






在Llama-3的报告中,任何在pre-training之后发生的训练都属于post-training,包括SFT、DPO等。
Llama-3的post-training不是一次完成的,而是多个round迭代进行,整个post-training包含6轮的SFT和DPO。
1.Modeling
post-training的流程如下图
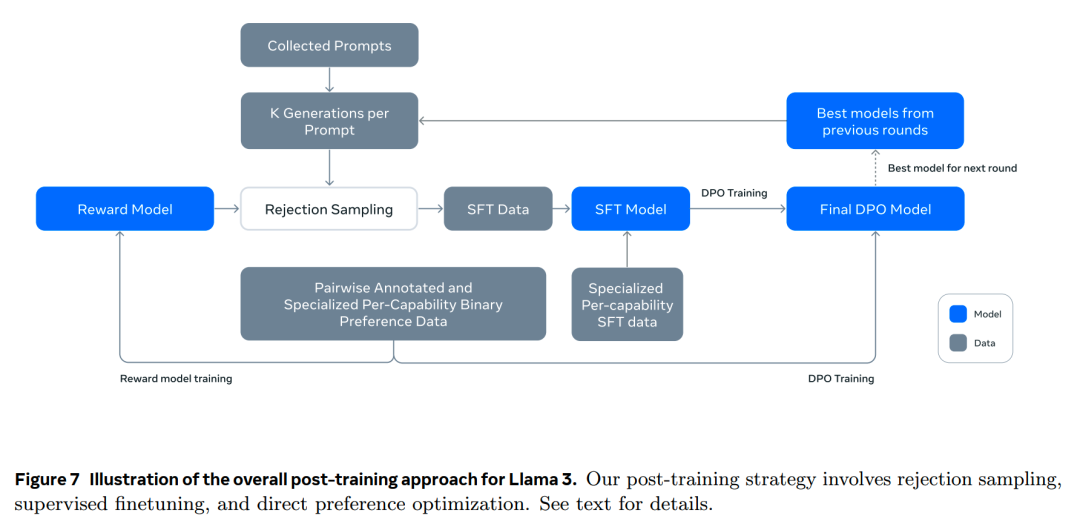
1.1.Chat Dialog Format
Llama-3相比之前的版本多了一些能力,比如tool use。在这些场景下,模型可能生成多个结果,并发送给不同的接收方,之后再由模型汇总各方结果。为了支持这些能力,Meta设计了multi-message chat protocol。
1.2.Reward Modeling
reward model(RM)是post-training中的一个重要部分。
和Llama-2相比,这次RM的一个变化是移除了训练时加入的margin term(用于把chosen和rejected response区分得更开),因为随着模型规模的增大,加入margin term收益越来越小了。
另一方面,同Llama-2一样,preference data中只有区分度比较大的数据对用于训练RM。
数据上,除了常规的chosen和rejected response之外,还引入了第三种 – “edited response”,即在chosen的基础上通过(人工)编辑,进一步提升这条response的质量。这样每条ranking sample就可能有3条response(edited > chosen > rejected)。
训练的时候,prompt和对应的多条随机打乱的response拼接在一起训练(prompt + resp_1 + resp_2 + resp_3),这和通常的做法,即每个response都拼接prompt有些不同(prompt + resp_1, prompt + resp_2, prompt + resp_3)。从结果上来看,都拼接到一起在accuracy上没有什么损失,而训练效率更高。(个人理解这里可能是通过乐死document mask来实现的)
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

1.3.SFT
训练好的RM模型会用于rejection sampling,对human annotation prompt的不同生成结果进行过滤。得到的高质量数据会和其他来源的SFT数据一起用来微调模型。
SFT训练的时候使用lr=1e-5,步数为8.5k~9k步。实践上这样的参数设置在多轮的post-training中都能保持较好的效果。
1.4.DPO
在DPO阶段,会用在上一轮post-training得到的最佳模型收集偏好数据对,这样能使得偏好数据的分布和强化学习时的policy model更一致。
除了DPO以外,Meta也尝试了一些on-policy的方案,如PPO。但是相对来说,DPO消耗更少的计算资源,并且效果也更好,特别是在instruction following的能力上,所以还是选择在post-training使用DPO。
DPO训练中,使用lr=1e-5,beta=0.1。
此外,训练中还做了一些不同于标准做法的改动:
1、Masking out formatting tokens in DPO loss
把特殊token比如header和termination token屏蔽,不用于计算训练loss。因为使用这些token计算loss会使得模型在生成时,出现如复读机或者在不合适的地方截断的情况。这可能就是因为chosen repsponse和rejected response同时包含的这些特殊token,让模型在训练时要同时增大和较小它们的likelihood,导致冲突。
