







1. 准备环境
1.1. 申请计算中心账号
a. 若已有账号,可略过;
b. 否则参考指导文档“平台注册和资源开通”链接为:云星平台使用手册 · 语雀 ;
1.2. 注册镜像
a. 需要注册的镜像为:swr.cn-north-300.hblfrgzn.com/vision/mindspore2.1.1-py3.9-kernel-cann6.3.rc2:v1.0 ;
b. 参考文档“环境准备-注册镜像指导”,链接为:https://www.yuque.com/fanxiangyu-xamn0/sthma6/yy05acmwpm6dqgmx? singleDoc# ;
1.3. 创建notebook服务
a. 参考指导文档“notebook服务器创建使用”链接为:https://www.yuque.com/fanxiangyu-xamn0/sthma6/ozqc14qlzya5g9nd?singleDoc# ;
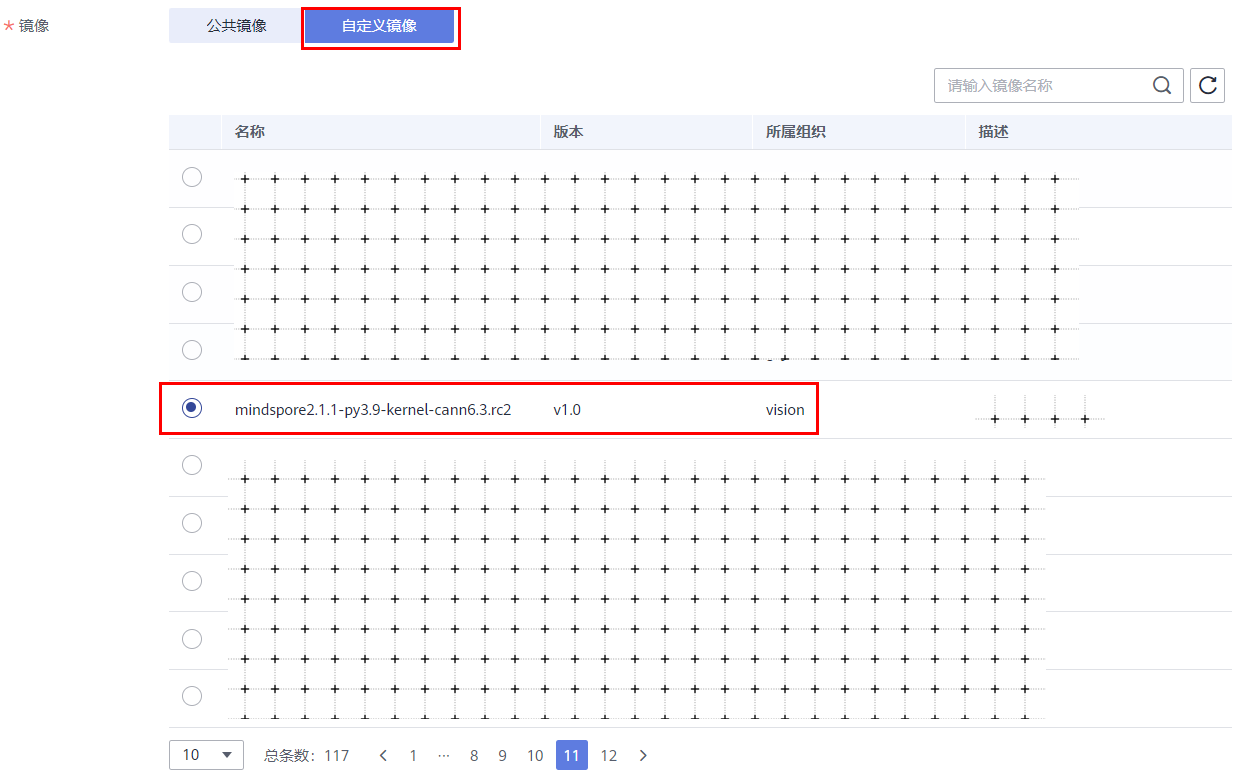
b. notebook创建的时候,选择镜像 swr.cn-north-300.hblfrgzn.com/vision/mindspore2.1.1-py3.9-kernel-cann6.3.rc2:v1.0
如下图所示:
2源码获取并进行环境安装
2.1获取代码以及权重文件
进入创建好的notebook,在默认路径下(/home/ma-user/work),下载 打包好的 llama2 代码,并进行解压,如下图所示
# 在notebook默认路径(/home/ma-user/work)下
# 拉取模型代码,并进行解压
wget https://hb-public.obs.cn-north-300.hblfrgzn.com:443/LLM/llama2/mindformers_1.0.0.tar.gz
tar -zxvf mindformers_1.0.0.tar.gz
# 解压成功之后,删除压缩文件
rm -rf mindformers_1.0.0.tar.gz
cd mindformers
mkdir ckpt
cd ckpt
# 下载 llama2相关模型(主要是7b和13b)权重,并进行解压
# 首先在notebook的Terminal命令行输入 python,进入python交互界面,然后输入如下语句
import moxing as mox
mox.file.copy_parallel("obs://hb-public/LLM/llama2/llama2-ckpt.tar.gz", "/home/ma-user/work/mindformers/ckpt/llama2-ckpt.tar.gz")
# 上述语句执行成功之后,表示权重下载成功,然后退出python交互界面
# 进入 目录 /home/ma-user/work/mindformers/ckpt/ 进行解压
tar -zxvf llama2-ckpt.tar.gz
# 解压成功后,删除压缩文件
rm -rf llama2-ckpt.tar.gz2.2. 环境安装
# 在notebook默认路径(/home/ma-user/work)下
cd mindformers
bash build.sh
# 如下图所示则表示完成环境的安装备注,完成环境的安装,之后的模型训推任务进本都在路径 /home/ma-user/work/mindformers/ 下进行,因此将该路径作为基础路径,本文档后续提到的路径没有特殊说明都是在 /home/ma-user/work/mindformers/ 下。
2.3. 获取RANK_FILE_TABLE
env |grep RANK_TABLE_FILE
# 得到 RANK_TABLE_FILE 的具体文件名称,一般打印结果为:/user/config/nbstart_hccl.json如下图所示:
![]()
备注,这个 RANK_TABLE_FILE 文件名称 /user/config/nbstart_hccl.json 很重要。
3. 数据预处理
3.1. 预训练数据集
以Wikitext2数据集为例
a. 数据集下载:https://hb-public.obs.cn-north-300.hblfrgzn.com:443/datasets/wikitext-2-v1.zip
b. 数据集转换
