






前言
今天分享的是【2024年大模型轻量化技术研究报告】 报告出品方:天津大学

《2024年大模型轻量化技术研究报告》由天津大学发布,对大模型轻量化技术进行了全面研究,核心内容如下:
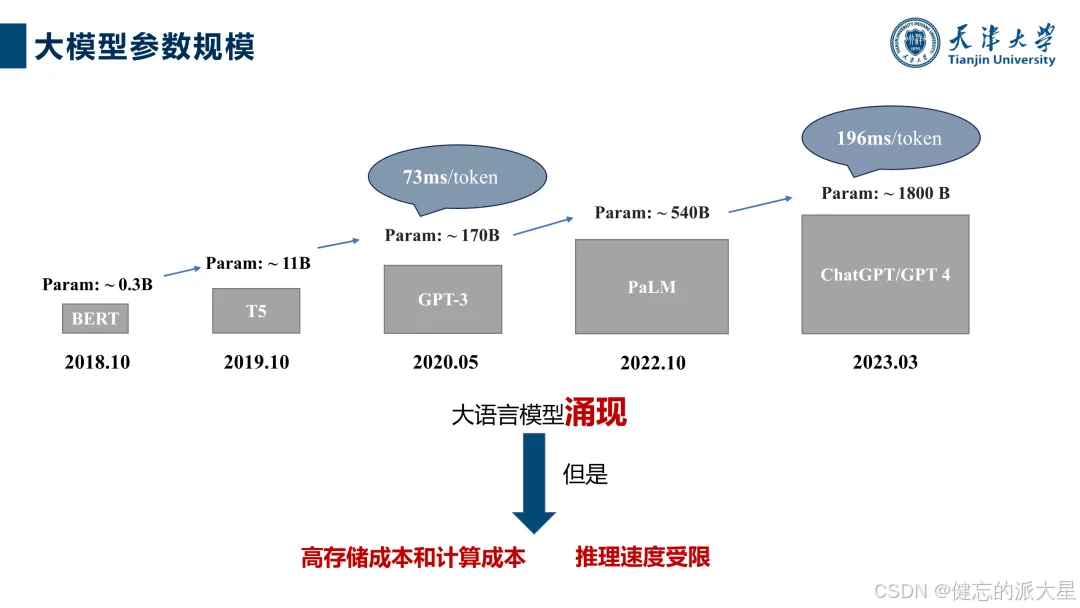
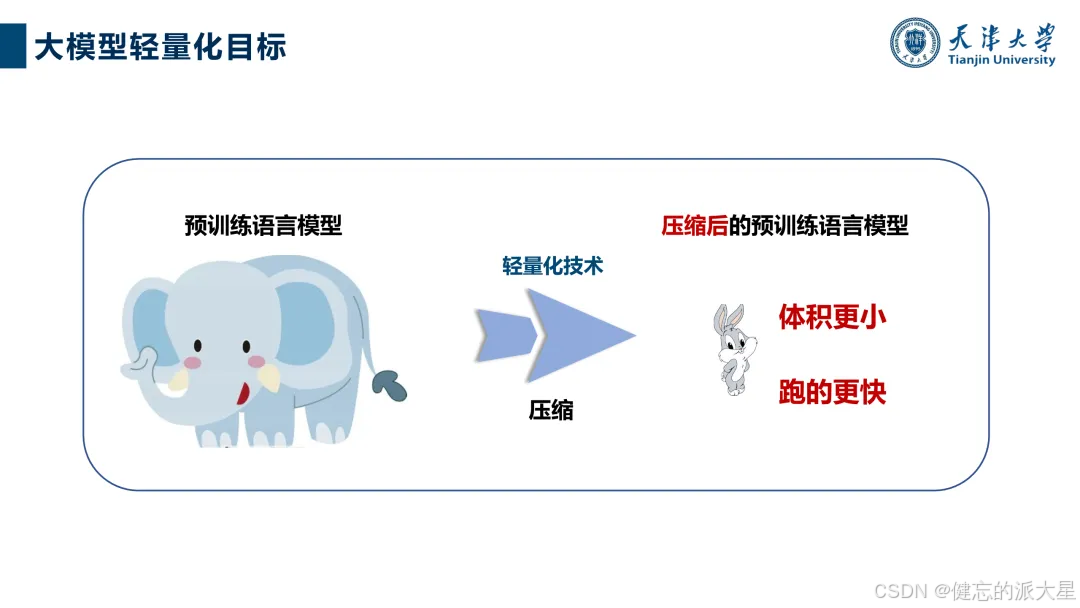
大模型轻量化的背景与需求
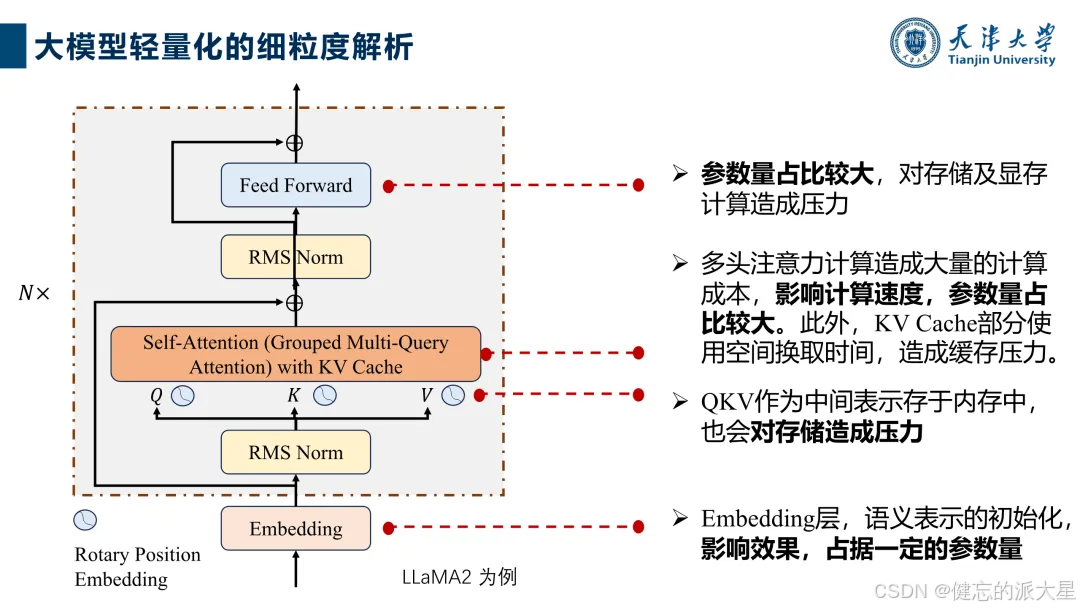
大语言模型发展迅速,但面临算力消耗大、可解释性差等问题。大模型轻量化旨在解决实际应用部署中的难题,实现体积更小、运行更快的目标,对降低成本、提高效率具有重要意义,如在手机端侧、医疗、工业等领域有广泛应用前景。
