






在模型设计中,我们不仅需理解Transformer的基本原理,还要了解不同变种的优劣及其适用场景。任务需求和数据特点会影响架构选择:处理长序列文本时,可能倾向于高效内存管理的变种;实时性要求高的任务,则需要计算速度更快整理的初衷
在现代自然语言处理(NLP)和机器学习领域,Transformer架构已成为模型设计和大规模语言模型(LLM)微调的关键工具。自其问世以来,Transformer迅速主导了机器翻译、文本生成、分类和问答系统等各类NLP任务。然而,面对各种变种和改进,如何为特定任务选择合适的Transformer架构成为许多研究人员和工程师的困扰。
在模型设计中,我们不仅需理解Transformer的基本原理,还要了解不同变种的优劣及其适用场景。 任务需求和数据特点会影响架构选择:处理长序列文本时,可能倾向于高效内存管理的变种;实时性要求高的任务,则需要计算速度更快的版本。
为了帮助大家更好地选择合适的Transformer架构,我们有必要回顾其发展历程。从最初的原始Transformer到BERT、GPT、RoBERTa、T5等改进版本,每个变种都解决了特定问题,并在特定场景下表现突出。通过回顾这些架构的演进,我们能更好地理解它们的优势和适用场景,从而在实际项目中做出更明智的选择。
在本篇技术博客中,我们将深入探讨Transformer架构的演进历程,解析各个变种的核心思想和适用场景,帮助大家在复杂任务中高效地选择最合适的Transformer模型。希望本文能为大家在模型设计和LLM微调中提供有价值的参考。
重温下Transformer的架构图
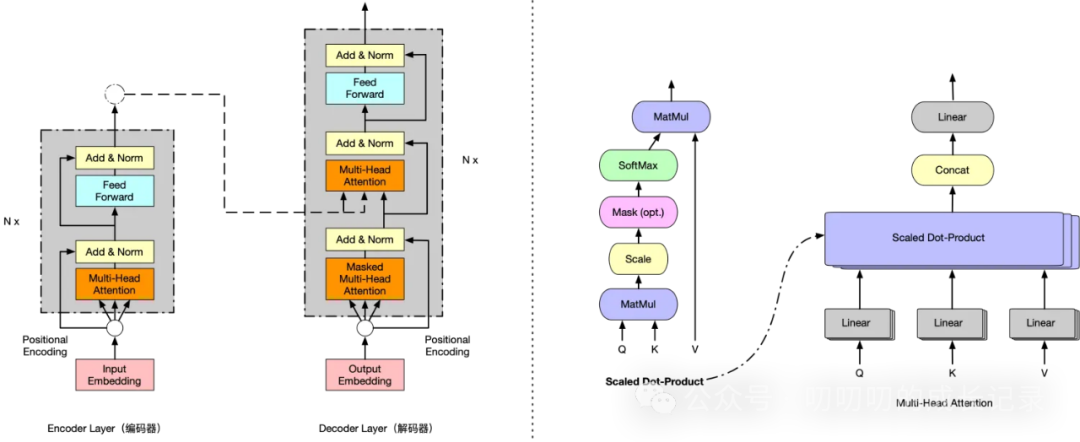
Transformer 模型自从2017年提出以来,迅速成为自然语言处理(NLP)领域的主流模型,凭借其强大的性能和灵活的结构,推动了多个领域的进步。我们一起来回顾下Transformer的发展历史及其关键论文:
- Transformer的提出(2017):
-
关键论文:Vaswani, A., et al., “Attention is All You Need,” 2017.
-
贡献:Transformer模型首次提出,完全基于注意力机制(Attention Mechanism),摒弃了传统的循环神经网络(RNN)结构。Transformer模型的核心创新在于自注意力机制(Self-Attention),能够更好地捕捉长距离的依赖关系。
- BERT的诞生(2018):
-
关键论文:Devlin, J., et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” 2018.
-
贡献:BERT(Bidirectional Encoder Representations from Transformers)模型通过双向训练来理解上下文,并在多个NLP任务上取得了显著的性能提升。BERT的预训练-微调(Pre-training and Fine-tuning)范式成为了后续大多数NLP模型的标准流程。
- GPT 系列的发展(2018-2020):
-
Radford, A., et al., “Improving Language Understanding by Generative Pre-Training,” 2018.(GPT-1)
-
Radford, A., et al., “Language Models are Unsupervised Multitask Learners,” 2019.(GPT-2)
-
Brown, T., et al., “Language Models are Few-Shot Learners,” 2020.(GPT-3)
-
关键论文:
-
贡献:OpenAI推出的GPT系列模型,从GPT-1到GPT-3,展示了生成式预训练模型在文本生成和理解任务上的强大能力,尤其是GPT-3,凭借其1750亿参数,展现了少样本学习(Few-shot Learning)的惊人能力。
- Transformer在图像处理上的应用(2020):
-
关键论文:Dosovitskiy, A., et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” 2020.
