






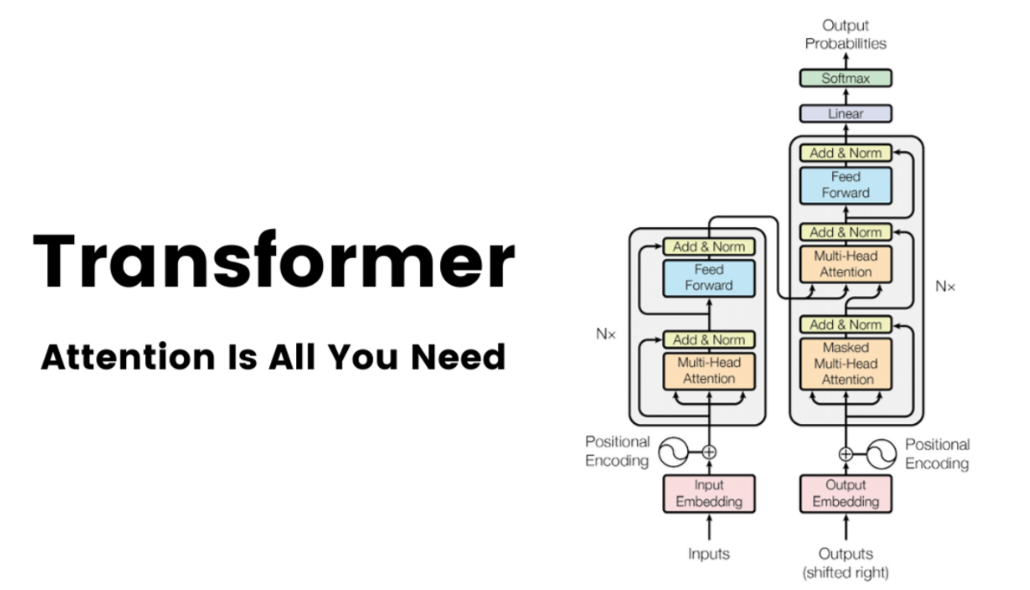
Transformer
Transformer模型的训练过程是一个复杂但高度优化的流程,旨在通过合理的数据选择、硬件配置、训练计划、优化器使用和正则化策略来训练出高性能的模型。
一、合理的数据选择
训练数据集: 训练数据作为Transformer模型训练的基础,扮演着至关重要的角色。这些数据集通常包含大量的、经过精心标注的样本,这些样本覆盖了模型在特定任务中需要学习和识别的各种语言现象、结构和模式。
在自然语言处理(NLP)领域,常用的数据集包括WMT(Workshop on Machine Translation)系列的翻译数据集,如WMT 2014英德和英法数据集。
- WMT 2014英德数据集: 在标准的WMT 2014英德数据集上进行了训练,该数据集包含约450万个句子对。句子使用字节对编码(Byte-Pair Encoding,BPE)进行编码,这样源语言和目标语言共享一个约37000个标记的词汇表。
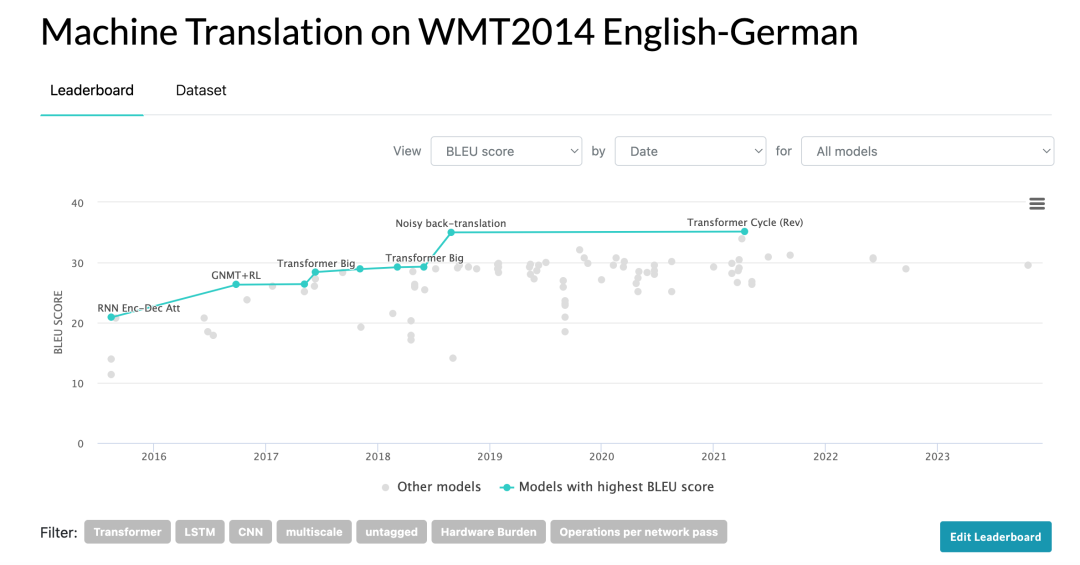
WMT 2014英德数据
- W MT 2014英法数据集: 对于英法数据集,使用了更大的WMT 2014英法数据集,包含3600万个句子,并将标记分为一个32000个词片段的词汇表。句子对根据序列长度的近似值进行批处理。每个训练批次包含一组句子对,这些句子对大约包含25000个源语言标记和25000个目标语言标记。
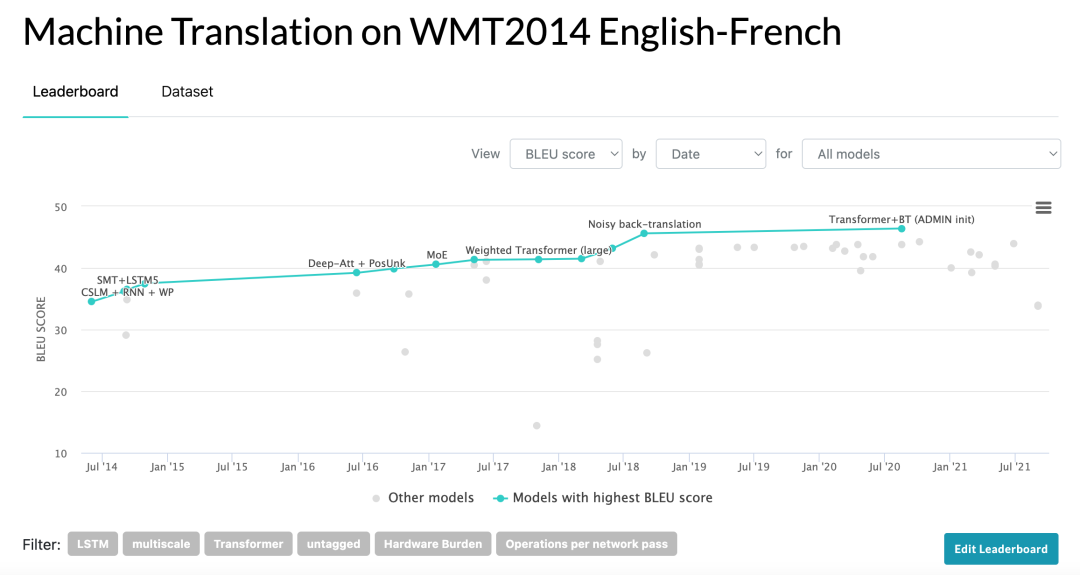
WMT 2014英法数据
WMT 2014英德和英法数据集在用于训练Transformer模型之前,需要进行一系列的数据预处理步骤。 这些步骤包括文本清洗、分词与标记化、构建词汇表、 子词单元生成(如BPE)、数值化以及添加特殊标记。
一、数据下载与解压
-
下载数据集:首先,从WMT官方网站或相关资源中下载WMT 2014英德和英法数据集。这些数据集通常包括训练集、验证集和测试集。
-
解压数据集:将下载的数据集文件(如.tgz或.tar格式)解压到指定的目录中,以便进行后续处理。
