






你还不知道 2024 年 AI 进步多快?
「2024 年 AI 时间轴」帮你回顾。
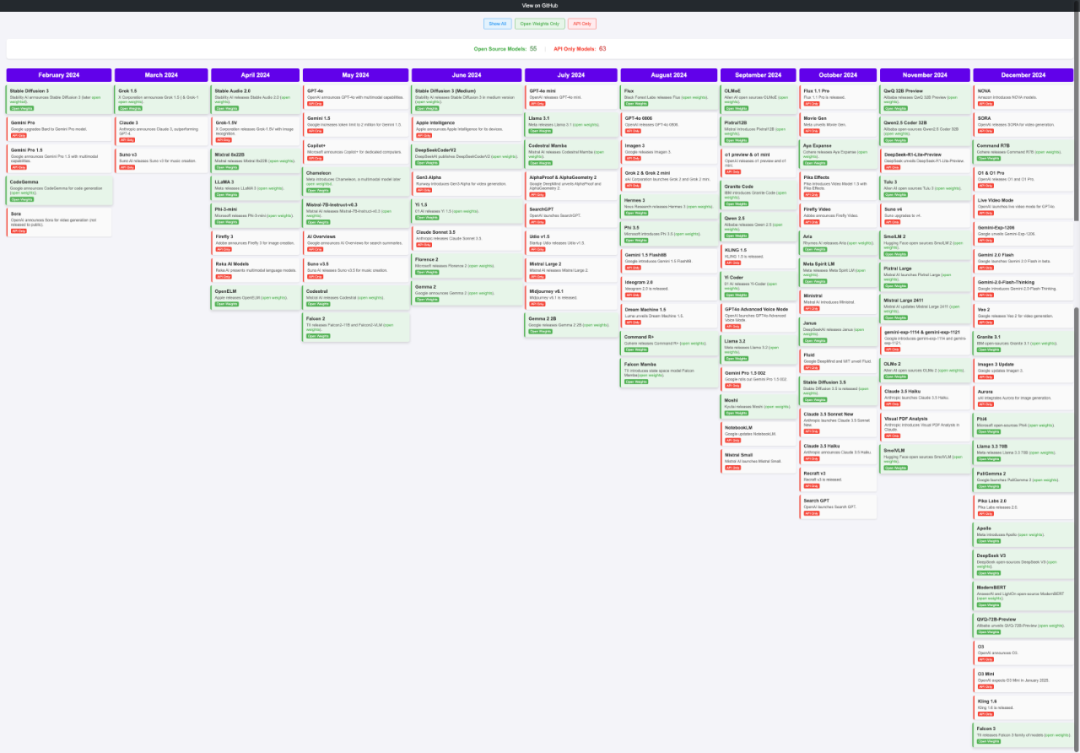
2024 年 AI 时间轴-All
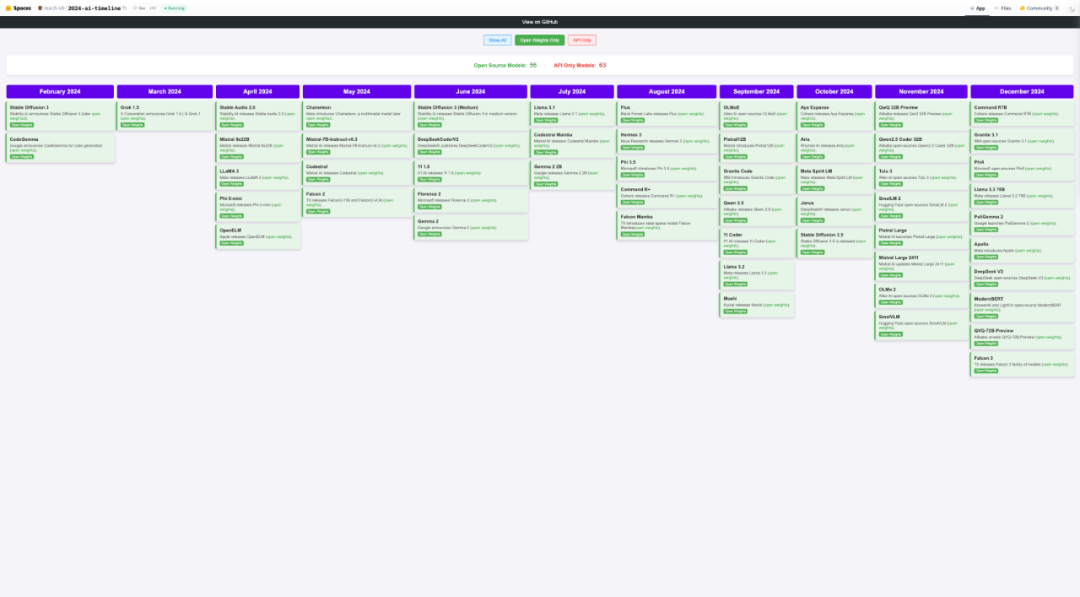
2024 年 AI 时间轴-Open weights only
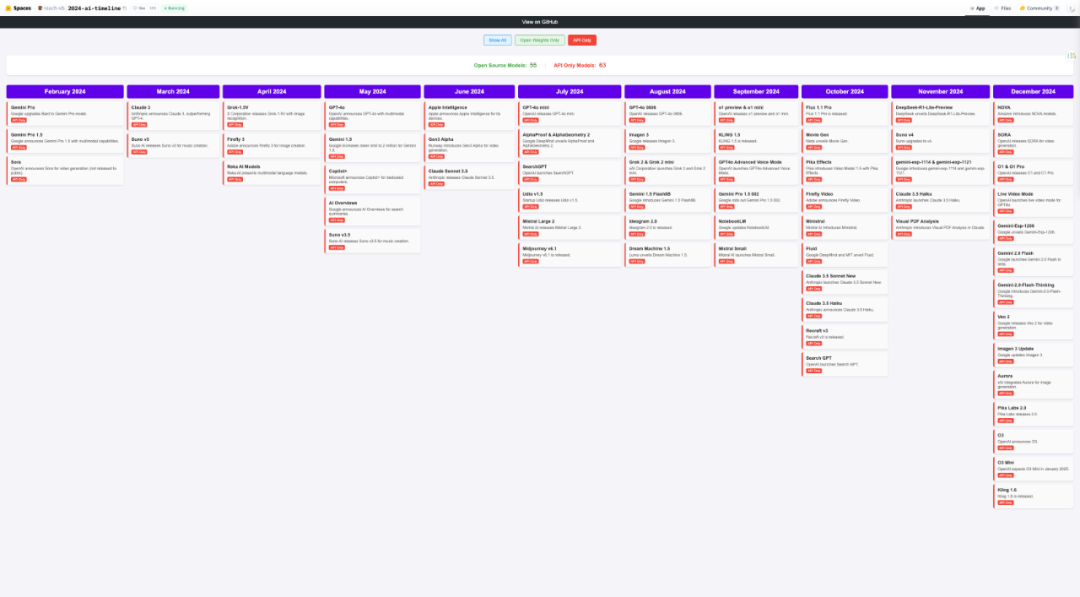
2024 年 AI 时间轴-API only
左右滑动查看更多
来源:https://huggingface.co/spaces/reach-vb/2024-ai-timeline
2024
2月

2024年2月 AI 大事记
Stable Diffusion 3
Stability AI 宣布推出 Stable Diffusion 3(逐步发布到等候名单)。
Gemini Pro
Google 升级了 Bard 中的人工智能聊天功能,基于新的Gemini Pro模型,支持所有可用语言。Google 将“Bard”替换为“Gemini”。
Gemini Pro 1.5
Google 宣布推出Gemini Pro 1.5多模态语言模型,该模型能够解析多达一百万个词,以及分析和理解视频和图像(逐步发布到等候名单)。
Sora
OpenAI 宣布推出可制作长达一分钟的视频的Sora 模型。该模型于12月正式向公众发布。
2024
3月
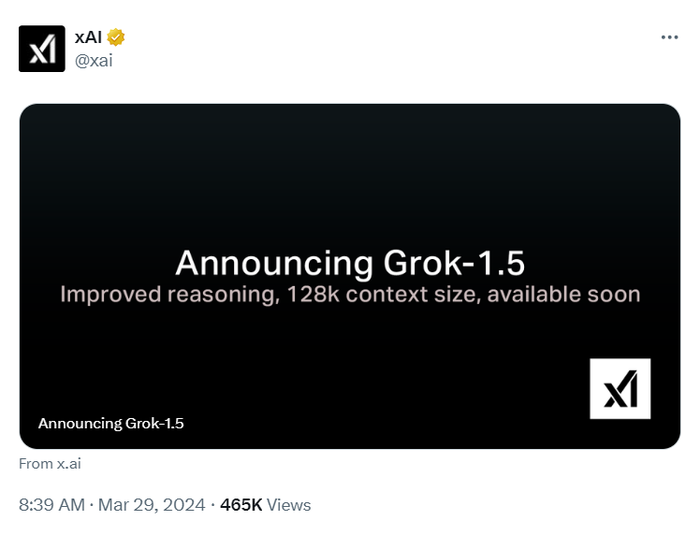
2024年3月 AI 大事记
Grok 1.5
X 公司宣布即将发布Grok 1.5 开源模型。
Claude 3
Anthropic 宣布推出其大型语言模型的新版本Claude 3。该版本部署了 3 种不同大小的模型,其中最大的模型性能优于 GPT-4。
Suno v3
开发音乐创作模型的 Suno AI 向公众发布了Suno v3。
2024
4月

2024年4月 AI 大事记
Stable Audio 2.0
Stability AI 发布音乐创作模型的全新更新——Stable Audio 2.0。
Grok-1.5V
X 公司发布第一代多模态模型Grok-1.5V,该模型集成了高级图像识别功能。在该公司展示的测试中,该模型在图像识别和分析方面的表现优于其他模型。