# 在基础路径 /home/ma-user/work/mindformers/ 下
cd /home/ma-user/work/mindformers/
mkdir datasets
mkdir mr_datasets
cd datasets
# 将下载好的 Wikitext2数据集 放在该路径下,然后进行解压
unzip wikitext-2-v1.zip
# 解压成功后,删除压缩文件
rm -rf wikitext-2-v1.zip
# 进行数据集的转换,执行如下命令
# 使用mindformers/tools/dataset_preprocess/llama/llama_preprocess.py进行数据预处理+Mindrecord数据生成
cd /home/ma-user/work/mindformers/mindformers/tools/dataset_preprocess/llama
python llama_preprocess.py \
--dataset_type wiki \
--input_glob /home/ma-user/work/mindformers/datasets/wikitext-2/wiki.train.tokens \
--model_file /home/ma-user/work/mindformers/ckpt/llama2/tokenizer.model \
--seq_length 4096 \
--output_file /home/ma-user/work/mindformers/mr_datasets/wiki4096.mindrecord如下图所示,则说明数据集预处理成功

此时,检查路径 /home/ma-user/work/mindformers/mr_datasets/,发现预处理好的数据集,如下图所示

3.2. 微调数据集
以alpaca数据集为例
a. 数据集下载:https://hb-public.obs.cn-north-300.hblfrgzn.com:443/datasets/alpaca_data.zip
b. 数据集格式转换
# 在基础路径 /home/ma-user/work/mindformers/ 下
cd /home/ma-user/work/mindformers/
cd datasets
# 将下载好的 alpaca数据集 放在该路径下,然后进行解压
unzip alpaca_data.zip
# 解压成功后,删除压缩文件
rm -rf alpaca_data.zip
cd /home/ma-user/work/mindformers/mindformers/tools/dataset_preprocess/llama
pip install fschat -i https://pypi.douban.com/simple/
# 进行数据集的转换
# step 1. 执行alpaca_converter.py,使用fastchat工具添加prompts模板,将原始数据集转换为多轮对话格式
# 执行转换脚本
python alpaca_converter.py \
--data_path /home/ma-user/work/mindformers/datasets/alpaca_data.json \
--output_path /home/ma-user/work/mindformers/datasets/alpaca-data-conversation.json
# step 2. 执行llama_preprocess.py,进行数据预处理、Mindrecord数据生成,将带有prompt模板的数据转换为mindrecord格式
# 由于此工具依赖fschat工具包解析prompt模板,请提前安装fastchat >= 0.2.13 python = 3.9
python llama_preprocess.py \
--dataset_type qa \
--input_glob /home/ma-user/work/mindformers/datasets/alpaca-data-conversation.json \
--model_file /home/ma-user/work/mindformers/ckpt/llama2/tokenizer.model \
--seq_length 2048 \
--output_file /home/ma-user/work/mindformers/mr_datasets/alpaca-fastchat2048.mindrecord如下图所示,则说明数据集预处理成功

