






前言
在AI大模型军备竞赛中,阿里云近期推出的QwQ-32B推理模型引发了行业震动。这款仅320亿参数的稠密模型,在数学推理(AIME24)和代码能力(LiveCodeBench)等核心指标上,竟与6710亿参数的DeepSeek-R1不相伯仲。
QwQ系列的诞生,不仅验证了大规模模型通过强化学习持续精进推理能力的可能性,更揭示了未来AI走向“工具化思考”(Tool-Aware Reasoning)的全新方向。
QwQ的命名源自“Qwen with Questions”,即专注于问题解决的Qwen。它是阿里巴巴基于Qwen开源的基础模型,通过强化学习进一步优化推理能力的“升级版”。阿里在QwQ-32B上复现了“规模越大、强化学习效果越显著”的规律。
QwQ-32B的“地基”直接取自Qwen2.5-Plus,而另一版本的QwQ-Max-Preview则基于更高规格的Qwen2.5-Max。这种设计逻辑透露出重要信息:在Qwen家族中,Plus是广泛适用的“全能型选手”,而Max则是性能与资源的终极平衡。官方宣布未来将完全开源QwQ-Max,very值得期待了。QwQ-32B通过创新性的多阶段强化学习实现突破:
- 数学/编程专项训练:摒弃传统奖励模型,直接通过答案验证和代码测试提供反馈,确保模型严谨性
- 通用能力增强:在保持专项能力前提下,引入通用奖励模型扩展应用场景
- 智能体融合:集成动态调整能力,在使用工具时可进行自我验证及策略优化
相比需要500GB显存的DeepSeek-R1部署方案,QwQ-32B的本地化成本降低超95%。实测显示,单张RTX 4090即可承载其Q4量化版本,推理速度达20+ tokens/秒。这种性能与成本的完美平衡,使其在数据敏感场景(如金融风控、医疗诊断)具备独特优势
另外需要夸夸的就是开发者友好生态构建,模型采用Apache 2.0协议开源,支持:
- 多精度量化:从2bit到8bit满足不同硬件需求
- 全栈工具链:集成vLLM加速框架、Ollama一键部署
- 函数调用API:通过标准OpenAI接口实现工具扩展
这场由「小模型+大RL」引发的技术革命,或许正在重写AGI的实现路径!
回归落地,我们要如何让QwQ-32B真正为我们所用?文章接下来将具体演示如何结合vLLM推理框架和SgLang工具包,将QwQ-32B通过OpenAI的API接入,并实现函数/工具的灵活调用。
正式实战前,还是先来了解一下QwQ-32B!
QwQ-32B
QwQ-32B开源链接:
- 魔搭开源链接:https://modelscope.cn/models/Qwen/QwQ-32B
- huggingface开源链接:https://huggingface.co/Qwen/QwQ-32B
在线体验地址:
- https://chat.qwen.ai/?models=Qwen2.5-Plus
据官方博客介绍,在初始阶段QwQ-32B团队采取了“最小阻力法”:优先聚焦数学和编程任务。这两个领域有个特殊优势——答案的对错能迅速验证:数学题有明确答案,代码运行成功与否能直接反馈。正是这种可量化、可快速验证的特性,让模型得以通过“试错学习”的路径高效迭代——模型给出答案,系统直接校验对错,再通过强化学习调整策略。
当基础能力站稳脚跟后,团队转而引入两个“裁判”——奖励模型和规则验证器:前者负责评估回答的“合理性”(比如逻辑连贯性、常识符合度),后者则像代码里的条件判断语句,确保答案不违反基本规则(例如单位换算是否正确)。这种分层设计的妙处在于让模型在巩固专项优势的同时,逐步扩展文字理解、多步骤推理等通用能力,避免“全面开花”导致的基础能力退化。