Mixtral 8x22B
Mistral 公司开源新模型Mixtral 8x22B。这是开源模型中最强大的模型,包含 1410 亿个参数,但采用了更经济的方法。
LLaMA 3
Meta 开源了LLaMA 3 模型,其参数规模分别为 8B 和 70B。在多项基准测试上,LLaMA 3 比 Claude 3 Sonnet 和 Gemini Pro 1.5 表现更好。Meta 预计随后会发布更大的模型,其参数规模将达到 4000 亿甚至更多。
Phi-3-mini
微软开源了Phi-3-mini 模型。该模型的参数精简版本为 3.8B,因此也可以在移动设备上运行,并且具有与 GPT-3.5 类似的功能。
Firefly 3
Adobe 宣布推出全新图像生成模型Firefly 3。
Reka AI Models
初创公司 Reka AI 发布了三款大模型产品,包括 21B 的Reka Flash、7B 的Reka Edge和新一代多模态模型Reka Core。这些模型能够处理视频、音频和图像,其中Reka Core可与 GPT-4 相媲美。
OpenELM
苹果开源OpenELM 系列小型语言模型,共四种变体,参数数量在 2.7 亿到 30 亿之间。
Command R+
CohereAI 开源大模型Command R+,包含 1040 亿参数,特别针对企业级大模型应用场景,如检索增强生成(RAG)和工具使用等,LMSYS得分超过 GPT-4 早期版本。
2024
5月
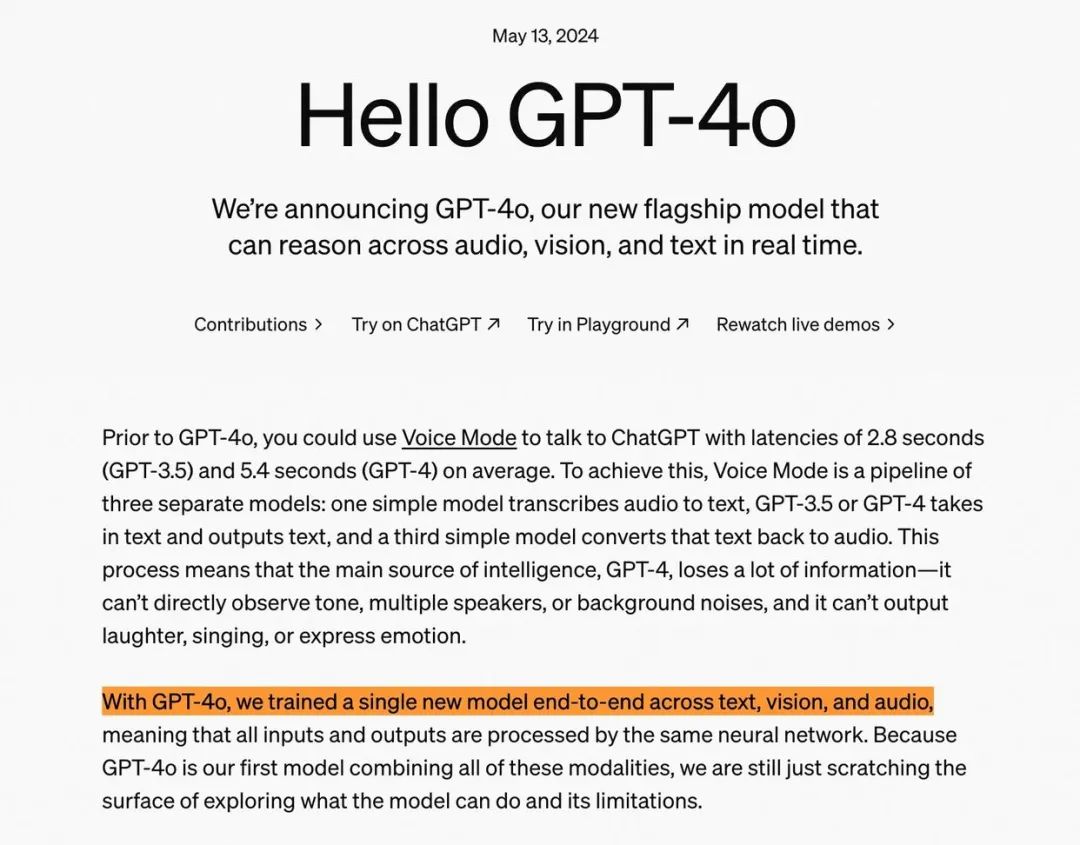
2024年5月 AI 大事记
GPT-4o
OpenAI 宣布推出首款多模态大模型GPT-4o,能同时理解文本、图像和音频,且反应速度非常快,人机交互更加接近人与人的自然交流。该模型的效率是 GPT-4 Turbo 模型的 2 倍,并且对英语以外的语言具有更好的能力。
Gemini 1.5
Google 宣布了大量具备 AI 功能的产品。主要包括:将Gemini 1.5 的 token 上限提高到 200 万;发布更小更快的Gemini Flash 1.5 模型;发布最新的图像生成模型Imagen 3;发布音乐创作模型Music AI;发布视频创作模型Veo。此外,Google 还宣布推出多模态模型Astra,用于实时音频和视频生成。
