






大模型能力非常契合数据分析发展趋势,且数据分析也是大模型重要落地场景,银行、证券、食品饮料、美妆、餐饮等领域都在探索将大模型和数据分析工具深度结合,通过对话等交互方式实现指标查询、报表生成等功能,降低数据分析工具使用门槛。
本次分享将围绕大模型在数据分析场景的落地应用以及应用实践路径来展开。
01
大模型与数据分析发展相结合
从当前数据分析的发展趋势来看,我们可以很清楚地感受到大模型的能力是自然而然的与数据分析的发展趋势相应契合,这意味着数据分析是大型模型落地应用中至关重要的场景。
关于大型模型的能力边界,我们通过调研数百家企业用户,发现问题在于企业用户(尤其是IT部门)对于大模型是否可以在哪些场景中落地,还没有明确的认知。实际上,IT部门最后还是服务于业务部门和管理层,因此当后两者对于大型模型在哪些场景下应用没有明确想法时,IT部门去推广大模型就会变得非常困难。
因此,在跟很多企业用户交流时,我们发现他们都非常想知道大型模型在哪些场景下可以应用,而数据分析天然是重要应用场景,这是由整个数据分析市场发展趋势所决定的,具体情况如下:
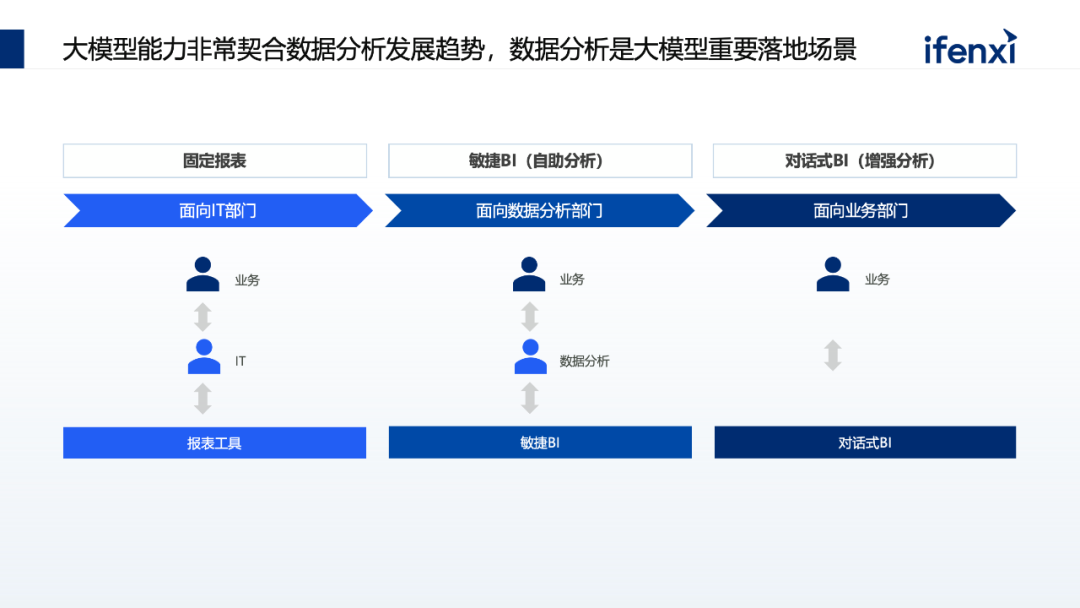
第一阶段,以静态报表为主,传统BI和静态报表基本上都是面向IT部门的,业务部门提出需求之后,由IT根据报表工具开发出固定的报表,然后业务部门查看报表结果。
第二阶段,我们提到的敏捷BI强调的是自助式分析,这一点实际上是指在业务部门提出需求之后,数据分析师可以基于敏捷BI的工具帮助业务部门快速获取所需的数据,帮助他们获得所需要的结果。
因此,第二阶段的真正服务对象变成了数据部门,也就是数据分析师。这个部门有时在独立的数据分析部门下,有时则在业务部门下设有专门的数据分析师。可以发现,对比第一阶段,第二阶段明显更近了一步。
第三阶段,我们看到的不管是基于大模型的AskBI还是增强分析,都是直接面向业务的,其理念是业务部门直接使用对话式BI工具就能够解决问题,获得所需的数据结果。这一过程无需像之前那样依赖IT部门开发报表,或者数据分析师基于敏捷BI再提供数据结果,而是直接由业务部门推进落地。
因此我们可以看到,在整个数据分析的发展趋势是不断地降低用户的交互门槛,让业务部门更加自如、更加容易地使用分析工具,并实现其自身的效果。
所有数据分析的需求,包括取数和用数需求,本质上都来自于业务部门。但是过去业务部门缺乏能力或者没有好的工具来满足这些需求,因此必须依赖于IT部门、数据部门来实现它们的目标。