二、文本清洗
-
去除无关信息:从文本中去除HTML标签、特殊字符、URL链接等与翻译任务无关的信息。
-
纠正拼写和语法错误:虽然这不是预处理的主要任务,但在某些情况下,可能需要纠正文本中的拼写和语法错误,以提高数据质量。
三、分词与标记化
-
分词:将文本分割成更小的单元,如单词或子词。对于英语和德语,由于单词之间有空格分隔,分词相对简单。但对于其他语言,可能需要使用专门的分词工具。
-
标记化:将分词后的文本转换为模型可以处理的标记(tokens)。这通常涉及将单词或子词转换为唯一的标识符(如整数ID)。
四、构建词汇表
-
提取唯一标记:从训练数据中提取所有唯一的标记(如单词或子词)。
-
构建词汇表:将提取的标记组织成一个词汇表,并为其分配唯一的索引(ID)。词汇表的大小和构成对模型的性能有一定影响。
五、子词单元生成(如BPE)
-
使用子词单元技术:如Byte Pair Encoding(BPE),将单词分割成更小的子词单元。这有助于处理未登录词(OOV)问题,并提高模型的泛化能力。
-
生成BPE词汇表:使用BPE算法对训练数据进行处理,生成包含子词单元的词汇表。
六、数值化
- 文本转ID:将文本数据中的每个标记(或子词单元)替换为其在词汇表中的索引(ID)。
七、添加特殊标记
-
开始和结束标记:在序列的开始和结束处添加特殊的标记,如
<s>和</s>,以指示句子的边界。 -
其他特殊标记:根据需要添加其他特殊标记,如填充标记(
<pad>)或分隔标记(<sep>)。
__二、_硬件配置___
在配备高性能NVIDIA P100 GPU的机器上训练Transformer模型的效率是非常高的。无论是基础模型还是大型模型,都能够在合理的时间内完成训练,这得益于P100 GPU的强大计算能力和高带宽内存。
基础模型训练:
-
硬件环境: 8个NVIDIA P100 GPU,每个GPU具有强大的并行计算能力和高带宽内存。
-
训练时间: 每步训练大约需要0.4秒,总共训练100,000步,因此总体训练时间约为12小时(0.4秒/步 * 100,000步 = 40,000秒 ≈ 11.11小时,四舍五入为12小时)。
-
