






YOLOv10目标检测创新改进与实战案例专栏
专栏链接: YOLOv10 创新改进有效涨点
介绍

摘要
Mamba是一种具有线性计算复杂度的有效状态空间模型。它最近在处理各种视觉任务的高分辨率输入方面表现出了令人印象深刻的效率。在本文中,我们揭示了强大的Mamba模型与线性注意力Transformer共享令人惊讶的相似性,而线性注意力Transformer在实践中通常不如传统Transformer。通过探索高效的Mamba和表现欠佳的线性注意力Transformer之间的相似性和差异,我们提供了全面的分析,揭示了Mamba成功背后的关键因素。具体来说,我们在统一的公式下重新定义了选择性状态空间模型和线性注意力,将Mamba重新表述为具有六个主要区别的线性注意力Transformer的变体:输入门、遗忘门、快捷连接、无注意力归一化、单头和修改的块设计。对于每个设计,我们仔细分析了其优缺点,并实验证明其对视觉任务中模型性能的影响。有趣的是,结果突出表明遗忘门和块设计是Mamba成功的核心贡献者,而其他四个设计则不太关键。基于这些发现,我们通过将这两个关键设计的优点引入线性注意力,提出了一种类Mamba的线性注意力(MLLA)模型。该模型在图像分类和高分辨率密集预测任务中均优于各种视觉Mamba模型,同时享有可并行计算和快速推理速度。代码可在https://github.com/LeapLabTHU/MLLA获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
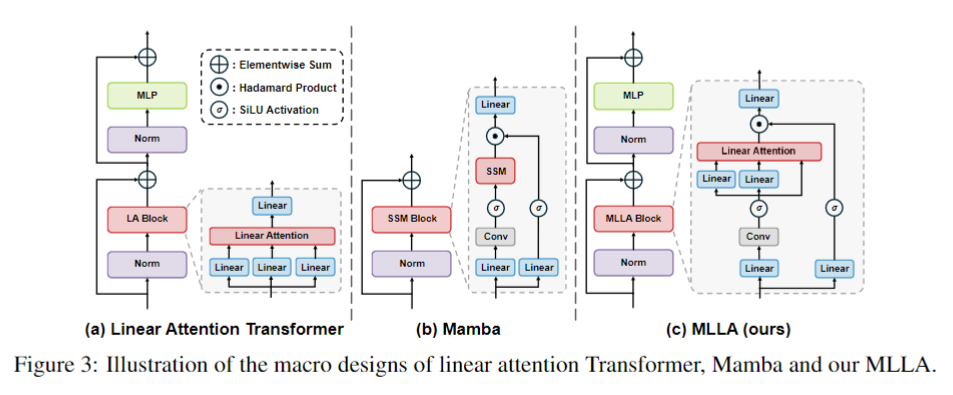
Mamba-Like Linear Attention (MLLA)是一种模型,结合了Mamba和线性注意力Transformer的优点,旨在提高模型在视觉任务中的性能。
-
线性注意力:
- 线性注意力是一种注意力机制,用于计算输入序列中各个位置之间的关联性。与传统的Softmax注意力不同,线性注意力使用线性归一化代替非线性Softmax函数,从而降低计算复杂度。这使得线性注意力的计算复杂度从O(N^2)降低到O(N),提高了效率。
-
Mamba模型:
- Mamba是一种基于状态空间的模型,具有线性计算复杂度。它通过有效地建模序列来处理长序列,适用于自然语言处理和视觉识别任务。
-
MLLA的数学原理:
- MLLA模型将Mamba的关键设计元素(如遗忘门和块设计)与线性注意力Transformer相结合。在数学上,这意味着将Mamba的状态空间建模方法与线性注意力的位置关联性计算相结合,以提高模型的表现。
-
遗忘门的替代:
- 在MLLA中,遗忘门通常被替代为适当的位置编码。这些位置编码可以在视觉任务中代替遗忘门的功能,同时保持模型的并行计算和快速推理速度。
-
核心设计元素的整合:
- MLLA模型的关键设计元素包括遗忘门和块设计。通过将这些设计元素整合到线性注意力中,MLLA模型能够在图像分类和密集预测任务中取得优越性能。
核心代码
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
# Demystify Mamba in Vision: A Linear Attention Perspective
# Modified by Dongchen Han
# -----------------------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=0, dilation=1, groups=1,
bias=True, dropout=0, norm=nn.BatchNorm2d, act_func=nn.ReLU):
super(ConvLayer, self).__init__()
self.dropout = nn.Dropout2d(dropout, inplace=False) if dropout > 0 else None
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, kernel_size),
stride=(stride, stride),
padding=(padding, padding),
dilation=(dilation, dilation),
groups=groups,
bias=bias,
)
self.norm = norm(num_features=out_channels) if norm else None
self.act = act_func() if act_func else None
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.dropout is not None:
x = self.dropout(x)
x = self.conv(x)
if self.norm:
x = self.norm(x)
if self.act:
x = self.act(x)
return x
class RoPE(torch.nn.Module):
r"""Rotary Positional Embedding.