而随着BI不断地提升交互的体验,降低用户门槛,最终使业务部门自身具备数据分析的能力,这与大模型的能力天然契合。大模型的生成能力和效力可以比较好地提升用户交互体验,因此我们认为,数据分析一定会是大模型很重要的落地场景。
02
大模型在数据分析场景的落地应用
在调研中我们发现,从趋势上看,像银行、保险、证券、消费品零售、美妆等领域各个头部企业,都在落地实施大模型和数据分析工具的深度融合。

从大模型实际能力的边界来看,它在企业内部的用户落地过程中,大致分为生成类应用、决策类应用和多模态应用这三类。在数据分析场景中,它涉及到生成类应用和决策类应用这两种。
2.1 生成类应用
目前,大家谈论的主要是生成类应用主要体现在以下几个方面:
第一,对话式交互,这也是最常见的应用体现,即通过自然语言取代原来拖拉的方式并自动完成整个数据分析和相关报表的生成。
第二,内容生成,就是自动地生成分析报告和相关报表。
第三,代码开发,这项应用在数据分析中非常重要,其中之一是编写SQL查询语句以查看底层宽表的数据。因此,大型模型本身可以自动地生成SQL查询语句。
第四,智能体,也就是大模型本身可以去做任务的分解。例如,你需要查询利润率,那利润率可能本身是由营收减成本来计算的,那么大模型其实要去做任务的分解和指标的分解。
这些是我们看到的生成类应用是现在比较落地比较多的场景,相对进展也跑得比较快。
2.2 决策类应用
另一类是决策类应用的。之前BI可以实现数据辅助决策,基于返回的数据结果进行一些分析和预警。例如,如果指标有异常变化,它会进行提示和执行一些简单的数据分析,基于增长率的变化进行分析。
但辅助决策实际上无法对该指标背后的结果进行深度分析,找出影响因素,智能决策我们认为是大型模型在BI和数据分析中的重点应用。具有一些理解能力后,可以对指标和结果背后的原因进行一些归因,进行下钻分析,找出深度影响因子。
2.3 未来价值
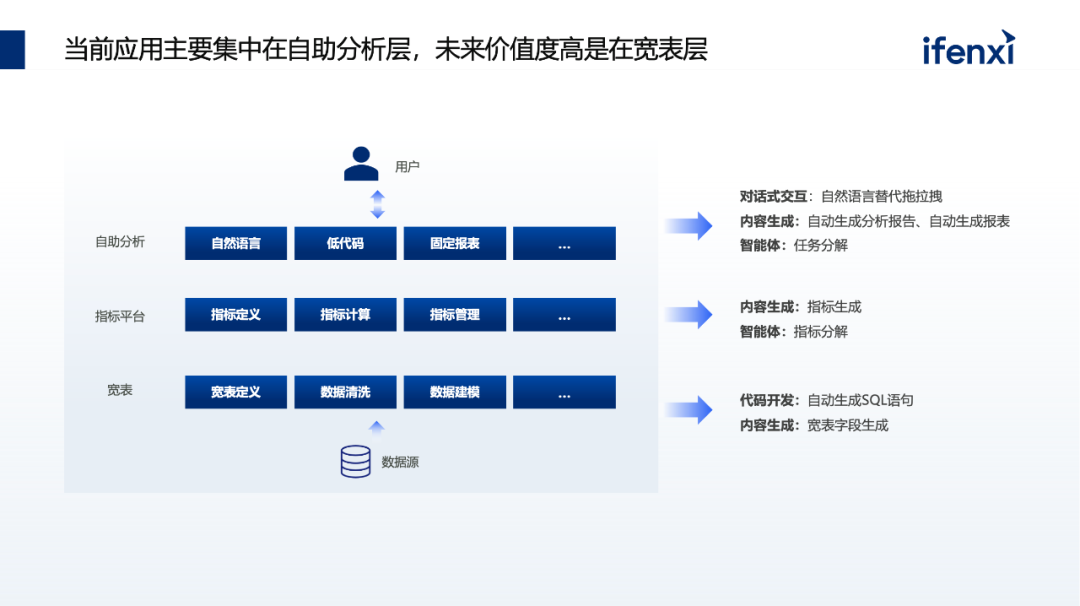
具体落实到分析场景中,一般自助分析都需要宽表,完成宽表后会涉及数据清洗和建模。由于从去年开始大家都在做指标平台,也就是去做中间指标的定义、计算、管理,然后再到交互层怎么样去实现自助式的分析。
在自助分析中,我们可以看到第一个环节是生成对话式的交互内容和任务分解,这些都是在自助分析中实现的。在指标平台中可以生成并分解指标;而在宽表中,大家通常会使用代码开发,即自动生成SQL查询语句以及生成内容,例如在定义宽表时,字段可以让大型模型先给你一版定义,然后你可以基于它持续优化。
