






本文将详细梳理从零开始训练大语言模型的全过程,包括预训练阶段、指令微调、奖励模型和强化学习的实现方式。

一、预训练阶段(Pretraining)
大模型的预训练是现代自然语言处理(NLP)技术中的核心步骤,特别是在基于Transformer架构的模型(如GPT系列、BERT等)中。预训练的目标是让模型能够从大量的无监督文本数据中学习语言的统计规律、语法结构、语义关系等,以便后续可以迁移到具体的下游任务(如文本分类、问答、翻译等)。这个过程就像一名高中生在三年的学习过程中,系统地接受老师的基础教学,积累了大量的知识和技能,为之后的专项训练(如高考)做好了充分准备。
1.1 核心思想
大模型的预训练通常分为两大类方法:自监督学习(Self - supervised Learning) 和无监督学习(Unsupervised Learning) 。其中,最常见的是自监督学习,通过对大量的无标签文本进行训练,模型能够学习到语法和语义信息,而无需手动标注数据。
预训练的过程包括以下几个关键步骤:
-
目标设定:学习语言的内部结构、词汇之间的关系以及长距离的上下文依赖。
-
数据准备:使用大规模的无标签文本数据集,这些数据通常来源于互联网、书籍、新闻等。
-
训练目标:模型通过预测文本的某些部分(例如下一个token,或者遮掩的部分)来训练自己,从而学习到语言的规律。
1.2 Transformer架构概述
Transformer架构是现代大规模预训练模型(如GPT、BERT等)的核心基础。它主要由注意力机制(attention)和前馈神经网络(Feed - forward Network)构成。
-
自注意力机制(Self - attention):自注意力机制使得模型在处理每个token时,可以“关注”输入序列中其他位置的token,从而捕捉到长距离的依赖关系。
-
多头注意力(Multi - head Attention) :将多个注意力头组合起来,模型能够在不同的子空间中捕捉到多种不同的依赖关系。
-
前馈神经网络:每个Transformer层包括一个前馈神经网络,用于进一步处理来自注意力层的信息。
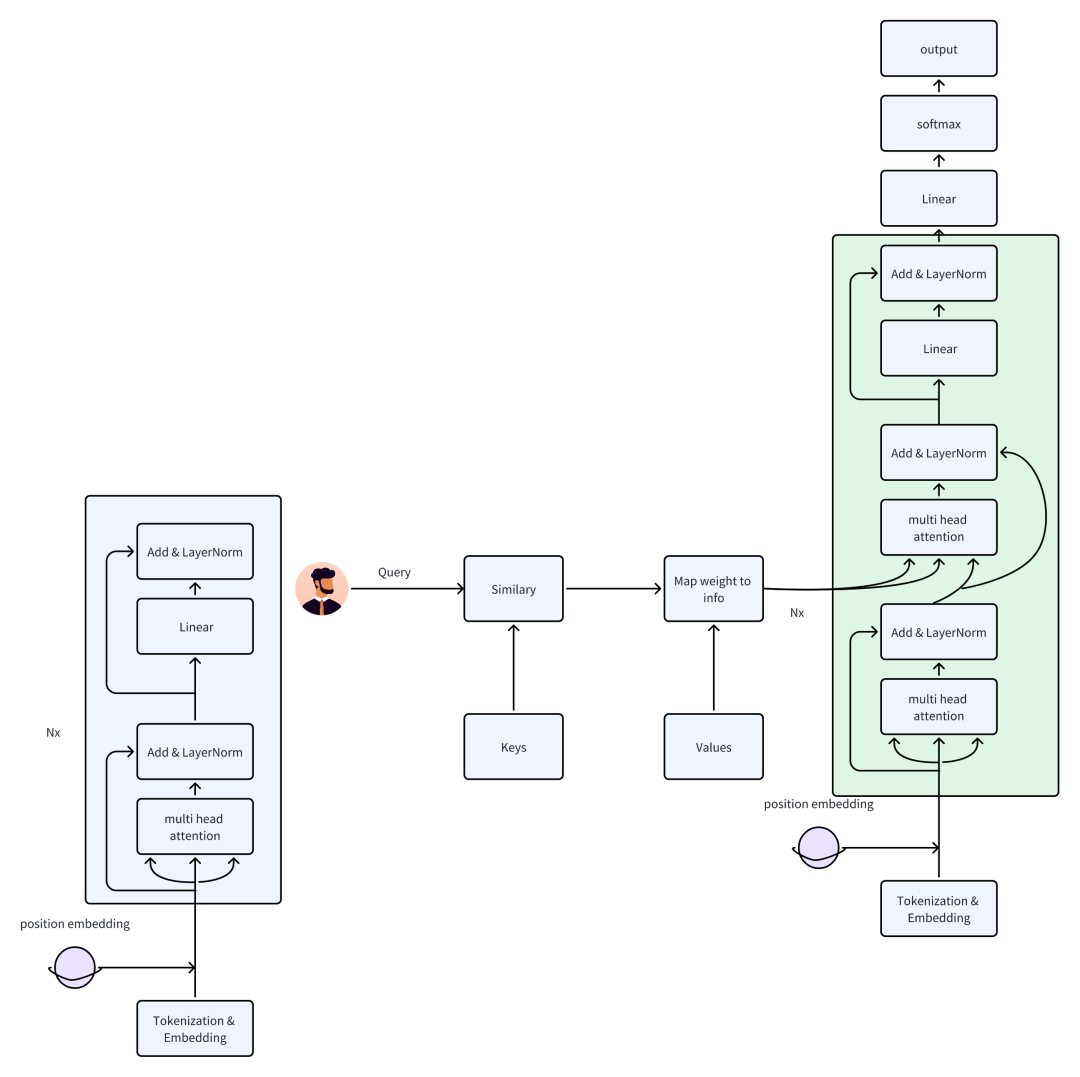
1.3 具体流程
大模型的预训练流程通常遵循以下步骤:
(1)数据准备
预训练过程中使用的是大规模的文本数据集(例如Wikipedia、BooksCorpus、Common Crawl等),这些数据通常是未经标注的原始文本。这些未经标注的 原始文本通常要进行以下处理:
-
分词(Tokenization) :原始文本需要进行分词处理(将文本拆分成tokens)。现代预训练模型大多采用子词级别的分词方法(如Byte Pair Encoding, BPE,或者SentencePiece等),使得词表能够灵活地处理未登录词(OOV)问题。
-
嵌入(Embedding) :每个token会通过一个嵌入层(Embedding layer)映射成一个高维向量表示,作为输入送入模型的后续处理流程。
(2)训练目标设定
预训练任务的选择会根据不同的模型架构有所不同,常见的目标包括:
自回归语言建模(Autoregressive Language Modeling) :这种方法主要用于生成式预训练(如GPT)。模型通过预测文本序列中的下一个token来学习语言规律。即在自回归模型中,输入序列中的每个token都是基于前文信息进行预测的,也就是根据前面所有的词预测下一个词。
