



Transformer 模型的强大之处在于其优雅的结构和高效的并行计算能力。理解它的最好方式,就是将其核心结构图与实际的代码实现一一对应起来。本文将以《Attention Is All You Need》论文中的经典结构图为蓝本,逐块解析其功能,并展示如何用 PyTorch 代码实现这些模块。
Transformer模型解析
一. 模型整体结构概述
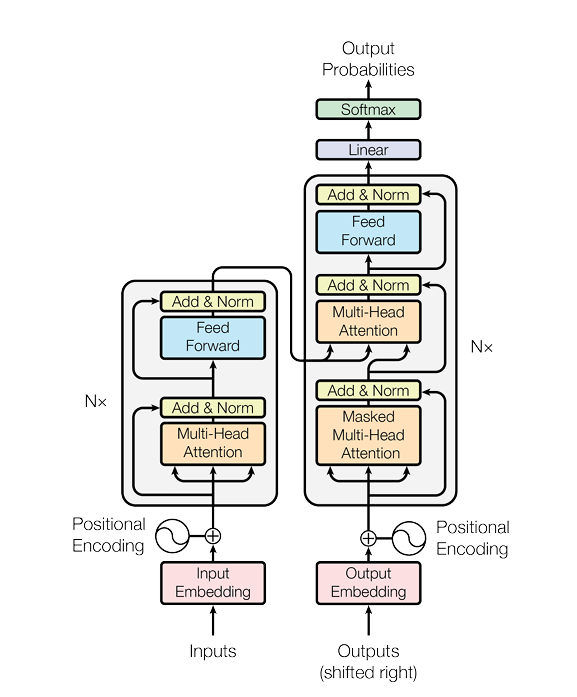
这张图是理解 Transformer 的核心。我们可以看到,它主要由两大部分组成:
- 编码器 (Encoder):在图的左侧,负责读取输入序列(如 "我是学生"),并将其转换为一个富含上下文信息的连续表示序列。
- 解码器 (Decoder):在图的右侧,负责在编码器的 "指导" 下,生成输出序列(如 "I am a student")。
二. 输入层处理
Transformer 的输入层处理是模型能够有效理解和处理输入数据的基础,它主要负责将原始的离散输入(如文本中的词)转换为适合模型计算的连续向量表示,同时为模型注入位置信息。
1. 词嵌入(Word Embedding)
(a) 词嵌入与独热编码(One-Hot Encoding)
在自然语言处理(NLP)任务中,Transformer 的输入通常是文本序列,而计算机无法直接处理文本,需要先将其转化为数值形式。在词嵌入出现之前,最常用的方法是独热编码(One-Hot Encoding)。
独热编码的问题:
- 维度灾难:如果词汇表有 10 万个词,每个词就需要一个 10 万维的向量来表示,其中只有一个位置是 1,其余都是 0,极其稀疏,浪费计算资源。
- 语义鸿沟:任意两个词的向量都是正交的(点积为 0),这意味着模型无法理解 “国王” 和 “王后”、“男人” 和 “女人” 之间的语义关系。
词嵌入的核心思想:将每个词映射到一个低维、稠密的实数向量空间中,使得语义上相似的词,其在向量空间中的距离也相近。
我们可以把这个向量空间想象成一个 “语义地图”:
- “国王” 和 “王后” 在地图上的距离很近。
- “男人” 和 “女人” 在地图上的距离也很近。
- 而且,“国王” - “男人” + “女人” ≈ “王后”,这种向量运算也能在这个地图上成立。
词嵌入就是这个 “语义地图” 的坐标。
(b) 词嵌入的工作原理与训练过程
词嵌入本质上是一个可学习的查找表(Look-up Table)。
初始化:我们创建一个大矩阵 Embedding Matrix,其形状为 [vocab_size(词汇表的大小), embedding_dim(每个词向量的维度)]。
这个矩阵的初始值是随机的、很小的数。此时,这个矩阵没有任何语义信息。
嵌入查找(Embedding Look-up):当我们处理一个词时(比如 “猫”),我们首先获取它在词汇表中的索引(比如索引为 5)。然后,我们从嵌入矩阵中取出第 5 行,这一行就是 “猫” 这个词的向量表示。
这个过程在数学上可以看作是一次矩阵乘法:将一个独热编码向量与嵌入矩阵相乘。但在实践中,为了效率,我们使用索引直接查找,这个操作被称为 gather。
训练与学习:嵌入矩阵是模型的参数,它会在模型的训练过程中通过反向传播不断更新。模型在执行特定任务(如语言模型预测下一个词、文本分类等)时,会调整词向量,使得语义相似的词在向量空间中被拉得更近,以帮助模型更好地完成任务。
例如,在训练一个语言模型时,模型学习到 "the cat sat on the ..." 后面接 "mat" 的概率很高。为了做出正确预测,模型会调整 "cat" 和 "mat" 的向量,使得它们之间的关系更有利于预测。久而久之,所有词的向量都会被调整到一个最优的位置,形成一张有意义的 “语义地图”。
(c) 词嵌入的代码实现过程 (PyTorch)
步骤:
- 创建词汇表,将词转为索引。
# 1. 定义一个小型语料库
corpus = ["i love machine learning", "i love python", "machine learning is future"]
# 2. 创建词汇表
# 将所有句子分词
tokenized_corpus = [sentence.split() for sentence in corpus]
# 收集所有唯一的词
vocabulary = set([word for sentence in tokenized_corpus for word in sentence])
# 为每个词分配一个唯一的索引
word_to_idx = {word: idx for idx, word in enumerate(vocabulary)}
vocab_size = len(vocabulary)
print("词汇表:", word_to_idx)
print("词汇表大小:", vocab_size)
"""
output:
词汇表: {'future': 0, 'learning': 1, 'is': 2, 'machine': 3, 'python': 4, 'love': 5, 'i': 6}
词汇表大小: 7
"""
- 实例化
nn.Embedding(vocab_size, embedding_dim)。
# 3. 定义超参数
embedding_dim = 10 # 每个词向量的维度
# 4. 实例化嵌入层
# nn.Embedding(num_embeddings, embedding_dim)
# num_embeddings: 词汇表大小
# embedding_dim: 嵌入维度
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 此时,embedding_layer.weight 就是我们的嵌入矩阵,它是一个可训练的参数。
print("嵌入层权重 (初始随机):\n", embedding_layer.weight)
print("嵌入层权重形状:", embedding_layer.weight.shape)
# 输出形状: torch.Size([7, 10])
- 将索引张量输入嵌入层,即可得到词向量。