Copilot+
微软宣布推出专用计算机的Copilot+,可通过用户活动的屏幕截图全面搜索用户历史记录。该公司还开源了尺寸最小、功能强大的 SLM:Phi-3 Small、Phi-3 Medium 和包含图像识别功能的Phi-3 Vision。
Chameleon
Meta 发布了Chameleon,一种可以无缝处理文本和图像的新型多模态模型。
Granite Code
IBM 宣布开源代码模型 Granite Code**,参数范围从 3B 到 34B,适用于代码生成、bug修复及代码解释等任务。该模型在所有模型尺寸和基准测试中整体表现非常出色,通常优于其他开源代码模型。
Mistral-7B-Instruct-v0.3
Mistral AI 开源Mistral-7B-Instruct-v0.3,该版本有重大改进,显示出根据用户指令生成连贯且适合上下文的文本的非凡能力。该模型在实际测试中优于以前的模型,突出了其处理复杂语言任务的增强能力。
AI Overview
谷歌宣布推出AI Overview,旨在对谷歌搜索中的相关信息进行总结。
Suno v3.5
Suno AI 发布更新的音乐创作模型Suno v3.5。
Codestral
Mistral AI 推出首个代码大模型Codestral,专为代码生成任务设计,支持80+编程语言。
Falcon 2
阿布扎比先进技术研究委员会(ATRC)下属的技术创新研究所(TII),发布了新一代的Falcon 2 模型,包含高效易用版本 Falcon 2 11B 和视觉语言模型版本Falcon 2 11B VLM。
Yi-1.5
零一万物推出了非开源的 Yi-Large 模型及Yi-1.5 系列的 6B、9B、34B 开源版本。
2024
6月
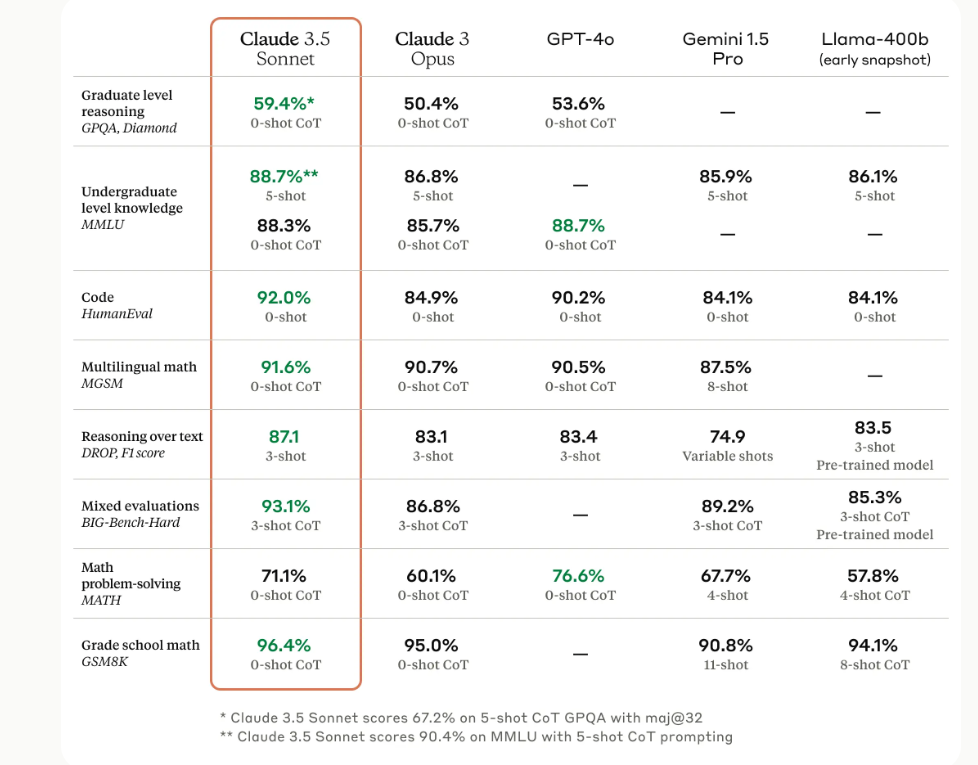
2024年6月 AI 大事记
Stable Diffusion 3(Medium)
Stability AI 发布了开源文生图模型Stable Diffusion 3 Medium,包含 20 亿参数,具有体积小、适合在消费级 PC 和笔记本电脑上运行的优点。
Apple Intelligence
苹果宣布推出Apple Intelligence,这是一套将被集成到公司设备中的人工智能系统,它将结合不同规模的人工智能模型来执行不同的任务。
