






在 RAG 系列之三:文本切分中介绍了如何将文本切分成更小的语义单元,接下来便是将拆分的文本块进行向量化。
什么是文本向量化?
文本向量化就是将文本数据转成数字数据,例如:将文本 It was the best of times, it was the worst of times. 转成 [0, 1, 0, 2, 2, 2, 2, 2, 0, 1]。
为什么要进行文本向量化?
因为计算机只能处理数字数据,而不能直接处理文本数据。为了让计算机高效地处理文本数据,只有将文本数据转成数字数据。文本向量化在人类语言和计算机之间架起了一座桥梁,使得计算机可以进行语言层面的操作。接下来介绍一些文本向量化的方法。
词袋模型
词袋模型是一种基于词频的文本向量化方法。它将文本数据表示为一个向量,其中每个元素表示一个单词在文本中出现的频率。
构建一个词袋模型,分为如下两个步骤:
-
构建一个包含所有单词的词汇表。
-
统计文本中单词出现的频率。假设有两个文本,内容为:
It was the best of times, it was the worst of times.
it was the age of wisdom, it was the age of foolishness.
首先,构建一个词汇表,它包含了上面文本中的所有单词(忽略大小写和标点符号)。构建的词汇表内容如下:

然后,统计文本中每个单词的出现频率,文本向量的每个元素便是每个单词出现的频率。文本 It was the best of times, it was the worst of times. 中每个单词出现的频率如下:
| 单词 | 频率 |
|---|---|
| age | 0 |
| best | 1 |
| foolishness | 0 |
| it | 2 |
| of | 2 |
| the | 2 |
| times | 2 |
| was | 2 |
| wisdom | 0 |
| worst | 1 |
由此,文本所对应的向量为:

文本 it was the age of wisdom, it was the age of foolishness. 中每个单词出现的频率如下:
| 单词 | 频率 |
|---|---|
| age | 2 |
| best | 0 |
| foolishness | 1 |
| it | 2 |
| of | 2 |
| the | 2 |
