






众所周知,Flux模型虽然好用,但是生成时间太长了,之前也提到过一些解决方案,比如使用量化版本的大模型、使用云端插件bizyAir,或者直接租用云服务器,今天呢再给大家推荐一种方案,就是加速lora。
目前出来的有两种加速lora,分别是字节的Hyper_SD模型和阿里最近刚出的Trubo模型,今天嘟嘟就带着大家一起来体验一番。
字节的Hyper_SD很早就有了,最早是支持SD1.5和SDXL的,Hyper-SD是一种基于模型蒸馏和LoRA技术的图像合成加速技术,通过创新的方法加速图像生成过程,使得用户能够在更短的时间内获得高质量的图像。这次呢,推出了基于Flux的Hyper模型,也算老玩家了,有8步和16步两种选择。

阿里妈妈最近也推出的基于FLUX的加速模型FLUX.1-Turbo-Alpha,该模型是基于FLUX.1-dev模型的8步蒸馏版lora,我们使用特殊设计的判别器来提高蒸馏质量。该模型可以用于T2I、Inpainting controlnet和其他FLUX相关模型。和字节上面效果一致,所以拿出来对比。

02
安装使用
Hyper_SD模型下载:
https://huggingface.co/ByteDance/Hyper-SD/tree/main
FLUX.1-Turbo-Alpha模型:
https://huggingface.co/alimama-creative/FLUX.1-Turbo-Alpha/tree/main
可以看到,字节的大一些1.39G,阿里的只有694M,那到底哪个更好用呢,咱们一起来瞅瞅。
存放路径:models/loras
03
使用介绍
我们使用Flux通用的加载lora的工作流,用最高配的fp16 dev模型。
字节Hyper_SD 推荐的Lora强度为 0.125,guidance 3.5。
阿里的 FLUX.1-Turbo-Alpha 推荐Lora强度为1,guidance 3.5。
接下来,我们分别展示原图、Hyper_SD、Turbo的效果对比图,分两组哈。
工作流如下:
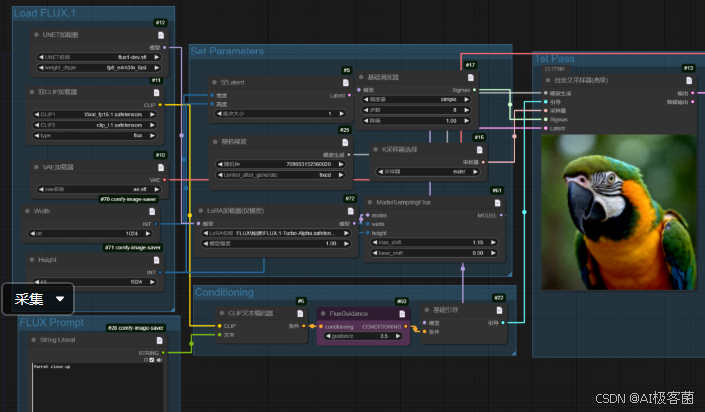
我们分别从写实、风景、卡通、动物 这四个方面来做对比。
左图是原版20步不加lora效果,中间是使用Hyper_SD效果,右边是使用FLUX.1-Turbo-Alpha效果。
01.写实美女
Annie Leibovitz Model features: Asian female models wear gorgeous traditional costumes,showing the beauty of culture and tradition ., Lens description :, The camera uses a standard lens 50mm f/1.8 to capture the natural expressions of the model in a carefully arranged scene., English: Using a 50mm f/1.8 standard lens,the model’s natural expressions are captured in a carefully staged setting
8步

16步

02.风景
raining,natural scenery,green tree,spring,hills,Ancient Chinese palaces,cinematic_angle,depth of field,fisheye,dynamic_angle,lens_flare,landscape, dandan,real, HDR,UHD,8K,best quality,masterpiece,Highly detailed,Studio lighting,ultra-fine painting,sharp focus,physically-based rendering, extreme detail description,Professional,masterpiece,best quality,delicate,beautiful,real,CG,
8步

16步

03.卡通
anime artwork Advertising poster style magazine “Flux AI” cover design, the cover picture is a miniature scene made of wool felt, a cute little white fox wearing in cyber punk style clothes, wearing a headphone, playing guitar in a futurism stage, . Professional, modern, product-focused, commercial, eye-catching, highly detailed . anime style, key visual, vibrant, studio anime, highly detailed
8步

16步

04.动物
Parrot close-up
8步

16步

上面就是对比效果了,大家觉得如何,觉得哪种效果好,加速lora的本质就是用质量换时间,降低一些质量,大大提高生成速度。
然后我们来对比下他们生成的速度,我本地是4090显卡,下面是分别跑出来的时间对比。
我是跑了多次后抽取出来相对平均的时间。
8步的话,时间节省了 55%+
16步的话,提效了19%+
所以还是很给力的。

04
总结
以上就是Flux生态下两种加速lora的对比介绍了,还不错,大家下载下来试试,当作辅助工具挺好用。
技术的迭代是飞快的,要关注最新的消息才不会掉队。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