2、Regularization with NLL loss
除了DPO的常规loss,Meta额外加入了NLL损失项,这和《Iterative reasoning preference optimization》的做法类似。这也有点像PPO里加入next token prediction loss,能使训练更加稳定,并能保持SFT学到的生成格式,并保持chosen response的log probability不下降(《Smaug: Fixing failure modes of preference optimisation with dpo-positive》)。
1.5.Model Averaging
参考《Averaging weights leads to wider optima and better generalization》《Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time》和《Branch-train-merge: Embarrassingly parallel training of expert language models》,在RM、SFT和DPO阶段,分别把“用不同版本的数据和超参训练得到模型”进行平均,以获得最终模型。
2.数据
2.1.偏好数据
偏好数据的处理过程和Llama-2类似。
首先,在每轮训练完后部署一批“在不同数据、超参、训练策略上训练”得到的模型,这些模型有各自的特点,比如有些擅长写代码,有些擅长数学推理。
对于每个user prompt,从这些模型里采样两个response。之后标注人员给每对chosen和rejected response分成4类:
-
significantly better
-
better
-
slightly better
-
marginally better
过程中标注人员也可以对chosen response进一步编辑,获得更好的response。
下表给出了偏好数据的的统计:
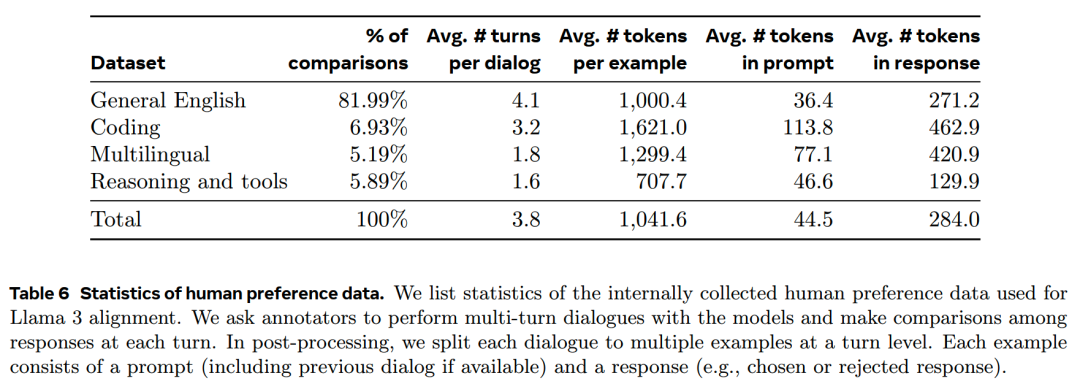
相比Llama-2的数据,Llama-3所用的prompt和response的长度都有所增加,这说明Llama-3的任务复杂度提升了。
在每一轮的post-training之后,都会分析当前版本模型效果不好的领域,并针对这些领域提升prompt的复杂度。
每轮post-training中,训练RM的时候,会使用所有来自不同轮所收集到的偏好数据。而DPO训练则只会用到最新的偏好数据。
对于RM和DPO,都只使用分类为significantly better 和 better的数据进行训练,而另外两类质量相近的偏好数据对则被丢弃。
2.2.SFT Data
SFT数据主要有这几个来源:
-
人工收集的prompt,以及对应的通过拒绝采样得到的response
-
特定领域的合成数据(后面capacities部分会讲到)
-
少量人类真实数据
1、拒绝采样(RS)
在RS阶段,每个prompt会从“最新的/领域最佳的chat模型”采样K个回复(一般10~30个),然后用RM选出最佳回复(《Constitutional AI: harmlessness from AI feedback》)。
在靠后轮次的post-training里,RS引入了控制风格、格式、语气等特性的system prompt以更精细地控制数据质量。不同的领域(如代码、推理、工具使用等)可能会采用不同的prompt。
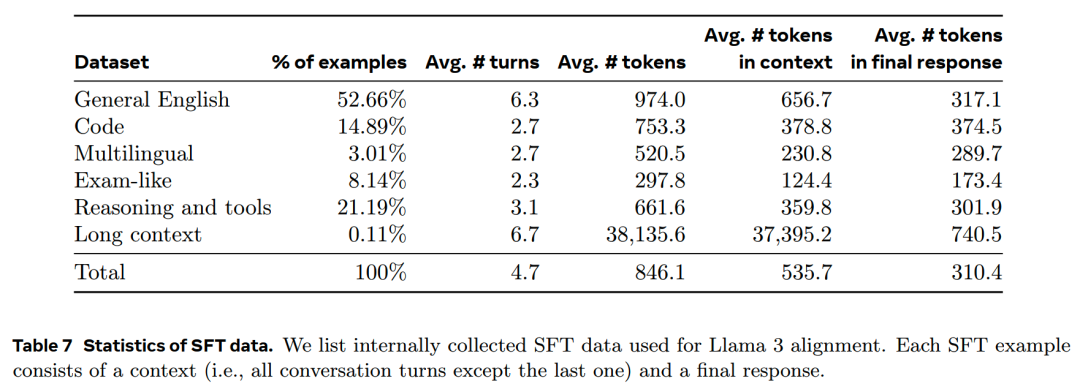
2、数据组成
下表给出了helpful数据中每个大类别的数据统计:
2.3.数据处理 & 质量控制
由于大部分数据都是模型生成的,所以需要仔细地清洗。