此时,检查路径 /home/ma-user/work/mindformers/mr_datasets/,发现预处理好的数据集,如下图所示

4. llama2-7b的预训练、微调以及推理
4.1. 预训练
本文档以单机8卡为例
step 1. 修改模型对应的配置文件
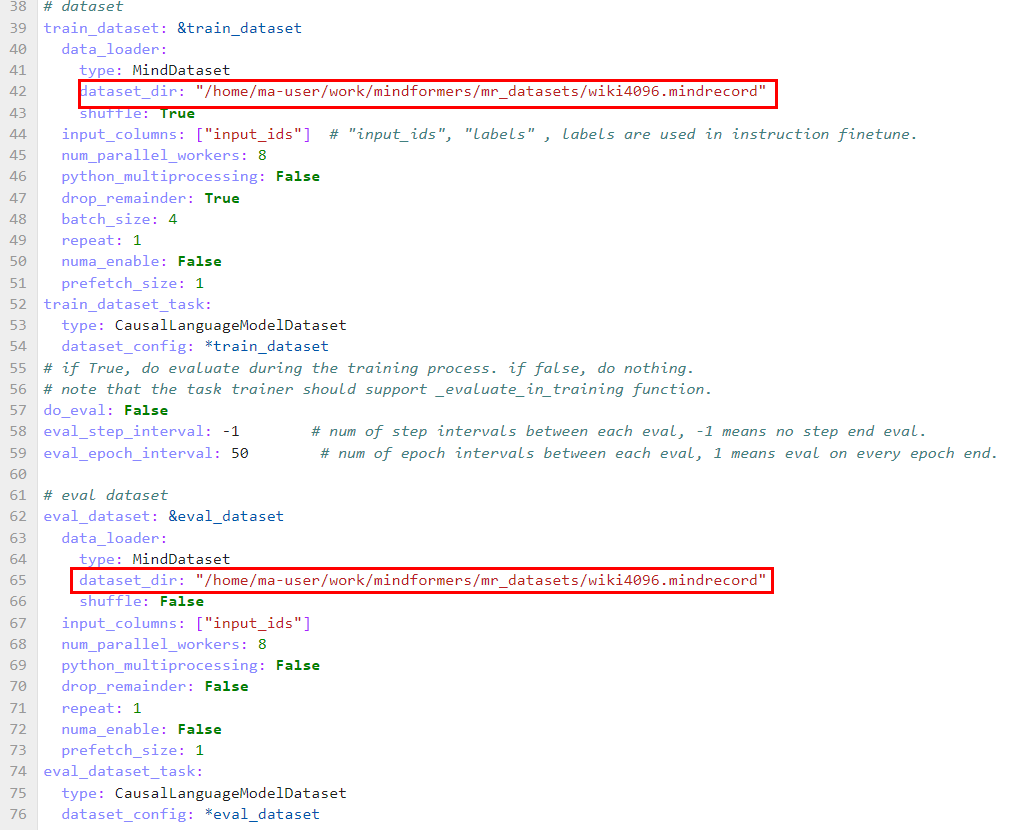
在模型对应的配置文件 configs/llama2/run_llama2_7b_pretrained.yaml 中,用户可自行修改模型、训练相关参数,并通过train_dataset的dataset_dir参数,指定训练数据集的路径,如下图所示
step2. 设置环境变量,变量配置如下:
cd /home/ma-user/work/mindformers/scripts
vi run_distribute.sh
# 在 run_distribute.sh 文件中作如下修改(如下图所示),然后保存关闭
source env_npu_pretrained.sh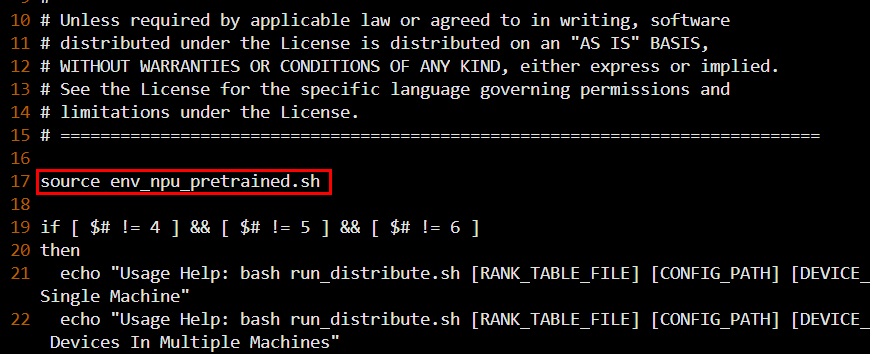
step3:启动运行脚本,进行8卡分布式运行
# 执行如下命令,拉起8卡分布式预训练
cd /home/ma-user/work/mindformers/scripts
bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/llama2/run_llama2_7b_pretrained.yaml [0,8] train如下图所示
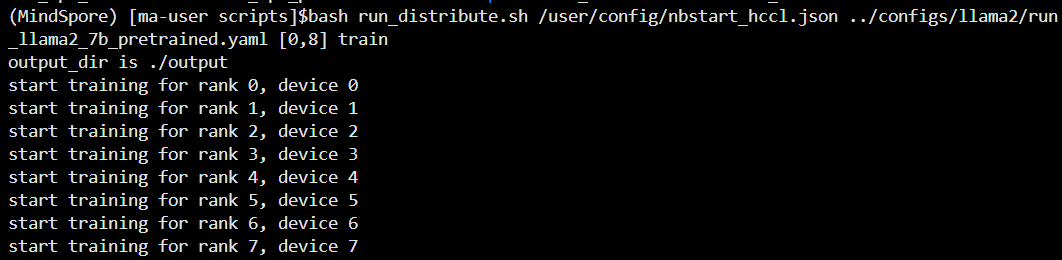
备注:1. 启动命令执行时如果出现 “run_distribute.sh: line 69: ulimit: max user porecesses: cannot modify limit: Operateion not permitted”或者类似的内容,请忽略;
2. 预训练输出的log日志路径:/home/ma-user/work/mindformers/output/log ;
3. 预训练checkpoint存储路径:/home/ma-user/work/mindformers/output/checkpoint ;
4.2. 微调
llama2-7b的微调目前有 全参微调 和 Lora微调
4.2.1. 全参微调
全参微调本文档以单机8卡为例
step 1. 修改模型对应的配置文件
参考 configs/llama2/run_llama2_7b_finetune.yaml 中训练数据集路径为微调数据集路径,并在 input_columns 中添加 labels ,如下图所示

step 2. 参数修改
修改微调时学习率, 优化器参数,seq_length , 新增 context 中参数, 与预训练不同,微调配置如下:
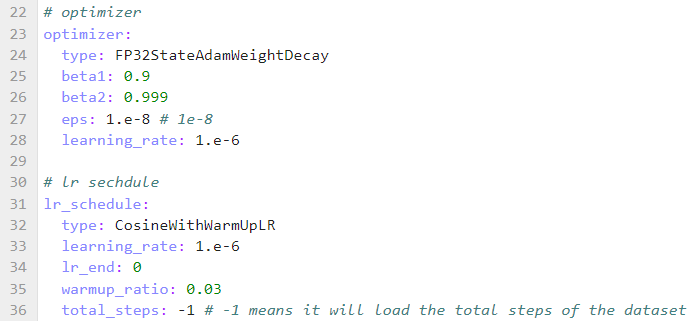

备注,alpaca数据集最长不超过2048,因此seq_length采用2048即可。
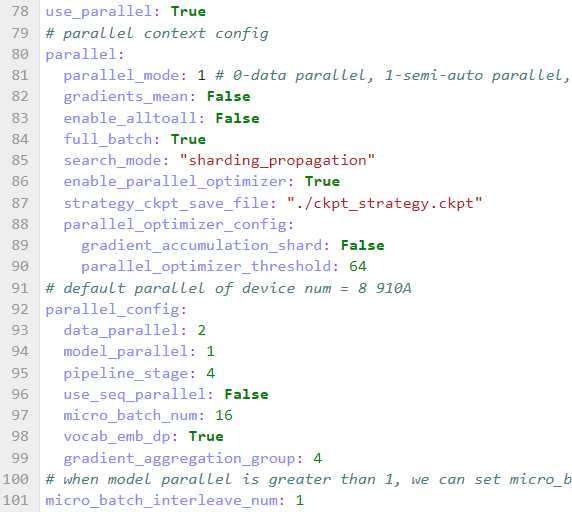
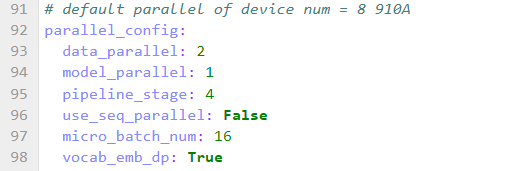
step 3. 并行策略配置
微调 llama2-7b 时修改并行策略配置,配置如下:
![]()
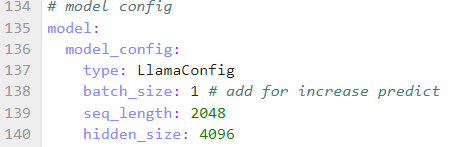
step 4. 添加预训练权重路径
修改配置文件中的 load_checkpoint,配置预训练权重路径,如下图所示

step5. 设置环境变量
变量配置如下:
cd /home/ma-user/work/mindformers/scripts
vi env_npu_finetune.sh
# 注释掉 "export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE" # llama2_7b 不用设置该项",如下图一所示
# 然后保存关闭
vi run_distribute.sh
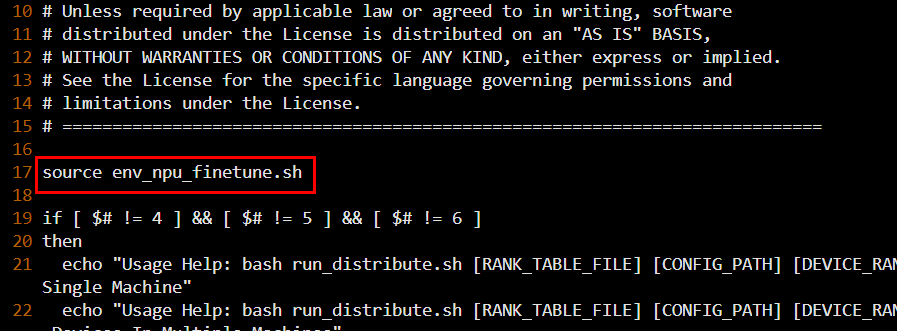
# 在 run_distribute.sh 文件中作如下修改(如下图二所示),然后保存关闭
source env_npu_finetune.sh图一