为何选择数学与编程作为突破口?EpochAI团队最近提出的推理模型发展理论,为这种选择提供了关键支撑:他们指出,推理模型最可能率先突破的场景,需满足两个条件——领域内有充足高质量训练数据,且解决方案能通过低成本程序化方式验证。数学和编程恰好是典型代表:数学涵盖人类数千年的知识积累,编程则拥有海量代码案例和执行验证机制。甚至让人联想到人工智能史上另一座里程碑——DeepMind开发AlphaGo前,正是通过复用围棋的确定性规则和海量棋谱进行训练。
官方文档显示在数学推理和编程能力上,QwQ-32B的测试得分已与DeepSeek的“满血版”R1模型平起平坐;面对参数量更小的R1蒸馏模型(如针对Qwen和Llama的版本),优势更为明显。这意味着原本使用R1蒸馏模型的开发者,可以无缝切换到QwQ-32B并获得同等甚至更好的推理效果。
不过,与OpenAI的推理模型o1 mini相比,QwQ-32B的性能暂时处于“并驾齐驱”而非“超越”状态。值得注意的是,o1 mini发布于去年9月——这个时间差异暗示着:尽管QwQ-32B展现了扎实的训练逻辑,但推理赛道的竞争早已踏入“毫厘必争”的深水区。
资源效率突破
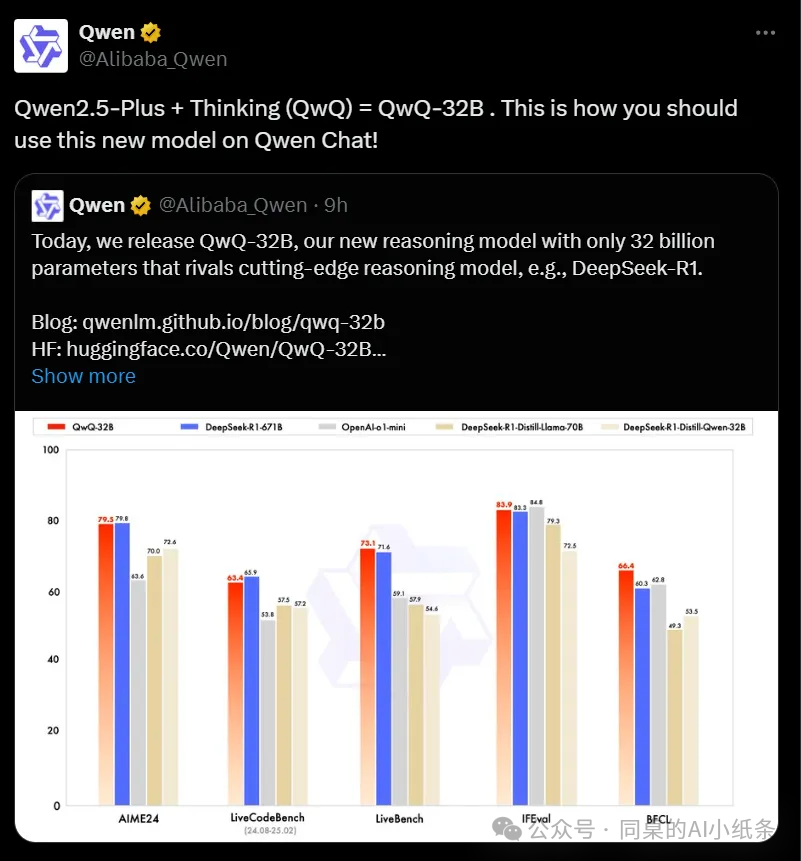
根据阿里巴巴官方自己的基准测试数据,QwQ-32B 在多项核心能力指标上均展现领先优势:
| 能力维度 | 评测基准 | QwQ-32B | DeepSeek-R1 | 性能优势 |
|---|---|---|---|---|
| 数学推理 | AIME24 | 79.74 | 79.13 | +0.61 |
| 代码生成 | LiveCodeBench | 73.54 | 72.91 | +0.63 |
| 综合推理 | LiveBench | 82.1 | 81.3 | +0.8 |
| 指令跟随 | IFEval | 85.6 | 84.9 | +0.7 |
| 安全合规 | BFCI | 92.4 | 91.8 | +0.6 |
尽管DeepSeek-R1单次推理激活37B,但要完整部署总规模671B的模型,且保证其经济性,需要至少22台服务器,每台8张GPU,超过1500GB显存(16张Nvidia A100 GPU)。这不是普通个人开发者能够承担的。跨服务器的流水线并行与专家并行机制,Prefill(预填充)与Decoding(解码)分离的特点,以及依赖特定的Expert Parallel 通信库,也推高了个人部署的技术门槛。
反观QwQ-32B,它将显存消耗压缩到了惊人的24GB的 vRAM(FP16精度下),仅需单块NVIDIA H100即可运行。如果技术实力不够硬核,甚至能退而求其次:
- 消费级显卡方案:4块RTX 4090即可启动(显存总需求60GB);
- 极致轻量化:量化到Q4精度后,显存需求进一步降到20GB,连苹果M3 Ultra笔记本都能流畅运行;
- 成本对比:以同等量化精度的DeepSeek-R1为例,其显存需求高达QwQ的20倍(QwQ-20GB vs R1-400GB)。

QwQ-32B 采用的架构优化
QwQ-32B基于因果语言模型(causal language model)架构,并进行了多项优化:
-
64层Transformer结构融合了多项关键技术:
-
- RoPE(旋转位置编码):解决长文本理解的“记忆错位”问题;
- SwiGLU激活函数:提升计算效率却不增加参数量;
- RMSNorm与QKV偏置:让模型在推理时更稳定、精准。
-
GQA(通用查询注意力):40个查询注意力头与8个键-值对头的组合,实现了「高精度检索与高效存储」的平衡,如同给模型装配了「分屏浏览器」,能同时处理多任务又不互相干扰。