-
贡献:Vision Transformer (ViT) 模型首次将Transformer架构引入计算机视觉领域,通过将图像分割成固定大小的块(类似于单词的处理方式),并使用自注意力机制来进行图像分类任务,取得了与传统卷积神经网络(CNN)相媲美的性能。
- 多模态Transformer的提出(2021):
-
关键论文:Radford, A., et al., “Learning Transferable Visual Models From Natural Language Supervision,” 2021.
-
贡献:CLIP(Contrastive Language–Image Pretraining)模型能够通过自然语言监督进行视觉模型的训练,将文本和图像的表示空间对齐,增强了多模态任务的处理能力。
- 高效Transformer的研究(2020-2021):
-
Tay, Y., et al., “Efficient Transformers: A Survey,” 2020.
-
Kitaev, N., et al., “Reformer: The Efficient Transformer,” 2020.
-
关键论文:
-
贡献:针对Transformer的计算和内存效率问题,提出了多种变体和优化方法,如Reformer、Linformer、Performer等,显著降低了计算复杂度和内存占用。
- 最新Transformer模型(2022及以后):
-
关键论文:Chowdhery, A., et al., “PaLM: Scaling Language Modeling with Pathways,” 2022.
-
贡献:PaLM(Pathways Language Model)是Google提出的大规模语言模型,通过更高效的架构和训练策略,进一步提升了Transformer模型在语言理解和生成任务上的性能。
Transformer模型的发展史展示了其在NLP、计算机视觉和多模态任务中的广泛应用和持续创新。通过不断的改进和优化,Transformer模型将继续推动人工智能领域的前沿研究。
几个关键的演进
在 Transformer 模型中,Attention 机制是一个关键的组成部分,极大地提升了模型在自然语言处理任务中的表现。
1. 自注意力机制(Self-Attention)
介绍
Transformer 模型最初引入了自注意力机制,这是一种能够在编码器和解码器中捕捉序列内部依赖关系的方法。在自注意力机制中,每个输入序列元素都会与其他元素进行交互,并根据其重要性进行加权求和,从而生成新的表示。
原因和思考
传统 RNN 和 LSTM 模型在处理长依赖关系时表现不佳,因为它们需要逐步地处理序列,容易导致梯度消失或爆炸问题。自注意力机制能够并行化处理序列中的所有元素,且可以直接建模任意长度的依赖关系,从而解决了 RNN 的一些局限性。
2. 多头自注意力(Multi-Head Self-Attention)
介绍
多头自注意力是一种改进,它通过引入多个并行的注意力头(Attention Heads)来捕捉不同的特征子空间。每个注意力头都独立地计算注意力权重,并将结果进行拼接和线性变换。
原因和思考
单一的自注意力机制可能无法充分捕捉到序列中的多种不同依赖关系。多头自注意力允许模型在不同的子空间中关注不同的信息,从而增强模型的表达能力和鲁棒性。
3. 位置编码(Positional Encoding)
介绍
由于 Transformer 模型没有像 RNN 那样的顺序处理能力,需要引入位置编码来提供序列中的位置信息。这些编码被加到输入的嵌入向量中,允许模型识别输入中的顺序信息。
原因和思考
自注意力机制本质上是无序的,即它并不考虑输入序列的顺序。为了让模型理解序列的顺序信息,必须显式地添加这些位置信息。位置编码解决了这一问题,使得 Transformer 可以处理和理解顺序依赖。
关于位置编码,我建议大家可以去看下苏剑林大佬的文章。我之前也整理过,感兴趣的可以自行查看。
4. 缩放点积注意力(Scaled Dot-Product Attention)
介绍
缩放点积注意力通过计算输入的点积来衡量不同元素之间的相似性,并根据这些相似性进行加权求和。为了避免点积值过大导致梯度消失,加入了缩放因子。
原因和思考
点积注意力是计算效率较高且易于理解的一种注意力机制。然而,在高维向量的点积计算中,可能会导致数值问题。引入缩放因子可以稳定梯度,防止数值不稳定,从而提高计算的稳定性和模型的训练效果。
5. 层归一化(Layer Normalization)
介绍
层归一化在每个注意力子层和前馈神经网络子层之后进行,以对输入进行归一化处理,减少训练中的内部协变量偏移。
原因和思考
层归一化帮助模型更快地收敛,提高了训练的稳定性和效率。通过标准化每一层的输入,使得模型可以在更稳定的环境中学习特征,提高了模型的泛化能力。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

6. 注意力掩码(Attention Masking)
介绍
在解码器中,为了保证自回归性质,需要引入注意力掩码,遮蔽未来词的注意力权重,只允许模型关注已经生成的词。
原因和思考
解码器的自回归性质要求在生成时仅依赖于已经生成的部分,而不应考虑未来的信息。注意力掩码确保了这一点,从而使得模型在解码过程中保持正确的信息流。
通过这些技术的逐步演进,Attention机制在Transformer模型中的表现得到了显著提升,使其成为自然语言处理任务中的一个强大工具。每一个改进都是为了克服之前方法的不足,进一步增强模型的表现和稳定性。
关于掩码这部分,值得单独的开一个文章去写。这里先挖个坑,后续去填充啦。

接下来,我们针对基础的Multi-Head Attention、Multi-Query Attention、Grouped-Query Attention进行展开说明。
多头注意力(MHA)
多头注意力机制(Multi-Head Attention)是Transformer模型中的核心组件之一。它通过并行多个注意力头来捕捉不同的特征和关系,从而增强模型的表达能力。每个注意力头都有自己的查询(Query)、键(Key)和值(Value)矩阵,并分别计算注意力,然后将各个头的输出拼接并通过线性变换得到最终的输出。
机制详解
1. 输入线性变换
首先,对输入进行线性变换以得到查询(Q)、键(K)和值(V):
其中,( ),( ),( ) 是可学习的权重矩阵。
2. 计算注意力
对每个头,计算注意力:
其中,() 是键的维度。
3. 多头拼接