现如今,我们所见到的应用大多都是在自助式分析层面,旨在提升用户的交互体验,让用户可以直接感受到互动的优势。然而这种方法存在一个问题:如果在数据分析的底层,也就是在宽表、数据治理、数据清洗、数据建模等方面不做足够成熟的工作,那么想要得到正确的结果是非常困难的。也就是说,数据底层如果没做好,想要进行数据提取也是非常困难的。
因此,我们认为未来最大的价值在于底层,即如何更好地进行整个数据治理和数据清理工作,这无疑是我们认为最关键的切入点,这也是现在我们看到的一些实际的实践方式。
2.4 当前挑战
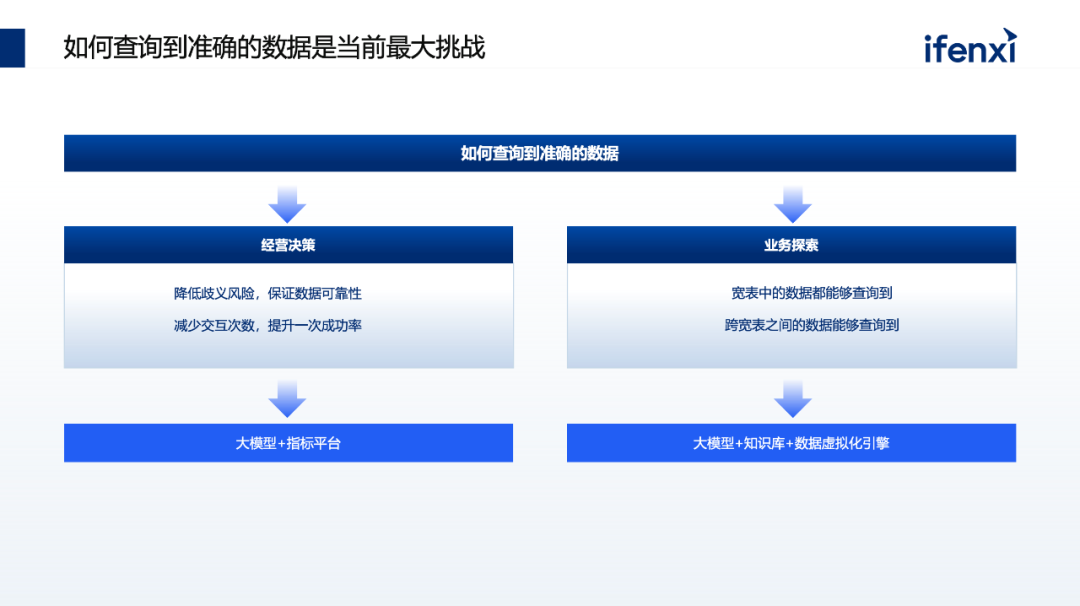
就目前而言,我们认为最大的挑战仍然是数据分析一直面临的一个问题:如何准确取得所需数据。业务部门的数据提取需求始终存在,但到目前为止并没有得以很好地解决。我们认为,在不同的场景下,该问题应该有一些行之有效的实践落地。
第一类场景是面向管理层的经营决策。 在该场景下,问题的核心是如何确保数据的可靠性和准确性,以及如何降低信息偏差。要提高数据的可靠性和准确性,首要解决的事如何减少中间的交互次数,提升成功率。对于管理层或者经营部门而言,他们很难在持续等待很长时间后才能得到回复。我们认为,具体的实践方式是使用大模型加指标平台,这也是目前许多公司在企业内部实现的方式之一。
第二类场景是业务探索,其中一个关键点是如何能够查询到宽表中的数据。这个问题对于业务探索来说是一个非常大的挑战。
对于经营部门而言,他们只需要关注这几个指标,因此只需确保通过自然语言理解后,他们能够快速查看这些指标并反馈结果,这基本上已经满足了经营决策的需求。因为实际上经营管理部门的管理层通常只会关注一些常规指标,只要你能够满足他们的需求即可。
但是当涉及到业务部门时情况就有所不同,因为在业务探索过程中往往存在大量指标。例如,有些银行可能会有两万个指标,甚至有数千或数万人使用这些指标进行数据提取和应用。因此不光需要查询这些指标的结果,同时由于其业务持续变化,因此现有的指标可能是不足够的。我们需要获取底层宽表中的数据,以查找除指标内数据之外的宽表中的数据。这是一大应用需求。
而另一个需求则是在宽表之上构建宽表,这是可以通过自助分析来实现的。然而,当存在多个不同的宽表时,如何进行join处理和跨宽表查询,就变成了相当大的挑战。在业务探索过程中,这些都是核心问题和关注点,因此我们认为实现路径应该是使用大型模型加上知识库,再加上数据虚拟化引擎来实现。而数据虚拟化引擎在市场上尚未十分成熟。
03
大模型在数据分析场景下的实现路径