有需要完整报告的朋友,可以扫描下方二维码免费领取👇👇👇

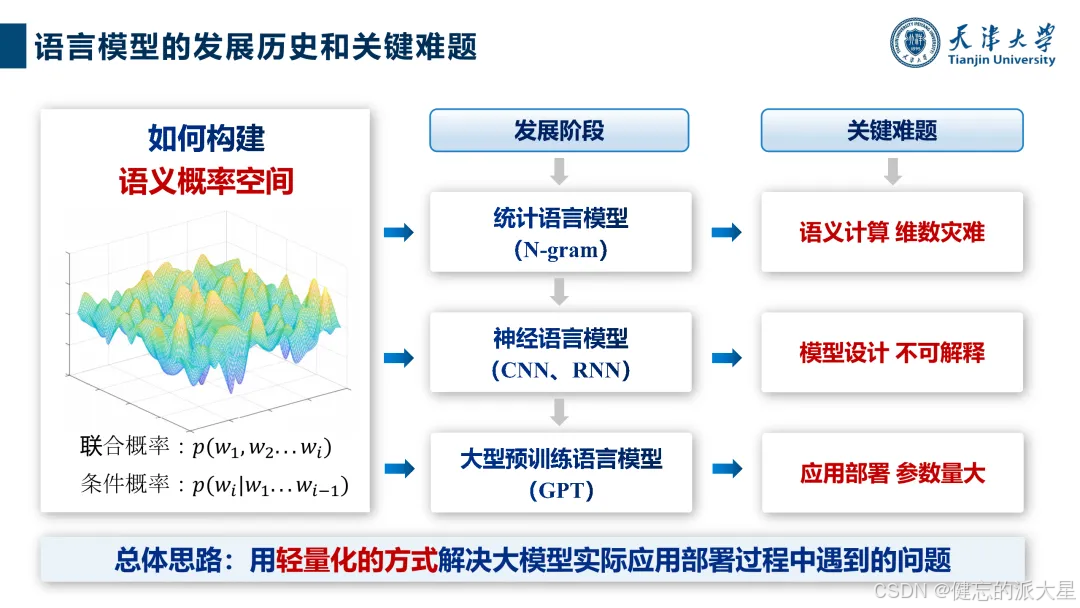
轻量化技术概览与理论
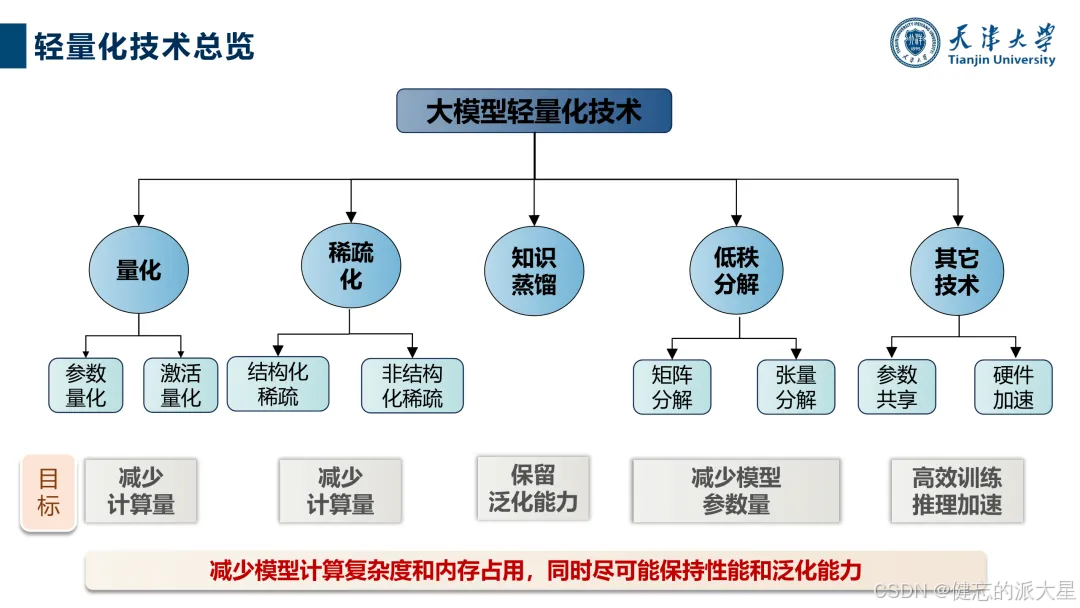
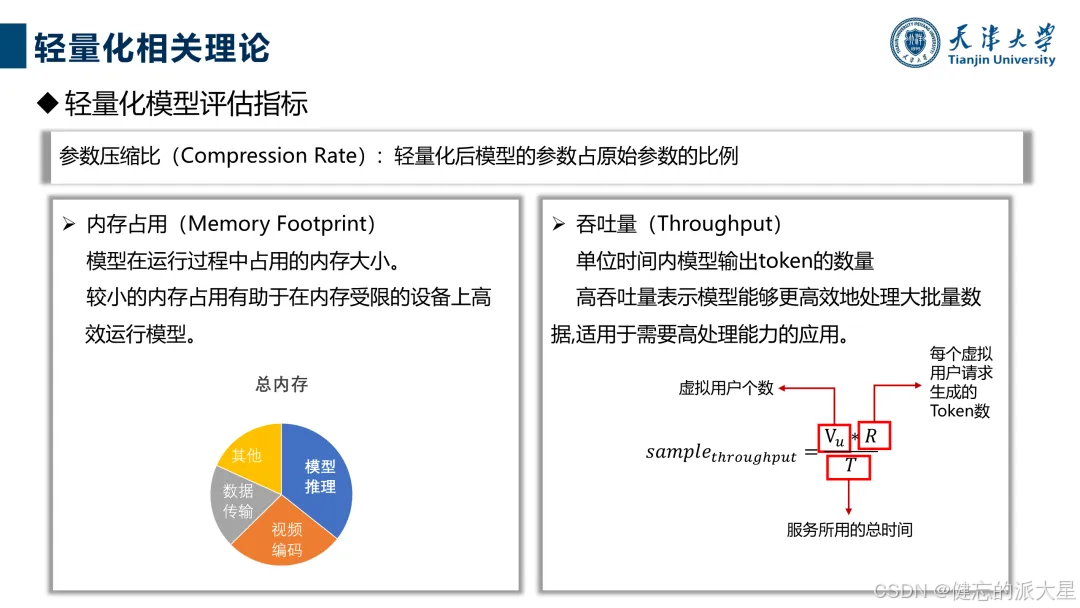
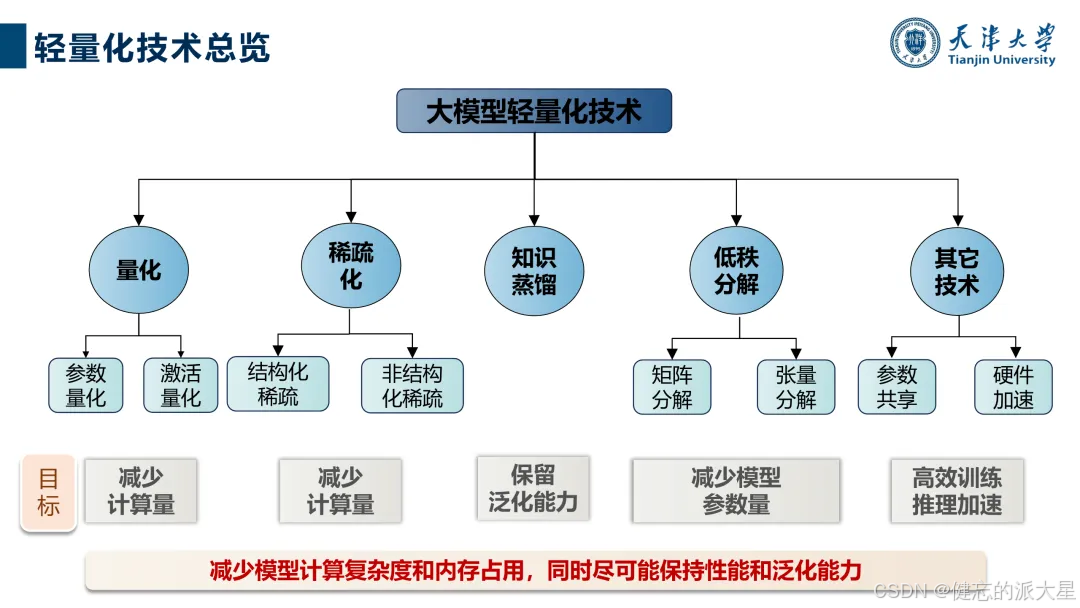
1. 技术分类与目标:包括量化、稀疏化、知识蒸馏、低秩分解、参数共享等技术,旨在减少参数量、计算量,提高推理速度,同时保持或提升模型性能和泛化能力。评估指标涵盖内存占用、参数压缩比、吞吐量、推理速度、延迟、推理效果等。