将所有头的输出拼接起来:
4. 输出线性变换
最后,再通过一个线性变换得到最终输出:
代码示例
以下是一个简化的 PyTorch 实现:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
self.q_linear = nn.Linear(embed_dim, embed_dim)
self.k_linear = nn.Linear(embed_dim, embed_dim)
self.v_linear = nn.Linear(embed_dim, embed_dim)
self.fc_out = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
N, seq_length, embed_dim = x.shape
# Linear projections
Q = self.q_linear(x)
K = self.k_linear(x)
V = self.v_linear(x)
# Split into num_heads
Q = Q.view(N, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(N, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(N, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
# Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-1, -2)) / (self.head_dim ** 0.5)
attention = torch.softmax(scores, dim=-1)
out = torch.matmul(attention, V)
# Concatenate heads
out = out.transpose(1, 2).contiguous().view(N, seq_length, embed_dim)
# Final linear layer
out = self.fc_out(out)
return out
# Example usage
embed_dim = 128
num_heads = 8
batch_size = 32
seq_length = 10
x = torch.randn(batch_size, seq_length, embed_dim)
mha = MultiHeadAttention(embed_dim, num_heads)
output = mha(x)
print(output.shape) # torch.Size([32, 10, 128])```
代码解释
- 初始化:
-
embed_dim是输入和输出的嵌入维度。 -
num_heads是注意力头的数量。 -
head_dim是每个头的维度,它是embed_dim除以num_heads。
- 线性变换:
-
q_linear、k_linear和v_linear分别生成查询、键和值。 -
fc_out是最后的线性层。
- 前向传播:
-
首先对
x进行线性变换得到查询、键和值,并将其拆分成多个头。 -
然后进行缩放点积注意力计算。
-
最后将各个头的输出拼接并通过线性层得到最终输出。
这个实现是多头注意力机制的基础版本,实际使用中还可能涉及到掩码(masking)等其他操作。
多Query注意力(MQA)
Multi-Query Attention (MQA) 是一种改进的注意力机制,旨在提升计算效率并减少内存需求。 与标准的多头自注意力机制(Multi-Head Self-Attention, MHSA)不同,MQA 通过共享所有注意力头的 Keys 和 Values 进行计算,仅为每个查询计算独立的注意力权重。这样做不仅可以减少计算复杂度,还可以降低内存占用。
机制解释
-
将输入序列映射到查询(Query)、键(Key)和值(Value)。
-
共享所有注意力头的键和值。
-
为每个查询计算独立的注意力权重,然后应用这些权重到共享的值上,得到输出。
代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiQueryAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiQueryAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "Embedding dimension must be divisible by number of heads"
# Linear layers to generate queries, keys, and values
self.q_linear = nn.Linear(embed_dim, embed_dim)
self.k_linear = nn.Linear(embed_dim, self.head_dim) # Shared keys
self.v_linear = nn.Linear(embed_dim, self.head_dim) # Shared values
self.out_linear = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_len, embed_dim = x.size()
# Generate queries, keys, values
queries = self.q_linear(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
keys = self.k_linear(x).view(batch_size, seq_len, self.head_dim).transpose(0, 1)
values = self.v_linear(x).view(batch_size, seq_len, self.head_dim).transpose(0, 1)
# Calculate attention scores
attn_scores = torch.matmul(queries, keys.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_weights = F.softmax(attn_scores, dim=-1)