性能特点: 基础模型由于参数较少,计算量相对较低,因此能够在相对较短的时间内完成训练。
大型模型训练:
-
硬件环境: 同样使用8个NVIDIA P100 GPU,但由于模型规模增大,每步训练的计算量显著增加。
-
训练时间: 每步训练需要1.0秒,总共训练300,000步,因此总体训练时间约为3.5天(1.0秒/步 * 300,000步 = 300,000秒 ≈ 3.47天,四舍五入为3.5天)。
-
性能特点: 大型模型由于参数众多,计算复杂度高,需要更长的训练时间。然而,得益于P100 GPU的强大计算能力,这种训练仍然可以在合理的时间内完成。
三、训练计划
模型构建与训练使用深度学习框架根据预设超参数建立模型并训练以提取数据特征,而模型评估与优化则是通过测试集验证模型性能并据此调整模型以提高其泛化能力。
模型训练
模型构建与训练:
- 模型构建:
-
根据论文或实验需求选择合适的模型架构,如Transformer。
-
设置超参数,如学习率、批次大小、优化器(Adam、SGD等)、训练轮次等。
-
使用深度学习框架提供的API构建模型。
- 训练过程:
-
加载训练数据,并进行批次处理。
-
使用训练数据对模型进行迭代训练,每个批次计算损失函数并更新模型权重。
-
在每个训练周期(epoch)结束时,使用验证集评估模型性能,并记录关键指标(如准确率、损失值)。
- 模型保存:
-
在训练过程中定期保存模型权重和参数,以便在需要时恢复训练或进行模型评估。
-
保存最佳模型(即验证集上性能最好的模型)。
模型评估与优化:
- 模型评估:
-
使用测试集对训练好的模型进行评估,确保评估过程与训练过程完全独立。
-
计算并记录关键性能指标,如准确率、召回率、F1分数等。
- 模型优化:
-
根据评估结果调整超参数,如学习率、批次大小等。
-
尝试不同的模型架构或改进现有架构。
-
使用正则化、dropout等技术防止过拟合。
-
应用集成学习方法(如模型平均、模型融合)提高整体性能。
- 结果分析:
-
分析模型在不同数据集上的表现,识别潜在的偏差或不足。
-
根据业务需求调整评估指标或评估方法。
** 四、 优化器使用_**
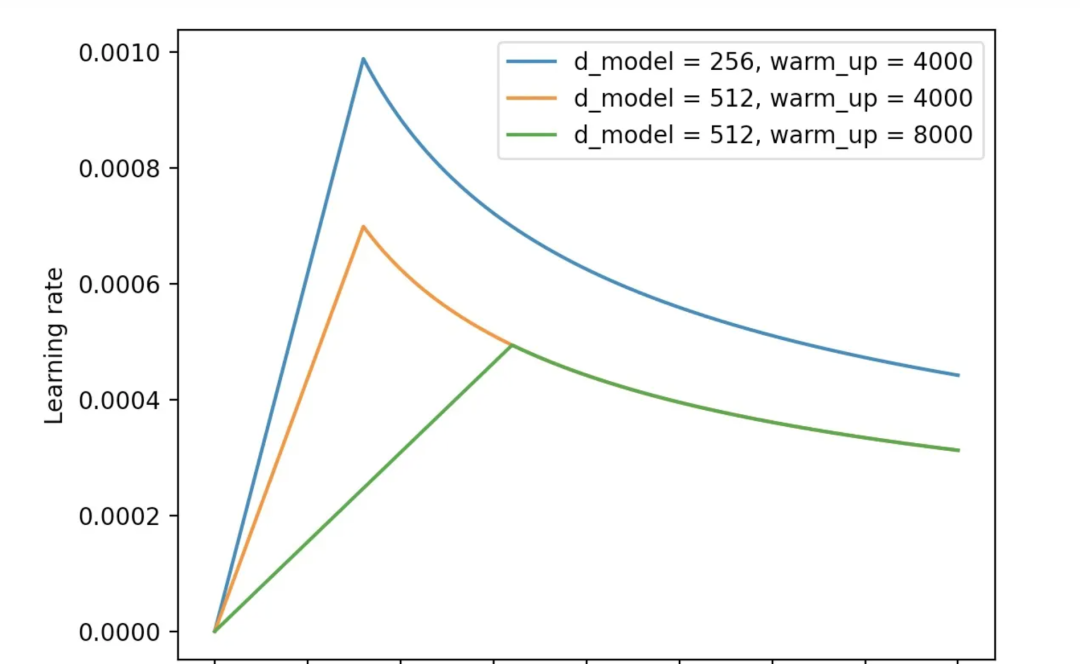