下一步将讲解如何实现这两个方面的需求,即经营决策的应用场景以及实现路径。
3.1 大模型+指标平台的实现路径

从目前看到的情况来看,决策首先需要的是确保准确性,要确保每次交互获取的数据是准确的,因此不能让大模型过于天马行空地查询数据。因此,我们通常采用的实现路径之一是直接调用GPT,结合用户输入的自然语言,使用大型模型的通用算法和功能来识别和理解用户意图,以更精准地命中关键词。
当命中关键词后会在指标平台上进行查询,这个查询过程非常严格,只能在指标平台上进行,这可以确保最终的结果一定会与指标平台中的具体指标相关。查询完成后,大模型会自动生成一段分析报告的语句,而不仅仅是简单地提供数据结果或表格,这样做可以让用户体验更加顺畅。
与此同时,大模型本身也可以解读这些数据,并给出初步的一些建议。例如,哪些指标在最近两个月内显著增长或发生了变化,需要特别关注哪些指标,而且当使用GPT3.5或GPT4时这个过程就会非常简单,不需要进行预训练。
我们现在看到,通过fine-tuning微调可以很好地发挥模型的理解能力。根据我们的调研结果,这种微调所需的数据量最多不超过1万条,通常只需要几千条就足够好训练出结果了,这是一类使用GPT的方法。
如果需要进行私有部署,使用6B、7B或13B的模型就可以很好地实现以上效果。无论是进行fine-tuning还是进行简单的预训练,都可以实现接近GPT3.5的效果。因为最终的查询是针对指标进行限定,这是一个相对较小的范围,而且整个推理的成本也不高。
根据我们的调研,使用两张3090显卡在几周的时间内进行微调是可以很好地实现结果的,这也是目前可以使用的比较好的实现方式。其优势在于,可以显著增强对话式交互能力,降低 BI 使用门槛,让管理层和经营分析部门能够快速获取所需数据
当然缺点也同时存在,即非常依赖于所关注的指标范围,如果指标涵盖的范围非常准确,那么它就可以很好地回答和解答相关的问题,可一旦超出了这个指标平台的范围之后,它的回答准确率和各方面就会有非常显著的下降。
另外,所有指标平台里面的指标是提前开发好,要做好开发就需要基于你的数据源,或者你的层面的宽表或数仓。因此当你的指标快速变化,比如说你每个月或者每几个月你的指标都会调整一次,那就意味着你的开发成本整体是相对较高的。
以上我们目前看到的大模型+指标平台的较多使用的场景以及实际的路径。
3.2 大模型+知识库+数据虚拟化的业务探索路径
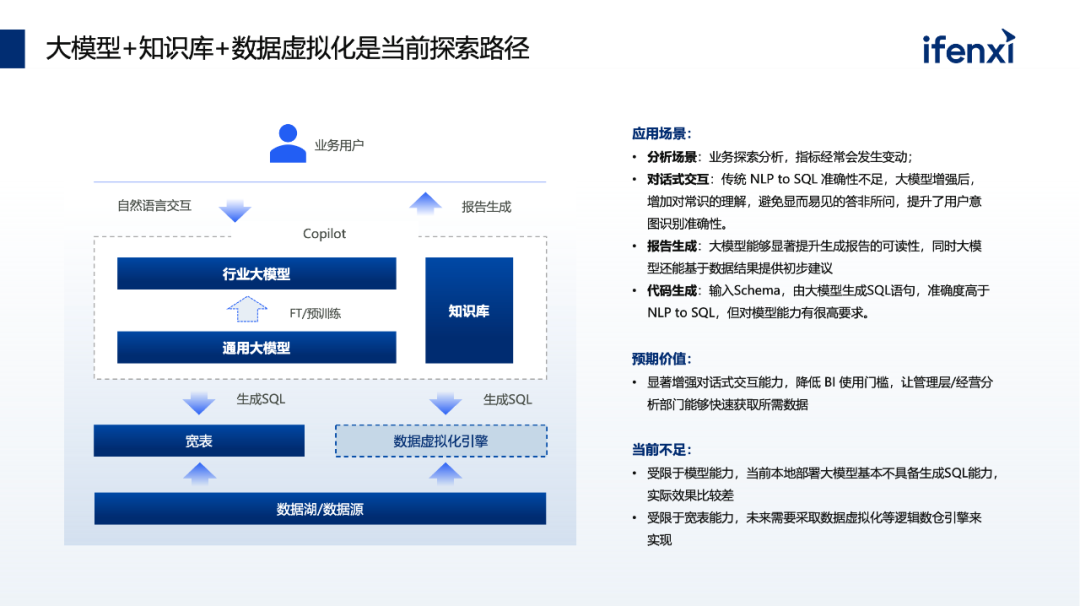