图二
step 6. 启动微调任务
llama2-7b模型以单机八卡为例进行微调,命令如下:
# 执行如下命令,拉起8卡分布式预训练
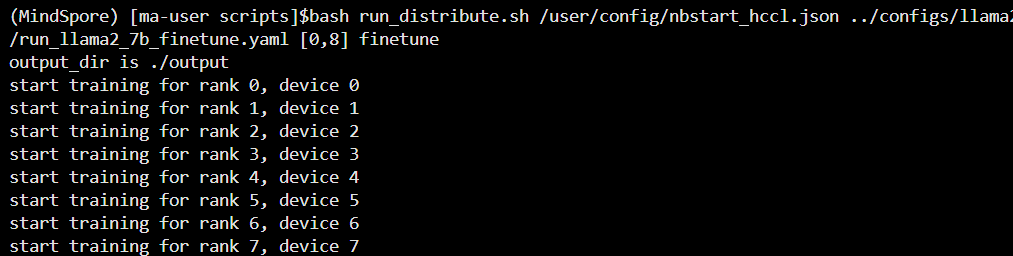
cd /home/ma-user/work/mindformers/scripts
bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/llama2/run_llama2_7b_finetune.yaml [0,8] finetune如下图所示
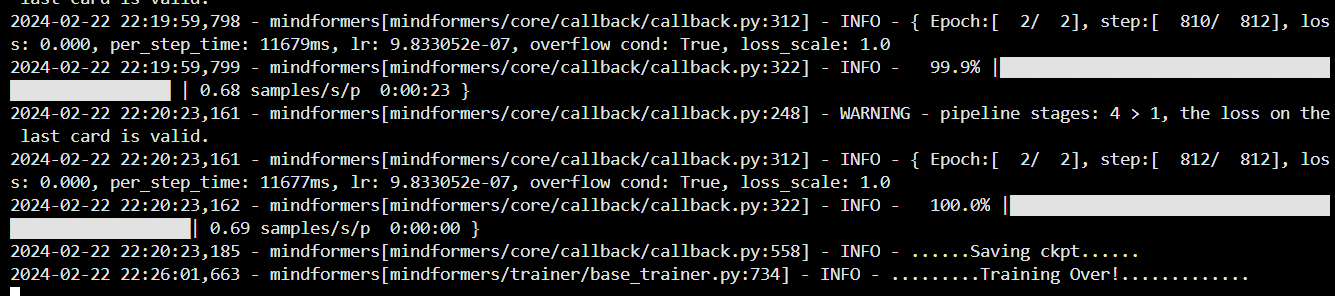
日志中如下图所示,说明训练成功
备注:1. 启动命令执行时如果出现 “run_distribute.sh: line 69: ulimit: max user porecesses: cannot modify limit: Operateion not permitted”或者类似的内容,请忽略;
2. 全参微调输出的log日志路径:/home/ma-user/work/mindformers/output/log ;
3. 全参微调checkpoint存储路径:/home/ma-user/work/mindformers/output/checkpoint ;
4.2.2. Lora微调
使用LoRA低参微调算法,冻结原模型权重,仅在小规模参数量上进行训练,使大模型在少量资源的情况下也能训练。使用LoRA算法进行低参微调时,使用 configs/llama2/run_llama2_7b_lora.yaml 配置文件,该配置文件包含了lora低参微调算法所需的配置项。
Lora低参微调本文档以8卡为例
step 1. 修改数据集/模型权重配置路径
修改 configs/llama2/run_llama2_7b_lora.yaml 脚本中train_dataset 的 dataset_dir 为前文生成的数据集路径,如下图所示

修改 configs/llama2/run_llama2_7b_lora.yaml 脚本中的 load_checkpoint 为预训练模型权重路径,如下图所示

step 2. 设置环境变量
cd /home/ma-user/work/mindformers/scripts
vi env_npu_finetune.sh
# 注释掉 "export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE" # llama2_7b 不用设置该项",如下图一所示
# 然后保存关闭
vi run_distribute.sh
# 在 run_distribute.sh 文件中作如下修改(如下图二所示),然后保存关闭
source env_npu_finetune.sh图一
图二
step 3. 启动lora微调任务
# 执行如下命令,拉起8卡分布式预训练
cd /home/ma-user/work/mindformers/scripts
bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/llama2/run_llama2_7b_lora.yaml [0,8] finetune如下图所示

日志中如下图所示,说明训练成功
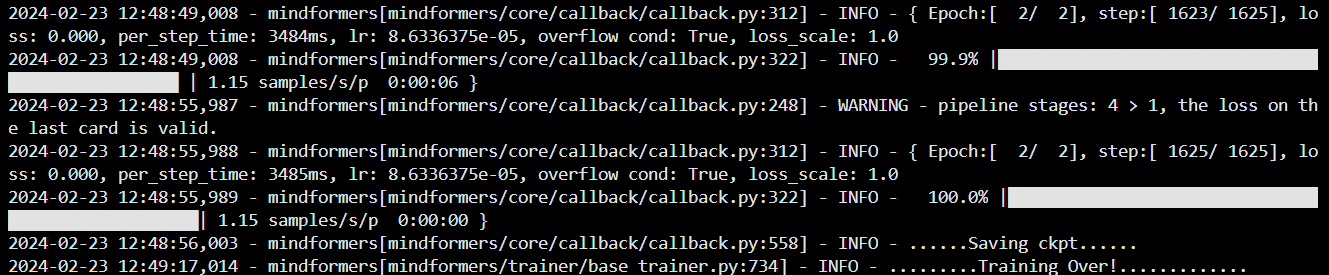
备注:1. 启动命令执行时如果出现 “run_distribute.sh: line 69: ulimit: max user porecesses: cannot modify limit: Operateion not permitted”或者类似的内容,请忽略;
2. Lora低参微调输出的log日志路径:/home/ma-user/work/mindformers/output/log ;
3. Lora低参微调checkpoint存储路径:/home/ma-user/work/mindformers/output/checkpoint ;
4.3. 推理
llama2-7b提供“基于generate的推理、基于pipline的推理、基于run_minformer推理”这三种推理方式,同时也分别支持单卡或者多卡推理,本文档以“基于generate的推理”的单卡推理为例(了解其他推理方式请参考链接 docs/model_cards/llama2.md · MindSpore/mindformers - Gitee.com )。