2. 理论基础:降低参数数量可减少存储和计算需求,轻量化模型能减轻硬件压力,包括显存、带宽和内存等。不同技术在减少计算复杂度、内存占用等方面各有优劣,且可联合使用。
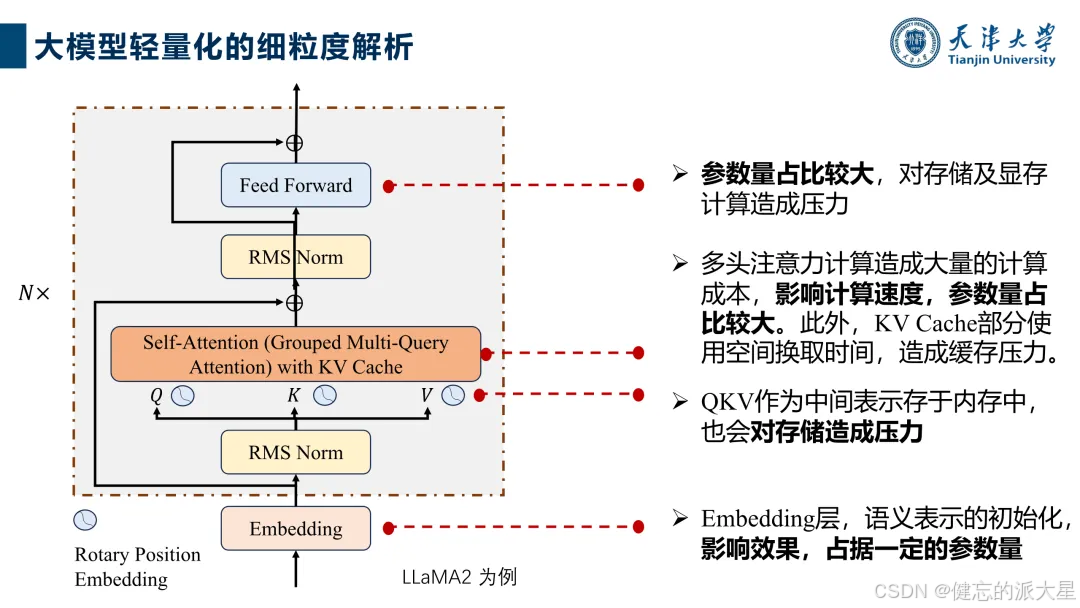
轻量化技术详细讲解
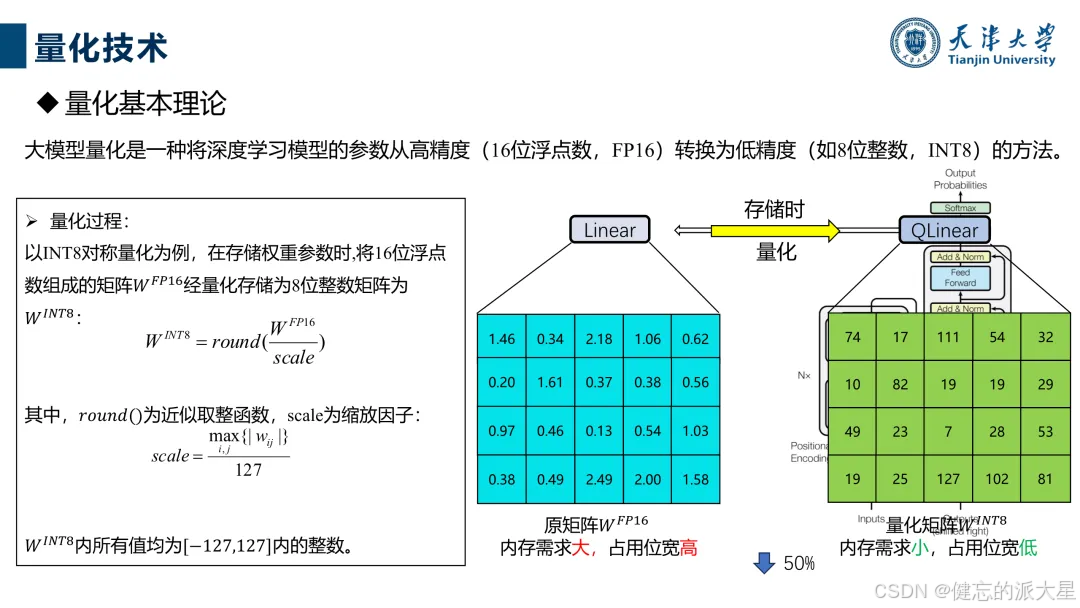
1. 量化技术:将参数从高精度转换为低精度,如LLM.int8()采用混合精度量化解决异常值问题,SmoothQuant使W矩阵“代偿”异常值影响,还有多种通用和端侧量化工具。
2. 稀疏化技术
-
参数稀疏化:分为非结构化和结构化稀疏,非结构化稀疏可减少参数数量,但会影响推理速度,Flash - LLM通过特定存储格式和计算流水线提升效率;结构化稀疏在保持模型准确率方面相对较弱,但能加速计算。
