






LoRAM(在剪枝模型训练LoRA并叠加到原始模型)
Train Small, Infer Large: Memory-Efficient LoRA Training for Large Language Models
https://arxiv.org/abs/2502.13533
https://github.com/junzhang-zj/LoRAM提出了一种名为LORAM的内存高效的LoRA训练方案,旨在解决大型语言模型(LLMs)在微调过程中面临的高内存需求问题。LORAM通过在剪枝后的模型上训练低秩矩阵,并将这些矩阵恢复后应用于原始模型进行推理,显著降低了训练过程中的内存占用,同时保持了推理性能。
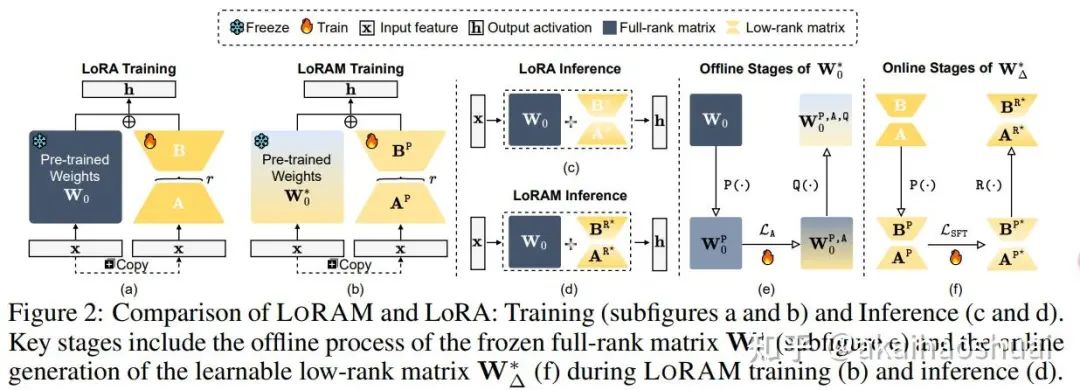
具体步骤如下:
1、剪枝全秩权重生成(Pruned Full-Rank Weight Generation):使用剪枝算法 对原始权重矩阵 进行剪枝,生成剪枝后的权重矩阵 。剪枝通过二值掩码矩阵 实现,保留重要参数(标记为1),移除冗余参数(标记为0)。 ◦ (裁剪的矩阵和原始矩阵维度相同,只不过更加稀疏)
2、剪枝低秩矩阵训练(Pruned Low-Rank Matrix Training):在剪枝后的模型上进行LoRA训练,更新剪枝后的低秩矩阵 ,同时保持 冻结。训练目标是最小化监督微调损失 。
3、恢复低秩矩阵生成(Recovered Low-Rank Matrix Generation):通过恢复函数 将训练好的剪枝低秩矩阵 恢复为与原始模型权重形状一致的矩阵 。恢复过程通过在剪枝位置填充零来实现,确保恢复后的矩阵可以与原始权重 无缝合并。

4、恢复低秩矩阵推理(Recovered Low-Rank Matrix Inference):在推理阶段,使用恢复后的低秩矩阵 与原始权重 结合,进行前向传播。
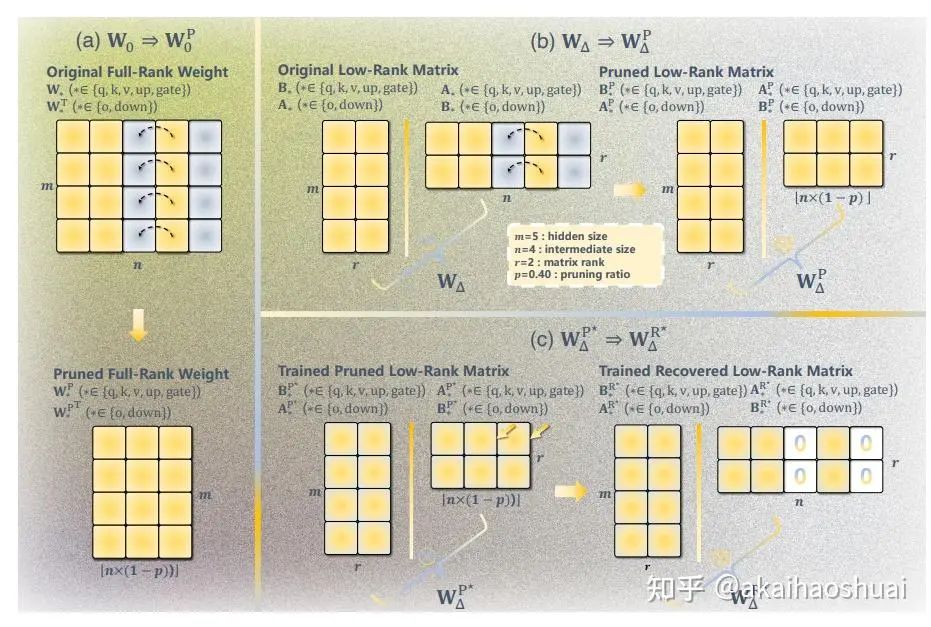
此外,论文还提出了一种有效的对齐策略,通过在小数据集上对剪枝模型进行持续预训练,以解决训练时使用的剪枝模型与推理时使用的原始模型之间的知识不一致性问题。
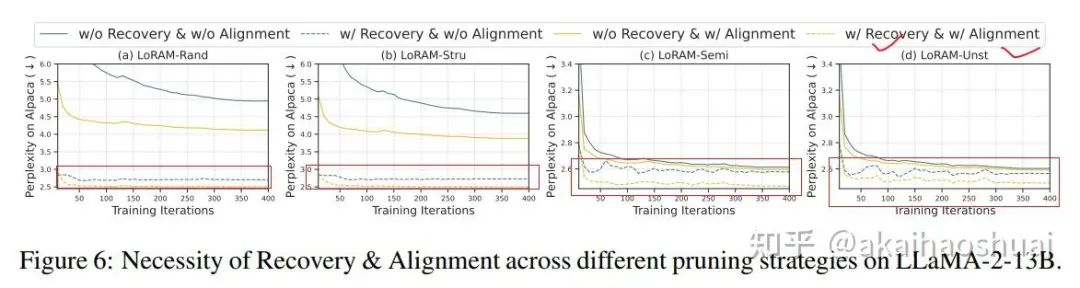
消融实验表明有恢复的效果比没回复的好,有对齐训练的效果比没有的好。