本文档以lora低参微调后的分布式权重为例
step 1. 分布式权重合并
# llama2-7b进行Lora低参微调后checkpoint存储路径为 /home/ma-user/work/mindformers/output/checkpoint ,
# 由于在 Lora低参微调 的时候开启了流水线并行( 即,pipeline_stage: 4 )
# 因此会有如下命令
cd /home/ma-user/work/mindformers/output
mkdir target_ckpt
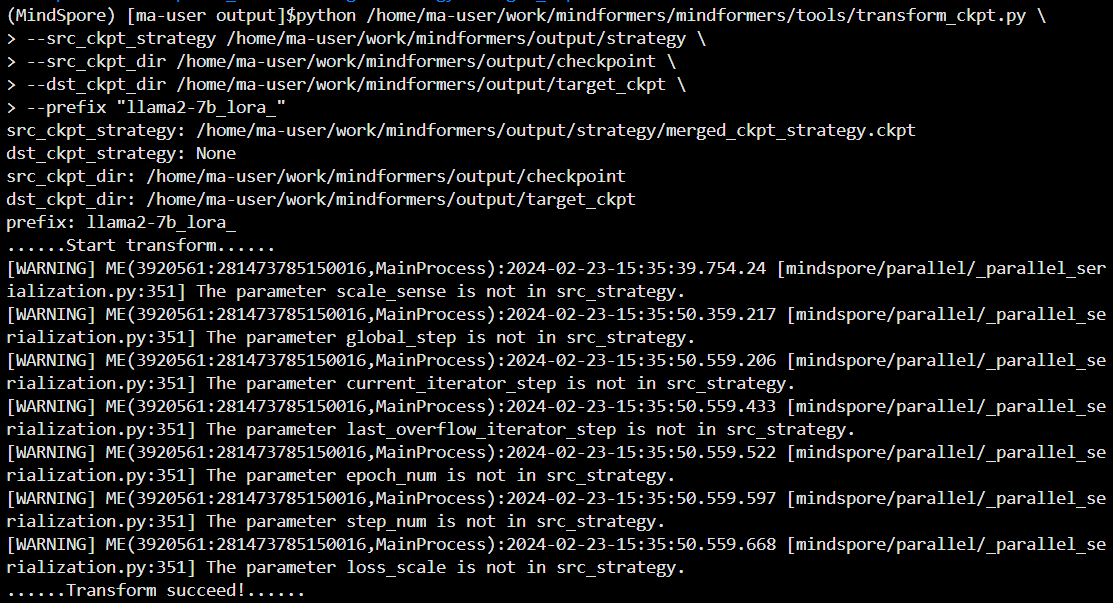
python /home/ma-user/work/mindformers/mindformers/tools/transform_ckpt.py \
--src_ckpt_strategy /home/ma-user/work/mindformers/output/strategy \
--src_ckpt_dir /home/ma-user/work/mindformers/output/checkpoint \
--dst_ckpt_dir /home/ma-user/work/mindformers/output/target_ckpt \
--prefix "llama2-7b_lora_"如下图所示,分布式权重合并成功
合并后的权重如下图所示

备注,src_ckpt_strategy:源权重对应的分布式策略文件路径。源权重为完整权重则不填写;若为分布式权重,视以下情况填写:
a. 源权重开启了流水线并行:权重转换基于合并的策略文件,填写分布式策略文件夹路径,脚本会自动将文件夹内所有ckpt_strategy_rank_x.ckpt合并,并在文件夹下生成merged_ckpt_strategy.ckpt;如果已有merged_ckpt_strategy.ckpt,可以直接填写该文件路径;
b. 源权重未开启流水线并行:权重转换基于任一策略文件,填写任一ckpt_strategy_rank_x.ckpt路径即可。
step 2. 修改推理配置文件
修改 configs/llama2/run_llama2_7b_lora_infer.yaml 配置文件,如下图所示
![]()
![]()
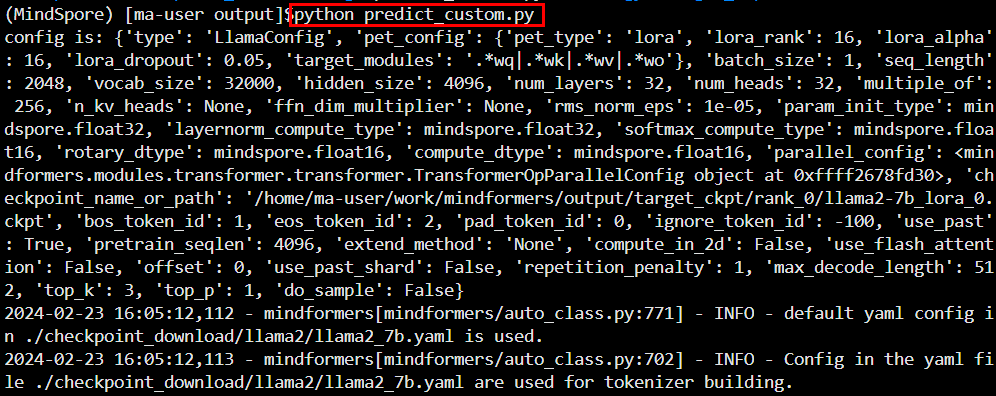
step 3. 推理脚本
在目录 /home/ma-user/work/mindformers/output 下,执行 touch predict_custom.py 命令,创建一个 名称为 predict_custom.py 的文件,将下面的内容拷贝到该文件中。
import argparse
import mindspore as ms
import numpy as np
import os
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train import Model
from mindformers import MindFormerConfig, LlamaConfig, TransformerOpParallelConfig, AutoTokenizer, LlamaForCausalLM
from mindformers import init_context, ContextConfig, ParallelContextConfig
from mindformers.tools.utils import str2bool
from mindformers.trainer.utils import get_last_checkpoint
def main(args):
"""main function."""
# 输入
# inputs = ["I love Beijing, because",
# # "LLaMA is a",
# # "Huawei is a company that"
# ]
# set model config
config = MindFormerConfig(args.yaml_file)
# 初始化环境
init_context(use_parallel=config.use_parallel,