| times | 0 |
| was | 2 |
| wisdom | 1 |
| worst | 0 |
由此,文本所对对应的向量为:

优点
-
词袋模型的概念和实现都非常简单,只需要统计词频。
-
由于模型只是简单的计数,计算效率高,尤其适合大规模文本数据的处理。
缺点
-
词袋模型不考虑词与词之间的顺序,这在一些需要上下文理解的任务中可能表现不佳。
-
词袋模型会生成一个高维稀疏向量,尤其是在处理大规模词汇表时,导致存储和计算资源消耗大。
-
当处理多种语言或非常大的文本语料库时,词汇表可能会变得非常庞大,增加计算复杂度。
-
只考虑了单词在当前文本中出现的频率而没有考虑在整个文档集合中出现的频率。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

TF-IDF 模型
TF-IDF,全称为 “Term Frequency-Inverse Document Frequency”(词频-逆文档频率),它的主要目的是评估一个词在一个文档集合中的重要性。TF-IDF 通过结合词频和逆文档频率来衡量一个词的权重。
词频 (TF,Term Frequency)
-
词频是指一个特定词在一个文档中出现的次数。TF 反映了词在文档中出现的频率,词频越高,词在该文档中的重要性可能越大。
-
计算公式:TF(t,d) = (词 t 在文档 d 中出现的次数) / (文档 d 中总词数)。
逆文档频率 (IDF,Inverse Document Frequency)
-
逆文档频率衡量的是一个词在整个文档集合中的重要性。一个词如果在很多文档中都出现,那么它的区分能力就不强,IDF 值就低。反之,出现较少的词则有较高的区分能力,IDF 值就高。
-
计算公式:IDF(t,D) = ln(总文档数 N / 包含词 t 的文档数 df(t)),其中 N 是文档总数,df(t) 是包含词 t 的文档数。
TF-IDF
-
TF-IDF 是词频和逆文档频率的乘积,用于衡量一个词在文档中的重要性,同时减少常见词的影响。
-
计算公式:TF-IDF(t,d,D) = TF(t,d) * IDF(t,D)。
我们使用词袋模型中的例子来展示 TF-IDF 的整个计算过程。
计算词频
由于在词袋模型中已经计算了每个单词的频率,所以复用上面的结果,文本 It was the best of times, it was the worst of times. 中每个单词出现的频率以及计算出的相应词频如下:
| 单词 | 频率 | 总词数 | 词频 |
|---|---|---|---|
| age | 0 | 12 | 0/12 = 0 |
| best | 1 | 12 | 1/12 = 0.083 |
| foolishness | 0 | 12 | 0/12 = 0 |
| it | 2 | 12 | 2/12 = 0.167 |
| of | 2 | 12 | 2/12 = 0.167 |
| the | 2 | 12 | 2/12 = 0.167 |
| times | 2 | 12 | 2/12 = 0.167 |
| was | 2 | 12 | 2/12 = 0.167 |
| wisdom | 0 | 12 | 0/12 = 0 |
| worst | 1 | 12 | 1/12 = 0.083 |
文本 it was the age of wisdom, it was the age of foolishness. 中每个单词出现的频率以及计算出的相应词频如下:
| 单词 | 频率 | 总词数 | 词频 |
|---|---|---|---|
| age | 2 | 12 | 2/12 = 0.167 |
| best | 0 | 12 | 0/12 = 0 |
| foolishness | 1 | 12 | 1/12 = 0.083 |
| it | 2 | 12 | 2/12 = 0.167 |
| of | 2 | 12 | 2/12 = 0.167 |
| the | 2 | 12 | 2/12 = 0.167 |
| times | 0 | 12 | 0/12 = 0 |
| was | 2 | 12 | 2/12 = 0.167 |
| wisdom | 1 | 12 | 1/12 = 0.083 |
| worst | 0 | 12 | 0/12 = 0 |
计算逆文档频率
逆文档频率的计算结果如下:
| 单词 | 总文档数 | 包含单词的文档数 | 逆文档频率 |
|---|---|---|---|
| age | 2 | 1 | ln(2/1) = 0.693 |
| best | 2 | 1 | ln(2/1) = 0.693 |
| foolishness | 2 | 1 | ln(2/1) = 0.693 |
| it | 2 | 2 | ln(2/2) = 0 |