# 5. 准备一个输入样本
# 将句子 "i love machine learning" 转换为索引
input_sentence = "i love machine learning"
input_indices = torch.tensor([word_to_idx[word] for word in input_sentence.split()], dtype=torch.long)
print("输入句子:", input_sentence)
print("输入索引:", input_indices)
# 输出:
# 输入句子: i love machine learning
# 输入索引: tensor([6, 5, 3, 1])
# 6. 通过嵌入层获取词向量
word_vectors = embedding_layer(input_indices)
print("\n获取的词向量:")
for i, word in enumerate(input_sentence.split()):
print(f" '{word}': {word_vectors[i]}")
print("\n输出张量形状:", word_vectors.shape)
# 输出形状: torch.Size([4, 10])
# 解释: 4个词, 每个词10维向量
2. 位置编码(Positional Encoding)
(a) 为什么需要位置编码
Transformer 模型的核心是自注意力机制,它本身不具备处理序列顺序的能力。也就是说,对于输入序列 "我爱你" 和 "你爱我",如果不提供位置信息,自注意力机制会认为它们是完全相同的,因为它只是计算所有词对之间的关联度,而不关心谁先谁后。
位置编码的作用:显式地将词在序列中的位置信息注入到词向量中,使得模型能够区分不同位置的词,从而理解句子的顺序结构。
(b) 位置编码的设计:正弦和余弦函数
对于一个位置为 pos 的词,其位置编码向量 PE 的第 2i 维(偶数索引)和第 2i+1 维(奇数索引)分别按以下公式计算:
其中:
pos:词在序列中的位置索引(从 0 开始)。i:位置编码向量的维度索引(从 0 开始)。
(c) 位置编码的代码实现 (PyTorch)
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000, dropout=0.1):
"""
d_model: 模型的维度,必须与词嵌入维度相同
max_len: 预设的最大序列长度,用于预计算位置编码
dropout: dropout概率,用于防止过拟合
"""
super(PositionalEncoding, self).__init__()
# 创建一个 dropout 层
self.dropout = nn.Dropout(p=dropout)
# 1. 初始化一个位置编码矩阵 pe
# pe 的形状是 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
# 2. 创建一个位置索引向量 position
# position 的形状是 (max_len, 1)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 3. 计算正弦和余弦函数的频率项 div_term
# 使用 exp 和 log 来计算 10000^(2i/d_model),数值上更稳定
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 4. 为偶数维度填充正弦值,为奇数维度填充余弦值
pe[:, 0::2] = torch.sin(position * div_term) # 偶数索引
pe[:, 1::2] = torch.cos(position * div_term) # 奇数索引
# 5. 增加一个批次维度,方便广播
# pe 的形状变为 (1, max_len, d_model)
pe = pe.unsqueeze(0)
# 6. 将 pe 注册为非可训练的缓冲区
# 这意味着 pe 是模型状态的一部分,但不会在反向传播中被更新
# 它会随着模型一起被保存和加载
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: 来自词嵌入层的输出,形状为 (batch_size, seq_len, d_model)
"""
# 将位置编码与词嵌入相加
# self.pe[:, :x.size(1)] 会自动选择与输入序列长度匹配的位置编码部分
x = x + self.pe[:, :x.size(1)]
# 应用 dropout
return self.dropout(x)
# 1. 实例化位置编码层
# d_model 必须与 embedding_dim 相同
pe_layer = PositionalEncoding(d_model=embedding_dim, max_len=100)
# 2. 将词嵌入与位置编码相加
# 注意:PositionalEncoding 的 forward 方法期望输入带有批次维度
# 我们使用 unsqueeze(0) 来添加一个批次维度
final_input = pe_layer(word_vectors.unsqueeze(0))
print("\n词嵌入 + 位置编码后的最终输入形状:", final_input.shape)
# 输出: torch.Size([1, 4, 10])
# 查看最终的输入向量
print("\n最终的输入向量 (批次中的第一个样本):")
print(final_input[0])
总结:
Transformer 的输入层处理可以概括为以下两步:
- 词嵌入 (Embedding):将离散的词索引转换为稠密的、包含语义信息的向量。
- 位置编码 (Positional Encoding):生成一个包含位置信息的向量,并将其与词嵌入向量相加。
与位置编码相加后的向量,才是真正送入 Transformer 编码器的最终输入。它同时携带了词的语义和位置这两种关键信息,为后续的自注意力机制能够正确理解语言奠定了坚实的基础。