-
超长文本支持:131072 token的上下文窗口(约相当于50页中文文档),让处理复杂多轮对话、长篇逻辑推导成为可能。
-
多阶段训练流程:包括预训练、监督微调(SFT)和强化学习(RL)。
强化学习(RL)训练策略
QwQ-32B的强化学习训练分为两个阶段:
- 第一阶段:数学编程的“严父模式”
模型先接受硬核打磨:通过数学验证器和代码执行器实时检查答案是否正确——如果解方程时算错结果,就像学生作业没过关;写代码有bug,系统直接报错。只有通过测试的回答,才能被强化学习所采纳。这一阶段奠定了模型的“基础学科实力”。 - 第二阶段:通识能力的“民主化提升”
游戏规则升级:引入通用奖励模型(衡量逻辑连贯性)和规则验证器(确保常识不翻车)。此时训练目标不仅是“正确”,还要“友好”——比如回答问题时先分析步骤是否合理,再判断是否符合人类直观。这种“宽进严出”的设计,让QwQ-32B在保持专精能力的同时,获得更广泛任务的适应性。
Tools Call支持与Agentic能力
QwQ-32B的特殊能力,藏在它的「代理系统友好基因」中:
- 函数工具调用(Tools Call):支持像人类专家协作一样,让模型在推理时调用计算器、数据库或编程解释器等外部工具,我们在下面的实战部分-模型调用会有详细的讲解!
- 动态反馈调整(Agentic能力):它能根据环境反馈「自主修正路径」。如果用户指出“第二步推导有问题”,模型能像经验丰富的顾问一样重新审视整个逻辑链,而不是机械重复错误。
最大化QwQ-32B表现的推荐参数
- 温度(Temperature):0.6
- TopP(核采样):0.95
- TopK(最高概率截取):20-40
- YaRN Scaling(用于长序列处理):适用于超过 32768 tokens 的输入
部署小贴士:该模型推荐使用vLLM(高吞吐量推理框架)进行部署。但需要注意,当前版本的静态YaRN扩展机制意味着输入长度的倍增会导致推理时间线性增长。对于超长文本任务,切记预留足够资源。
补课(可选阅读):vLLM和SGLang是什么
vLLM和SGLang是两个专注于提升大语言模型(LLM)推理效率的开源框架,但在设计目标、技术特性和适用场景上存在各自的发挥领域:
-
选择vLLM
若需快速部署高并发服务,或资源有限但追求吞吐量(如中小团队部署百亿参数模型)。
-
选择SGLang
若涉及复杂逻辑(如工具调用、数据库交互)或需严格结构化输出(如智能客服的JSON响应)。
两者技术互补,部分场景可结合使用(如SGLang调用vLLM的底层优化)。具体选择需综合硬件资源、任务复杂度及开发能力。我们来一个个看:
vLLM(Vectorized Large Language Model)
vLLM是由加州大学伯克利分校团队开发的高性能推理引擎,专注于优化内存管理和吞吐量,尤其适合高并发场景。其核心技术包括:
-
PagedAttention
借鉴操作系统分页机制,将注意力机制的键值缓存(KV Cache)分块管理,显存利用率提升3-4倍,支持更长上下文和更高并发。
-
连续批处理(Continuous Batching)
动态调整批处理大小,允许新请求随时加入处理批次,吞吐量相比传统框架提升高达24倍。
-
多量化支持
兼容GPTQ、AWQ等量化技术,降低显存占用,适合资源受限的在线服务。
适用场景:适合单轮高吞吐任务,如实时聊天机器人、批量内容生成和推荐系统,尤其在需要最大化GPU利用率的场景中表现突出。
SGLang(Structured Generation Language)
SGLang同样由伯克利团队开发,但更注重复杂任务的支持和交互灵活性。其创新技术包括:
-
RadixAttention
通过基数树管理KV缓存,在多轮对话中共享前缀缓存,缓存命中率提升3-5倍,延迟降低30%-50%。
-
结构化输出支持
通过正则表达式和有限状态机实现约束解码,直接生成JSON等结构化数据,速度比其他方案快10倍。
-
编译器式设计
前端提供领域特定语言(DSL),简化复杂任务编程;后端优化调度和资源分配,支持多节点分布式部署。
适用场景:专为多轮交互和结构化输出设计,例如智能客服(需多轮对话)、数据分析(生成JSON/XML格式结果)以及需要自定义生成逻辑的场景。
关键对比
| 维度 | vLLM | SGLang |
|---|---|---|
| 核心技术 | PagedAttention、动态批处理 | RadixAttention、结构化解码 |
| 吞吐量优势 | 单轮任务(如内容生成) | 多轮任务(如对话系统) |
| 内存管理 | 显存浪费率<4% | 缓存复用率更高 |
| 部署复杂度 | 需手动调参,依赖NVIDIA GPU | 支持多厂商GPU,自动化程度高 |
| 典型场景 | 实时问答、推荐系统 | API接口生成、多模态交互 |
实战!部署QwQ-32B,结合OpenAI调用Tools工具能力
Tools是OpenAI的Chat Completion API中的一个可选参数,可用于提供函数调用规范(function specifications)。这样做的目的是使模型能够生成符合所提供的规范的函数参数格式。同时,API 实际上不会执行任何函数调用。开发人员需要使用模型输出来执行函数调用。(用例参考OpenAI cookbook:https://cookbook.openai.com/examples/howtocallfunctionswithchatmodels)
vLLM和SgLang均支持OpenAI-API的tool参数。通过tool参数以及其中的函数调用规范,QwQ将能决定何时调用什么样的函数,以及怎么调用函数。
接下来的实战内容主要包含以下两个个部分:
- 模型部署:使用vLLM,SgLang和QwQ,通过设置参数,部署支持Function call的聊天API接口。
- 生成函数参数:指定一组函数并使用 API 生成函数参数。
模型部署
模型文件下载
modelscope download --model=Qwen/QwQ-32B --local_dir ./QwQ-32B
环境安装
pip install vllm
pip install "sglang[all]>=0.4.3.post2"
vLLM部署命令
vllm serve /ModelPath/QwQ-32B \
--port 8000 \
--reasoning-parser deepseek_r1 \
--max_model_len 4096 \
--enable-auto-tool-choice \
--tool-call-parser hermes
sglang部署命令
python -m sglang.launch_server --model-path /ModelPath/QwQ-32B --port 3001 --host 0.0.0.0 --tool-call-parser qwen25python -m sglang.launch_server --model-path /ModelPath/QwQ-32B --port 3001 --host 0.0.0.0 --tool-call-parser qwen25
模型调用
在实战之前先要说下OpenAI的functioncalls和toolcalls!避免有小伙伴和我一样开始总是弄混淆!