Make LoRA Great Again
Make LoRA Great Again:Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
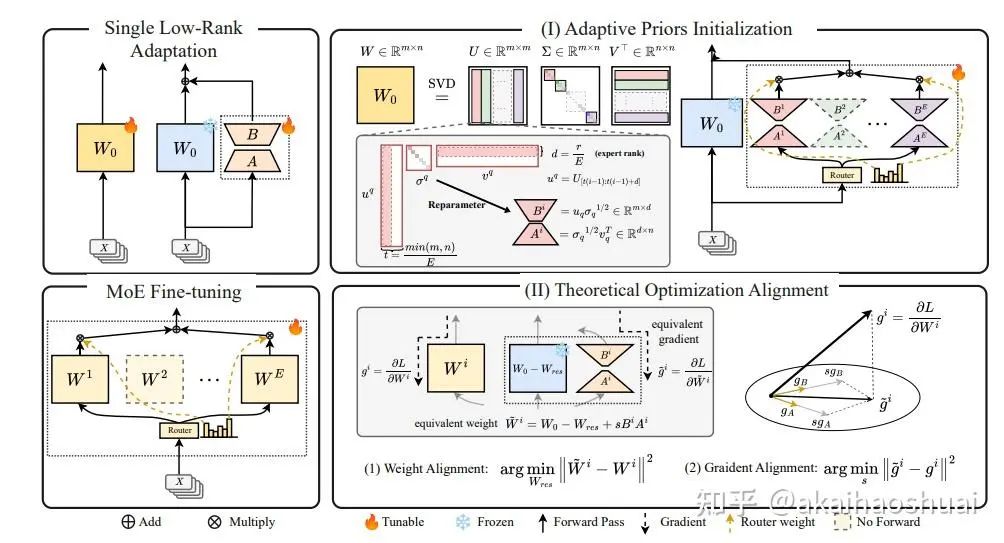
https://arxiv.org/abs/2502.16894GOAT通过自适应地整合SVD结构化的先验知识,并通过理论缩放与全微调MoE的优化过程对齐,显著提高了LoRA微调的效率和性能。

Overcoming Vocabulary Mismatch
Overcoming Vocabulary Mismatch: Vocabulary-agnostic Teacher Guided Language Modeling
https://arxiv.org/abs/2503.19123在token级别的蒸馏方法中,要对teacher模型和student模型的logit计算loss,那么就需要vocab size相同。因此对于不同模型的vocab,需要进行一定的处理才能进行token级蒸馏。
1. Token-level Lexical Alignment(Token级词汇对齐)
该方法通过字符级别的偏移量来精确地将学生模型的token映射到教师模型的token上。具体步骤如下:
输入:学生模型的token序列 和教师模型的token序列 ,每个token都有对应的字符偏移量(起始和结束位置)。
映射函数:对于每个学生token xS_i ,找到覆盖该token的教师token范围 [j,k]。映射函数定义为:

算法实现:通过两次二分查找来高效地确定每个学生token对应的教师token范围。具体算法如下:
for each student token xS_i:
stS_i, edS_i = get_offsets(xS_i)
lowIdx = binary_search_lower_bound(edT_t > stS_i)
highIdx = binary_search_upper_bound(stT_t < edS_i) - 1
mapping[i] = (lowIdx, highIdx)2. Teacher Guided Loss(教师引导的损失函数)
该方法通过教师模型的损失值来指导学生模型的训练,即使它们的logit分布不同。具体步骤如下:
定义损失函数:
学生模型的token损失:
教师模型的token损失(通过映射函数确定的教师token范围):
其中, 是一个聚合函数(如求和、取最大值或求平均值)。
指导学生模型的训练:
通过teacher模型的token损失来重新加权学生模型的token重要性:
其中, 是一个权重函数,用于确定是否采用某个token的指导。具体定义为:

基线方法:
KLD:基于Kullback-Leibler Divergence的知识蒸馏方法,适用于相同词汇表的教师和学生模型。
ULD:Universal Logit Distillation,适用于不同词汇表的教师和学生模型。
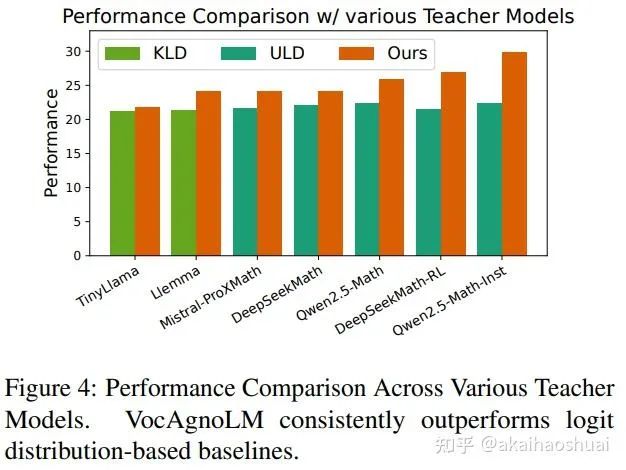
VocAgnoLM通过Token级词汇对齐和教师引导的损失函数,有效地解决了教师模型和学生模型之间的词汇表不匹配问题。该方法不仅能够显著提升学生模型的性能,还能灵活地利用不同词汇表的教师模型,展示了其在跨词汇表知识转移中的高效性和实用性。
Everything You Need to Know about Knowledge Distillation
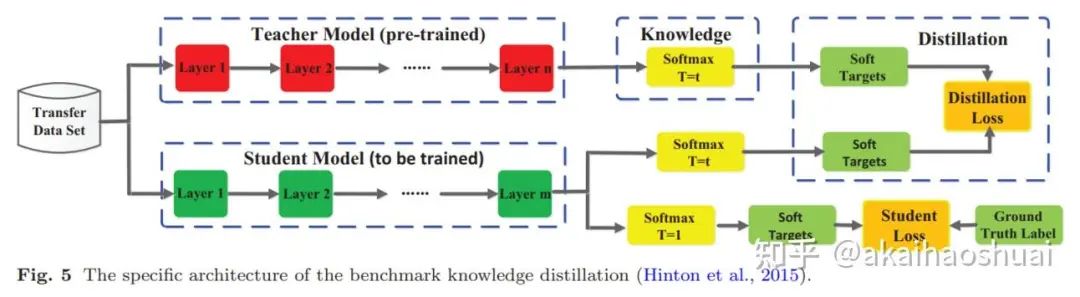
https://huggingface.co/blog/Kseniase/kdstudent 模型不仅要学会复现正确答案,还要学会复现teacher 模型对这些答案及其错误的相对置信度。关于teacher 模型如何在错误类别中分配概率质量的知识提供了丰富的信息,有助于student 模型更好地进行泛化。通过将真实标签上的标准训练损失与teacher 模型软标签上的蒸馏损失相结合,student 模型可以在参数少得多的情况下,实现接近teacher 模型的准确率。
改进算法
不同的研究提出了知识提炼算法,以使其更有效,有时甚至应用其他技术。以下是其中一些:
多teacher蒸馏:结合多位teacher的知识,打造更全面的学生模型。这种方法可以针对不同的特征使用不同的teacher模型,对所有teacher模型的预测进行平均,或者在每个训练步骤中随机选择一位teacher模型。它结合了不同模型的优势,并提升了知识的多样性。
跨模式提炼:在不同类型的数据之间传输知识,例如从图像到文本或从音频到视频。