三. 自注意力 (Self-Attention)的工作流程
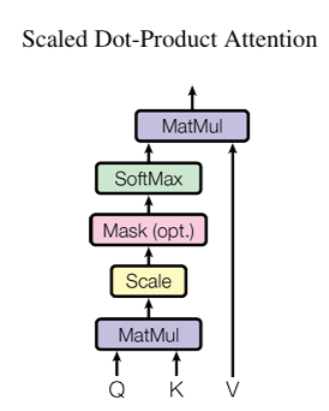
假设我们正在处理一个输入序列:是三个词的向量表示。自注意力会为每个词(如
1. 生成(Q)、键(K)和值(V)
模型会使用三个可学习的权重矩阵
结果:我们得到了三个新的矩阵 Q, K, V。它们的形状和
2. 计算 Self-Attention 的输出
第一步:计算 Q 和 K 的点积(MatMul)
计算每个查询(来自 Q)与每个键(来自 K)之间的相似度分数。这些分数反映了 “当前词(由 Q 代表)” 和 “其他词(由 K 代表)” 之间的关联紧密程度。
第二步:缩放(Scale)
当键向量的维度 较大时,点积的结果会很大,这会导致后续 softmax 函数的梯度变得很小(softmax 对大数值的输入梯度不敏感)。除以
可以将点积结果的范围缩放,使得 softmax 能更稳定地工作,避免梯度消失问题。
第三步:掩码(Mask,可选)
在一些场景下(比如生成任务中的解码器自注意力,需要防止模型看到未来的信息),会对缩放后的分数进行掩码操作。例如,把未来位置的分数设为很小的值(如负无穷),这样在后续 SoftMax 后,这些位置的注意力权重就会接近 0,模型就不会关注未来的信息。在一般的编码器自注意力中,这一步通常不需要。
第四步:SoftMax 归一化
将分数转化为注意力权重,这些权重之和为 1,代表 “当前词” 对 “其他每个词” 的关注程度。权重越高,说明 “当前词” 与该 “其他词” 的关联越紧密,越需要关注该 “其他词” 的信息。
第五步:计算注意力输出(MatMul)
根据注意力权重,对值矩阵 V 中的信息进行加权求和。这样,“当前词” 的输出就融合了 “其他词” 的信息,且融合的程度由注意力权重决定(关联越紧密的词,其信息在输出中占比越高)。
输出公式:
四. 多头自注意力机制(Multi-Head Self-Attention)
1. 单头自注意力的局限性
一个词在句子中可能扮演多种角色,因此需要从不同角度与其他词建立联系。例如,在句子 "The animal didn't cross the street because it was too tired." 中:
it需要与animal建立指代关系。tired需要与animal建立描述关系。cross需要与street建立动作 - 对象关系。
单头注意力试图用一套注意力权重来捕捉所有这些关系,这就像用一个单一的视角去理解一个复杂的场景,可能会顾此失彼。
2. 多头自注意力
将自注意力机制并行地执行多次(即 “多头”),每次都学习不同的表示子空间。
我们可以把每个 “头” 想象成一个独立的 “专家”,它们从不同角度分析同一个句子:
- 头 1(句法专家):专注于学习主谓宾、修饰等句法关系。
- 头 2(语义专家):专注于学习指代、同义等语义关系。
- 头 3(逻辑专家):专注于学习因果、转折等逻辑关系。
通过这种方式,模型能够学习到更丰富、更全面的词间依赖关系。
3. 多头自注意力的工作流程
步骤 1:线性投影与分拆(Linear Projections & Split)
首先,将输入序列 X 通过三组不同的线性层,得到查询(Q)、键(K)和值(V)矩阵。这一步与单头注意力相同。
关键区别在于:接下来,我们将 Q, K, V 沿着特征维度分拆成 h 个(h是头数)低维度的矩阵。
Q = [Q₁, Q₂, ..., Qₕ]
K = [K₁, K₂, ..., Kₕ]
V = [V₁, V₂, ..., Vₕ]
例如,如果模型维度 d_model=512,头数 h=8,那么每个头的维度 d_k = 512 / 8 = 64。Q 矩阵(形状 [seq_len, 512])会被分拆成 8 个 Qᵢ 矩阵(每个形状 [seq_len, 64])。
步骤 2:并行计算自注意力(Parallel Attention Computation)
现在,我们对这 h 组 (Qᵢ, Kᵢ, Vᵢ) 并行地执行缩放点积自注意力计算:
这样,我们就得到了 h 个不同的输出矩阵(每个 “专家” 的报告):head₁, head₂, ..., headₕ。
步骤 3:拼接(Concatenation)
我们已经从 h 个专家那里得到了 h 份不同的 “报告”。现在需要将这些报告整合成一份最终的、全面的报告。
拼接操作就是将这 h 个输出矩阵在特征维度上连接起来:
Concat = [head₁; head₂; ...; headₕ]
如果每个 headᵢ 的形状是 [seq_len, dₖ],那么拼接后的 Concat 矩阵形状就是 [seq_len, h * dₖ],即 [seq_len, d_model]。
步骤 4:最终线性投影(Final Linear Projection)
最后一步,我们使用一个最终的、可学习的权重矩阵 Concat 进行线性变换:
这个 h 个头的输出有效地压缩和整合,最终得到一个维度为 d_model 的、包含了所有头信息的综合表示。
五. 编码器 (Encoder) 详解
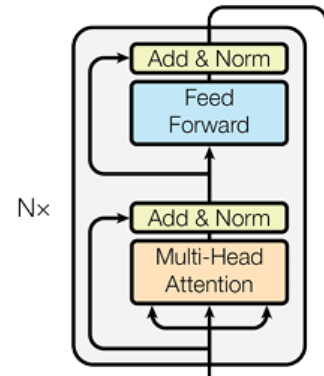
编码器由 N=6 个完全相同的编码器层(Encoder Layer)堆叠而成,每个编码器层包含 2 个子层 + 残差连接 + 层归一化:
- 子层 1:多头自注意力(Multi-Head Self-Attention)—— 接收上一层输出,计算词与词的依赖关系;
- 子层 2:前馈网络(Feed-Forward Network)—— 对每个词的向量进行独立非线性变换;
- 残差连接:每个子层的输出都与该子层的输入 “相加” (
x + 子层输出); - 层归一化:对残差连接后的结果做归一化(均值 0、方差 1)。
经过 6 层处理后,得到最终的上下文感知表示序列,传递给解码器。
六. 解码器 (Decoder) 详解
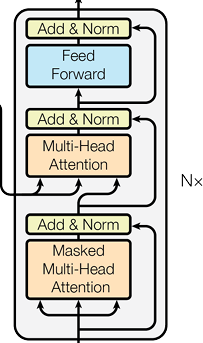