DeepSeekCoderV2
DeepSeekAI 发布了DeepSeekCoderV2 开源语言模型,该模型具有与 GPT-4、Claude 3 Opus 等模型类似的编码能力。
Gen3 Alpha
Runway 推出了新一代文生视频模型Gen3 Alpha,可创建高精细、多风格、富有艺术指导的视频。
Claude Sonnet 3.5
Anthropic 发布了Claude Sonnet 3.5 模型,该模型比其他模型具有更出色的能力且资源占用率更低。
Florence 2
微软开源了一系列名为Florence 2 的图像识别模型。
Gemma 2
Google 发布新一代最强开源模型Gemma 2,参数大小分别为 9B 和 27B。此外,该公司还向开发人员开放了上下文窗口功能,最多支持 200 万个 token。
2024
7月

2024年7月 AI 大事记
GPT-4o mini
OpenAI 推出了一个「小模型」——GPT-4o mini,以低成本提供高性能。
Llama 3.1
Meta 开源了Llama 3.1,尺寸为 8B、70B 和 405B。Llama 3.1 405B 可与GPT-4o、Claude 3.5 Sonnet 和 Gemini Ultra 等业界头部模型媲美。
Codestral Mamba
Mistral AI 发布三款「小模型」:专为数学推理和科学发现设计的Mathstral(7B);专门用于代码生成的模型Codestral Mamba(7B);与英伟达联合发布的Mistral NeMo(12B),旨在提供性能优越、部署便捷、安全性高的企业级AI功能。
AlphaProof & AlphaGeometry 2
谷歌 DeepMind 发布了两个在今年国际数学奥林匹克(IMO)上获得银牌的全新 AI 系统 ——AlphaProof 和 AlphaGeometry 2。
SearchGPT
OpenAI 推出 AI 搜索工具 SearchGPT,可以实时访问互联网信息,提供更具时效性和更准确的答案(邀请测试阶段)。
Udio v1.5
初创公司 Udio 发布了全新升级的音乐创作模型 Udio v1.5。
Mistral Large 2
Mistral AI 发布了大小为 123B 的大型语言模型 Mistral Large 2,与OpenAI、Meta顶尖模型媲美。