1、数据清洗
在post-training的前几轮中,研究人员发现数据中混入了一些包含过量emoji或者感叹号之类的数据,因此用专门的规则对发现的低质量pattern进行了清洗。此外有些数据还有overly-apologetic(比如模型经常回复“我很抱歉”)的问题,也会有规则识别如“I‘m sorry”这样的内容,并降低这类数据的比例。
2、Data pruning
一系列model-based的方法用来过滤低质量数据:
-
话题分类:用Llama-3-8B来做粗粒度 & 细粒度的领域分类。
-
质量打分:一方面,RM模型会用于识别高质量回复,只有RM得分在前四分之一的数据被认为是高质量的;另一方面,基于Llama-3 checkpoint,使用特定的prompt(不同领域prompt可能不同)进行多个方面的打分,只有得分最高的数据会被认为是高质量的。RM和Llama-3二者的高质量数据识别一致性并不高,实践上,取二者结果的并集对高质量数据的召回效果最好。
-
难度打分:用了Instag和Llama模型打分两种方式来衡量数据的难度。
-
语义去重:用Roberta对对话进行聚类,在每个类别中按quality score × difficulty score进行排序,然后只保留“和已选高质量数据相似度小于阈值”的样本(《Semdedup: Data-efficient learning at web-scale through semantic deduplication》、《What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning》)
3.Capabilities
在不同的具体领域上,Meta分别有一套方法,来提升对应的能力。
3.1.Code
代码上,要提升的目标语言包括:Python, Java, Javascript, C/C++, Typescript, Rust, PHP, HTML/CSS, SQL, bash/shell。
代码能力提升的方法包括训练code expert、生成数据用于SFT训练、通过system prompt调整格式以及使用quality filter过滤低质量数据。
3.1.1.Expert training
首先,在主预训练模型的基础上,增加1T的代码继续预训练,其中>85%的样本是代码数据。然后采用和CodeLlama类似的方法训练code expert。
在训练的最后几千个step,会加入repo-level的长代码数据,以提升code expert的长窗口能力。
继续预训练之后会采用前面提到的方法进行post-training,只是所用数据主要是代码数据。
得到的code expert用于:
-
在主模型的post-training中获取高质量的代码数据
-
code prompt的rejection sampling
3.1.2.合成数据
生成的代码会存在一些问题,包括难以遵循指令、语法错误、生成错误代码和难以修复错误等。
虽然人工标注理论上可以解决这些问题,但合成数据的成本更低、更方便扩展到更大规模,因此还是使用Llama 3和code expert生成大量SFT合成数据。
3.1.3代码生成的方法
基于以下三个方法,一共生成了超过2.7M的代码SFT数据。
1、执行反馈
Llama-3的8B和70B模型在用更大的模型(比如405B)所生成的数据训练时,获得了明显的收益。但是405B模型在用自己生成的数据训练之后(毕竟这个规模下很难有更大的模型了),不仅没有提升,甚至还有些退化。
为了解决这个问题,Meta引入了execution feedback,来对代码进行正确性校验,并让模型从错误中学习。
具体来说,用以下的过程获得了1M左右的训练数据:
(1)生成问题描述