解码器同样由 N=6 个完全相同的解码器层堆叠而成。每个解码器层包含三个主要子层(Sublayer),并且每个子层都配有残差连接(Residual Connection)和层归一化(Layer Normalization)。
结构:
1. 子层一:掩蔽的多头自注意力 (Masked Multi-Head Self-Attention)
这是解码器最具特色的部分,它确保了生成过程的自回归性(Autoregressive Property)。
“自” (Self):意味着 Q, K, V 都来自同一个输入,即解码器自身已生成的序列部分。
“掩蔽” (Masked):掩蔽操作确保了生成过程的自回归性(Autoregressive Property)—— 预测第 t 个词时,模型只能‘看到’第 t 个词之前的所有词,无法利用未来信息,这与人类逐词生成文本的逻辑一致,也保证了生成序列的合理性。
工作流程:
- 生成注意力分数:与普通多头自注意力一样,计算
Q和K的点积。 - 应用掩码:使用一个下三角矩阵作为掩码,将上三角区域(代表未来词的位置)的注意力分数置为负无穷。
- Softmax 归一化:经过 Softmax 后,未来词的注意力权重将为 0。
- 加权求和:模型只能基于过去和当前的词来生成下一个词。
举例:生成 "I love machine learning" 时,预测 "love" 时,模型只能看到 "I";预测 "machine" 时,模型只能看到 "I love"。
2. 子层二:编码器 - 解码器注意力 (Encoder-Decoder Attention)
这是解码器与编码器之间唯一的信息交互通道,也称为交叉注意力(Cross-Attention)。
“编码器 - 解码器”:意味着 Q, K, V 来自不同的输入。
- 查询 (Q):来自解码器的上一个子层(掩蔽自注意力)的输出。它代表了 “我当前想生成什么?” 或 “我需要什么信息?”。
- 键 (K) 和 值 (V):来自编码器的最终输出。它们代表了 “源序列提供了什么信息?”。
工作流程:
- 生成注意力分数:计算解码器的 Q与编码器的 K的点积。
- Softmax 归一化:得到的注意力权重反映了为了生成当前词,应该 “关注” 源序列中的哪些词。
- 加权求和:根据注意力权重,对编码器的 V进行加权求和。
举例:在将 "Je vous aime" 翻译成 "I love you" 时,当解码器生成 "you" 时,编码器 - 解码器注意力会强烈地关注源序列中的 "vous"。
3. 子层三:前馈网络 (Feed-Forward Network, FFN)
这部分与编码器中的前馈网络完全相同。
作用:对编码器 - 解码器注意力的输出进行逐词的、独立的非线性变换,作为每个解码器层的最终输出。
工作流程:
解码器的工作是一个循环迭代的过程。我们以机器翻译为例,源语言是法语 "Je vous aime",目标语言是英语。
1. 初始化:
编码器首先处理输入 "Je vous aime",得到一个上下文表示 Z。解码器的初始输入是一个特殊的起始符号,如 <start>。
2. 第 1 步:生成第一个词 "I"
输入:解码器接收 <start>。
处理:
掩蔽自注意力:只关注 <start>。
编码器 - 解码器注意力:根据 <start> 的查询,关注编码器输出 Z,发现最相关的是 "Je"。
前馈网络:输出一个向量。
预测:通过一个线性层和 Softmax,模型预测出概率最高的词是 "I"。
3. 第 2 步:生成第二个词 "love"
输入:解码器现在接收 <start> I。
处理:
掩蔽自注意力:I 可以关注 <start>,但 <start> 不能关注 I(掩蔽效应)。
编码器 - 解码器注意力:根据 I 的查询,关注编码器输出 Z,发现最相关的是 "aime"。
预测:模型预测出下一个词是 "love"。
4. 第 3 步:生成第三个词 "you"
输入:解码器现在接收 <start> I love。
处理:
掩蔽自注意力:love 可以关注 <start> 和 I。
编码器 - 解码器注意力:根据 love 的查询,关注编码器输出 Z,发现最相关的是 "vous"。
预测:模型预测出下一个词是 "you"。
5. 终止:
这个过程持续进行,直到模型预测出特殊的终止符号 <end>,生成过程结束。最终输出序列为 "I love you <end>"。
七. 输出层 (Output Layer)
解码器的最终输出还不能直接作为文本。它是一个维度为 d_model 的向量序列。我们需要一个输出层将其转换为词汇表上的概率分布。
输出层的结构
输出层非常简单,通常由两个部分组成:
1. 线性变换 (Linear Transformation):
一个线性层,将解码器输出的 d_model 维向量投影到词汇表大小 vocab_size 的维度上。
这个 logits 张量的形状是 (batch_size, seq_len, vocab_size),每个位置的向量可以看作是词汇表中每个词的 “分数”。
2. SoftMax 函数:
对 logits 的最后一个维度应用 SoftMax 函数,将分数转换为一个概率分布。
概率最高的那个词,就是模型当前步的预测结果。
PyTorch 实现
整体结构概览
一个标准的 Transformer 模型包含以下几个核心部分:
- 输入层 (Input Embedding + Positional Encoding):将输入的离散 token (如单词 "apple") 转换为连续的、包含语义信息的向量,并注入位置信息。
- 编码器 (Encoder):读取源语言(如英语)的输入序列,将其编码成一个包含所有输入信息的上下文向量(Context Vector)。
- 解码器 (Decoder):在编码器输出的基础上,一步一步地生成目标语言(如法语)的输出序列。
- 输出层 (Output Projection + Softmax):将解码器输出的隐藏状态转换为词汇表中每个词的概率分布,从而预测下一个词。
1. 准备工作:导入库和设置超参数
首先,我们导入所有需要的库,并定义模型的超参数:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import numpy as np
