






期刊:ICCV
年份:2021
代码:https://github.com/IBM/CrossViT
摘要
与卷积神经网络相比,最近开发的视觉transformer (ViT)在图像分类方面取得了很好的结果。受此启发,本文研究如何在transformer模型中学习多尺度特征表示,用于图像分类。本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次融合这些token,以相互补充。为了减少计算量,开发了一个简单有效的基于交叉注意力的token融合模块,为每个分支使用一个token作为查询,以与其他分支交换信息。所提出的交叉注意力在计算和记忆复杂度方面只需要线性时间,而不是二次时间。广泛的实验表明,所提出方法在视觉transformer上的表现优于或与几个并发工作持平,此外还有高效的CNN模型。例如,在ImageNet1K数据集上,通过一些架构上的更改,所提出方法的性能比最近的DeiT高出2%,FLOPs和模型参数略有到适度的增加。
Introduce
研究现状:
- 之前的研究努力主要集中在将自注意力(self-attention)与CNN结合的方法上,但这些混合方法在计算上的可扩展性有限。
- Vision Transformer(ViT),这是一种无卷积的transformer模型,它使用一系列嵌入的图像块作为输入,并展示了与CNN模型相当或更好的性能。然而,ViT需要非常大的数据集进行训练,例如ImageNet21K或JFT300M。
本研究的核心问题:如何在transformer模型中学习多尺度特征表示以提高图像识别能力。尽管多尺度特征表示在许多视觉任务中已被证明是有益的,但其在视觉transformer中的潜在好处尚未得到验证。
主要贡献:
- 本文提出一种新的双分支视觉transformer,用于提取图像分类的多尺度特征表示。提出了一种基于交叉注意力的简单有效的token融合方案,在计算和内存上都是线性的,以结合不同尺度的特征。
- 所提出方法的性能优于或与几个基于ViT的并发工作持平,并在准确性、吞吐量和模型参数方面与EfficientNet展示了可比较的结果。
Related Work
CNN with Attention:
- 注意力机制在多种形态中被广泛用于增强特征表示。例如,SENet利用通道注意力,CBAM添加了空间注意力,ECANet提出了一种高效的通道注意力来进一步提升SENet的性能。
- 研究者们对将CNN与不同形式的自注意力结合表现出了浓厚兴趣。SASA和SAN使用局部注意力层替代卷积层,而LambdaNetwork引入了一种高效的全局注意力来改善图像分类模型的速度-准确率权衡。
Vision Transformer:
- 受到Transformer在机器翻译中成功应用的启发,完全依赖于Transformer层的无卷积模型在计算机视觉中变得流行。特别是Vision Transformer(ViT),是首个基于Transformer的方法,用于图像分类任务,并且能够与CNN相匹敌或甚至超越。