基于图的提炼:关注不同数据点之间的关系,以捕捉隐藏的关系并更好地理解数据结构。
基于注意力的提炼:teacher模型生成注意力图来突出显示数据中的重要区域,学生模型复制这些注意力图,学习关注的位置。
非目标类别增强 KD(NTCE-KD):关注teacher输出中经常被忽略的非目标类别的概率,因此学生模型也会学习到错误的标签。
对抗式蒸馏:利用生成对抗网络 (GAN) 帮助学生通过模仿老师来提高学习效果。GAN 可以生成额外的合成数据来改进学生的训练,或者使用其鉴别器(用于检查数据真伪)来比较老师和学生的输出。
无数据蒸馏:无需原始数据集即可进行。这里也使用 GAN 基于teacher模型生成合成训练数据。
量化蒸馏:将大型模型中用于计算的高精度数字(如 32 位)减少为更小的低精度值(8 位或 2 位),从而使 AI 模型更轻量、更快。
推测性知识提炼 (SKD):学生和老师在文本生成训练过程中相互合作。学生生成草稿 token,老师选择性地替换低质量 token,从而生成与学生自身分布一致的实时高质量训练数据。
终身蒸馏:模型持续学习,在学习新技能的同时记住旧技能。以下是此方法的一些变体:
-
• 1)模型学习如何学习,因此可以快速适应新任务(元学习);
-
• 2)利用过去任务中的知识,从极少量的示例中进行学习(小样本学习);
-
• 3)在训练新任务时,保留其知识的压缩版本(全局蒸馏)。
生成模型中的蒸馏:指将复杂的生成过程蒸馏成更简单的过程。例如,你可以将多步骤扩散模型蒸馏成单步骤生成模型(通常是 GAN),从而显著加速推理速度。此外,在文本转语音模型中,蒸馏可用于将自回归模型压缩为非自回归模型,从而加速语音生成。
神经架构搜索 (NAS):帮助自动找到最佳的学生模型来匹配老师。
如果学生模型较小,可以使用较小的教师模型来节省计算资源。如果学生模型较大,则需要更好、更大的教师模型来获得最佳性能。
Sparse Logit Sampling
Sparse Logit Sampling: Accelerating Knowledge Distillation in LLMs
https://arxiv.org/abs/2503.16870稀疏 Logit 抽样:加速法学硕士 (LLM) 中的知识提炼。