具体来说,给定一个文本序列,模型的任务是学习条件概率分布:
也就是,模型根据前面所有的词预测下一个词。每一步都根据前文信息更新其对下一个token的预测。
自编码语言建模(Autoencoding Language Modeling) :这种方法主要用于BERT类的模型,它通过预测文本中被遮蔽(masked)的token来进行训练。即输入序列中的一部分token被“遮蔽”掉(通常使用一个特殊的[MASK]标记代替),模型的目标是根据上下文预测出这些被遮蔽的token。
例如,给定句子:
`The quick brown fox jumps over the [MASK] dog.`
模型的目标是预测[MASK]位置的单词是"lazy"。
这种训练方式使得模型能够捕捉到双向上下文信息(即同时考虑左侧和右侧的上下文),适用于需要理解语义关系的任务。
(3)模型训练
模型通过前向传播算法对目标值进行预测,然后通过损失函数计算预测值与真实值之间的损失值,再利用梯度下降算法和反向传播算法优化模型参数。最常见的优化算法是Adam,它在处理稀疏梯度和大规模数据时非常有效。
不同的语言建模方式有不同的损失函数:
-
自回归语言建模:对于自回归模型(如GPT),损失函数通常使用交叉熵损失(Cross - Entropy Loss),其目标是最小化模型预测的概率分布与真实分布之间的差异。即在每个token的预测上,模型尽量将预测的token分布接近真实的token分布。损失函数为:
-
自编码语言建模:对于自编码模型(如BERT),模型的损失函数也是交叉熵损失,目标是让模型预测出正确的被遮蔽的token。例如,对于某个位置被遮蔽的token,损失函数会计算模型预测的token分布与真实token之间的交叉熵。
通过这样的大规模预训练,模型能够捕捉到语言中的丰富结构和语义信息,从而为下游任务的迁移学习打下坚实的基础。例如,在自回归模型中,模型通过根据前文预测下一个词来捕捉到单词之间的依赖关系,这帮助模型学习到语言的流畅性和一致性。
二、监督微调阶段(Supervised Finetuning)
尽管在预训练阶段,模型已经通过大量的文本数据学习到语言的统计特性和一些基础的语法、语义信息,但它通常并不能很好地处理特定任务。通过监督微调(Supervised Fine-Tuning, SFT)阶段的训练,模型将学习如何在特定的任务或领域内表现得更加出色,尤其是在应对具体问题时能够更精准、更高效。就像是高中生为了高考所做的专项模拟考试训练。
在这一阶段一般采用的方式是指令微调(Instruction Finetuning),为了便于理解,下文提到的SFT与指令微调不做区分。
2.1 数据准备
数据主要来源于两个方面:一是人工进行标注,二是通过类似ChatGPT这样的模型自动生成训练数据。 后者减少了人工构建数据集的成本,也能够更快地生成大量的训练样例。具体来说,可以给定一些基本的指令样例,让模型生成类似的新的指令和答案对,从而形成一个自动化的训练数据生成过程。例如,斯坦福大学的Alpaca项目通过ChatGPT自动生成了5200条指令 - 答案样例,极大地提升了训练的效率。
(1)文本数据格式