context_config=config.context,
parallel_config=config.parallel)
model_config = LlamaConfig(**config.model.model_config)
model_config.parallel_config = TransformerOpParallelConfig(**config.parallel_config)
# model_config.batch_size = len(inputs)
model_config.batch_size = 1
model_config.use_past = args.use_past
model_config.seq_length = args.seq_length
if args.checkpoint_path and not config.use_parallel:
model_config.checkpoint_name_or_path = args.checkpoint_path
print(f"config is: {model_config}")
# build tokenizer
tokenizer = AutoTokenizer.from_pretrained(args.model_type)
# build model from config
model = LlamaForCausalLM(model_config)
# if use parallel, load distributed checkpoints
if config.use_parallel:
# find the sharded ckpt path for this rank
ckpt_path = os.path.join(args.checkpoint_path, "rank_{}".format(os.getenv("RANK_ID", "0")))
ckpt_path = get_last_checkpoint(ckpt_path)
print("ckpt path: %s", str(ckpt_path))
# shard model and load sharded ckpt
warm_up_model = Model(model)
warm_up_model.infer_predict_layout(ms.Tensor(np.ones(shape=(1, model_config.seq_length)), ms.int32))
checkpoint_dict = load_checkpoint(ckpt_path)
not_load_network_params = load_param_into_net(model, checkpoint_dict)
print("Network parameters are not loaded: %s", str(not_load_network_params))
count_i = 0
while True:
if count_i == 0:
inputs = "你好"
else:
inputs = input("please input your question (if you want to logout, put in 'quit' please): ")
if inputs == "quit":
break
inputs_ids = tokenizer(inputs, max_length=model_config.seq_length, padding="max_length")["input_ids"]
output = model.generate(inputs_ids,
max_length=model_config.max_decode_length,
do_sample=True,
top_k=model_config.top_k,
top_p=model_config.top_p)
print(tokenizer.decode(output))
count_i += 1
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--model_type', default='llama2_7b', type=str, help='which model to use.')