"""
def __init__(self, shape, base=10000):
super(RoPE, self).__init__()
channel_dims, feature_dim = shape[:-1], shape[-1]
k_max = feature_dim // (2 * len(channel_dims))
assert feature_dim % k_max == 0
# angles
theta_ks = 1 / (base ** (torch.arange(k_max) / k_max))
angles = torch.cat([t.unsqueeze(-1) * theta_ks for t in torch.meshgrid([torch.arange(d) for d in channel_dims], indexing='ij')], dim=-1)
# rotation
rotations_re = torch.cos(angles).unsqueeze(dim=-1)
rotations_im = torch.sin(angles).unsqueeze(dim=-1)
rotations = torch.cat([rotations_re, rotations_im], dim=-1)
self.register_buffer('rotations', rotations)
def forward(self, x):
if x.dtype != torch.float32:
x = x.to(torch.float32)
x = torch.view_as_complex(x.reshape(*x.shape[:-1], -1, 2))
pe_x = torch.view_as_complex(self.rotations) * x
return torch.view_as_real(pe_x).flatten(-2)
class LinearAttention(nn.Module):
r""" Linear Attention with LePE and RoPE.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
"""
def __init__(self, dim, input_resolution, num_heads, qkv_bias=True, **kwargs):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.qk = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.elu = nn.ELU()
self.lepe = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.rope = RoPE(shape=(input_resolution[0], input_resolution[1], dim))
def forward(self, x):
"""
Args:
x: input features with shape of (B, N, C)
"""
b, n, c = x.shape
h = int(n ** 0.5)
w = int(n ** 0.5)
num_heads = self.num_heads
head_dim = c // num_heads
qk = self.qk(x).reshape(b, n, 2, c).permute(2, 0, 1, 3)
q, k, v = qk[0], qk[1], x
# q, k, v: b, n, c
q = self.elu(q) + 1.0
k = self.elu(k) + 1.0
q_rope = self.rope(q.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
k_rope = self.rope(k.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
q = q.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
k = k.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
v = v.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
z = 1 / (q @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)
kv = (k_rope.transpose(-2, -1) * (n ** -0.5)) @ (v * (n ** -0.5))
x = q_rope @ kv * z
x = x.transpose(1, 2).reshape(b, n, c)
v = v.transpose(1, 2).reshape(b, h, w, c).permute(0, 3, 1, 2)
x = x + self.lepe(v).permute(0, 2, 3, 1).reshape(b, n, c)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, num_heads={self.num_heads}'
class MLLABlock(nn.Module):
r""" MLLA Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, mlp_ratio=4., qkv_bias=True, drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, **kwargs):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.mlp_ratio = mlp_ratio
self.cpe1 = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.in_proj = nn.Linear(dim, dim)
self.act_proj = nn.Linear(dim, dim)
self.dwc = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.act = nn.SiLU()
self.attn = LinearAttention(dim=dim, input_resolution=input_resolution, num_heads=num_heads, qkv_bias=qkv_bias)
self.out_proj = nn.Linear(dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.cpe2 = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x + self.cpe1(x.reshape(B, H, W, C).permute(0, 3, 1, 2)).flatten(2).permute(0, 2, 1)
shortcut = x
x = self.norm1(x)
act_res = self.act(self.act_proj(x))
x = self.in_proj(x).view(B, H, W, C)
x = self.act(self.dwc(x.permute(0, 3, 1, 2))).permute(0, 2, 3, 1).view(B, L, C)
# Linear Attention
x = self.attn(x)
x = self.out_proj(x * act_res)
x = shortcut + self.drop_path(x)
x = x + self.cpe2(x.reshape(B, H, W, C).permute(0, 3, 1, 2)).flatten(2).permute(0, 2, 1)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"mlp_ratio={self.mlp_ratio}"
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
"""
def __init__(self, input_resolution, dim, ratio=4.0):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
in_channels = dim
out_channels = 2 * dim
self.conv = nn.Sequential(
ConvLayer(in_channels, int(out_channels * ratio), kernel_size=1, norm=None),
ConvLayer(int(out_channels * ratio), int(out_channels * ratio), kernel_size=3, stride=2, padding=1, groups=int(out_channels * ratio), norm=None),
ConvLayer(int(out_channels * ratio), out_channels, kernel_size=1, act_func=None)
)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
# assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = self.conv(x.reshape(B, H, W, C).permute(0, 3, 1, 2)).flatten(2).permute(0, 2, 1)
return x
class BasicLayer(nn.Module):
""" A basic MLLA layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, mlp_ratio=4., qkv_bias=True, drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
MLLABlock(dim=dim, input_resolution=input_resolution, num_heads=num_heads,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
class Stem(nn.Module):
r""" Stem
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.conv1 = ConvLayer(in_chans, embed_dim // 2, kernel_size=3, stride=2, padding=1, bias=False)
self.conv2 = nn.Sequential(
ConvLayer(embed_dim // 2, embed_dim // 2, kernel_size=3, stride=1, padding=1, bias=False),
ConvLayer(embed_dim // 2, embed_dim // 2, kernel_size=3, stride=1, padding=1, bias=False, act_func=None)
)
self.conv3 = nn.Sequential(
ConvLayer(embed_dim // 2, embed_dim * 4, kernel_size=3, stride=2, padding=1, bias=False),
ConvLayer(embed_dim * 4, embed_dim, kernel_size=1, bias=False, act_func=None)
)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.conv1(x)
x = self.conv2(x) + x
x = self.conv3(x)
x = x.flatten(2).transpose(1, 2)
return x
class MLLA(nn.Module):
r""" MLLA
A PyTorch impl of : `Demystify Mamba in Vision: A Linear Attention Perspective`
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each MLLA layer.