这一步生成大量涵盖广泛主题的编程问题描述。为了增加多样性,从不同的来源随机抽取代码片段,然后根据代码片对生成对应的问题描述。(《Magicoder: Empowering code generation with oss-instruct》)
(2)Solution生成
这一步用Llama-3生成代码问题的答案。
这个过程中,会在prompt里加入优质代码的general rule,并要求模型在注释里给出思路。这两个做法能有效促进代码质量的提升。
(3)正确性分析
检查生成的solution正确性包括两个方面。
一是静态分析,即通过parser和linter保证基础的语法正确性。
另一个是动态检查,通过让模型给代码生成单元测试并执行来判断代码的正确性。
(4)错误反馈 & 迭代修正
对于有问题的代码,并不是直接舍弃,而是让模型修改优化。
通过prompt把错误信息给到模型,不断迭代修改,直到代码通过所有单元测试。
原数据里大概有20%的样本通过这样的修改才通过测试,说明如果不对正确性进行校验的话,会在训练数据里引入大量的错误信息。
(5)微调 & 迭代优化
微调迭代了多个round,每个round产生的模型都用来生成新的数据给下一次迭代训练。
2、programming language translation
不同语言的代码数据量有不平衡的情况,因此Meta基于Llama-3把高频语言的代码“翻译”成低频语言的数据,并通过syntax parsing, compilation, execution等来保证翻译数据的质量。(类似《Breaking language barriers in multilingual mathematical reasoning: Insights and observations》的思路)
3、backtranslation
在代码相关的能力如documentation、debugging和explanation上,执行+反馈的做法并不适用。
因而采用一个多步方法backtranslation,从代码片段开始:
-
Generate:让模型先生成,比如文档,或者代码功能解释
-
Backtranslate:再要求用生成的文档或者功能说明生成代码
-
Filter:如果第二步生成的代码和原代码一致性够高,则说明生成的文档/代码解释好用,可作为训练数据
通过backtranslation,大约获得了1.2M的documentation、debugging和explanation等数据。
3.1.4.其他
1、system prompt
使用代码专用的system prompt可以提高生成数据的质量,下图是一个样例,右边多了comment,变量名更为合理,还更省空间。

2、Filtering training data with execution and model-as-judge signals
rejection sampling的过程会遇到有问题的代码,但是检验这些代码并不是想象中的那么straightforward,比如生成的内容可能包含了不能执行的内容(如伪代码),或者用户要求生成的是完整代码的一个小片段(无法单独执行),这些都无法直接通过单元测试来检验。
因此使用“model-as-judge”的方法,即通过Llama-3对生成内容做正确性和风格好坏的二分类,只有当二者都被分为好,对应的代码数据才会被使用。
但是这种方法会倾向于保留简单任务(因为复杂的任务更容易出现问题),导致模型在复杂问题上的能力受损。因此研究人员还专门人为地修改了困难任务上的response,直到这些response符合Llama-3的要求。
3.2.多语言
Llama-3支持8种语言:German, French, Italian, Portuguese, Hindi, Spanish, Thai。
3.2.1.Expert training