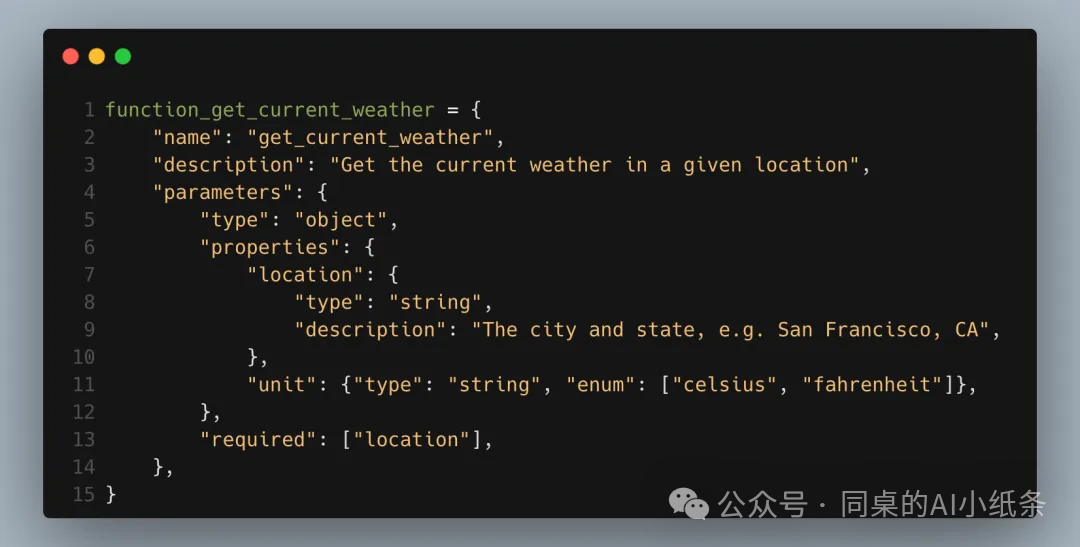
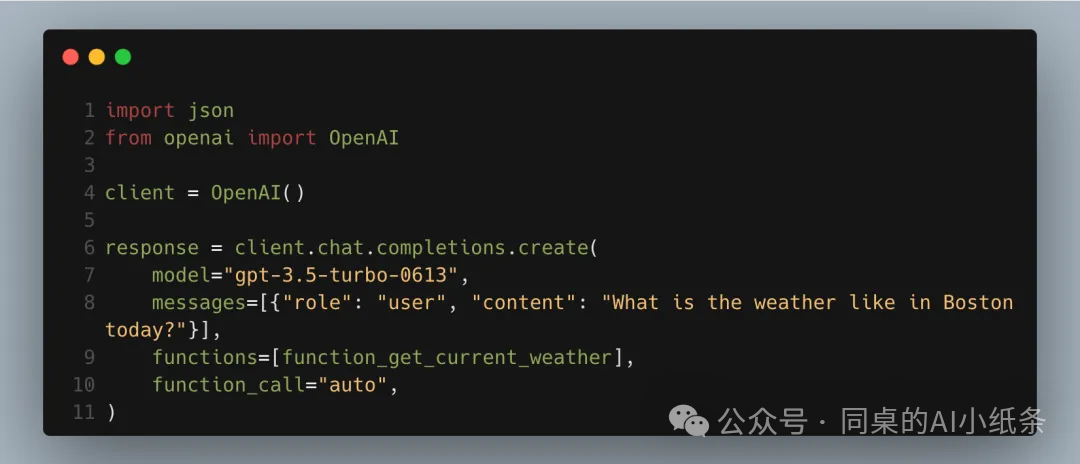
最初,OpenAI使用 function_calls ,这种方法允许开发者为AI定义特定任务。任务以JSON格式结构化,详细描述了函数名称、参数及其他相关信息,调用方式如下
通过 function_calls ,开发者可以直接与AI交互以执行函数,但这种方法在处理并行function calls时有一定限制。例如,在一个聊天完成请求中,同时查询多个股票价格是不可能的,因为一次只能调用一个工具函数。此方法现已在OpenAI的官方网站上标记为弃用。
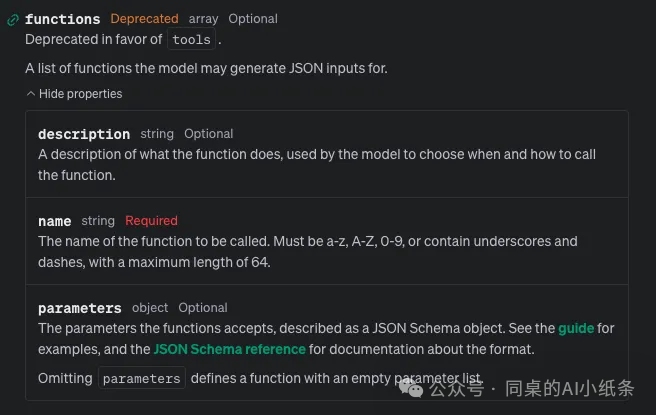
后来OpenAI引入了tool_calls,提供了一个更强大的框架,支持更复杂的接入和交互。此更新显著增强了模型的实用性,允许并行函数调用,并有可能在未来整合更多种类的工具。
Tool Calls的高级功能:
- 并行的Function Calling:此功能允许模型同时执行多个函数调用。例如,模型可以同时查询三个不同地点的天气。每个function call在 tool_calls 数组中独立管理,响应并行处理,减少了往返时间和等待时间。
- 接入灵活性: tool_calls 的结构设计支持多种工具,不仅限于函数。这种设计允许未来的扩展和不同工具类型的接入,增强了模型的适应性和应用范围。
好啦,接下来的实战,我们就来结合OpenAI的tool_calls,以及API格式调用本地部署的QwQ模型
from openai import OpenAI
# 设置 OpenAI 的 API 密钥和 API 基础 URL 使用 vLLM 的 API 服务器。
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
首先,让我们定义一些用于调用聊天完成API并维护和跟踪对话状态的实用程序
@retry(wait=wait_random_exponential(multiplier=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, tools=None, tool_choice=None, model=GPT_MODEL):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice=tool_choice,
)
return response
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
def pretty_print_conversation(messages):
role_to_color = {
"system": "red",
"user": "green",
"assistant": "blue",
"function": "magenta",
}
for message in messages:
if message["role"] == "system":
print(colored(f"system: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "user":
print(colored(f"user: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "assistant" and message.get("function_call"):
print(colored(f"assistant: {message['function_call']}\n", role_to_color[message["role"]]))
elif message["role"] == "assistant" and not message.get("function_call"):
print(colored(f"assistant: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "function":
print(colored(f"function ({message['name']}): {message['content']}\n", role_to_color[message["role"]]))
让我们创建一些功能规格,以与假设的天气API接口。我们将这些功能规范传递给聊天完成API,以生成符合规范的函数参数
通过以下的配置方式告诉模型什么时候来调用工具, tools列表中定义了函数名称name和签名之类的工具的描述,并将其传递给API调用中的模型。如果选择,则函数名称和参数包含在响应中。
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
}
},
{
"type": "function",
"function": {
"name": "get_n_day_weather_forecast",
"description": "Get an N-day weather forecast",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
"num_days": {
"type": "integer",
"description": "The number of days to forecast",
}
},
"required": ["location", "format", "num_days"]
},
}
},
]
如果我们提示模型有关当前天气,它将以一些澄清的问题做出回应
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the weather like today"})
chat_response = chat_completion_request(
model="path/to/QwQ-32B",
messages,
tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message