`{ "Instruction":"", "Input":"", //Input字段为可选字段,有时Instruction部分会包含Input的内容 "Output":"" } // 例子: { "Instruction":"请帮我翻译一句话", "Input":"hello", "Output":"你好" }, { "Instruction":"请帮我翻译一句话:hello", "Input":"", "Output":"你好" } `
(2)数据编码格式
首先是使用与预训练时相同的分词器(如BPE、SentencePiece)进行分词操作,即将文本拆分为token。然后将输入和输出拼成一个序列,通常按照如下的方式
`[Instruction] + [分隔符] +([Input])+ [分隔符] + [Output] `
给出例子如下:
文本:
`用户:请解释量子力学的基本概念。\n助手:量子力学是描述微观粒子行为的物理学分支…… `
Token序列:
`[Token_1, Token_2, ..., Token_n] `
标签序列(对应输出):
`[Token_k, Token_k+1, ..., Token_m] `
注意:
-
输入的最大长度由模型的上下文窗口大小限制(例如 GPT - 3 为 2048 tokens)。
-
如果序列超过最大长度,可能需要截断或者滑窗处理。
-
现代深度学习框架(如 PyTorch、TensorFlow)在批量训练时要求所有样本具有一致的形状(例如张量的维度相同),这样可以充分利用 GPU 的并行计算能力。常采用 padding 和截断机制使所有序列在一个批次中具有相同的长度。
2.2 训练目标与损失计算
SFT 的目标是让模型生成的输出与标注的正确答案(label)尽量接近,与预训练阶段预测下一个词不同,SFT 需要预测整个输出序列。
SFT 的数据包含输入(context)和输出(label),模型需要学习生成整个 label 序列。模型通过计算预测的 token 分布和真实 label 分布的_交叉熵_,优化预测精度。
损失的具体流程
-
前向传播:输入序列和输出序列拼接后,送入模型。模型通过 Transformer 层计算每个位置的 token 概率分布。
-
计算概率分布:模型输出的最后一层会生成一个 logits 矩阵:形状为 [L,V],其中 L 是序列长度,V 是词表大小。对 logits 应用 softmax,得到每个位置的 token 概率分布。
-
计算交叉熵损失:针对输出序列中的每个 token,计算预测概率和真实 label 的交叉熵,将每个 token 的损失取平均作为总体损失。
其中,x 是输入序列,y_j是输出序列中的第 j 个token。
通过 SFT,模型在特定任务的数据上进一步调整,能够更好地理解和完成实际任务需求,如对话生成、问答、机器翻译等。损失的计算方式延续了预训练阶段的逐 token 交叉熵,但加入了输入 - 输出对的监督信息,从而使模型的生成结果更符合任务要求。
三、奖励模型(Reward Model)
奖励模型(Reward Model, RM)是强化学习与人类反馈(RLHF)过程中至关重要的一环,它的作用是评估大语言模型输出的文本质量,给出一个分数,指导模型在后续生成过程中更好地符合人类偏好和需求。
通过与人类标注者进行交互,奖励模型能够提供反馈信号,帮助优化模型的输出,使得生成内容更加自然、真实且符合用户的期望。就像高三毕业班老师专门学习往年高考题型来辅导学生提高成绩。
3.1 为什么需要奖励模型?