用包含超过90%的多语言(即除英语以外的语言)的data mix,对主预训练模型做继续预训练,之后再进行同code expert类似的post-training。得到的多语言expert model用于收集高质量的非英文数据。
3.2.2.多语言数据收集
多语言的SFT数据中,包含:
-
2.4%的人类数据
-
44.2%的NLP task数据
-
18.8%来自rejection sampling
-
34.6%来自translated reasoning data
1、人类数据
这部分都是从native speaker收集的,大部分包含开放的多轮对话,代表了真实世界的数据。
2、NLP task
-
把常规NLP任务改写成对话格式。
-
为了提升语言的alignment,使用了来自《Parallel global voices: a collection of multilingual corpora with citizen media stories》和Wikimedia的parallel text。
-
用LID based filtering和Blaser2.0 (《Seamlessm4t—massively multilingual & multimodal machine translation》)清洗掉低质量数据。
3、拒绝采样数据
相比英文数据,多语言数据的RS做了几点改动:
-
Generation:在post-training的前几轮中,使用0.2~1.0的随机温度来生成回复,以提升多样性。而在最后一轮中,则使用0.6的温度,以保持生成结果中创新性和流畅性的平衡。
-
Selection:在RM模型之前,对prompt和response做了语言检查,保证语言的匹配性(比如不会出现一种语言问,另一种语言回答,除非明确要求)。
4、翻译数据
大部分数据都没有做翻译,以避免引入翻译腔等问题,除了一个例外:synthetic quantitative reasoning data。
这类数据的语言描述通常比较简单,所以翻译之后没有什么质量问题,而推理数据可以帮助改善多语言的定量推理能力。
3.3.Math and Reasoning
reasoning被定义为“执行多步计算并得出最终正确答案”的能力。
reasoning能力的训练有几个挑战:
-
缺少prompt:这种高难度的任务数据相对较少
-
缺少正确的CoT:reasoning任务一般有多步,包含这些多步CoT的正确答案的数据也不多
-
错误的中间步骤:基于模型生成的CoT很容易有错误的中间步骤
-
使用外部工具:教会模型使用外部工具能极大提升效果,但这并不容易
-
训练与推理的差异:推理的时候可能需要在中间和用户进行交互获取反馈,这可能和训练数据不完全一致
针对这些问题,Meta给出以下解决方案。
1、解决缺少prompt的问题
为了解决缺少prompt的问题,研究人员从数学相关的context抽取数据片段并转换为对话形式。
对于模型表现不好的数学领域,专门收集了人类的prompt。为此构建了数学相关的分类体系(《Metacognitive capabilities of llms: An exploration in mathematical problem solving》),并让人类专家提供相应的prompt和问题。
2、Augmenting training data with step-wise reasoning traces
就是用Llama-3为一系列的prompt生成step-by-step的解决方案。
对于每个prompt,模型会生成不同数量的结果。这些生成结果随后根据正确答案进行筛选(《Common 7b language models already possess strong math capabilities》)。
此外还进行了自我验证,即使用Llama-3来验证给定的步骤解决方案对于特定问题是否有效。