# --- 超参数定义 ---
# 词汇表大小 (源语言和目标语言可以不同,这里为了简化设为相同)
src_vocab_size = 5000
tgt_vocab_size = 5000
# 词向量嵌入维度 (Embedding Dimension)
d_model = 512
# 编码器和解码器堆叠的层数
num_layers = 6
# 多头注意力的头数
num_heads = 8
# 前馈网络中隐藏层的维度
d_ff = 2048
# Dropout比率
dropout = 0.1
# 最大序列长度 (用于位置编码)
max_len = 5000
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
2. 输入层 (Input Layer)
输入层由两部分组成:词嵌入 (Embedding) 和 位置编码 (Positional Encoding)。
2.1 词嵌入 (Embedding)
词嵌入层的作用是将一个整数索引(代表一个词)映射为一个固定维度的稠密向量。
2.2 位置编码 (Positional Encoding)
Transformer 是并行处理整个序列的,本身不包含序列的顺序信息。位置编码的作用就是将词在序列中的位置信息注入到词向量中。这里我们使用正弦和余弦函数来实现,这是论文中推荐的方法。
class PositionalEncoding(nn.Module):
"""
位置编码模块
"""
def __init__(self, d_model, max_len, dropout):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵,维度为 [max_len, d_model]
pe = torch.zeros(max_len, d_model)
# 创建一个位置索引向量,维度为 [max_len, 1]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 计算正弦和余弦函数的频率,使用log空间来缩放
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数索引位置使用正弦函数
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数索引位置使用余弦函数
pe[:, 1::2] = torch.cos(position * div_term)
# 增加一个批次维度,使其形状变为 [1, max_len, d_model]
# 这样可以方便地对一个批次内的所有序列进行广播
pe = pe.unsqueeze(0)
# 将位置编码矩阵注册为非可训练的缓冲区
# 这意味着它是模型的一部分,但不会在反向传播中更新
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: 嵌入后的词向量,形状为 [batch_size, seq_len, d_model]
"""
# 将位置编码加到词向量上。注意,我们只取与输入序列长度匹配的部分
# self.pe[:, :x.size(1)] 的形状是 [1, seq_len, d_model]
x = x + self.pe[:, :x.size(1)]
# 应用dropout
return self.dropout(x)
class InputEmbedding(nn.Module):
"""
输入层模块,包含词嵌入和位置编码
"""
def __init__(self, vocab_size, d_model, max_len, dropout):
super(InputEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
def forward(self, x):
"""
x: 输入的词索引序列,形状为 [batch_size, seq_len]
"""
# 1. 词嵌入
# [batch_size, seq_len] -> [batch_size, seq_len, d_model]
embedded = self.embedding(x)
# 2. 位置编码
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, d_model]
output = self.pos_encoding(embedded)
return output
3. 编码器 (Encoder)
编码器由 num_layers 个相同的编码器层堆叠而成。
3.1 编码器层 (Encoder Layer)
每个编码器层包含两个子层:
- 多头自注意力机制 (Multi-Head Self-Attention):关注输入序列自身的所有词,计算每个词与其他所有词的关联度。
- 前馈网络 (Feed-Forward Network, FFN):一个简单的两层线性网络,对每个词的表示进行独立的非线性变换。
每个子层后面都跟着一个残差连接 (Residual Connection) 和 层归一化 (Layer Normalization)。
class MultiHeadAttention(nn.Module):
"""
多头注意力机制
"""
def __init__(self, d_model, num_heads, dropout):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
# 每个头的维度
self.d_k = d_model // num_heads
# 定义线性变换层,用于将输入线性投影到 Q, K, V
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# 定义输出的线性变换层
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
query, key, value: 输入张量,形状均为 [batch_size, seq_len, d_model]