存储全部的logit进行蒸馏会耗费较多的内容,因此有些方法尝试只存储部分关键logit进行蒸馏,降低内存消耗。而之前使用的top-k logits蒸馏,会导致筛选的logits分布和原始logits分布差异较大,影响蒸馏效果。本文尝试了随机采样蒸馏,以尽量少的logit近似原始分布,从而减少蒸馏效果的丢失。
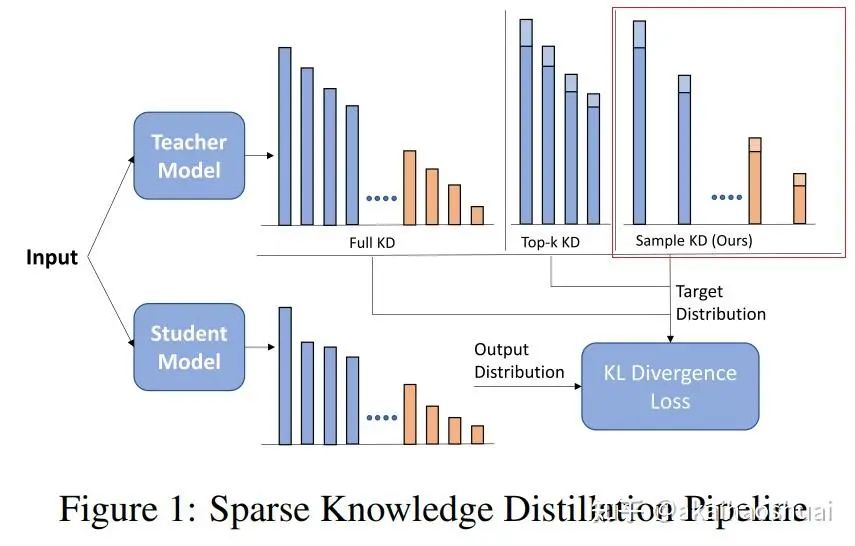
系数蒸馏对比
论文提出了随机采样知识蒸馏(RS-KD)方法,通过重要性采样(importance sampling)来解决现有稀疏知识蒸馏方法的偏差问题。具体方法如下:
重要性采样:从教师模型的概率分布中随机采样,而不是简单地选择Top-K概率值。采样过程中,每个采样点都会根据其采样概率进行权重调整,从而获得无偏的教师概率分布估计。
无偏估计:通过理论证明和实验验证,RS-KD能够提供教师概率分布的无偏估计,并且在期望上保持与完整蒸馏(FullKD)相同的梯度。
稀疏存储:RS-KD只需要存储少量的采样结果,相比Top-K方法,大大减少了存储需求。例如,论文中提到仅需存储12个采样结果,即可达到与完整蒸馏相近的性能。
具体实现:在实现上,RS-KD通过多次采样(如50轮)来确保采样结果的多样性,并通过归一化处理来获得最终的稀疏目标概率分布。
Long-to-Short-via-Model-Merging(模型合并效果对比)
Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging
https://arxiv.org/abs/2503.20641
https://github.com/hahahawu/Long-to-Short-via-Model-Merging具体合并方法
平均合并(Average Merging):通过算术平均模型权重来减少方差。
任务算术(Task Arithmetic, TA):通过任务向量(weight_diff)将多个SFT模型能力合并到预训练模型中。
Ties-Merging:通过修剪参数、解决冲突和加权聚合来合并模型。
DARE:通过随机丢弃冗余参数、调整参数方向和加权整合关键参数来合并模型。
AIM(Activation-Informed Merging):利用激活空间信息保护预训练模型中的关键权重。
LoRE-Merging:通过低秩估计框架减少任务向量之间的干扰。
Twin-Merging:通过将专家知识分为通用知识和特定任务知识,并动态整合这些知识。