3、Filtering incorrect reasoning trace
训练outcome RM和stepwise RM来把中间过程错误的数据清洗掉(《Let’s verify step by step》,《Math-shepherd:Verify and reinforce llms step-by-step without human annotations》)。
对于更难的prompt,使用Monte Carlo Tree Search (MCTS)来处理(《Monte carlo tree search boosts reasoning via iterative preference learning》)。
4、Interleaving code and text reasoning
在文本推理之外,加上python code的执行反馈来对结果正确性做进一步确认(《Tora: A tool-integrated reasoning agent for mathematical problem solving》)。
5、Learning from feedback and mistakes
为了模仿人类的反馈,使用包含错误的生成结果,并要求模型给出修正(《Learning from mistakes makes llm better reasoner》,《Generating sequences by learning to self-correct》,《Self-refine: Iterative refinement with self-feedback》)。
3.4.Long Context
在预训练的最后阶段,训练窗口从8k扩展到128k。
而和预训练相似,在post-training阶段也需要仔细平衡模型的短文本能力和长文本能力。
1、SFT
如果直接把常规的、较短的SFT数据应用在预训练模型上做SFT,会使得预训练阶段得到的长文本能力退化,因此SFT阶段必须加上长数据。
由于让人类来给出超长(128k)的SFT数据,难度太大耗时太长,并不现实,所以主要还是依赖合成数据。
用早期的Llama-3版本来生成长文本关键场景的数据,比如多轮问答、长文本摘要和代码仓库级别的reasoning。
(1)Question answering
从预训练数据里筛选一些长文档,并把它们切分为8k的片段,之后让(短窗口)模型对随机选择的片段生成QA数据。长文本训练时则是把完整的文档和相关的QA作为输入。
(2)Summarization
摘要采用层次化的方式,即先用8k的模型对长文档的每个8k片段进行摘要,多个片段摘要合在一起再进行二次摘要,获得最终结果。
此外,Meta还基于文档摘要生成QA对,要求模型回答那些需要对文档做全面理解的问题。
(3)Long context code reasoning
首先解析Python文件,识别导入语句并确定它们的依赖关系。
接下来,对那些被至少五个其他文件使用的文件,随机删除一个,训练时要求模型识别哪些文件依赖于被删除的文件,并生成所需的缺失代码。
以上这些数据都被分成16K, 32K, 64K和128K的长度,方便进行细粒度的微调。
另外,消融实验发现,在原SFT数据中混入0.1%的这些合成的长文本,对模型的短文本和长文本能力都有提升。
2、DPO
实验发现DPO阶段仅使用短文本并不会对模型长文本能力造成明显影响,可能是因为DPO的更新步数比较少,因此DPO没有特意增加长文本数据。
3.5.Tool Use
使用工具的能力可以拓展模型的能力边界,让模型从单纯的聊天机器人变成有用的智能助手。Llama-3被训练使用以下core tools:
-
搜索引擎:Brave Search
-
Python interpreter:用于执行生成的代码
-
Mathematical computational engine:Wolfram Alpha API