- 其他一些ViT的变体,它们通过数据蒸馏、金字塔结构或自注意力来提高效率。
Multi-Scale CNNs:
- 多尺度特征表示在计算机视觉中有着悠久的历史,例如图像金字塔、尺度空间表示和粗到细的方法。
- 在CNN的背景下,多尺度特征表示被用于多尺度的目标检测和识别,以及在Big-Little Net和OctNet中加速神经网络。
Method
CrossViT方法建立在ViT的基础上
拓展阅读:
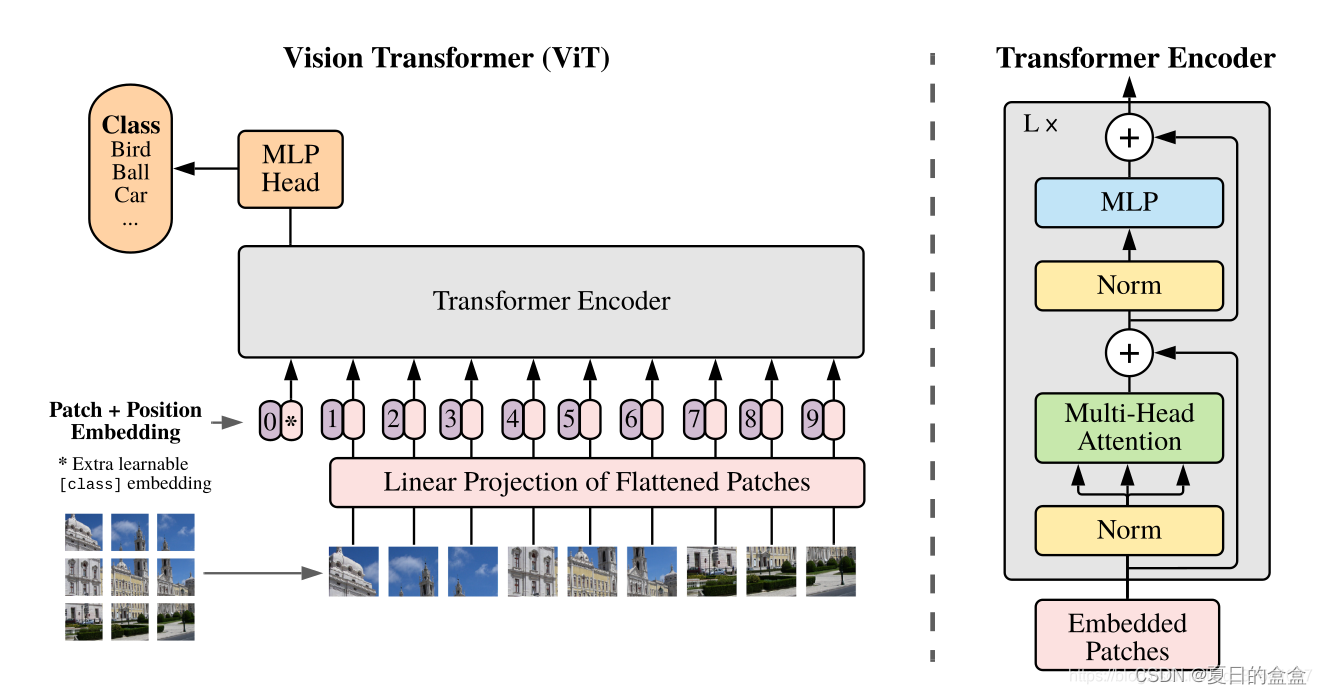
首先通过将图像划分为一定的patch大小,将图像转换为patch token序列,然后将每个patch线性投影为token。一个额外的分类标记(CLS)被添加到序列中。此外,由于transformer编码器中的自注意力与位置无关,而视觉应用高度需要位置信息,因此ViT在每个token中添加了位置嵌入,包括CLStoken。然后,所有token通过堆叠的transformer编码器传递,最后使用CLStoken进行分类。transformer编码器由一系列块组成,其中每个块包含带有前馈网络(FFN)的多头自注意力(MSA)。FFN在隐层采用具有扩展率的两层多层感知器,在第一层线性层之后采用一阶GELU非线性。在每个块之前应用层归一化(LN),在每个块之后应用剩余快捷方式。
3.1 Multi-Scale Vision Transformer
动机:图像块(patch)的粒度大小影响 ViT 的准确性和复杂性。细粒度的 patch 可以提高性能,但会导致更高的浮点运算次数(FLOPs)和内存消耗。为了同时利用细粒度和粗粒度 patch 的优势,作者提出了一个双分支 ViT。每个分支处理不同尺寸的 patch tokens,并通过一个高效的模块在分支间融合信息。
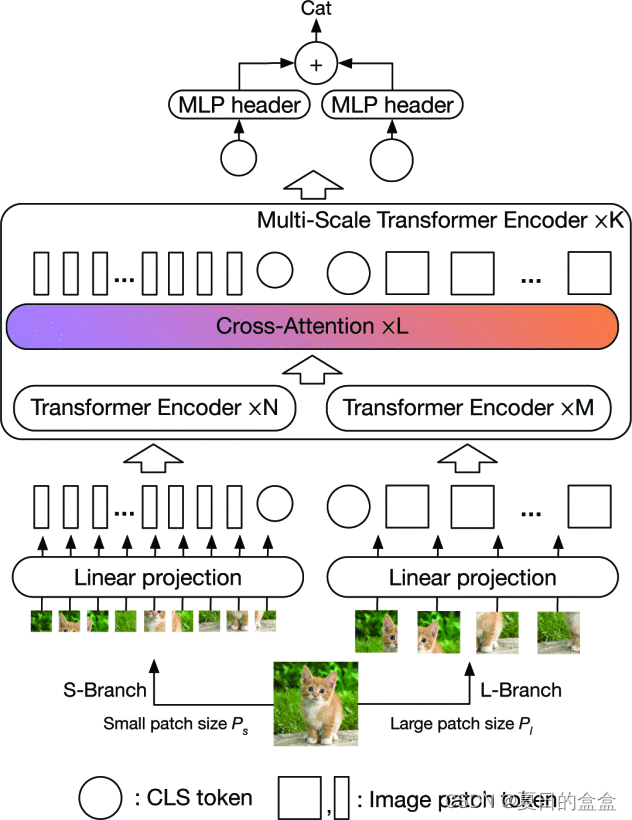
模型架构:CrossViT 模型由 K 个多尺度变换器编码器堆叠而成,每个编码器包含两个分支
- L-Branch(大分支):使用粗粒度 patch 大小(Pl),具有更多的变换器编码器和更宽的嵌入维度。
- S-Branch(小分支):使用细粒度 patch 大小(Ps),具有较少的编码器和较小的嵌入维度(Ps < Pl)。
CLStoken:每个分支都加上CLStoken两个分支的信息通过 L 次融合,最终使用两个分支的 CLS tokens 进行预测。
Position Embedding:每个分支的每个 token 在多尺度Transformer编码器之前都添加了可学习的位置嵌入,以学习位置信息。
3.2 Multi-Scale Feature Fusion
探索了四种不同的融合策略:三种简单的启发式方法和提出的交叉注意力模块:

- (a) All-attention 融合,其中所有令牌都被捆绑在一起,而不考虑令牌的任何特征。
- (b) 类令牌融合,其中只有 CLS 令牌被融合,因为它可以被认为是一个分支的全局表示。
- (c) 成对融合,其中相应空间位置的标记融合在一起,CLS 分别融合。
- (d) 交叉注意,其中一个分支的 CLS 标记和另一个分支的补丁令牌融合在一起。
参数定义:
是分支i处的标记序列(patch和CLS Token)
- 对于大分支i是l,对于小分支i是s
和
分别表示分支i的CLS和patch Token
3.2.1 All-Attention Fusion
All-Attention Fusion 是一种直接的融合方法,它不考虑每个token的特性,将两个分支的所有tokens简单串联起来,然后使用自注意力模块来处理合并后的token序列。
计算过程:

计算公式:

其中 和
是投影和反投影函数来对齐维度。
特点:All-Attention Fusion在理论上可以捕捉到不同分支间的复杂交互,但其效率较低,且在实际应用中可能不如其他更高效的融合策略表现出色。
3.2.2 Class Token Fusion
CLS token 可以被视为其分支的全局特征表示。因此,通过简单地将两个分支的CLS tokens相加或融合,可以有效地结合来自不同分支的信息。
计算过程:

计算公式:
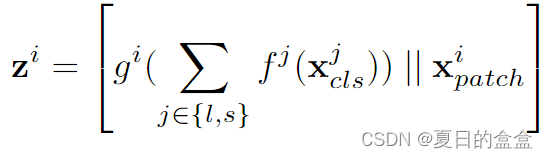
其中 和
是投影和反投影函数来对齐维度。
特点:计算上非常高效,但它可能不会捕获不同分支间所有可能的交互和信息流动。这是因为它依赖于CLS tokens来聚合信息,而CLS tokens可能不足以完全表示来自不同尺寸patch的复杂特征。
3.2.3 Pairwise Fusion
将两个分支中空间位置相对应的patch tokens进行配对融合。这种方法考虑了不同尺寸的patch tokens在原始图像中的空间对应关系。
计算过程:

计算公式:
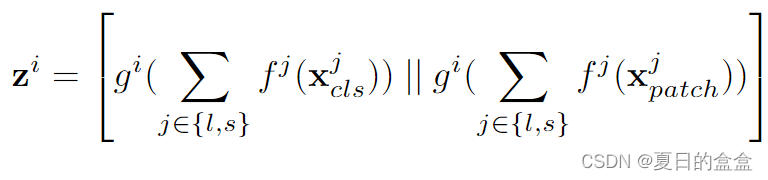
其中 和
是投影和反投影函数来对齐维度。
特点:
- Pairwise Fusion 考虑了不同分支间的空间对应关系,这有助于保留图像的空间结构信息。
- 此方法在理论上可以更好地捕获多尺度特征之间的空间关联性。
- 由于不同尺寸的patch tokens数量可能不同,因此需要适当的插值或尺寸调整步骤,这可能会引入额外的计算负担。
- 配对融合需要精确的空间对齐,这可能在实际操作中具有一定的复杂性。
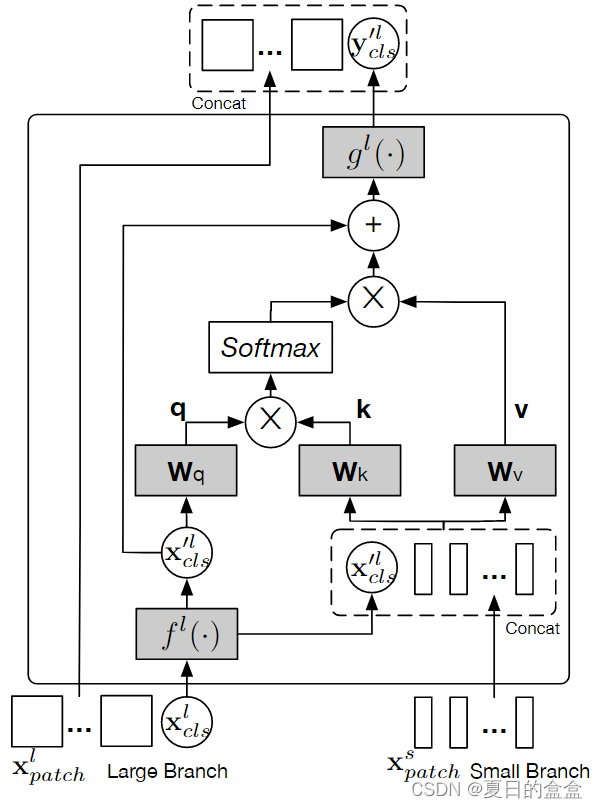
3.2.4 Cross-Attention Fusion
利用每个分支的CLS token作为查询(query),与另一个分支的patch tokens进行交互,以此来实现两个分支间的信息交换。这种方法允许模型在保持计算效率的同时,捕获不同尺度的特征表示。
计算过程:

计算架构图:
计算公式:
- 大分支CLSToken和小分支的patch进行连接
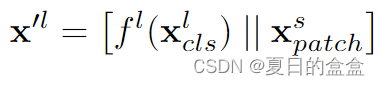
- 计算q、k、v
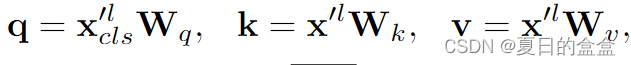
- 计算注意力
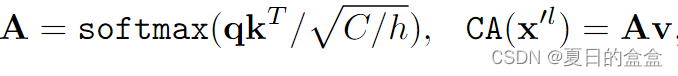
- 将交叉注意力的输出与原始的大分支的patch tokens进行融合,并添加残差连接和层归一化

