






1 前言
往期的文章中,笔者从网络结构和代码实现角度较为深入地和大家解析了Transformer模型、Vision Transformer模型(ViT)、BERT以及DETR模型,其具体的链接如下:
本期内容,笔者想和大家聊一聊ViT的变体,即CrossViT ,其大致结构如下图所示 。
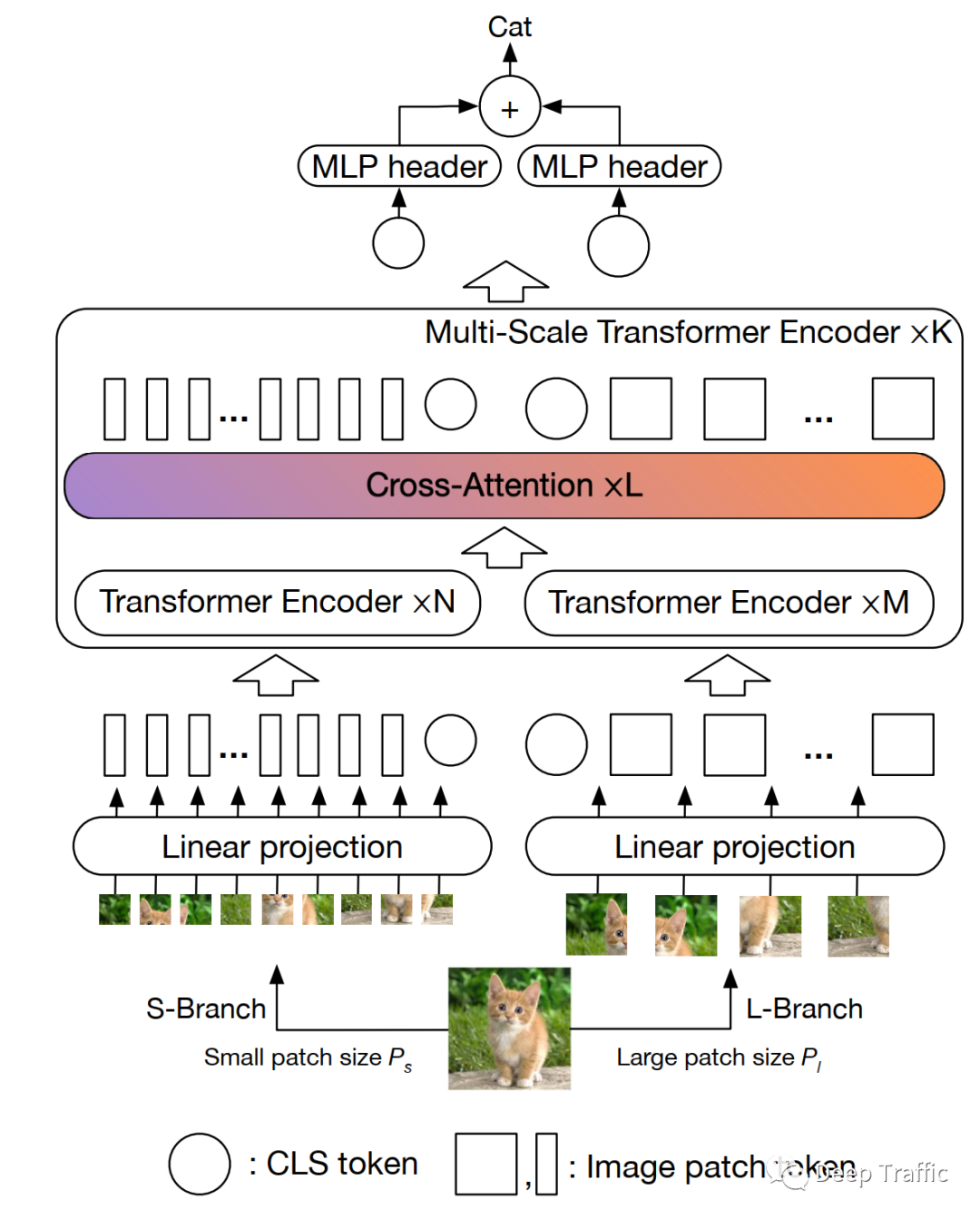
在深入探索CrossViT具体结构之前,我们先简单回归一下CNN中的多尺度特征。
一般而言,在CNN网络中,通过堆叠卷积+池化层来实现特征提取和摘要。所谓摘要,就是特征图的尺度会越来越小,而通道数会增多。
通常来说,越靠近输入的特征图,尺度大但通道维度低,包含更多的细节信息;而越远离输入的特征图,其尺度小但维度大,包含更多语义信息。对于一些视觉任务(如图像分类和目标检测),多尺度特征的融合非常利于性能提升。
但是,初始的ViT中好像无法高效地利用这种多尺度特征。因此,本文提出了cross-attention,旨在实现在不同尺度的输入序列间进行高效交互。
这里我反复提到的高效,也请读者谨记于心。个人认为这是CrossViT 的核心所在。CrossViT的官方代码如下:
“
https://github.com/IBM/CrossViT
2 Cross ViT解析
2.1 动机和思路
前面提到,多尺度特征融合对于一些视觉任务很有帮助,加上ViT在图像分类任务上也展示了非常有潜力的结果,这就促进了结合多尺度特征融合的ViT的提出,即本文的CrossViT。
那么如何将多尺度特征融合到ViT中呢?在解答这个问题之前,我们需要先搞清楚一个概念,也就是ViT中的多尺度是什么。
在ViT中,需要先将图片转换成一个个尺度为的图像patch。如果越小,那么包含的细节就越丰富;反之,其语义性就越强。
那么,也就是说,在ViT中,这种多尺度实际指的是图像patch的大小。
接着,我们言归正传,想一想如何将一张图像按照不同尺度进行拆分的图像patch进行融合呢?
这篇论文作者尝试了四种融合方式,如下图所示。

-