当用户的query需要用到多个工具时,Llama-3可以给出plan,对工具进行串行调用,并在每次调用之后进行推理整合。
除了core tool之外,Llama-3还有zero-shot的工具调用能力,能根据query调用此前没见过的用户定义的工具。
1、Implementation
Meta将core tools实现为具有不同方法的Python对象。
而zero-shot tool可以作为带有描述、文档(使用示例)的Python函数来实现,模型只需要函数的签名和文档字符串作为上下文来生成适当的调用。
函数的定义和调用都转换为json格式,例如用于Web API调用。
所有工具调用都由Python解释器执行,且需要在Llama-3的system prompt中启用(即告诉模型可以使用哪些工具能力)。core tool可以在system prompt中单独启用或禁用。
2、Data collection
与ToolFormer不同,Llama-3主要依赖人类的标注数据和偏好数据来训练。
人类标注员对模型给出的多个message进行排序,如果两个都不好,就手动编辑一个好的,并让对话继续。
工具使用的训练没有使用rejection sampling,因为实践上来看这样做没有效果。
为了减少标注的人力投入,会先进行基本的finetune让模型具备基本的工具使用能力,并且会先从单轮对话开始,慢慢迭代到多轮对话。
3、Tool datasets
通过以下方法来获取数据。
(1)Single-step tool use
先用few-shot prompt让模型生成core tools的调用,之后要求模型基于用户query和调用结果回答问题。
顺序如下:system prompt, user prompt, tool call, tool output, final answer。
生成的数据里有30%的数据有诸如无法执行,或者有格式问题,就被清除掉了。
(2)Multi-step tool use
先让Llama-3生成至少需要调用2次core tool(可以相同也可以不同)的prompt,然后再用few shot prompt让Llama-3生成一个由交错推理步骤和工具调用组成的解决方案,和ReAct类似。下图是一个多步工具调用的例子:

(3)File uploads
使用这些格式的文件:.txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml。
基于上传的文件,要求模型进行摘要生成、查找并修复错误、优化代码片段、执行数据分析和可视化等任务。下图是一个示例
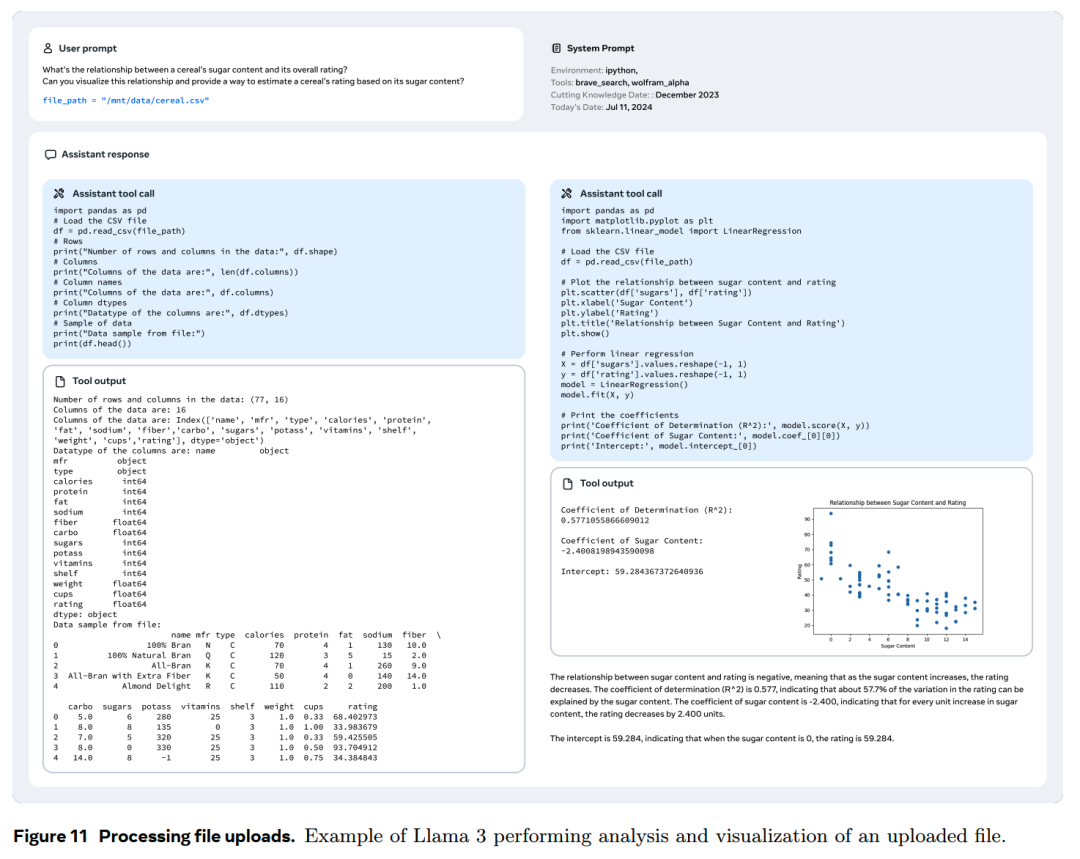
在使用这些合成数据进行了微调之后,Meta进一步收集了多样化且具有挑战性的任务数据,包括多轮交互、三个以上步骤的工具使用,以及工具调用未能得到满意答案的case。
为了让模型避免对简单的query调用工具,使用了简单数学或问答数据集的query,及其不使用工具的response,但在system prompt中激活了工具。这样模型就能学到,即使工具时available的,但是对于简单问题可以不调用工具,避免了工具滥用。
4、Zero-shot tool use data
通过在一个大型的多样化(合成)数据集上微调,提高了Llama-3的zero-shot工具使用能力(函数调用)。
数据包括函数定义、用户query和相应的调用。然后另一批从未见过的工具上进行评测。
(1)Single, nested, and parallel function calling
函数的调用情况有多重,可以是简单的单次调用,也可以是嵌套的(即将一个函数调用作为另一个函数的参数),或者是并行的(即模型返回一个独立的函数调用列表)。