| of | 2 | 2 | ln(2/2) = 0 |
| the | 2 | 2 | ln(2/2) = 0 |
| times | 2 | 1 | ln(2/1) = 0.693 |
| was | 2 | 2 | ln(2/2) = 0 |
| wisdom | 2 | 1 | ln(2/1) = 0.693 |
| worst | 2 | 1 | ln(2/1) = 0.693 |
计算 TF-IDF
文本 It was the best of times, it was the worst of times. 的计算结果如下:
| 单词 | 频率 | 总词数 | 词频 | 逆文档频率 | TF-IDF |
|---|---|---|---|---|---|
| age | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
| best | 1 | 12 | 1/12 = 0.083 | 0.693 | 0.083 * 0.693 = 0.058 |
| foolishness | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
| it | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| of | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| the | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| times | 2 | 12 | 2/12 = 0.167 | 0.693 | 0.167 * 0.693 = 0.115 |
| was | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| wisdom | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
| worst | 1 | 12 | 1/12 = 0.083 | 0.693 | 0.083 * 0.693 = 0.058 |
文本 it was the age of wisdom, it was the age of foolishness. 的计算结果如下:
| 单词 | 频率 | 总词数 | 词频 | 逆文档频率 | TF-IDF |
|---|---|---|---|---|---|
| age | 2 | 12 | 2/12 = 0.167 | 0.693 | 0.167 * 0.693 = 0.115 |
| best | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
| foolishness | 1 | 12 | 1/12 = 0.083 | 0.693 | 0.083 * 0.693 = 0.058 |
| it | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| of | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| the | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| times | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
| was | 2 | 12 | 2/12 = 0.167 | 0 | 0.167 * 0 = 0 |
| wisdom | 1 | 12 | 1/12 = 0.083 | 0.693 | 0.083 * 0.693 = 0.058 |
| worst | 0 | 12 | 0/12 = 0 | 0.693 | 0 * 0.693 = 0 |
TF-IDF 的优缺点
优点
-
简单易懂且计算高效。
-
在文本特征提取中效果显著。
缺点
-
不能捕捉词语之间的语义关系。
-
对长文档可能不够有效,因为 TF 值会偏高。
-
对于很常见的词(比如“the”、“and”),即使经过 IDF 调整,仍可能会有较高权重。
Word2Vec
上面的词袋模型和 TF-IDF 都是单纯地计算单词的频率,而没有考虑单词与单词之间的顺序,因此不能捕获语义信息。Word2Vec 是一种基于神经网络的文本向量化方法。它使用神经网络来学习单词的向量表示形式,使得具有相似含义的单词在向量空间中的距离更近。Word2Vec 包括 CBOW(Continuous Bag-of-Words)和 Skip-gram 两种模型。CBOW 模型根据上下文单词预测目标单词,而 Skip-gram 模型根据目标单词预测上下文单词。这种方法可以捕捉单词之间的语义关系,但需要大量的语料库来训练模型。下面以 Skip-gram 模型为例来简单介绍模型的训练过程。