parser.add_argument('--device_id', default=0, type=int, help='set device id.')
parser.add_argument('--checkpoint_path', default='/home/ma-user/work/mindformers/output/target_ckpt/rank_0/llama2-7b_lora_0.ckpt', type=str, help='set checkpoint path.')
parser.add_argument('--use_past', default=True, type=str2bool, help='whether use past.')
parser.add_argument('--yaml_file', default="/home/ma-user/work/mindformers/configs/llama2/run_llama2_7b_lora_infer.yaml", type=str, help='predict yaml path')
parser.add_argument('--seq_length', default=2048, type=int, help='predict max length')
args = parser.parse_args()
main(args)
其中,“ --checkpoint_path ”、“ --yaml_file ”可以根据实际位置填写;
step 4. 执行推理
# 执行单卡推理为例
python predict_custom.py如下图所示,则推理成功
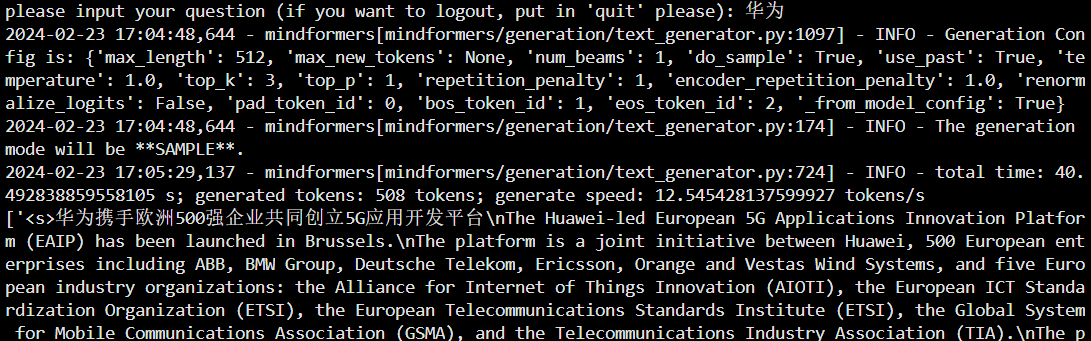