-
知识蒸馏:将知识从大模型转移到小模型,大语言模型的知识蒸馏分为黑盒和白盒蒸馏,MiniLLM方法采用多种策略改进学习,效果优于其他蒸馏方法。
-
低秩分解:通过分解矩阵保留主要信息实现数据压缩,如PCA分解、张量分解技术等,可有效压缩模型参数,平衡推理速度、预测效果和参数规模,如Hypoformer方法结合矩阵分解和TT分解。
-
参数共享:如MQA和GQA通过共享键值矩阵减少计算量和内存占用,推理时间显著缩短,性能基本不变。
-
结合硬件特点的技术:Flash Attention减少存取操作次数和分块优化计算,并行解码策略可提升吞吐量。
未来展望
1. 量子计算:量子计算架构上的轻量化技术是新研究路径,量子隐式神经表征具有指数级增长的傅里叶序列拟合能力,在多个任务中展现出优势。
2. 稀疏化技术发展方向:大模型稀疏化面临挑战,现有方法存在问题,未来可从与硬件存储特性结合、保持高稀疏率下模型效果、实现端侧存储速度与效果平衡等方面改进,如LLM - Pruner在参数量等指标上有良好效果,早停策略可减少计算量,SparseGPT能在高稀疏率下保持效果,端侧稀疏化技术可减少参数读取时间等。同时期待在Scaling law指导下快速配置推理体系,实现实时在线微调,构建端云高效推理体系。
以下为报告节选内容

有需要完整报告的朋友,可以扫描下方二维码免费领取👇👇👇

















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