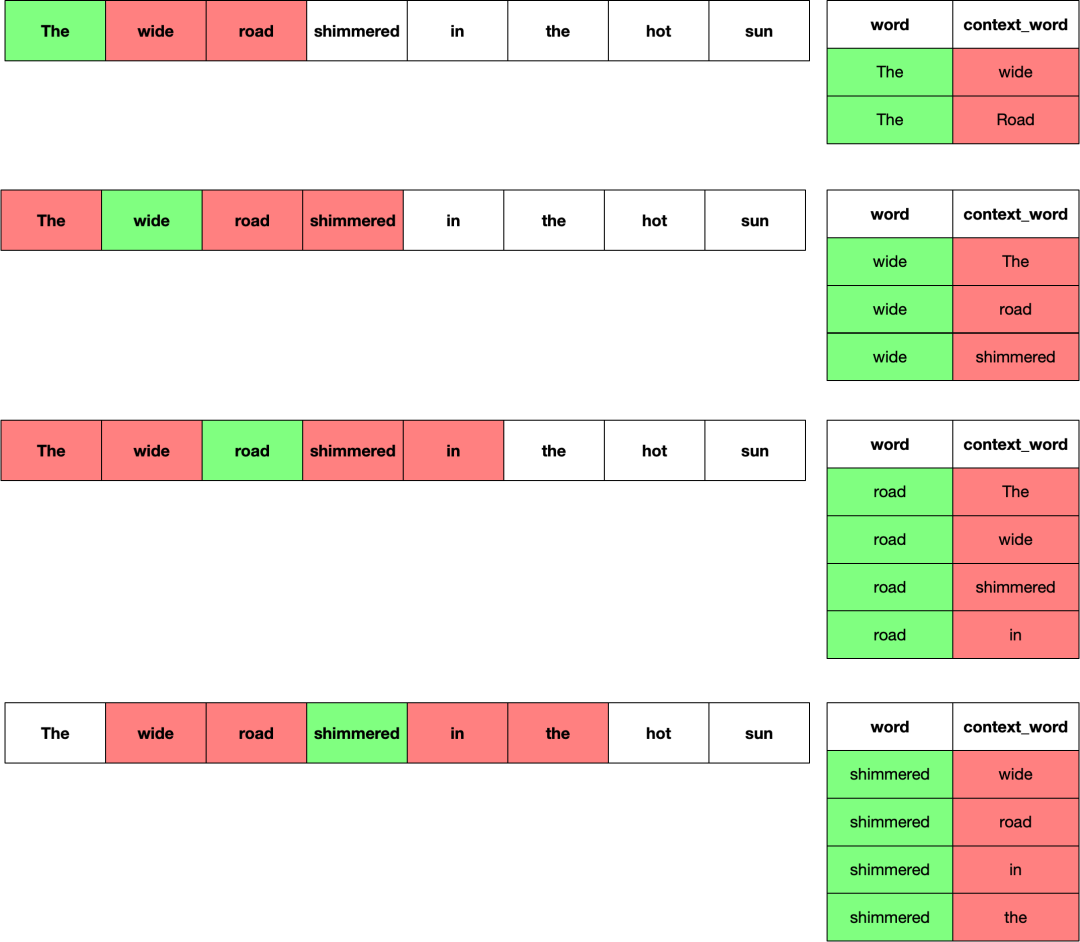
假设训练的文本为:The wide road shimmered in the hot sun.,上下文的窗口大小为 2。于是,在窗口内的单词为正样本,不在窗口内的单词为负样本,假设每个正样本所对应的负样本的个数为 4 个。生成正样本的过程如下,标绿的为当前单词,标红的为窗口内的单词,也就是正样本。
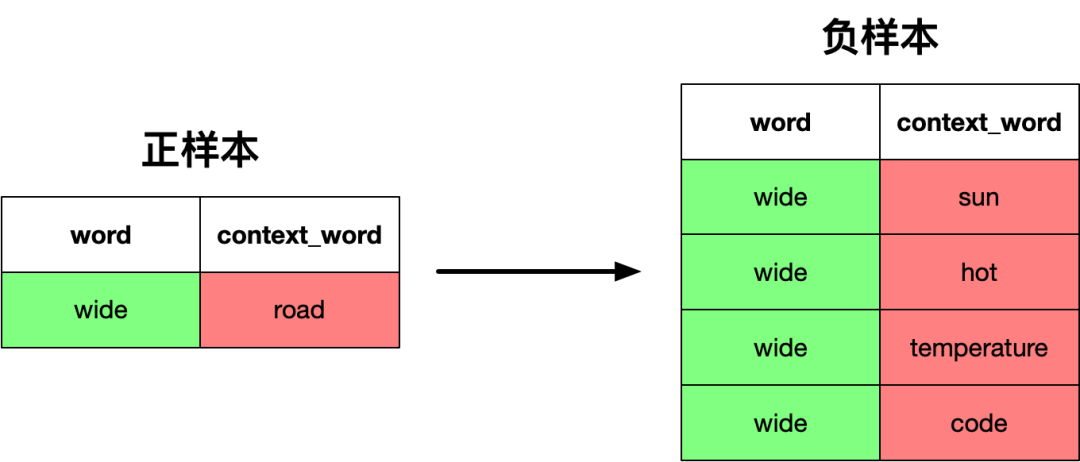
接下来展示负样本的生成过程,负样本是不在窗口内的单词:
下面将正样本和负样本合在一起以生成训练所需的训练样本。

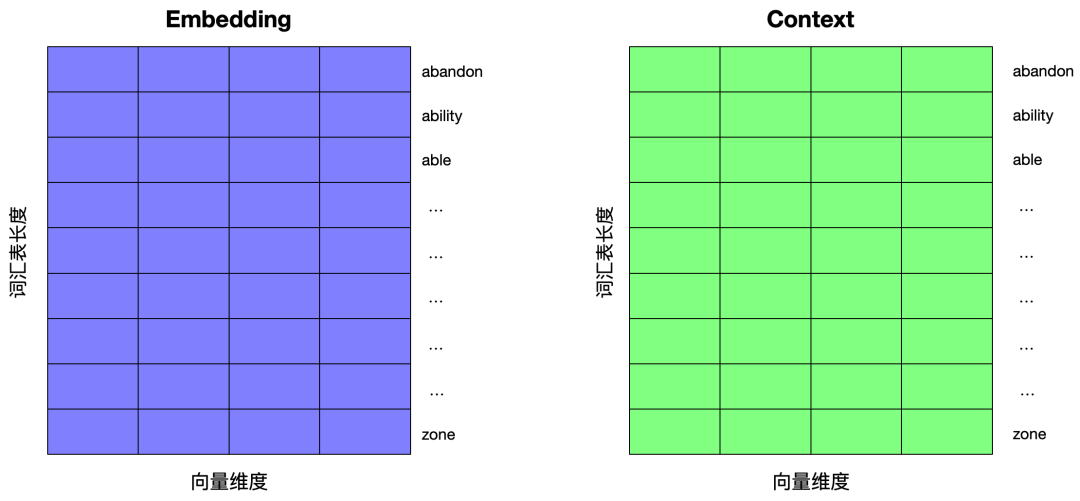
下面通过一个训练样本来展示整个的训练过程。首先初始化两个矩阵,一个 Embedding 矩阵,一个 Context 矩阵,矩阵的行数据为词汇表里的每个单词所对应的向量,刚开始是,矩阵里的数据都是随机的。
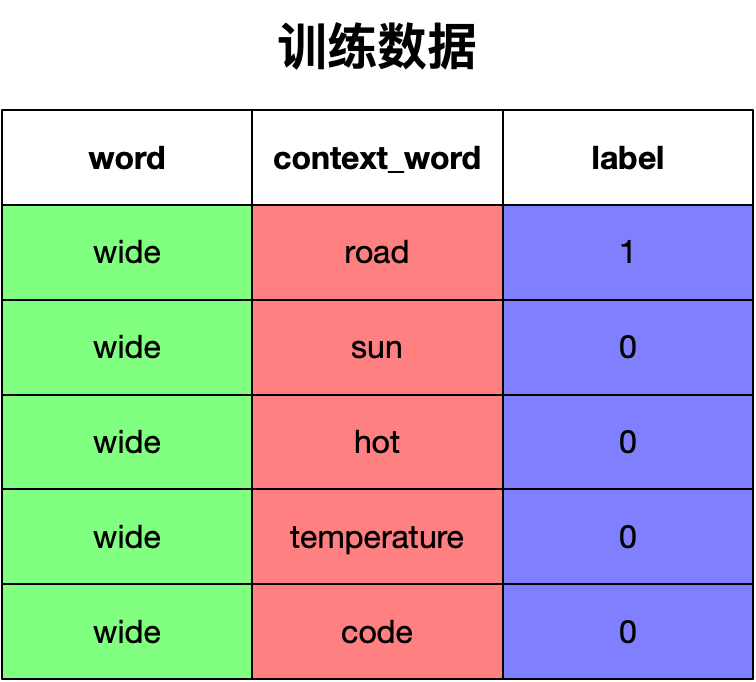
每次训练,我们选取一个正样本以及其所对应的负样本以构成训练数据。例如:
选择训练数据中的一行数据分别到 Embedding 矩阵和 Context 矩阵查询单词所对应的向量。
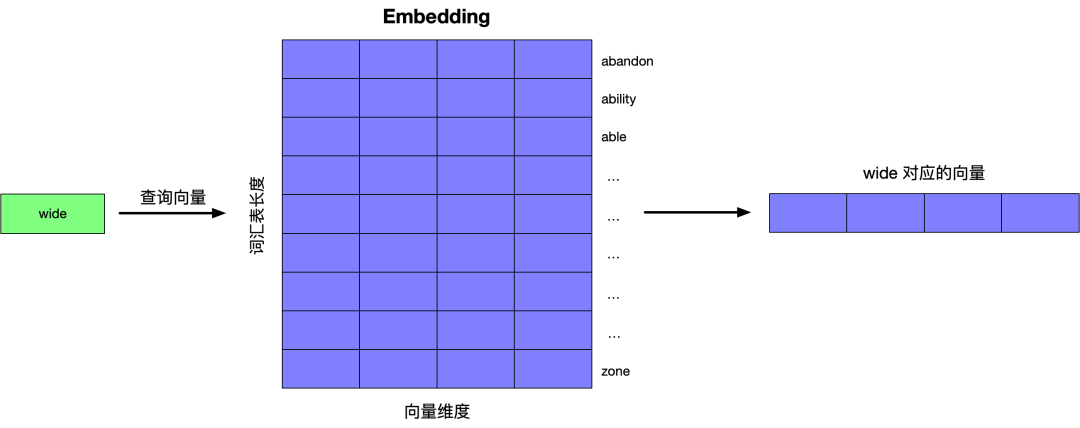
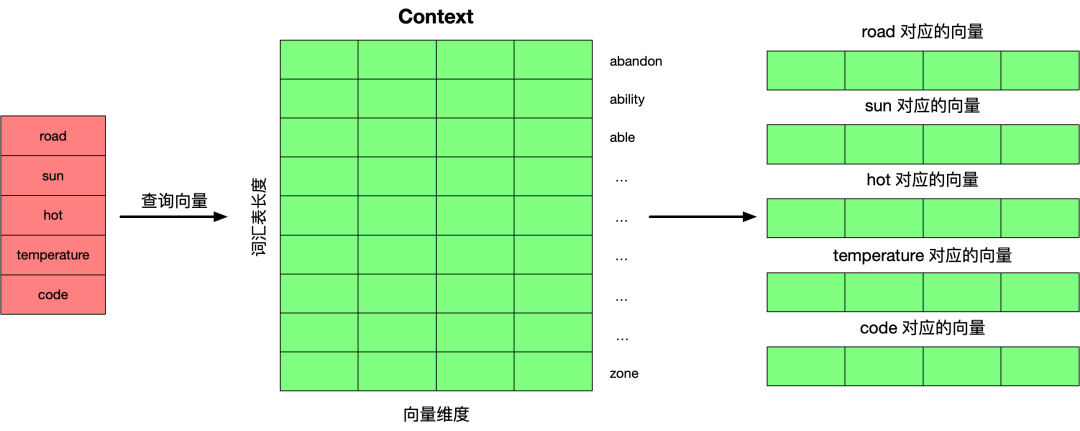
下面将每个单词的向量和其上下文中的单词所对应的向量求点积,点积的结果反映了两者的相似度。
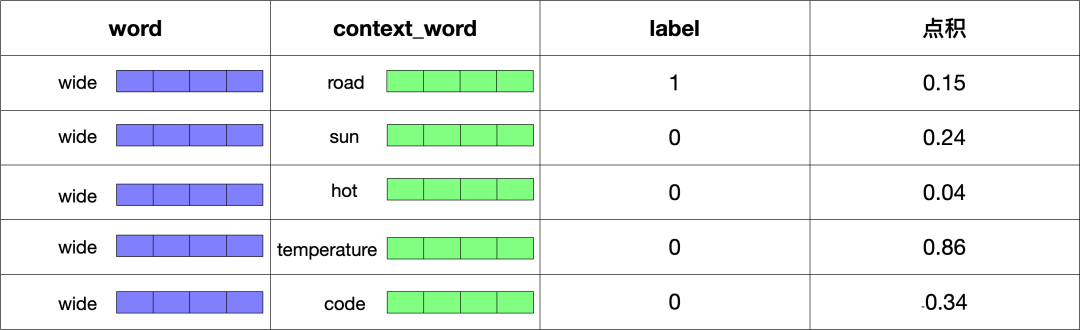
因为 label 的数值指的是概率,所以我们需要使用 sigmoid 函数将点积转成概率,转换后的结果如下:
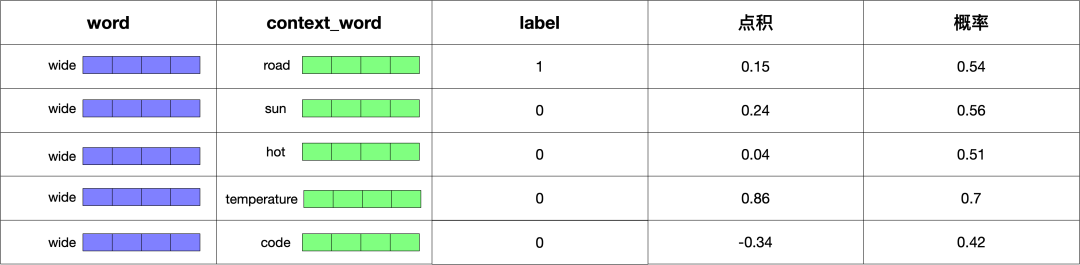
有了 label 这预测的概率值之后,就可以求出差值了,结果如下:
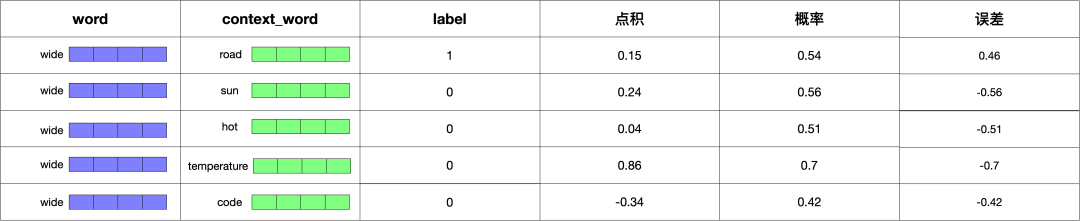
有了误差之后,就可以使用误差来更新前面的 Embedding 矩阵和 Context 矩阵的值了。这便是整个的训练过程。
Word2Vec 的优缺点
优点:
-