Transformer使用了Adam优化器,并设置其超参数为β1=0.9,β2=0.98,以及ϵ=10−9。在学习过程中,根据以下公式调整学习率:

这种动态调整的方法通常基于训练过程中的一些指标或条件,如训练轮数、验证集性能等,来实时调整学习率的大小。根据公式(1)的计算方式,模型在训练过程中学习率的变化如图所示:
Adam优化器:Adam(Adaptive Moment Estimation)优化器是一种结合了AdaGrad和RMSProp优点的高效优化算法******,它广******泛应用于深度学习模型的训练中。
Adam优化器: Adam(Adaptive Moment Estimation)优化器是一种结合了AdaGrad和RMSProp优点的高效优化算法,它广泛应用于深度学习模型的训练中。
-
自适应性: 能够自适应地调整每个参数的学习率,从而更好地适应不同参数之间的差异。
-
有效性: 使用了动量和二阶动量信息来更新参数,使模型训练更加平稳和快速。
-
鲁棒性: 对于噪声较多或稀疏数据集也具有很好的鲁棒性。
-
参数范围不变性: 能够保持对参数范围变化的不敏感性,在实际应用中比其他优化算法更为稳定。
五、正则化策略____
Transformer模型使用了多种正则化方法来减少过拟合现象,提高模型的泛化能力。三种正则化方法如下:
-
Layer Normalization: 对每个子层的输出进行归一化处理,使得每个神经元输入的分布更加稳定,这有利于模型的训练和泛化性能。
-
Dropout: 在训练过程中随机地将一部分神经元的输出设置为0,从而减少不同神经元之间的依赖关系,避免模型过拟合。这种方法可以防止模型过分依赖于某些特定输入,从而提高模型的泛化能力。
-
注意力机制中的随机Drop Key: 在注意力计算阶段,通过随机drop部分Key来鼓励网络捕获目标对象的全局信息,从而避免了由过于聚焦局部信息所引发的模型偏置问题,进而提升了模型的精度。这种方法通常被用于基于Transformer的视觉类算法中。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}