Midjourney v6.1
Midjourney v6.1 发布,人像生成更逼真,图像质量提升显著,增强一致性、纹理、细节理解等。
Gemma 2 2B
Google 开源「小模型」Gemma 2 2B,该模型展现出比大型模型更出色的能力。
Moshi
法国AI实验室 Kyutai 开源Moshi 多模态语音模型,70亿参数规模,使用文本转语音(TTS)技术,200毫秒端到端延迟,支持70多种不同的语言情感和风格。
2024
8月
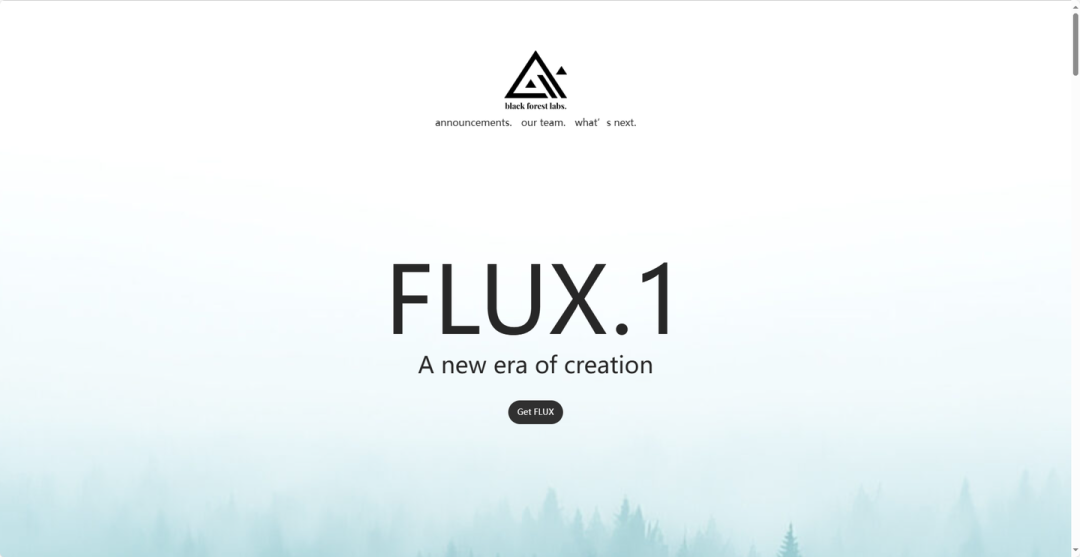
2024年8月 AI 大事记
Flux
“黑森林实验室”开源 12B 文生图大模型Flux,分为Pro、Dev 和 Schnell 三个型号。其中 Pro 模型具备最强性能,Dev 同时兼备了性能和运行速度,Schnell 则是速度最快的模型。该模型性能表现优于同类闭源模型。
GPT-4o 0806
OpenAI 发布了其模型的新版本GPT-4o 0806,在生成有效 JSON 输出方面实现了 100% 的成功率。
Imagen 3
Google 发布图像生成模型Imagen 3。
Grok 2 & Grok 2 mini
xAI 公司发布两个新模型:Grok-2 和 Grok 2 mini,相较上一代在编码、数学、推理方面性能大涨,而且在LMSYS总榜上与 GPT-4o 不相上下。
Hermes 3
初创公司 Nous Research 开源Hermes 3,是首个 Llama 3.1 405B 全参数微调版本。
Phi 3.5
微软开源「小模型」Phi 3.5 系列,包括 mini、MoE 和 vision 三款模型。mini模型轻量级,适合内存受限设备;MoE模型采用混合专家架构,擅长专业学科任务;vision模型支持多模态,适用于图像和视频理解。
Gemini 1.5 Flash8B
谷歌推出了三个新的实验性 AI 模型:Gemini 1.5 Flash8B,Gemini 1.5 Pro Enhanced 和 Gemini 1.5 Flash Update。
Ideogram 2.0
Ideogram 发布文生图模型Ideogram 2.0,在图像生成能力上领先业界,表现优于 Flux Pro 和 DALL·E 3.