num_heads (tuple(int)): Number of attention heads in different layers.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
mlp_ratio=4., qkv_bias=True, drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
self.patch_embed = Stem(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, drop=drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
下载YOLOv10代码
直接下载
Git Clone
git clone https://github.com/THU-MIG/yolov10.git
安装环境
进入代码根目录并安装依赖。
创建虚拟环境并安装依赖
conda create -n yolov10
conda activate yolov10
pip install -r requirements.txt
pip install -e .
引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 MLLA为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=0, dilation=1, groups=1,
bias=True, dropout=0, norm=nn.BatchNorm2d, act_func=nn.ReLU):
super(ConvLayer, self).__init__()
self.dropout = nn.Dropout2d(dropout, inplace=False) if dropout > 0 else None
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, kernel_size),
stride=(stride, stride),
padding=(padding, padding),
dilation=(dilation, dilation),
groups=groups,
bias=bias,
)
self.norm = norm(num_features=out_channels) if norm else None
self.act = act_func() if act_func else None
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.dropout is not None:
x = self.dropout(x)
x = self.conv(x)
if self.norm:
x = self.norm(x)
if self.act:
x = self.act(x)
return x
class RoPE(torch.nn.Module):
def __init__(self, base=10000):
super(RoPE, self).__init__()
self.base = base
def generate_rotations(self, x):
# 获取输入张量的形状
*channel_dims, feature_dim = x.shape[1:-1][0], x.shape[-1]
k_max = feature_dim // (2 * len(channel_dims))
assert feature_dim % k_max == 0, "Feature dimension must be divisible by 2 * k_max"
theta_ks = 1 / (self.base ** (torch.arange(k_max, dtype=x.dtype, device=x.device) / k_max))
angles = torch.cat([t.unsqueeze(-1) * theta_ks for t in
torch.meshgrid([torch.arange(d, dtype=x.dtype, device=x.device) for d in channel_dims],
indexing='ij')], dim=-1)
rotations_re = torch.cos(angles).unsqueeze(dim=-1)
rotations_im = torch.sin(angles).unsqueeze(dim=-1)
rotations = torch.cat([rotations_re, rotations_im], dim=-1)
return rotations
def forward(self, x):
rotations = self.generate_rotations(x)
x_complex = torch.view_as_complex(x.reshape(*x.shape[:-1], -1, 2))
pe_x = torch.view_as_complex(rotations) * x_complex
return torch.view_as_real(pe_x).flatten(-2)
class MLLAttention(nn.Module):
def __init__(self, dim=3, input_resolution=[160, 160], num_heads=4, qkv_bias=True, **kwargs):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.qk = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.elu = nn.ELU()
self.lepe = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.rope = RoPE()
def forward(self, x):
x = x.reshape((x.size(0), x.size(2) * x.size(3), x.size(1)))
b, n, c = x.shape
h = int(n ** 0.5)
w = int(n ** 0.5)
# self.rope = RoPE(shape=(h, w, self.dim))
num_heads = self.num_heads
head_dim = c // num_heads
qk = self.qk(x).reshape(b, n, 2, c).permute(2, 0, 1, 3)
q, k, v = qk[0], qk[1], x
# q, k, v: b, n, c
q = self.elu(q) + 1.0
k = self.elu(k) + 1.0
q_rope = self.rope(q.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
k_rope = self.rope(k.reshape(b, h, w, c)).reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
q = q.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
k = k.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
v = v.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)
z = 1 / (q @ k.mean(dim=-2, keepdim=True).transpose(-2, -1) + 1e-6)
kv = (k_rope.transpose(-2, -1) * (n ** -0.5)) @ (v * (n ** -0.5))
x = q_rope @ kv * z
x = x.transpose(1, 2).reshape(b, n, c)
v = v.transpose(1, 2).reshape(b, h, w, c).permute(0, 3, 1, 2)
x = x + self.lepe(v).permute(0, 2, 3, 1).reshape(b, n, c)
x = x.transpose(2, 1).reshape((b, c, h, w))
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, num_heads={self.num_heads}'
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.MLLA import MLLAttention
步骤2
修改def parse_model(d, ch, verbose=True):
elif m in {MLLAttention}:
c2 = ch[f]
args = [c2, *args]

















 2722
2722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