mask: 注意力掩码,形状为 [batch_size, 1, seq_len, seq_len] 或 [batch_size, num_heads, seq_len, seq_len]
"""
batch_size = query.size(0)
# 1. 线性投影并分割成多个头
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, d_model]
q = self.w_q(query)
k = self.w_k(key)
v = self.w_v(value)
# [batch_size, seq_len, d_model] -> [batch_size, num_heads, seq_len, d_k]
q = q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = k.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = v.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. 计算注意力分数
# (batch_size, num_heads, seq_len_q, d_k) x (batch_size, num_heads, d_k, seq_len_k)
# -> (batch_size, num_heads, seq_len_q, seq_len_k)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
# 3. 应用掩码
if mask is not None:
# mask中值为True的位置,分数设为一个非常小的数,经过softmax后概率几乎为0
scores = scores.masked_fill(mask, -1e9)
# 4. 应用Softmax
# (batch_size, num_heads, seq_len_q, seq_len_k) -> (batch_size, num_heads, seq_len_q, seq_len_k)
attn_probs = F.softmax(scores, dim=-1)
# 5. 应用Dropout
attn_probs = self.dropout(attn_probs)
# 6. 与Value矩阵相乘
# (batch_size, num_heads, seq_len_q, seq_len_k) x (batch_size, num_heads, seq_len_k, d_k)
# -> (batch_size, num_heads, seq_len_q, d_k)
output = torch.matmul(attn_probs, v)
# 7. 拼接多个头的输出
# (batch_size, num_heads, seq_len_q, d_k) -> (batch_size, seq_len_q, num_heads, d_k)
output = output.transpose(1, 2).contiguous()
# (batch_size, seq_len_q, num_heads, d_k) -> (batch_size, seq_len_q, d_model)
output = output.view(batch_size, -1, self.d_model)
# 8. 最终的线性投影
# (batch_size, seq_len_q, d_model) -> (batch_size, seq_len_q, d_model)
output = self.w_o(output)
return output, attn_probs
class PositionWiseFeedForward(nn.Module):
"""
位置-wise前馈网络
"""
def __init__(self, d_model, d_ff, dropout):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
x: 输入张量,形状为 [batch_size, seq_len, d_model]
"""
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, d_ff]
x = self.fc1(x)
x = F.relu(x)
x = self.dropout(x)
# [batch_size, seq_len, d_ff] -> [batch_size, seq_len, d_model]
x = self.fc2(x)
return x
class EncoderLayer(nn.Module):
"""
编码器层
"""
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = PositionWiseFeedForward(d_model, d_ff, dropout)
# 两个子层之后都需要层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, src_mask):
"""
x: 编码器层的输入,形状为 [batch_size, src_seq_len, d_model]
src_mask: 源语言的注意力掩码,用于屏蔽padding
"""
# --- 子层1: 多头自注意力 ---
# 残差连接: x + SubLayer(x)
attn_output, _ = self.self_attn(x, x, x, src_mask) # Q, K, V 都来自于输入x
x = self.norm1(x + self.dropout1(attn_output))
# --- 子层2: 前馈网络 ---
# 残差连接: x + SubLayer(x)
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout2(ffn_output))
