






前言
DeepSeek 这是要搞一波大的了?
一条关于 DeepSeek 新模型的消息在 AI 圈里炸开了锅。
什么?DeepSeek-R2,混合专家模型,5.2 PB 训练数据,1.2 万亿总参数,780 亿动态激活参数,最最炸裂的是,R2 的训练和推理成本比 GPT-4 还要低 97.3%?!
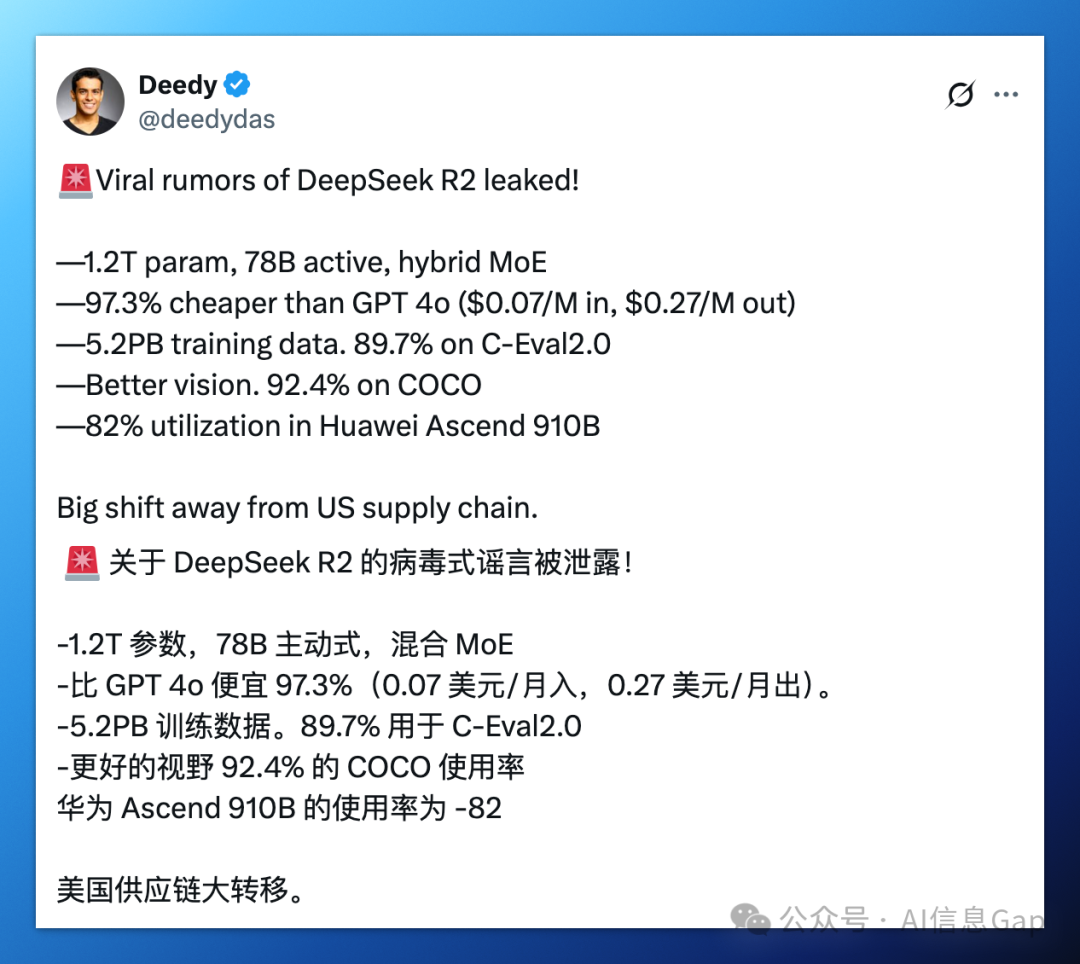
上面这条在 X 平台疯传的帖子,经我调查,源头来自一个叫“韭研公社”的投资平台。

根据“韭研公社”的爆料,DeepSeek-R2 模型采用混合专家 3.0(Hybrid MoE 3.0)架构,总参数规模达到惊人的 1.2 万亿,其中动态激活 780 亿;单位 token 推理成本比起 GPT-4 Turbo 下降 97.3%,硬件适配上实现了昇腾 910B 芯片集群 82% 的高利用率,算力接近 A100 集群。
然而,先别急着开香槟,爆料的真实性仍待 DeepSeek 官方确认。
“热心”的外国网友甚至根据这则爆料制作出了下面这份 DeepSeek-R2 概念股(DeepSeek R2 Concept Stocks)的盘点图。
一个字,绝!

