心脏病的风险因素。", "input":"心脏病的危险因素有哪些?", "chosen":"包括高血压、高胆固醇和吸烟。", "rejected":"心脏病与生活方式无关。" }, { "instruction":"如何缓解焦虑?", "input":"我感到很焦虑,有什么建议?", "chosen":"尝试深呼吸练习和规律锻炼。", "rejected":"焦虑没什么好担心的。" }, { "instruction":"推荐一些适合老年人的锻炼方式。", "input":"老年人适合什么运动?", "chosen":"散步、游泳和太极都是很好的选择。", "rejected":"老年人不需要运动。" }, { "instruction":"解释什么是过敏反应。", "input":"过敏反应是什么?", "chosen":"是免疫系统对某些物质的异常反应。", "rejected":"过敏反应就是感冒。" }, { "instruction":"如何保持心理健康?", "input":"我应该怎么照顾自己的心理健康?", "chosen":"定期与朋友交流和寻求专业帮助是很重要的。", "rejected":"心理健康不重要。" }, { "instruction":"描述高胆固醇的影响。", "input":"高胆固醇对身体有什么影响?", "chosen":"可能导致动脉硬化和心脏病。", "rejected":"高胆固醇没什么影响。" }, { "instruction":"如何识别抑郁症?", "input":"抑郁症的症状有哪些?", "chosen":"包括持续的悲伤、失去兴趣和疲惫感。", "rejected":"抑郁只是心情不好。" }, { "instruction":"建议如何提高免疫力。", "input":"我想增强免疫力,有什么建议?", "chosen":"保持均衡饮食、充足睡眠和适量运动。", "rejected":"吃药就能提高免疫力。" }, { "instruction":"讲解什么是癌症筛查。", "input":"癌症筛查是什么?", "chosen":"是通过检测早期发现癌症的过程。", "rejected":"癌症筛查没必要。" }, { "instruction":"如何处理压力?", "input":"我压力很大,怎么办?", "chosen":"可以尝试冥想和时间管理技巧。", "rejected":"压力是正常的,不必处理。" }, { "instruction":"解释什么是肥胖。", "input":"肥胖是什么?", "chosen":"是体重超过健康范围的状态,通常由多种因素造成。", "rejected":"肥胖只是吃得多。" }, { "instruction":"如何进行健康检查?", "input":"健康检查包括什么?", "chosen":"通常包括体检、血液检查和必要的影像学检查。", "rejected":"健康检查不重要。" }, { "instruction":"推荐一些抗氧化的食物。", "input":"哪些食物富含抗氧化剂?", "chosen":"蓝莓、坚果和绿茶都是很好的选择。", "rejected":"抗氧化食物没什么特别。" }, { "instruction":"解释什么是慢性病。", "input":"慢性病是什么?", "chosen":"是长期存在且通常无法完全治愈的疾病。", "rejected":"慢性病就是普通病。" } ]
注册自定义数据
在dataset_info.json中,注册新添加的custom_rlhf_train_data.json数据集。
"custom_rlhf_train_data":{
"file_name":"custom_rlhf_train_data.json",
"ranking":true,
"columns":{
"prompt":"instruction",
"query":"input",
"chosen":"chosen",
"rejected":"rejected"
}
},
配置训练参数
第三阶段有两种训练方式:Reward Model + PPO 和 DPO,这两种方式我们都做一下尝试。
策略1:Reward Model + PPO
第一步:先训练Reward Model
-
• Finetuning method: 选择
lora(因为是训练补丁,所以此处一定要选择为lora) -
• Stage: 选择
Reward Modeling -
• Dataset: 选择刚才上传
custom_rlhf_train_data.json -
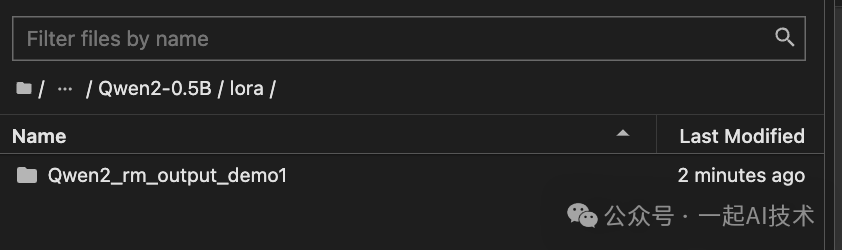