# Apply attention to values
attn_output = torch.matmul(attn_weights, values)
# Concatenate heads and pass through final linear layer
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
output = self.out_linear(attn_output)
return output
# Example usage
batch_size = 2
seq_len = 5
embed_dim = 16
num_heads = 4
x = torch.randn(batch_size, seq_len, embed_dim)
mqa = MultiQueryAttention(embed_dim, num_heads)
output = mqa(x)
print(output.shape) # Output shape should be (batch_size, seq_len, embed_dim)
请注意以下几点:
-
embed_dim必须是num_heads的整数倍。 -
q_linear用于生成查询;k_linear和v_linear用于生成共享的键和值。 -
通过对
queries,keys和values进行维度调整和矩阵乘法来计算注意力分数和加权值。 -
最终的输出连接并通过一个线性层进行映射。
这种实现方式有效地减少了计算复杂度,使得注意力机制在处理长序列时更加高效。
分组注意力(GA)
Grouped Attention是一种改进注意力机制的方法,旨在提升处理长序列或高维数据时的计算效率和效果。其核心思想是将输入数据划分成若干组,然后在每一组内分别应用注意力机制,再将结果合并以获得最终的输出。这种方法能够减少计算复杂度,同时保持或提升模型的性能。
机制详解
1. 输入划分
将输入序列或数据划分成若干组。例如,对于一个长度为N的序列,可以将其划分成G组,每组包含N/G个元素。
2. 组内注意力计算
在每一组内分别应用标准注意力机制(如自注意力)。这涉及计算查询(Query)、键(Key)和值(Value)的投影,然后基于查询和键之间的相似性来加权求和值。这一阶段的计算复杂度较低,因为注意力计算仅在较小的组内进行。
3. 组间合并
将各组内的注意力输出合并起来,形成最终的输出。合并方法可以是简单的拼接(Concatenation)或某种形式的聚合(如加权求和)。
4. 可选的跨组注意力
在某些变体中,还可以在合并之前或之后引入跨组注意力机制,以捕捉组之间的依赖关系。这进一步增强了模型的表达能力,但也会增加一些计算复杂度。
代码示例
以下是一个简化的PyTorch代码示例,展示了Grouped Attention的基本实现:
import torch
import torch.nn as nn
class GroupedAttention(nn.Module):
def __init__(self, input_dim, num_heads, group_size):
super(GroupedAttention, self).__init__()
self.num_heads = num_heads
self.group_size = group_size
self.attention = nn.MultiheadAttention(input_dim, num_heads)
def forward(self, x):
N, L, D = x.shape # Batch size (N), Sequence length (L), Embedding dimension (D)
assert L % self.group_size == 0, "Sequence length must be divisible by group size"
# Reshape input into groups
num_groups = L // self.group_size
x = x.view(N, num_groups, self.group_size, D)
# Apply attention within each group
x = x.permute(1, 0, 2, 3).contiguous() # (num_groups, N, group_size, D)
x = x.view(num_groups, N * self.group_size, D) # (num_groups, N * group_size, D)
attn_output, _ = self.attention(x, x, x)
# Reshape back to original dimensions
attn_output = attn_output.view(num_groups, N, self.group_size, D)
attn_output = attn_output.permute(1, 0, 2, 3).contiguous() # (N, num_groups, group_size, D)
attn_output = attn_output.view(N, L, D)
return attn_output
# Example usage
batch_size = 2
seq_length = 8
embedding_dim = 16
num_heads = 2
group_size = 4
x = torch.rand(batch_size, seq_length, embedding_dim)
grouped_attention = GroupedAttention(embedding_dim, num_heads, group_size)
output = grouped_attention(x)
print(output.shape) # Should be (2, 8, 16)
优点
-
计算效率高:由于注意力计算在较小的组内进行,计算复杂度显著降低。
-
适用长序列:更适合处理长序列或高维数据,减少了内存和计算资源的占用。
-
灵活性:可以根据具体应用需求调整组大小和注意力机制的参数。
缺点
-
信息丢失风险:如果组之间的关联性较强,简单的组内注意力可能会丢失一些跨组信息。可通过引入跨组注意力机制来缓解这一问题。
-
参数选择复杂:需在实际应用中仔细选择组大小和其他超参数,以平衡计算效率和模型性能。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}