模型回答:ChatCompletionMessage(content=‘Sure, can you please provide me with the name of your city and state?’, role=‘assistant’, functioncall=None, toolcalls=None**)**
一旦我们提供缺失的信息,它就会为我们生成适当的函数参数。
messages.append({"role": "user", "content": "I'm in Glasgow, Scotland."})
chat_response = chat_completion_request(
model="path/to/QwQ-32B",messages, tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message
模型回答:ChatCompletionMessage(content=None, role=‘assistant’, functioncall=None, toolcalls=[ChatCompletionMessageToolCall(id='callxb7QwwNnx90LkmhtlW0YrgP2’, function=Function(arguments=‘{“location”:“Glasgow, Scotland”,“format”:“celsius”}’, name='getcurrent_weather’), type=‘function’)])
通过不同的提示,我们可以让它执行我们告诉过它的其他功能。
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "what is the weather going to be like in Glasgow, Scotland over the next x days"})
chat_response = chat_completion_request(
model="path/to/QwQ-32B",messages, tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message
**模型回答:Choice(finishreason=‘toolcalls’, index=0, logprobs=None, message=ChatCompletionMessage(content=None, role=‘assistant’, functioncall=None, toolcalls=[ChatCompletionMessageToolCall(id=‘call34PBraFdNN6KR95uD5rHF8Aw’, **function=Function(arguments='{“location”:“Glasgow, Scotland”,“format”:“celsius”,"numdays":5}’, name=‘getndayweatherforecast’), type=‘function’)]))
再次,模型要求我们澄清,因为它还没有足够的信息。在这种情况下,它已经知道预报的位置,但它需要知道预报需要多少天。
messages.append({"role": "user", "content": "5 days"})
chat_response = chat_completion_request(
model="path/to/QwQ-32B", messages, tools=tools
)
chat_response.choices[0]
**模型回答:ChatCompletionMessage(content=None, role=‘assistant’, functioncall=None, toolcalls=[ChatCompletionMessageToolCall(id=‘callFImGxrLowOAOszCaaQqQWmEN’, function=Function(arguments='{“location”:“Toronto, Canada”,“format”:“celsius”,"numdays":7}', name='getndayweatherforecast’), type=‘function’)])
我们可以强迫模型使用特定函数,例如使用functioncall参数,例如getndayweather_forecast。通过这样做,我们强迫模型对如何使用它做出假设
# in this cell we force the model to use get_n_day_weather_forecast
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "Give me a weather report for Toronto, Canada."})
chat_response = chat_completion_request(
model="path/to/QwQ-32B", messages, tools=tools, tool_choice={"type": "function", "function": {"name": "get_n_day_weather_forecast"}}
)
chat_response.choices[0].message
模型回答: ChatCompletionMessage(content=None, role=‘assistant’, functioncall=None, toolcalls=[ChatCompletionMessageToolCall(id=‘callFImGxrLowOAOszCaaQqQWmEN’, **function=Function(arguments='{“location”:“Toronto, Canada”,“format”:“celsius”,"numdays":7}’, name=‘getndayweatherforecast’), type=‘function’)**])
我们还可以强迫模型根本不使用函数。通过这样做,我们防止其产生适当的函数调用