特点:
- Cross-Attention Fusion 的核心优势在于其计算效率。由于只有CLS token参与查询,计算和内存复杂度从二次时间降低到线性时间。
- 此方法允许不同尺度的特征通过注意力机制进行有效交互,有助于学习更丰富的多尺度特征表示。
3.2.5 不同融合机制对比
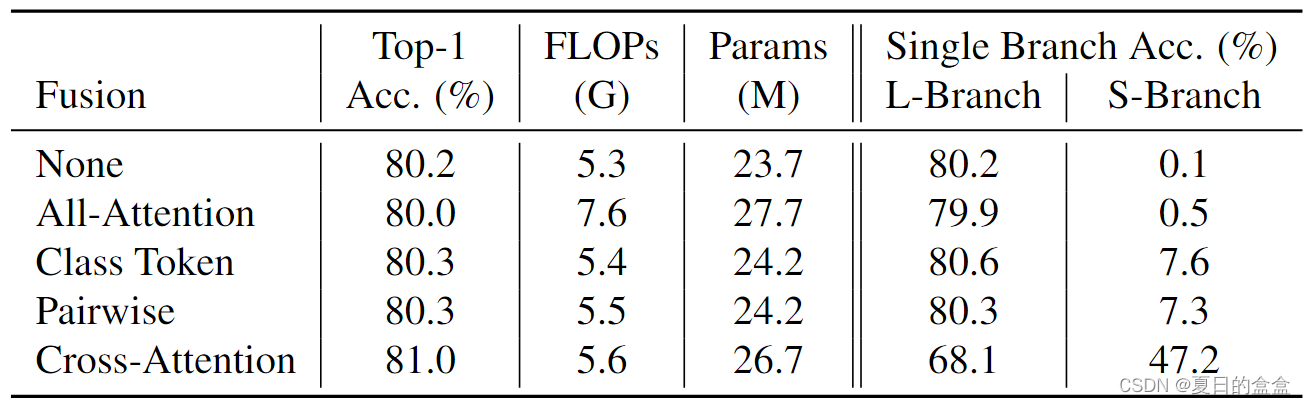
在所有比较策略中,所提出的交叉注意融合在FLOPs和参数增加较小的情况下获得了最好的精度。令人惊讶的是,尽管使用了额外的自注意来组合两个分支之间的信息,但与简单的类令牌融合相比,全注意无法获得更好的性能。在其他融合策略中,主l分支通过减少互补s分支的影响而在精度上占主导地位,而在我们提出的交叉注意融合方案中,两个分支都达到了一定的精度,并且它们的集合是最好的,这表明这两个分支对不同的图像学习了不同的特征。
Result
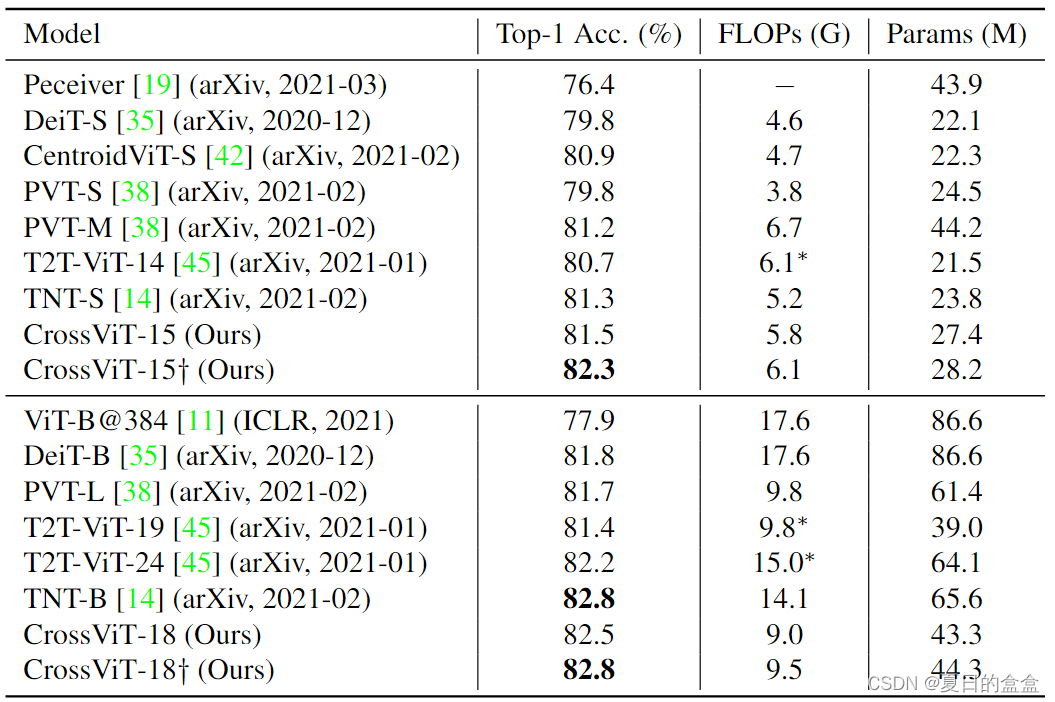
与 SOTA Transformers 的比较。我们进一步将我们的方法与一些最新的视觉Transformers并行工作进行了比较。他们都提高了原始 ViT [11] 在效率、准确性或两者方面。如表所示,CrossViT-15†在FLOPs和参数相当的所有其他方法中都优于小型模型。有趣的是,与 ViT-B 相比,CrossViT-18† 在准确度上显着优于它 4.9%(77.9% 对 82.8%),同时需要更少的 FLOP 和参数。此外,CrossViT-18† 的性能与 TNT-B 一样好,优于其他模型,但 FLOP 和参数也更少。我们的方法在准确性和FLOPs方面始终优于T2T-ViT[45]和PVT[38],显示了多尺度特征在视觉变压器中的有效性。
Conclusion
在本文中,我们提出了 CrossViT,一种用于学习多尺度特征的双分支视觉Transformer,以提高图像分类的识别精度。为了有效组合不同尺度的图像补丁标记,我们进一步开发了一种基于交叉注意的融合方法,在线性时间内有效地交换两个分支之间的信息。通过广泛的实验,我们证明了我们提出的模型除了高效的 CNN 模型外,还优于或与视觉转换器的几个并行工作相当。虽然我们目前的工作触及了用于图像分类的多尺度视觉转换器的表面,但我们预计未来将有更多的工作来开发用于其他视觉应用的高效多尺度转换器,包括对象检测、语义分割和视频动作识别。

















 2823
2823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