Sens-Merging:通过分析参数敏感性来确定合并系数,实现细粒度的参数控制。
本文通过合并wen2.5-Math-7B和DeepSeek-R1-Distill-Qwen-7B,测试了不同合并方法的效果
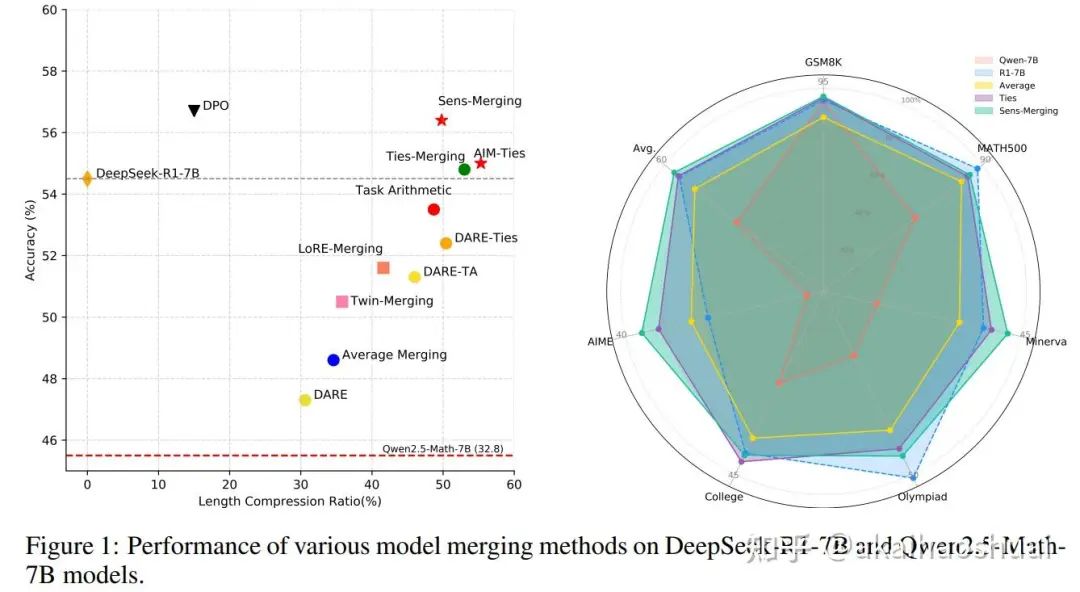
其中Sens-Merging的方法效果最好。
在每个任务特定的模型中,Sens-Merging 通过计算梯度信息来分析各层参数的敏感性。具体步骤如下:
-
• 使用校准数据集(calibration dataset)计算每个任务模型的梯度信息。
-
• 通过 softmax 函数对梯度信息进行归一化,得到每个任务模型中各层的敏感性分数。
-
• 这些敏感性分数反映了各层对模型性能的贡献程度。
Mediator(模型合并冲突问题)
Mediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
https://arxiv.org/abs/2502.04411模型合并(Model Merging):包括模型平均(Model Averaging)和模型路由(Model Routing)。模型平均通过计算参数的加权平均值来融合不同模型的知识,但面临参数冲突问题;模型路由则通过在推理时选择最相关的模型来避免冲突,但会导致存储和计算成本显著增加。
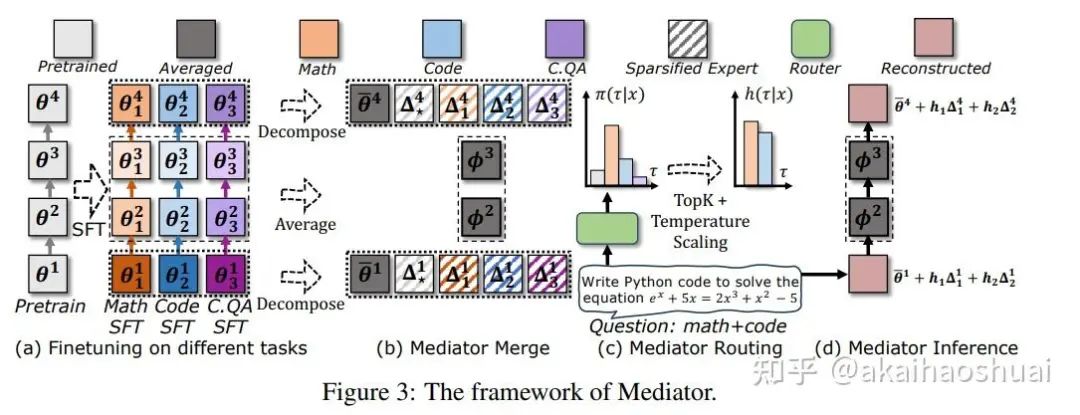
对于两个SFT任务的权重参数 和 ,如果它们的符号相反(即 ),则认为它们存在冲突。冲突比例 是指在某一层中冲突参数的比例。
-
• 冲突分布建模:将不同层的冲突比例 建模为高斯分布 。
-
• 层合并与路由策略:对于每一层,如果该层的冲突比例 小于 ,则对该层进行平均合并;否则,将该层作为专家进行路由。通过这种方式,模型可以在保留公共知识的同时,避免高冲突层的参数冲突。

DarwinLM(剪枝)
DarwinLM: Evolutionary Structured Pruning of Large Language Models
https://arxiv.org/abs/2502.07780
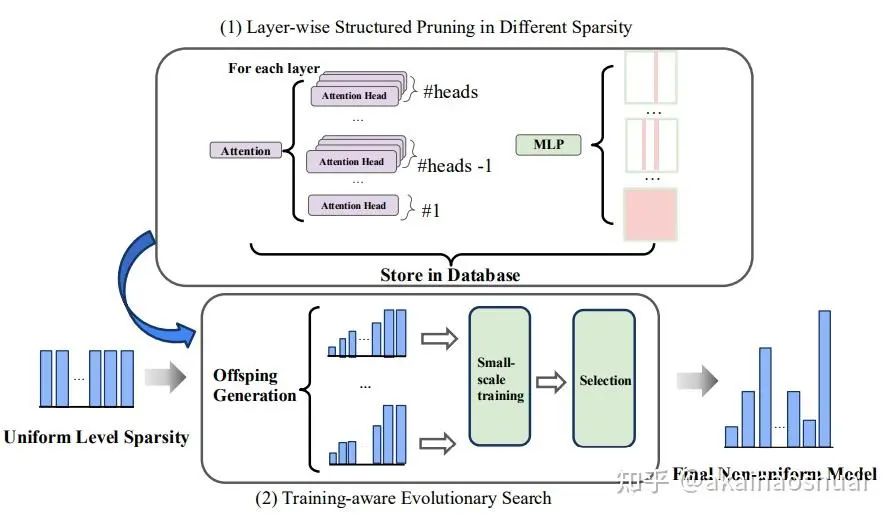