第一种方式最为直白,就是将所有的patch压缩到同一维度,然后全部堆叠后输入到同一个transformer模块中,显然这种方式的计算量很大。
-
第二种方式是只对大patch对应的CLS token和小patch对应的CLS token进行相加融合,接着与各自的patch进行堆叠后分别输入到各自transformer模块中。CLS token可以视为全局特征的摘要,所以这种方式也是可行的。
-
第三种方式稍微复杂一点,除了引入了第二种融合方式外,还对同一位置的大patch和小patch也进行了相加融合。作者考虑到大patch和小patch在数量上存在差异,这里执行了插值来对齐空间大小。
-
第四种方式就是所谓的cross-attention融合了,下面将进行详细讲述。
2.2 Cross-attention
再讲Cross-attention之前,请大家稍微回忆一下自注意力(Self-attention)怎么执行的:
-
映射为Q、K、V向量:首先,将输入序列中的每个元素通过不同的线性变换映射为查询(Q)、键(K)和值(V)向量。这些线性变换通常是通过学习的参数矩阵实现的。
-
计算注意力分数:对于每个查询向量Q,计算其与所有键向量K之间的相似度。常用的相似度计算方法是点积(dot product)或点积后经过缩放(scaled dot product)。这一步骤可以通过将Q与所有K的内积计算得到。
-
归一化注意力权重:对于每个查询向量Q,将其与所有键向量K之间的相似度得分进行归一化处理,使得注意力权重的总和为1。这一步骤通常通过应用softmax函数实现。
-
加权求和得到输出:将归一化的注意力权重与值向量V相乘,并对乘积结果进行加权求和,得到最终的自注意输出。每个输出向量可以看作是输入序列中不同位置对当前位置的关注程度加权后的表示。
其核心总结起来就是通过计算各要素间的相似度对原始输入进行调整。
这里我们抛出一个疑问:
“
那么做多尺度融合,即大patch和小patch融合,能否先利用大patch的CLS token来计算与所有小patch之间的相似度,然后对小patch进行调整呢?亦或者利用小patch的CLS token来计算与所有大patch之间的相似度,然后对大patch进行调整呢?