在指令微调(SFT)阶段,虽然模型已经被训练并具备一定的语言生成能力,但其输出结果仍然可能不符合人类的偏好,可能存在「幻觉」问题(模型生成的内容不真实或不准确)或者「有害性」问题(输出有害、不合适或令人不安的内容)。
这是因为,SFT 仅通过有限的人工标注数据来微调预训练模型,可能并未完全纠正预训练阶段中潜在的错误知识或不合适的输出。为了进一步提高模型的生成质量,解决这些问题,必须引入奖励模型,利用强化学习进行进一步优化。
3.2 强化学习与奖励模型
强化学习的核心思想是通过奖惩机制来引导模型的学习。 在 RLHF(强化学习与人类反馈)中,奖励模型负责为模型生成的每个响应提供一个奖励分数,帮助模型学习哪些输出符合人类的期望,哪些输出不符合。
奖励模型的训练数据通常来自人工标注的排序数据,标注员会对多个生成的回答进行排名,奖励模型基于这些排名进行训练。
与传统的有监督学习不同,奖励模型并不要求直接对每个输出给出明确的分数,而是通过相对排序的方式对多个输出进行比较,告诉模型哪些输出更好,哪些输出更差。这种相对排序方式能有效减少人工评分时的主观差异,提高标注的一致性和模型的学习效率。
3.3 训练奖励模型
(1)训练数据(人工排序数据)
奖励模型的训练数据通常由人工标注人员对模型输出进行排序生成。在训练过程中,标注人员会根据多个生成回答的质量进行排序,而不是为每个答案打分。具体来说,给定一个问题,标注人员会评估并排序该问题的多个答案,并将这些排序数据作为奖励模型的训练数据。
这种相对排序的方式比直接给每个答案打分更加高效且一致,因为评分会受到标注人员个人主观看法的影响,而相对排序则减少了这种影响,使得多个标注员的标注结果能够更加统一。
数据格式:
`//基于比较的数据格式 { "input": "用户输入的文本", "choices": [ {"text": "候选输出 1", "rank": 1}, {"text": "候选输出 2", "rank": 2} ] } //基于评分的数据格式 { "input": "用户输入的文本", "output": "生成模型的输出文本", "score": 4.5 } `
奖励模型的输入包括:
-
输入文本:用户给定的提示或问题,作为上下文。
-
输出文本:生成模型的候选答案,用于评估质量。
-
上下文和候选文本拼接:奖励模型通常会将 input(上下文)和每个 choice(候选文本)进行拼接,然后输入到模型中。这样,模型就能够理解生成文本与上下文之间的关系,并基于该关系来评估生成文本的质量。
下面是一个简单的例子:
`//原始数据 { "input": "What is the capital of France?", "choices": [ {"text": "The capital of France is Paris.", "rank": 1}, {"text": "The capital of France is Berlin.", "rank": 3}, {"text": "Paris is the capital of France.", "rank": 2} ] } //应输入到模型的数据 [Input] What is the capital of France? [SEP] The capital of France is Paris. [Input] What is the capital of France? [SEP] The capital of France is Berlin. [Input] What is the capital of France? [SEP] Paris is the capital of France. `