中文翻译版在这里。

此外,无独有偶,Hugging Face(抱抱脸)CEO Clément Delangue 也在几小时前发布了一条耐人寻味的“谜语”帖。
帖子内容仅有三个 👀 小表情,以及 DeepSeek 在 Hugging Face 的仓库链接(按照惯例,DeepSeek 的开源模型会第一时间发布在 Hugging Face 仓库)。
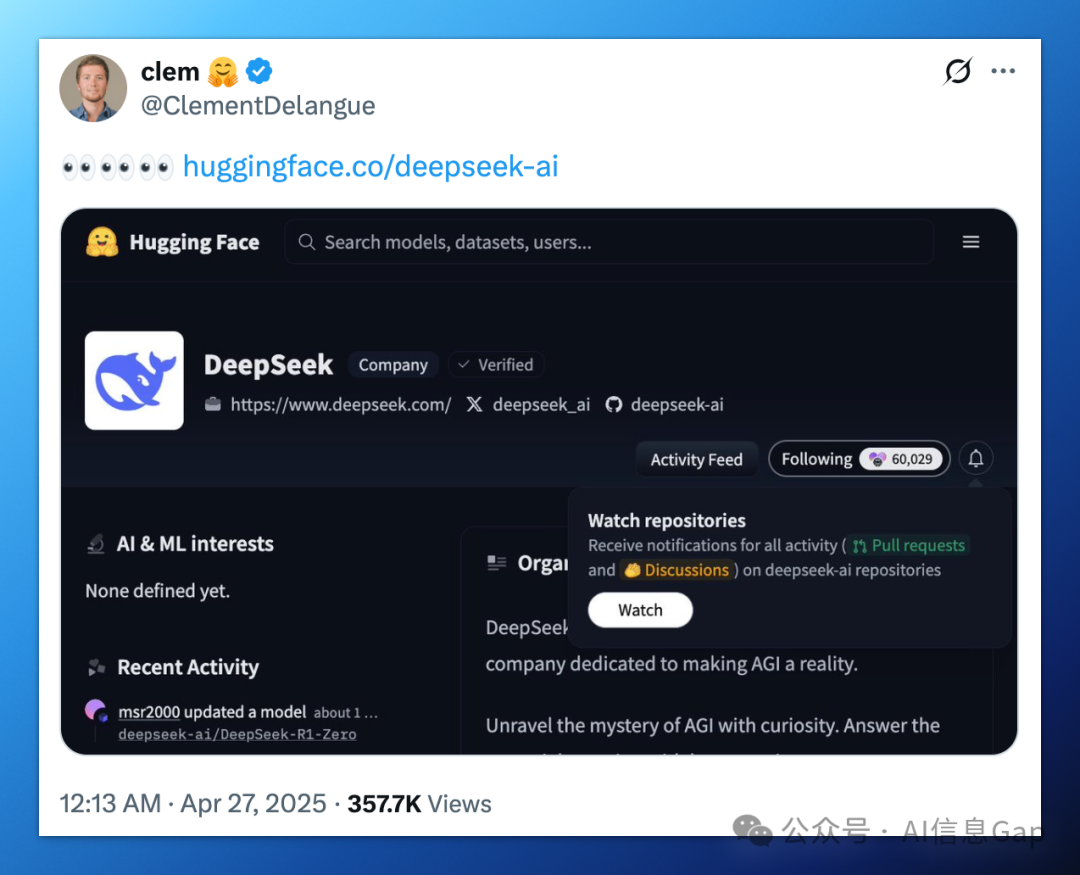
该说不说,留给 DeepSeek 的时间不多了。
距离轰动全球的 DeepSeek-R1 模型发布已经过去了 3 个月。
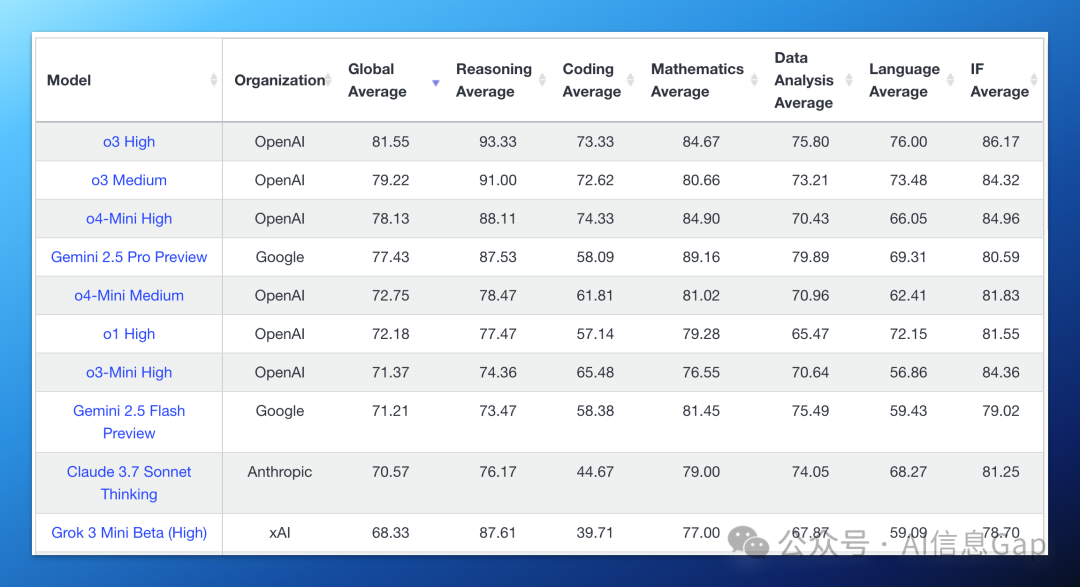
在这期间,有太多比 R1 强的新模型涌现:北美“御三家”有近期刚发布的 o3 + o4-mini、曾一度霸榜且免费的 Gemini 2.5 Pro、代码之王 Claude 3.7 Sonnet,以及背靠大金主马斯克的 Grok 3。
大模型排行榜的前几位已经看不到 DeepSeek 的身影。
结语
坦白说,这条坊间的传言有几分真几分假,没人知道。
但即使只有一半的数据是真的,也足以引起轰动了。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