事实上,Cross-attention就是这么实现的,作者设计了双分支的结构,分别实现(1)用大patch的CLS token访问小patch,以及(2)用小patch的CLS token访问大patch。其中,用大patch的CLS token访问小patch的具体实现流程如下图所示。
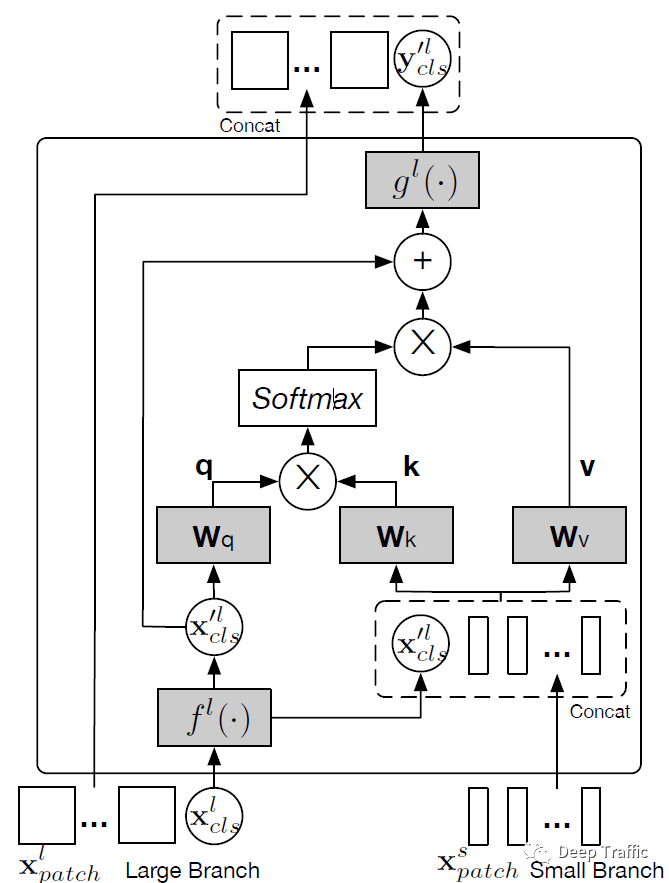
具体的运算流程可以归纳为:
-
Q向量设置:首先,利用将大patch的CLS token维度调整为和小patch相同的维度,作为自注意力计算的询问向量Q;
-
K,V向量设置:将维度变换后的Q向量与所有小patch进行堆叠,作为自注意力计算的键向量K和值向量V。这里只需要补上Q向量,也是想做一个自注意力了(自己和自己的关系);
-
计算注意力分数:利用点积计算询问向量Q与所有键向量K之间的相似度;
-
归一化注意力权重:应用softmax函数实现相似度得分的归一化处理;
-
加权求和得到输出:将归一化的注意力权重与值向量V相乘,并对乘积结果进行加权求和,得到最终的自注意输出;
-
残差连接后维度恢复:将Q向量与自注意输出进行相加,并利用将维度映射回去,作为大patch新一轮的CLS token。
对于用小patch的CLS token访问大patch,其流程与上述完全一致,这里就不赘述了。
前面提到CLS token可以视为是一个数据样本的全局特征,用大patch的CLS token去访问所有小patch,其实是在以一种相对高效的方式来建立大patch与各个小patch之间的交互。
这边我们简单看一下cross-attention的代码实现:
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.wq = nn.Linear(dim, dim, bias=qkv_bias)
self.wk = nn.Linear(dim, dim, bias=qkv_bias)
self.wv = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
q = self.wq(x[:, 0:1, ...]).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # B1C -> B1H(C/H) -> BH1(C/H)
k = self.wk(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
v = self.wv(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
attn = (q @ k.transpose(-2, -1)) * self.scale # BH1(C/H) @ BH(C/H)N -> BH1N
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 1, C) # (BH1N @ BHN(C/H)) -> BH1(C/H) -> B1H(C/H) -> B1C
x = self.proj(x)
x = self.proj_drop(x)
return x
这么一看,好像和多头self-attention的操作是一样的,唯一的不同在于张量q取得是第一个位置(就CLS token)的元素,而非全部元素。
3 总结
写到这里,关于CrossViT的基本流程和网络结构都讲解完毕了。其核心在于实现多尺度特征融合的cross attention。
如果大家熟悉Transformer和VIT的话,应该会觉得CrossViT其实比较容易理解。当然,如果大家觉得看起来比较吃力的话,这里非常建议大家可以自学/温习一下Transformer和VIT后再来看一遍!
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 2639
2639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}