Dream Machine 1.5
Luma AI 推出了用于视频创作的Dream Machine 1.5,120秒打造高清视频,具有更好的文本到视频转换、更智能地提示理解、自定义文本渲染和改进图像到视频的功能。
Falcon Mamba
阿布扎比技术创新研究所(TII)开源全球首个通用大型 Mamba 架构模型Falcon Mamba 7B,采用SSLM架构,性能与Transformer模型相媲美,在多个基准测试上的均分超过了 Llama 3.1 8B 和 Mistral 7B。
2024
9月
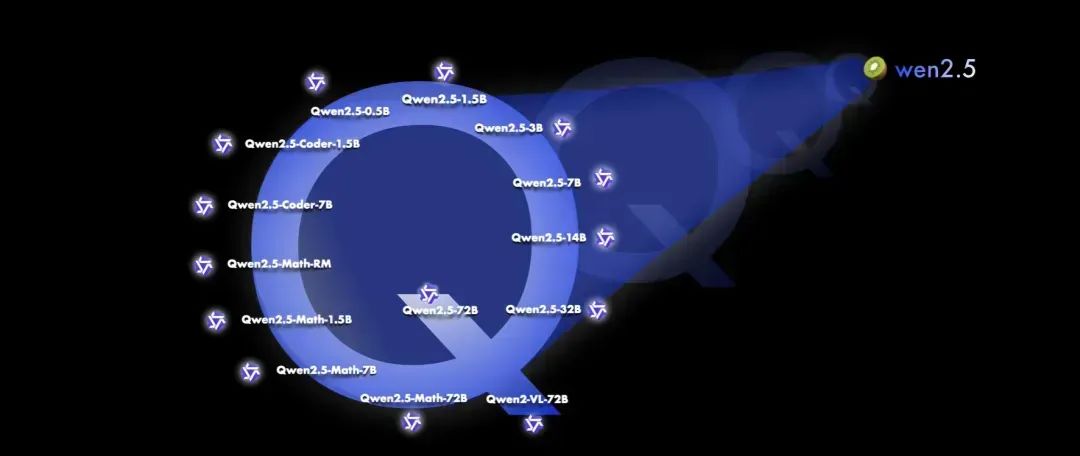
2024年9月 AI 大事记
OLMoE
Allen AI、Contextual AI 等机构推出OLMoE,首个完全开源的混合专家语言模型,在类似大小的模型中具有 SOTA 性能。
Pixtral 12B
Mistral AI 开源首款多模态模型 Pixtral 12B,支持文本和图像处理,性能优异,广泛用于OCR、图像描述等任务。
o1 preview & o1 mini
OpenAI 发布了两款新的 AI 模型:o1 preview 和 o1 mini。这些模型在性能上表现出显著的提升,特别是在需要推理的任务中,包括编码、数学、GPQA等。
Qwen 2.5
阿里巴巴开源 Qwen 2.5 系列模型,大小从 0.5B 到 72B 不等,累计上架超100个,部分性能赶超 GPT-4o,刷新世界纪录。
Kling 1.5
中国快手公司推出视频生成模型 Kling 1.5,提供了增强的图像质量、更自然的运动和更好的即时相关性。
Yi Coder
零一万物开源了 Yi-Coder 系列模型,提供 1.5B 和 9B 两种参数,展现了强大的代码生成能力。
GPT4o Advanced Voice Mod
OpenAI 推出 GPT4o 高级语音模式(GPT4o Advanced Voice Mode)。
Llama 3.2
Meta 推出1B、3B、11B 和 90B 尺寸的 Llama 3.2,首次具备图像识别功能。
Gemini Pro 1.5 002
谷歌升级旗下 Gemini 1.5 AI 模型,推出了 Gemini Pro 1.5 002 和 Gemini Flash 1.5 002,相比较此前版本成本更低、性能更强、响应更快。
NotebookLM
谷歌发布 AI 工具 NotebookLM 的更新版本,用户能够根据自己的内容创建播客。
Mistral Small
Mistral AI 推出企业级小型模型 Mistral Small Instruct 2409 (22B),拥有 220 亿个参数,提供了可在各种平台和环境中部署的经济高效的解决方案。
2024
10月
2024年10月 AI 大事记
Flux 1.1 Pro
黑森林实验室推出 Flux 1.1 Pro,不仅在图像生成速度上是 Flux 1 Pro 的 6 倍,而且生成图片质量更高,更合规、更多样。Flux 1.1 Pro 在视觉逼真度和提示准确性方面表现优异,Elo 分数达到了 1153,超过了 Midjourney 6.1 等其他竞争模型。
Movie Gen
Meta 推出了 Movie Gen,这是一种根据文本输入生成视频、图像和音频的新型 AI 模型,号称最先进的 AI 媒体基础模型。
Aya Expanse
Cohere 宣布推出新的开源 AI 模型 Aya Expanse, 专注于缩小基础模型的语言差距,包括 8B 和 35B 两个版本,在各类多语言任务中表现优异,胜过 Gemma 2、Llama 3.1 及 Ministral 等领先的开源模型。
Pika Effects
Pika 推出新一代AI视频模型 Pika 1.5, 以及新增的一系列物理特效(Pika Effects)。
Firefly Video
Adobe 推出视频创作模型 Firefly Video。
Aria
初创公司 Rhymes AI 开源多模态模型 Aria,在性能上超过了 Pixtral 12B 和 Llama 3.2 11B,并且在各种多模态任务上与最佳的专有模型具有竞争力。
Meta Spirit LM
Meta 开源了 7B 参数的多模态语言模型 Meta Spirit LM的,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。
Ministral
Mistral AI 推出全新 AI 模型 Ministral,有 3B 和 8B 两个版本,专为笔记本电脑、智能手机等边缘设备设计,无需连接云服务器,即可在本地提供AI服务,被称为“全球最好的边缘模型”。
Janus
DeepSeekAI 开源 Janus,这是一种能够识别和生成文本和图像的多模态语言模型。Janus是一种基于自回归的多模态理解与生成统一模型,通过解耦视觉编码提升模型灵活性,缓解单一编码冲突。
Fluid
Google DeepMind 联合麻省理工学院推出了文生图模型 Fluid,在 105 亿个参数的规模上具有业界领先的性能。该模型不仅在生成效果上取得了突破,也挑战了长期以来的行业共识:自回归模型(Autoregressive Models)在文生图领域性能低于扩散模型(Diffusion Models)。