return x
class Encoder(nn.Module):
"""
完整的编码器
"""
def __init__(self, src_vocab_size, d_model, num_layers, num_heads, d_ff, max_len, dropout):
super(Encoder, self).__init__()
self.embedding_layer = InputEmbedding(src_vocab_size, d_model, max_len, dropout)
# 堆叠多个编码器层
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, src_seq, src_mask):
"""
src_seq: 源语言输入序列,形状为 [batch_size, src_seq_len]
src_mask: 源语言注意力掩码,形状为 [batch_size, 1, 1, src_seq_len]
"""
# 1. 输入层: 词嵌入 + 位置编码
# [batch_size, src_seq_len] -> [batch_size, src_seq_len, d_model]
output = self.embedding_layer(src_seq)
# 2. 通过所有编码器层
for layer in self.layers:
# [batch_size, src_seq_len, d_model] -> [batch_size, src_seq_len, d_model]
output = layer(output, src_mask)
return output
4. 解码器 (Decoder)
解码器与编码器结构类似,但它包含三个子层。
4.1 解码器层 (Decoder Layer)
每个解码器层包含三个子层:
- 掩码多头自注意力机制 (Masked Multi-Head Self-Attention):与编码器的自注意力类似,但增加了一个未来信息掩码 (Look-Ahead Mask),确保在生成第
i个词时,模型只能看到第i个词之前的词。 - 编码器 - 解码器注意力机制 (Encoder-Decoder Attention):这是编码器和解码器之间的桥梁。它的 Query (Q) 来自于解码器的前一个子层的输出,而 Key (K) 和 Value (V) 则来自于编码器的最终输出。
- 前馈网络 (Feed-Forward Network, FFN):与编码器中的完全相同。
同样,每个子层后面都跟着残差连接和层归一化。
class DecoderLayer(nn.Module):
"""
解码器层
"""
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
# 子层1: 掩码自注意力
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 子层2: 编码器-解码器注意力
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
# 子层3: 前馈网络
self.ffn = PositionWiseFeedForward(d_model, d_ff, dropout)
# 三个子层之后都需要层归一化
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
"""
x: 解码器层的输入,形状为 [batch_size, tgt_seq_len, d_model]
enc_output: 编码器的输出,形状为 [batch_size, src_seq_len, d_model]
src_mask: 源语言的注意力掩码,用于在编码器-解码器注意力中屏蔽源语言的padding
tgt_mask: 目标语言的注意力掩码,包含padding和未来信息的屏蔽
"""
# --- 子层1: 掩码多头自注意力 ---
attn_output, _ = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout1(attn_output))
# --- 子层2: 编码器-解码器注意力 ---
# Q来自解码器自身(x),K和V来自编码器输出(enc_output)
attn_output, _ = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout2(attn_output))
# --- 子层3: 前馈网络 ---
ffn_output = self.ffn(x)
x = self.norm3(x + self.dropout3(ffn_output))
return x
class Decoder(nn.Module):
"""
完整的解码器
"""
def __init__(self, tgt_vocab_size, d_model, num_layers, num_heads, d_ff, max_len, dropout):
super(Decoder, self).__init__()
self.embedding_layer = InputEmbedding(tgt_vocab_size, d_model, max_len, dropout)
# 堆叠多个解码器层
self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, tgt_seq, enc_output, src_mask, tgt_mask):
"""
tgt_seq: 目标语言输入序列,形状为 [batch_size, tgt_seq_len]
enc_output: 编码器的输出,形状为 [batch_size, src_seq_len, d_model]
src_mask: 源语言注意力掩码
tgt_mask: 目标语言注意力掩码
"""