要生成多样化的工具调用数据并不容易(《Toolverifier: Generalization to new tools via self-verification》),因此通过在Stack里(《The stack: 3 tb of permissively licensed source code》)进行挖掘,确保函数调用和定义是真实的。即从里面提取出真实的函数调用和定义,过滤掉如文档有问题或者无法执行的函数,之后用Llama-3生成函数调用的query。
(2)Multi-turn function calling
参照《Api-bank: A comprehensive benchmark for tool-augmented llms》的做法,为带有函数调用的多轮对话生成了合成数据。
通过使用不同的prompt,让Llama-3扮演不同的agent,分别用于生成domains, APIs, user queries, API calls, 和 responses。
3.6.Factuality
Hallucination依然是大模型的一个问题。即使在模型不怎么了解的领域,模型也会给出很自信的回答,这就会给大模型的使用带来风险。
Meta遵循的原则是,post-training应该使模型 “know what it knows” ,而不是增加知识(《Does fine-tuning llms on new knowledge encourage hallucinations?》,《Linguistic calibration through metacognition: aligning dialogue agent responses with expected correctness》)。
主要方法是生成数据 – 生成与预训练数据中存在的实际数据保持一致的微调数据。
为了实现这一点,Meta开发了一种基于Llama-3的in-context能力的knowledge probing技术。
这个数据生成过程包括以下步骤:
-
从预训练数据抽取一个片段
-
用Llama-3对这个片段生成一个事实性问题
-
用Llama-3采样这个问题的答案
-
用原片段的context对生成答案的正确性进行打分
-
对生成结果的informativeness进行打分
-
用Llama-3生成对“信息丰富但错误的response”的refusal
Meta使用knowledge probing生成的数据,来鼓励模型只回答它有知识的问题,并拒绝回答它不确定的问题。
此外,预训练数据并不总是一致或正确的。因此还专门收集了一个数据集,处理那些事实矛盾或不正确陈述普遍存在的敏感话题。
3.7.Steerability
可操控性是指引导模型的行为和结果以满足开发者和用户需求的能力。
由于Llama-3是一个通用的基础模型,它应该具备在不同使用场景下的可操控性。
Meta主要通过system prompt来增强Llama-3的可操控性,特别是在response长度、格式、语气等方面。
数据收集上,首先要求annotator为Llama-3设计不同的system prompt,然后,annotator与模型进行对话,评估模型在对话过程中遵循system prompt中定义指令的一致性,并收集偏好数据。
以下是一个增强可操控性的system prompt例子:

4.小结
-
Llama-3不仅仅是一个模型,而且是一个巨大的工程
-
大量的工作仍然是在数据上,而且post-training的权重提高了许多
-
对各个领域数据的细致整理,也提醒开发者们,目前阶段的“通用能力”说到底还是多任务训练,而多任务,就需要一个领域一个领域踏实优化
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 5610
5610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}