(2)上下文建模
奖励模型会基于 Transformer(如 BERT、RoBERTa)等架构对整个拼接后的文本进行编码处理。对于每个候选文本,模型会生成一个上下文感知的表示,其中考虑了 input 和该候选 choice 之间的语义关系。
(3)计算得分或排序
-
回归任务:如果任务是回归类型的(例如预测一个分数),奖励模型会为每个候选文本生成一个预测的质量分数。
-
排序任务:如果任务是基于排序(例如选择哪个候选文本质量更好),奖励模型会通过对所有候选文本进行打分,计算并比较它们的得分,确保高质量文本的得分高于低质量文本。
(4)损失函数
在训练过程中,模型会通过比较候选文本的预测得分与实际的标签(排名或评分)之间的差异来计算损失,并进行反向传播优化:
-
回归任务使用均方误差(MSE)损失来最小化预测分数与真实评分之间的差距。
-
排序任务通常使用对比损失(Contrastive Loss)或者排名损失(例如 Hinge Loss),优化模型以便正确排序候选文本。
3.4 奖励模型的挑战
奖励模型的设计和训练过程中存在一定的挑战,主要体现在以下几个方面:
-
人类偏好的多样性:不同的标注员可能对同一生成结果有不同的看法,这就要求奖励模型能够容忍一定的主观性,并通过排序学习来减少偏差。
-
模型不稳定:由于奖励模型通常较小,训练过程中可能会出现不稳定的情况。为了提高训练的稳定性,奖励模型通常会采取合适的正则化技术和优化方法。
-
数据质量与多样性:为了确保奖励模型的有效性,训练数据需要足够多样化,涵盖不同类型的问题和答案。如果数据质量不高或过于单一,模型可能无法学到有效的评分规则。
四、 基于人类反馈的强化学习(RLHF)
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)是一种将强化学习与人类反馈结合的方法,旨在优化模型的行为和输出,使其更加符合人类的期望。通过引入人类反馈作为奖励信号指导模型更好地理解和满足人类的偏好,生成更自然、更符合人类意图的输出。
就像高考生需要根据模拟考试的反馈进行调整,优化答题策略,这就像是模型在 RLHF 中根据人类反馈不断优化自身行为。
4.1 RLHF框架的核心组件
RLHF框架包含几个关键元素,它们共同协作,确保模型能够根据人类反馈进行优化:
强化学习算法(RL Algorithm):强化学习算法负责训练模型,以优化其行为。在RLHF中,常用的强化学习算法是近端策略优化(Proximal Policy Optimization,PPO)。PPO是一种“on-policy”算法,模型通过当前策略直接学习和更新,而不依赖于过去的经验。通过PPO算法,模型能够根据奖励信号调整策略,最终生成符合期望的输出。
行动(Action):在RLHF框架中,行动是指模型根据给定的提示(prompt)生成的输出文本。每个输出都可以视为模型在执行任务时的选择。行动空间包括词汇表中所有可能的token及其排列组合。
环境(Environment):环境是模型与外界交互的场景,提供模型需要执行任务的状态、动作和对应的奖励。在RLHF中,环境是模型根据提示生成输出并根据反馈调整行为的外部世界。
状态空间(State Space):环境呈现给模型的所有可能状态,通常是输入给模型的提示或上下文信息。