# 1. 输入层: 词嵌入 + 位置编码
# [batch_size, tgt_seq_len] -> [batch_size, tgt_seq_len, d_model]
output = self.embedding_layer(tgt_seq)
# 2. 通过所有解码器层
for layer in self.layers:
# [batch_size, tgt_seq_len, d_model] -> [batch_size, tgt_seq_len, d_model]
output = layer(output, enc_output, src_mask, tgt_mask)
return output
5. 输出层 (Output Layer) 和 完整的 Transformer 模型
输出层很简单,就是一个线性变换,将解码器输出的隐藏状态(维度为 d_model)投影到词汇表大小(维度为 tgt_vocab_size),然后通常会接一个 Softmax 函数来得到概率分布。
class Transformer(nn.Module):
"""
完整的Transformer模型
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_layers, num_heads, d_ff, max_len, dropout):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, d_model, num_layers, num_heads, d_ff, max_len, dropout)
self.decoder = Decoder(tgt_vocab_size, d_model, num_layers, num_heads, d_ff, max_len, dropout)
# 输出层:将解码器输出投影到词汇表
self.projection = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src_seq, tgt_seq, src_mask, tgt_mask):
"""
src_seq: [batch_size, src_seq_len]
tgt_seq: [batch_size, tgt_seq_len]
src_mask: [batch_size, 1, 1, src_seq_len]
tgt_mask: [batch_size, 1, tgt_seq_len, tgt_seq_len]
"""
# 1. 编码器编码源序列
# enc_output: [batch_size, src_seq_len, d_model]
enc_output = self.encoder(src_seq, src_mask)
# 2. 解码器解码
# dec_output: [batch_size, tgt_seq_len, d_model]
dec_output = self.decoder(tgt_seq, enc_output, src_mask, tgt_mask)
# 3. 输出层投影
# output: [batch_size, tgt_seq_len, tgt_vocab_size]
output = self.projection(dec_output)
return output
6. 辅助函数:生成掩码 (Mask)
为了让模型正常工作,我们需要生成两种掩码:
- Padding Mask: 用于屏蔽输入序列中的填充 token (padding token),因为我们不希望模型关注这些无意义的 token。
- Look-ahead Mask (未来信息掩码): 仅用于解码器的自注意力,确保模型在预测下一个词时,无法看到未来的词。
def create_padding_mask(seq, pad_idx=0):
"""创建Padding掩码"""
# [batch_size, 1, 1, seq_len]
return (seq != pad_idx).unsqueeze(1).unsqueeze(2)
# 文件: model.py
def create_look_ahead_mask(seq_len):
"""
创建Look-ahead布尔掩码。
上三角部分(未来信息)为 True,表示需要被屏蔽。
"""
# torch.triu(..., diagonal=1) 创建一个上三角矩阵(不包括对角线)
# .bool() 将其转换为布尔类型
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
return mask
def create_masks(src_seq, tgt_seq, pad_idx=0):
"""
为训练创建所有需要的掩码。
- src_pad_mask: 用于编码器和编码器-解码器注意力,屏蔽源序列的padding。
- tgt_mask: 用于解码器自注意力,同时屏蔽目标序列的padding和未来信息。
"""
src_pad_mask = create_padding_mask(src_seq, pad_idx)
tgt_pad_mask = create_padding_mask(tgt_seq, pad_idx)
tgt_seq_len = tgt_seq.size(1)
tgt_look_ahead_mask = create_look_ahead_mask(tgt_seq_len)
tgt_look_ahead_mask = tgt_look_ahead_mask.to(tgt_pad_mask.device)
tgt_look_ahead_mask = tgt_look_ahead_mask.unsqueeze(0).unsqueeze(0)
tgt_mask = tgt_pad_mask | tgt_look_ahead_mask
src_pad_mask = src_pad_mask.to(src_seq.device)
return src_pad_mask, tgt_mask

















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