• Output dir:设置一个新的输出目录,例如:
Qwen2_rm_output_demo1
训练完毕后,会在save下生成一个补丁。
第二步:通过PPO+第一步训练时的Reward Model,具体配置方法为:
-
• Finetuning method: 选择
lora(因为是训练补丁,所以此处一定要选择为lora) -
• Stage: 选择
Supervised Fine-tuning -
• Dataset: 由于这一过程本质是
SFT训练,所以数据集选择custom_sft_train_data.json。 -
• Reward model: 在
RLHF configurations中,设置为第一步训练的输出目录,即Qwen2_rm_output_demo1 -
• Output dir:设置一个新的输出目录,例如:
Qwen2_ppo_output_demo1
训练完毕后,同样会在save下生成一个补丁。
第三步:将Lora补丁与原始模型合并导出
-
- 切换到
Chat标签下
- 切换到
-
- Model path: 选择第二阶段的输出,即:
saves/Qwen2-0.5B/full/Qwen2_sft_output_demo1
- Model path: 选择第二阶段的输出,即:
-
- Checkpoint path: 选择上面第二步的输出,即
Qwen2_ppo_output_demo1
- Checkpoint path: 选择上面第二步的输出,即
-
- 点击
Load model,待模型加载成功后,测试模型
- 点击
-
- 切换至
Export标签下
- 切换至
-
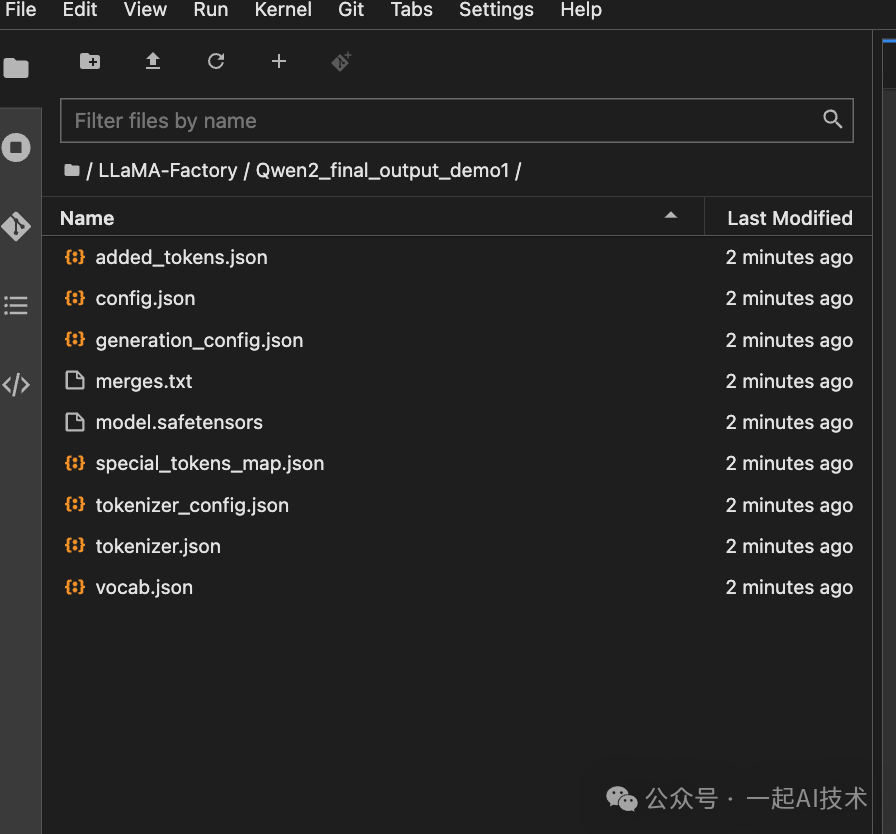
- Export path:设置一个新的路径,例如
Qwen2_final_output_demo1
- Export path:设置一个新的路径,例如
-
- 点击
Export按钮
- 点击
最终,会在LLaMa Factory中,生成导出的目录文件,该文件即为最终训练的模型。
策略2:直接使用DPO训练
第一步:直接配置DPO训练参数
-
• Finetuning method: 选择
lora -
• Stage: 选择
DPO -
• Dataset: 选择刚才上传
custom_rlhf_train_data.json -
• Output dir:设置一个新的输出目录,例如:
Qwen2_dpo_output_demo1
训练完毕后,会在save下生成一个补丁。
第二步:将Lora补丁与第二阶段训练的模型输出合并导出。(该步骤与上面策略1的方法类似,此处不再赘述)
至此,经过大模型的三个阶段,我们完成了一个医疗大模型的训练。
附录
TeleChat-PTD数据集
如果涉及到从零开始训练大模型的话,预训练数据集可以参考了解 TeleChat-PTD 数据集。
数据集简介:
-
• TeleChat-PTD 是由电信星辰大模型TeleChat预训练语料中抽取出的的综合性大规模中文数据集。
-
• 数据集地址:https://modelscope.cn/datasets/TeleAI/TeleChat-PTD
-
• 数据集规模:2.7亿
-
• 数据集类型:纯中文文本构成
-
• 数据集来源:网页、书籍、官方媒体等
-
• 数据集大小:原始大小约1TB,压缩后480G,共189个文件。
数据集特点:
-
• 该数据集是以
JSON Lines格式(.jsonl)存储的,每一行都是一个独立的 JSON 对象。 -
• 每个
JSON对象包含一个键为"data"的字段:{ "data": "文本内容" }
数据集内容预览:

内容小结
-
• LLaMA-Factory是一个开源的、可自定义的、可扩展的、可部署的、可训练的大模型训练平台。
-
• LLaMA-Factory的训练流程分为3个阶段:预训练、监督微调、偏好纠正。
-
• 训练过程的大致步骤为:
-
• 按照LLaMA-Factory官方README文档的数据格式,准备训练数据;
-
• 按照LlaMA-Factory官方README文档,在的dataset_info.json文件,注册自定义数据;
-
• 根据训练阶段配置训练参数,包括模型名称、模型路径、训练方法、数据集、输出目录等;
-
• 预览训练命名无误后,启动训练。
-
• 如果启动训练失败,可以通过切换到启动
LLaMA Factory的命令行查看日志信息排查问题。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