动作空间(Action Space):模型可以执行的所有可能动作,即根据提示生成的所有输出文本。
奖励函数(Reward Function):根据模型的输出,奖励函数为其分配奖励或惩罚。通常,这些奖励由训练好的奖励模型预测,该模型依据人类反馈评估输出质量。
观察(Observation):观察是模型生成输出时接收到的输入提示(prompt)。这些提示作为模型决策和执行任务的基础。**观察空间(Observation Space)**是指可能的输入token序列,即模型处理的提示文本。
奖励机制(Reward):奖励机制是RLHF框架的核心组成部分,负责基于奖励模型的预测分配奖励或惩罚。奖励模型通常通过大量人类反馈数据进行训练,以确保能够准确预测人类对不同输出的偏好。反馈数据通常通过对模型输出的排序、打分集。
4.2 RLHF实战应用:InstructGPT的训练过程
RLHF的实际应用可以通过InstructGPT(ChatGPT的前身)训练过程来说明。InstructGPT的训练过程分为三个阶段:
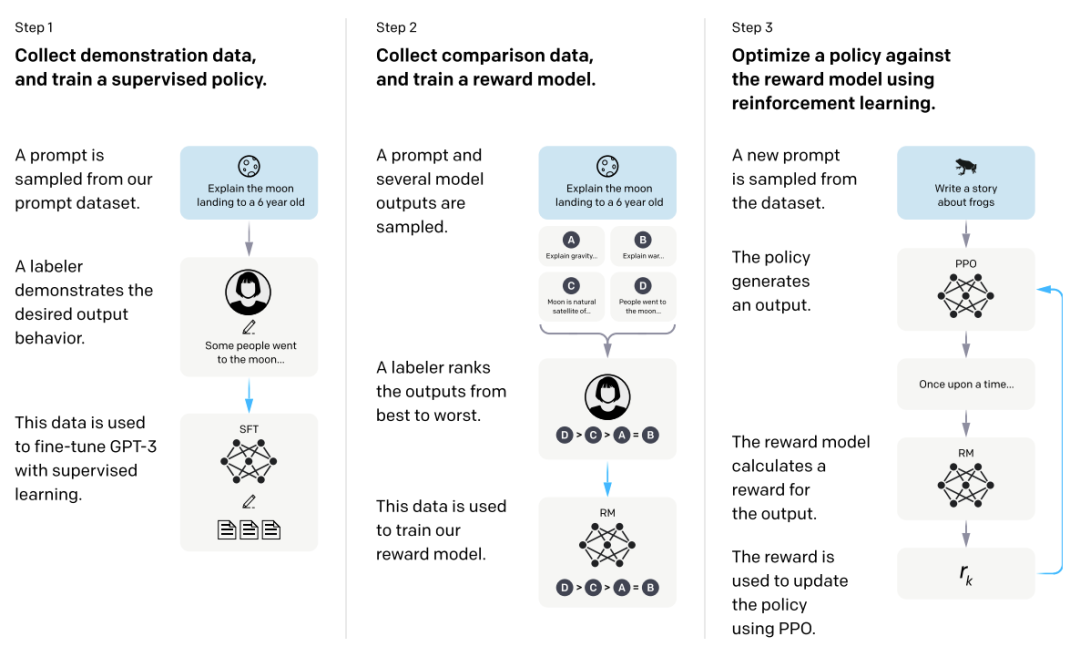
来源与 Training language models to follow instructions with human feedback
首先,从prompt数据集中采样,标注员根据要求为采样的prompt编写答案,形成描述性数据(Demonstration Data)。这些数据用于微调GPT-3模型,训练出一个监督学习模型(Supervised Fine-Tuning, SFT)。通过描述性数据对模型进行有监督微调,使模型能够生成符合基本要求的答案。
接着,从prompt数据库中采样,生成多个模型输出,标注员对这些输出进行打分或排序,形成比较性数据(Comparison Data),并用这些数据训练奖励模型(Reward Modeling, RM)。奖励模型预测不同输出的偏好分数,从而帮助模型生成更高质量的输出。
最后,使用PPO算法(Proximal Policy Optimization)来优化奖励模型。通过从数据集中取样,模型根据监督学习阶段得到的初始化数据进行输出,奖励模型为每个输出打分,最终通过PPO算法调整模型策略,使其生成更符合人类期望的输出。通过RLHF(Reinforcement Learning from Human Feedback)方法,模型能够利用人类反馈逐步提高性能,最终训练出能够生成高质量输出的模型。
通过这三个阶段的训练,InstructGPT能够生成更符合人类需求和偏好的输出,最终形成类似ChatGPT的对话模型。
结语
从零开始训练一个大语言模型是一个复杂且充满挑战的过程,涉及多个环节的设计和优化。通过预训练阶段的语言建模、指令微调、奖励模型的构建以及强化学习与人类反馈(RLHF)等方法,最终可以训练出一个高效、灵活且符合人类需求的大语言模型。在这一过程中,每一个步骤的优化都至关重要,只有精心设计并进行反复实验,才能取得理想的效果。希望本文能够为正在进行LLM研究的朋友们提供有益的思路。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。
 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。

除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