https://github.com/IST-DASLab/DarwinLM论文通过非均匀剪枝策略,结合二阶信息和进化搜索算法,能够在满足稀疏度约束的条件下找到性能最优的模型结构。
权重更新的公式(和量化的相同)

逐层量化,计算量化前后的loss之差,更新剩下权重

过程相同,只是将之前的权重更新(量化)->剪枝。
剪枝结构包括:
-
• 多头自注意力中的头剪枝
-
• MLP 模块的中间维度剪枝
-
• 整个注意力或 MLP 模块的移除
考虑到上述过程是均匀剪枝的,效果部好,因此使用进化搜索算法进行非均匀优化。
进化搜索算法包括初始化、变异过程和多步训练感知后代选择过程:
-
• 初始化:从均匀压缩的父模型开始,生成稀疏度级别数据库。
-
• 变异过程:在每个模块组内随机选择一个单元增加稀疏度级别,同时选择另一个单元减少稀疏度级别,保持总稀疏度不变。
-
• 多步训练感知选择过程:通过小规模数据对后代进行微调,并计算适应度值。随着选择步骤的增加,保留的后代数量逐渐减少,同时用于适应度评估和训练的样本数量逐渐增加。最终选择的候选模型作为下一代的起点。

Efficient Model Development through Fine-tuning Transfer(diff权重迁移)
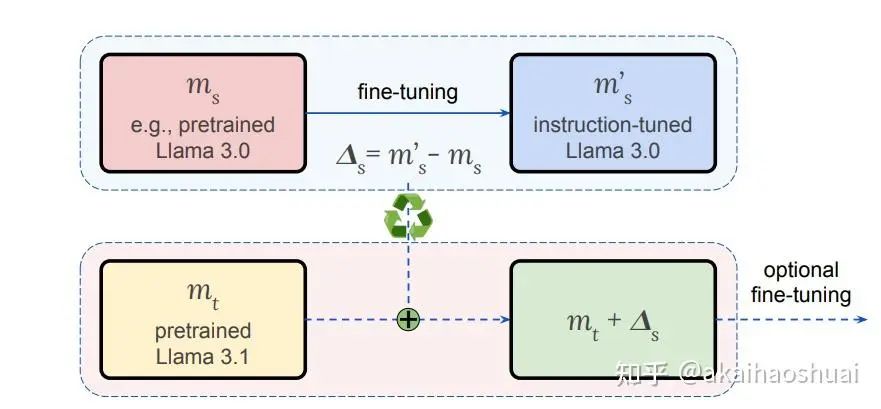
https://arxiv.org/abs/2503.20110每次新的预训练模型版本发布时,都需要重复进行昂贵的对齐(alignment)过程,例如针对特定任务的微调。本文尝试了将微调前后的模型权重weight_diff保存下载,在新的模型上直接叠加,已得到微调后的效果。
问题
1、需要模型架构相同才能叠加weight_diff。
2、模型权重是独一无二的,或许可以认为是训练数据的代表。那么在A数据上训练的模型,在B数据上微调,假设得到了A+B的效果,那么新版模型在B数据上训练,需要在A数据上微调,才能得到相同的效果。如果直接叠加之前的weight__diff,会导致新的模型在B上过度训练,而在A上欠拟合。(其实这么理解也不对,数据不一样,权重不一样,梯度更新的方向也不同,diff代表的含义也完全不同)。总之就是以我目前的认知,我觉得肯定是有问题的。。。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