Word2Vec 能够有效捕捉单词之间的语义相似度。例如,它能够识别“国王”和“王后”之间的关系,以及“男人”和“女人”之间的关系。
-
使用优化的训练算法(如 Skip-Gram 和 CBOW),Word2Vec 可以在大规模语料库上高效地训练,生成高质量的词向量。
-
用户可以根据具体应用需求调整词向量的维度,以平衡计算复杂度和表示能力。
-
Word2Vec 在处理未见过的词或罕见词时具有较好的泛化能力,因为它能够利用上下文信息来推断词义。
缺点:
-
Word2Vec 主要基于上下文窗口内的共现信息,忽略了单词顺序,无法捕捉到词序对语义的影响。
-
Word2Vec 为每个词生成一个固定的词向量,无法区分同一个词在不同上下文中的不同含义(即词的多义性问题)。
-
由于词向量是基于词的共现频率学习的,对于稀有词或未见词,Word2Vec 的表现较差,词向量质量不高。
-
虽然 Word2Vec 能够在大量未标注的数据上进行训练,但其训练过程完全是无监督的,无法利用标注数据中的监督信息来改进词向量质量。
总结
本文介绍了文本向量化的几种方法,包括词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)和Word2Vec。
词袋模型(Bag of Words) 通过统计每个词在文档中出现的频率来表示文档,不考虑词的顺序和上下文关系。其主要优点是简单易懂,计算效率高,但缺点是生成的向量维度高且无法捕捉词语间的语义关系。
TF-IDF(Term Frequency-Inverse Document Frequency):这种方法在词袋模型的基础上进行了改进,通过结合词频和逆文档频率,降低常见词的权重,提升区分性强的词的权重。它能更好地反映重要词语在文档中的相对重要性,但仍然不考虑词的上下文关系。
Word2Vec:这种方法通过神经网络模型将词语映射到低维向量空间中,能够捕捉到词语的语义关系。Word2Vec主要有两种模型:CBOW(Continuous Bag of Words)和Skip-gram。CBOW通过上下文预测目标词,Skip-gram则通过目标词预测上下文。Word2Vec的优点是能够捕捉词语的语义和上下文关系,缺点是训练复杂度较高。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
自己也整理很多AI大模型资料:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}