Stable Diffusion 3.5
Stability AI 发布了 Stable Diffusion 3.5,包含三个版本(Large、Large Turbo、Medium), 各版本模型在多个方面表现出色。
Claude 3.5 Sonnet New
Anthropic 推出了升级版 Claude 3.5 Sonnet New 以及新的 Claude 3.5 Haiku 模型,这两款模型在多个领域都有显著提升,特别是在编程领域取得了突破性进展。
Claude 3.5 Haiku
Anthropic 推出了升级版 Claude 3.5 Sonnet New 以及新的 Claude 3.5 Haiku 模型,这两款模型在多个领域都有显著提升,特别是在编程领域取得了突破性进展。Anthropic 还宣布推出一款可通过公开测试版 API 进行 computer use(计算机使用)的实验性功能。
Recraft v3
初创公司 Recraft 发布了最新的文生图模型 Recraft v3,在 Hugging Face 的文本生成图像基准测试中名列第一,获得1172的 ELO 分数,超越了近期的竞争对手 Flux 和 Ideogram。
ChatGPT Search
OpenAI 宣布为 ChatGPT 推出 AI 搜索引擎 ChatGPT Search,无广告,可联网实时对话,付费订阅者先享,覆盖多平台。
2024
11月

2024年11月 AI 大事记
QwQ 32B Preview
阿里巴巴推出首个开源AI推理模型 QwQ 32B Preview,已展现出研究生水平的科学推理能力,在数学和编程方面表现尤为出色,整体推理水平比肩 OpenAI o1。
Qwen2.5 Coder 32B
阿里巴巴开源代码生成模型 Qwen2.5 Coder,共有0.5B、1.5B、3B、7B、14B 和 32B 六个版本,适用于移动端、PC等不同开发环境,在同等尺寸下均取得了模型效果最佳(SOTA)表现。 Qwen2.5 Coder 32B 在多项基准测试中,成为开源模型中性能排名第一,超过 GPT-4o、Claude 3.5 Sonnet 两款闭源模型。
DeepSeek-R1-Lite-Preview
DeepSeek 推出全新 AI 推理模型 DeepSeek-R1-Lite-Preview,在 AIME 和 MATH 基准测试中表现出色,与 OpenAI 的 o1-preview 水平相当。
Tülu 3
艾伦人工智能研究所(Ai2)开源 Tülu 3 模型,包含 8B 和 70B 两个版本(未来还会有 405B 版本),推动后训练技术发展,性能超越 Llama 3.1 Instruct,与 GPT-4o-mini 等闭源模型相媲美。
Suno v4
AI音乐平台 Suno 发布 Suno v4,引入了新功能和性能改进。
SmolLM2
Hugging Face 开源「小模型」SmolLM2,共 135M、360M 和 1.7B 三种参数,适合在智能手机及其他资源有限的边缘设备上部署。SmolLM2-1B 在众多重要的基准测试中,超越了Meta Llama 3.2 1B,特别是在科学推理和常识任务方面表现突出。
Pixtral Large
Mistral AI 开源最新多模态模型 Pixtral Large,有 1240 亿参数,展示出强大的图像理解能力,能够理解文档、图表和自然图像,同时还保持了 Mistral Large 2 优秀的纯文本理解能力。此外,还更新了 Mistral Large 2411 模型。
Mistral Large 2411
Mistral AI 开源最新多模态模型 Pixtral Large,有 1240 亿参数,展示出强大的图像理解能力,能够理解文档、图表和自然图像,同时还保持了 Mistral Large 2 优秀的纯文本理解能力。此外,还更新了 Mistral Large 2411 模型。
gemini-exp-1114 & gemini-exp-1121
谷歌推出了两个实验模型 gemini-exp-1114 和 gemini-exp-1121,目前以增强的性能引领聊天机器人领域。gemini-exp-1114 亮点主要在于质量改进,而最新的 gemini-exp-1121重点改进了编码、推理和视觉能力。
OLMo 2
艾伦人工智能研究所(Ai2)开源新语言模型 OLMo2,包括了 7B 和 13B 两个参数版本,在性能上已与 Llama 3.1、Qwen 2.5 等开源模型竞争。
Claude 3.5 Haiku
Anthropic 发布最新 Claude 3.5 Haiku,在多个关键基准测试中表现优异,且性价比竞争力强。 此外, Anthropic 在最新的桌面版客户端 Claude 中推出 Visual PDF Analysis 新功能。
Visual PDF Analysis
Anthropic 发布最新 Claude 3.5 Haiku,在多个关键基准测试中表现优异,且性价比竞争力强。 此外, Anthropic 在最新的桌面版客户端 Claude 中推出 Visual PDF Analysis 新功能。
SmolVLM