在业务探索层面,目前我们看到的比较常见的方式是生成SQL,但传统的NLP to SQL的准确率相对较低,现在真正能够将准确率提高的就是GPT4,能做到约90%的准确率。同时,国内的其他大模型目前在这方面能力上相对较有限,所以,直接生成SQL是现在的一个比较大的挑战。
这一块实现路径是在提出需求后直接查询宽表,不只是通过指标平台去查,而是去查底层的宽表。对于生成SQL的准确度的要求而言,现在国内的大模型能力都不能达到。许多大型企业要做私有部署,如果使用了百亿级别的模型尺寸,它本身的理解能力和交互能力与通用模型的差距会更大。
因此,我们目前看到的一种较好的方式是使用GPT4,但其中有一种方式是并不一定要将所有数据都挂进去,只需提供与GP4相关的一些Schema,就能帮你自动生成。如果只需要做这一层,它实际上可以很好地满足你的需求。
但如果下一步计划是进行更多的归因分析,并进行一些有关预测的深入挖掘分析时,就需要使用到知识库。这其中会存在以下两点问题:
第一,数据跨境合规风险。 针对跨境输送,国内政策对于数据出境方面有严格的要求,其中有提到,数据量超过一定限制时可能会引发法律风险,甚至可能涉及刑事风险。因此,合规是一个相当大的问题。
第二,企业数据泄露。 对于一些头部企业,因为GPT4不断基于一些优质语料进行重新训练,一些回答和最佳实践可能被用于GPT4内部语料的训练。虽然Open AI还是公开表示不会去动数据,但是如果想要不断优化模型,他们必然需要大量高价值的语料,这些语料大量来自用户的交互场景。
因此,如果使用GPT4的方法去做外挂的话,这两点仍然存在较大的风险。而要解决以上问题,当前阶段最大的挑战是受制于模型的能力,无论是通用国产大模型还是未来的私有化部署模型,这两种能力现在都不足够。
此外,在查找宽表时仍然会受到本身的限制,也就是说当业务部门希望进行更多更灵活的自助式分析时,可能需要的数据不在单个宽表中,或者需要通过连接多个宽表来获得数据。在这种情况下,我们认为这条路可能并不可行,因为仍然需要依赖于宽表之间的连接。因此,未来的另一个方向是基于数据化虚拟化引擎。
数据虚拟化引擎本质上是在数据湖之上通过物理引擎形成的逻辑性数仓,通过数据虚拟化引擎实现整个数据资产管理后,再进行SQL的生成。然而,我们目前看到的案例相对较少,有大型银行在做POC和相关尝试,但目前没有走通的。不过我们认为,数据虚拟化引擎在未来会是一个比较好地去解决业务探索问题的方向。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