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "Give me the current weather (use Celcius) for Toronto, Canada."})
chat_response = chat_completion_request(
model="path/to/QwQ-32B", messages, tools=tools, tool_choice="none"
)
chat_response.choices[0].message
**模型回答:**ChatCompletionMessage(content=“Sure, I’ll get the current weather for Toronto, Canada in Celsius.”, role=‘assistant’,functioncall=None, toolcalls=None)
并行函数调用,诸如GPT-4O或GPT-3.5-Turbo之类的较新型号可以一回合调用多个功能
messages = []
messages.append({"role": "system", "content": })
messages.append({"role": "user", "content": "what is the weather going to be like in San Francisco and Glasgow over the next 4 days"})
chat_response = chat_completion_request(
model="path/to/QwQ-32B", messages, tools=tools, model=GPT_MODEL
)
assistant_message = chat_response.choices[0].message.tool_calls
assistant_message
模型回答:[ChatCompletionMessageToolCall(id=‘callObhLiJwaHwc3U1KyB4Pdpx8y’, function=Function(arguments='{“location”: “San Francisco, CA”, “format”: “fahrenheit”, "numdays": 4}’, name=‘getndayweatherforecast’), type=‘function’),
ChatCompletionMessageToolCall(id=‘call5YRgeZ0MGBMFKE3hZiLouwg7’, function=Function(arguments='{“location”: “Glasgow, SCT”, “format”: “celsius”, "numdays": 4}’, name=‘getndayweatherforecast’), type=‘function’)]
最后将模型的回复进行合理的拼接:
# Step 2: determine if the response from the model includes a tool call.
tool_calls = response_message.tool_calls
if tool_calls:
# If true the model will return the name of the tool / function to call and the argument(s)
tool_call_id = tool_calls[0].id
tool_function_name = tool_calls[0].function.name
tool_query_string = json.loads(tool_calls[0].function.arguments)['query']
# Step 3: Call the function and retrieve results. Append the results to the messages list.
if tool_function_name == 'ask_database':
results = ask_database(conn, tool_query_string)
messages.append({
"role":"tool",
"tool_call_id":tool_call_id,
"name": tool_function_name,
"content":results
})
# Step 4: Invoke the chat completions API with the function response appended to the messages list
# Note that messages with role 'tool' must be a response to a preceding message with 'tool_calls'
model_response_with_function_call = client.chat.completions.create(
model="gpt-4o",
messages=messages,
) # get a new response from the model where it can see the function response
print(model_response_with_function_call.choices[0].message.content)
else:
print(f"Error: function {tool_function_name} does not exist")
else:
# Model did not identify a function to call, result can be returned to the user
print(response_message.content)
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