Hugging Face 开源AI视觉语言模型 SmolVLM,提供三个版本(Base、Synthetic 和 Instruct),包含 20亿 参数,用于设备端推理,凭借其极低的内存占用在同类模型中脱颖而出。
2024
12月

2024年12月 AI 大事记
NOVA
亚马逊推出名为 NOVA 的新系列模型,专为文本、图像和视频处理而设计。
Sora
OpenAI 发布了视频生成模型 Sora,以及面向高级订阅者的完整版 o1 和 o1 Pro。此外,该公司还推出了 GPT4o 的 Live Video Mode 新功能。
Command R7B
初创公司 Cohere 推出 Command R7B,是其R系列LLM中最小的模型,面向注重速度、成本效率和灵活性的企业,可在低端设备运行。Command R7B 在数学、编码等任务上优于同类模型,在与RAG、工具使用和 AI 代理相关的任务中也表现出色。
o1 & o1 Pro
OpenAI 发布了视频生成模型 Sora,以及面向高级订阅者的完整版 o1 和 o1 Pro。此外,该公司还推出了 GPT4o 的 Live Video Mode 新功能。
Live Video Mode
OpenAI 发布了视频生成模型 Sora,以及面向高级订阅者的完整版 o1 和 o1 Pro。此外,该公司还推出了 GPT4o 的 Live Video Mode 新功能。
Gemini-Exp-1206
谷歌发布实验模型 Gemini-Exp-1206,该模型在 Chatbot Arena 聊天机器人排行榜上名列第一。
Gemini 2.0 Flash
谷歌发布了 Gemini 2.0 Flash 测试版。该模型在基准测试中处于领先地位,性能优于上一版本 Gemini Pro 1.5。此外,Google 还推出了实时语音和视频模式,并宣布该模型内置了图像生成功能。
Gemini-2.0-Flash-Thinking
谷歌发布了基于 Gemini 2.0 Flash 的“推理”模型 Gemini-2.0-Flash-Thinking,斩获 Chatbot Arena 聊天机器人排行榜第二名。
Veo 2
谷歌推出了 Veo 2,这是一款测试版视频生成模型,能够生成长达两分钟的 4K 视频。该模型在人工评估中的表现优于 SORA 。此外,谷歌还更新了 Imagen 3,提高了图像质量和真实感。
Granite 3.1
IBM 开源 Granite 3.1,具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。
Imagen 3 Update
谷歌发布 Veo 2 视频生成模型之外,还增强了 Imagen 3 文生图模型,为用户带来更多花样的艺术风格。
Aurora
xAI 宣布 Grok 集成了首款完全自研图像生成模型 Aurora,这是一个自回归模型,采用了MoE架构,多个场景下均表现出色。
Phi4
微软开源「小模型」 Phi4,仅140亿参数,成为年度SLM之王,展示其尺寸小而功能强大的特点。
Llama 3.3 70B
Meta 发布了 Llama 3.3 70B,该模型的性能与 Llama 3.1 405B 相当。
PaliGemma 2
谷歌推出视觉语言模型 PaliGemma 2,提供3B、10B、28B三种参数规模,与现有的 Gemma 2 模型相集成。
Pika 2.0
Pika Labs 发布AI视频生成工具 Pika 2.0,带来多项重大更新。
Apollo
Meta和斯坦福大学团队联合推出开源多模态大模型 Apollo,共 1.5B、3B、7B三种尺寸,旨在显著提升机器对视频内容的理解能力。
Deepseek V3
Deepseek 开源了 Deepseek V3,一个具有 671B 参数的模型,在多个基准测试中超越了闭源 SOTA 模型。
ModernBERT
AnswerAI 和 LightOn 联合发布了开源语言模型 ModernBERT,这是对谷歌 BERT 的重大升级。ModernBERT 比其前身快四倍,同时使用更少的内存,在处理速度、效率和质量上都有了显著提升。
QVQ-72B-Preview
阿里巴巴开源视觉推理模型 QVQ-72B-Preview,在解决数学、物理、科学等领域的复杂推理问题上表现尤为突出。在多项基准测试中,该模型与OpenAI o1、Claude3.5 Sonnet等模型相当,性能达到SOTA级别。
o3
OpenAI 推出突破性的 AI 模型 o3,其在ARC-AGI基准测试中达到 87.5%,在Frontier Math Benchmark 中达到 25.2%(而之前的模型不到 2%),在博士级科学问题中达到 87.7%。
o3 mini
OpenAI 预计 2025 年 1 月将推出一款经济实惠的版本 o3 mini,其性能与 o1 相似,同时速度和效率有所提升。
Kling 1.6
快手公司发布视频生成模型 Kling 1.6,性能显著提升。
Falcon 3
阿布扎比技术创新研究院(TII)发布新一代开源AI模型 Falcon3,共推出四种规格:1B、3B、7B和10B,在相关基准测试中的表现优于 Mistral、阿里巴巴、Meta 和谷歌等类似规模的竞争对手。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