5. llama2-13b的预训练、微调以及推理
5.1. 预训练
llama2-13b的预训练至少需要2机16卡,并且需要在平台的云上设置训练任务,本文档以2机16卡为例。
备注,在平台云上进行预训练的时候会用到镜像 swr.cn-north-300.hblfrgzn.com/vision/llama2:v1.0 ,因此在进行该训练任务的时候,需要先进行该镜像的注册(ps,镜像注册请参考文档“环境准备-注册镜像指导”,链接为:https://www.yuque.com/fanxiangyu-xamn0/sthma6/yy05acmwpm6dqgmx? singleDoc# )。
step 1. 修改模型对应的配置文件
在模型对应的配置文件 configs/llama2/run_llama2_13b_pretrained.yaml 中,用户可自行修改模型、训练相关参数,并通过train_dataset的dataset_dir参数,指定训练数据集的路径,如下图所示
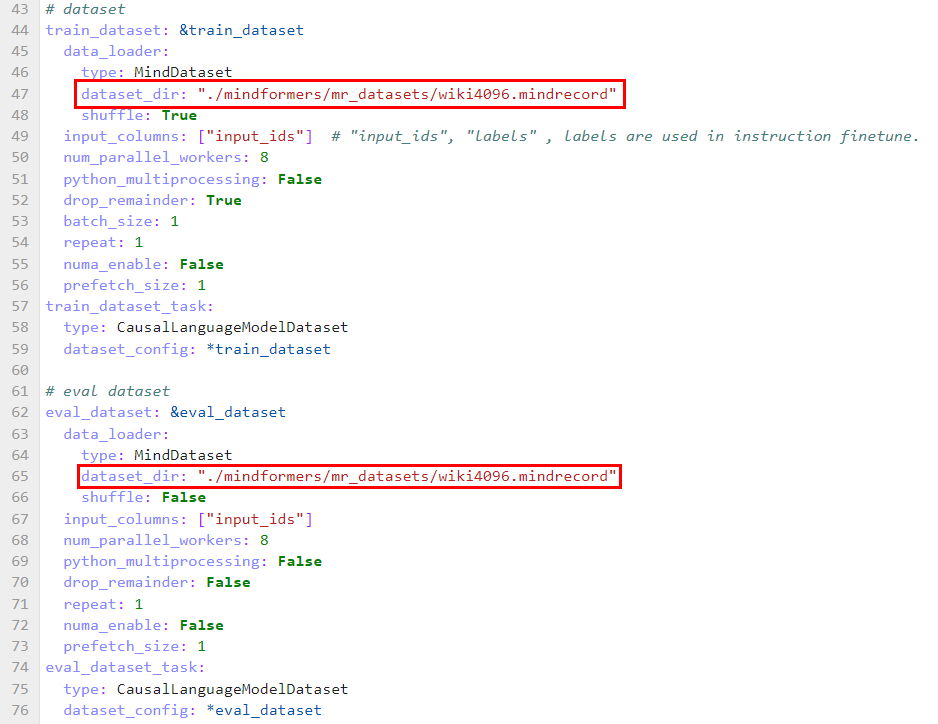
step2. 配置云上环境
a. 将从步骤2.1中获得的代码以及权重文件放置到obs桶中,如下图所示
b. 设置云上训练任务参数
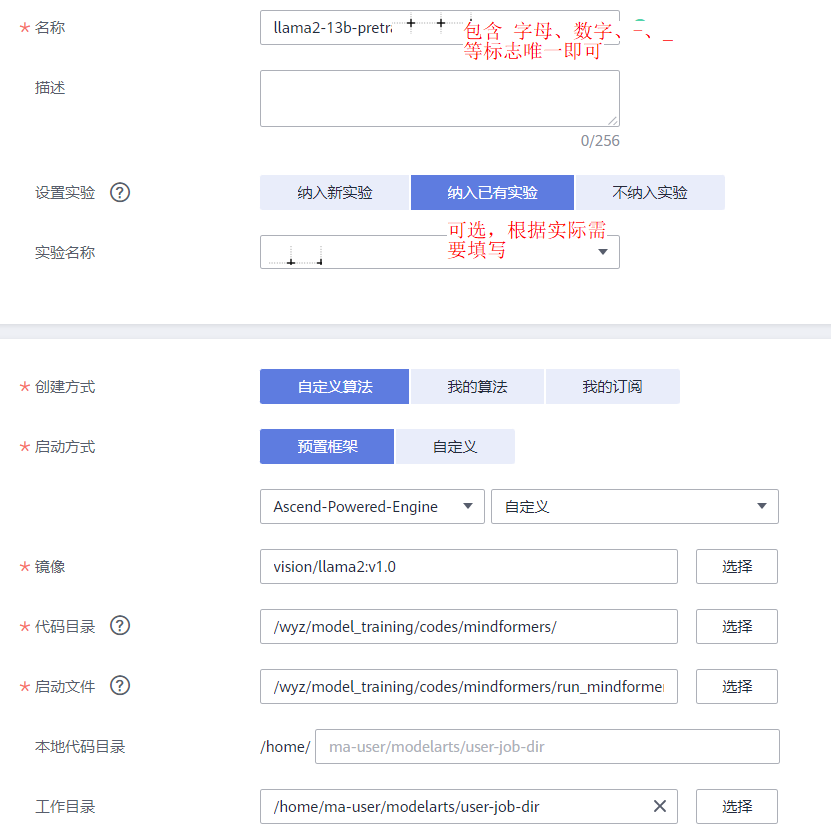
其中,“启动文件”的路径为“ /wyz/model_training/codes/mindformers/run_mindformer.py ”;
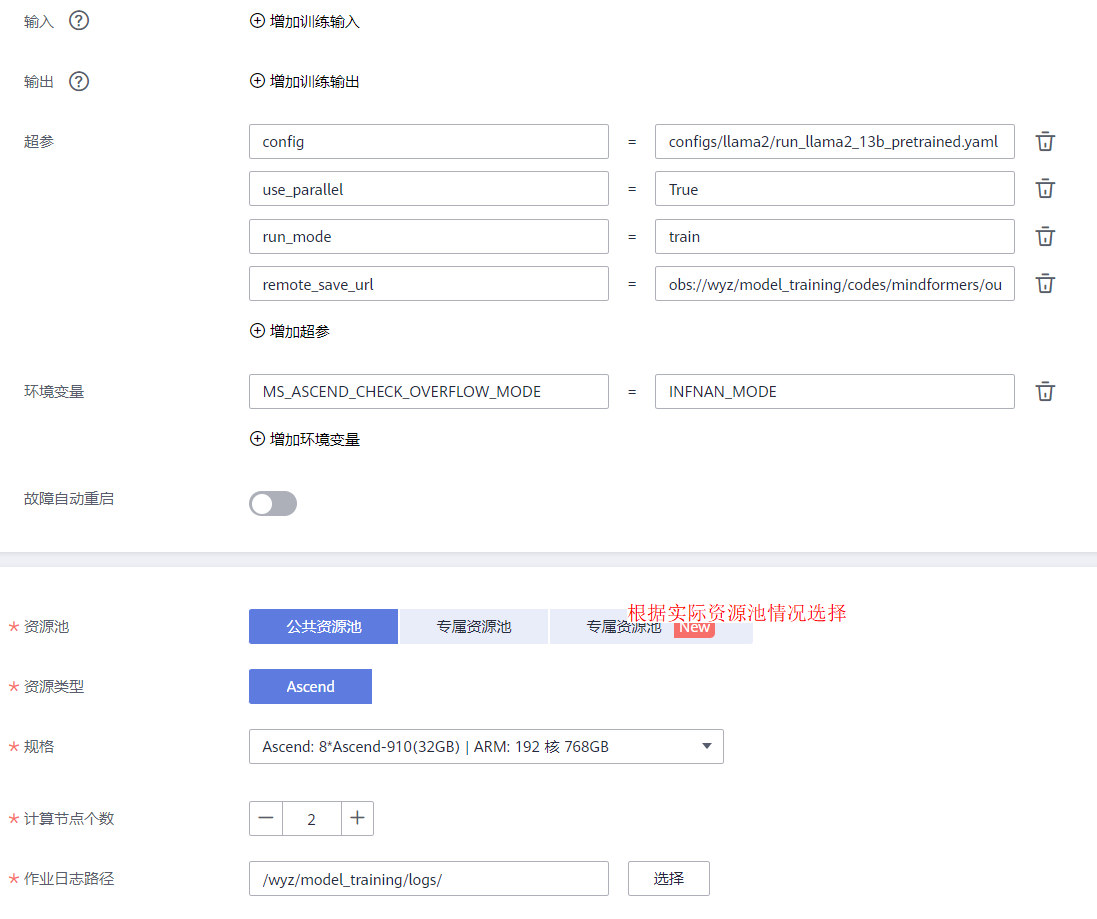
其中,“remote_save_url”的路径为“ obs://wyz/model_training/codes/mindformers/output ”;
step 3. 开启训练任务
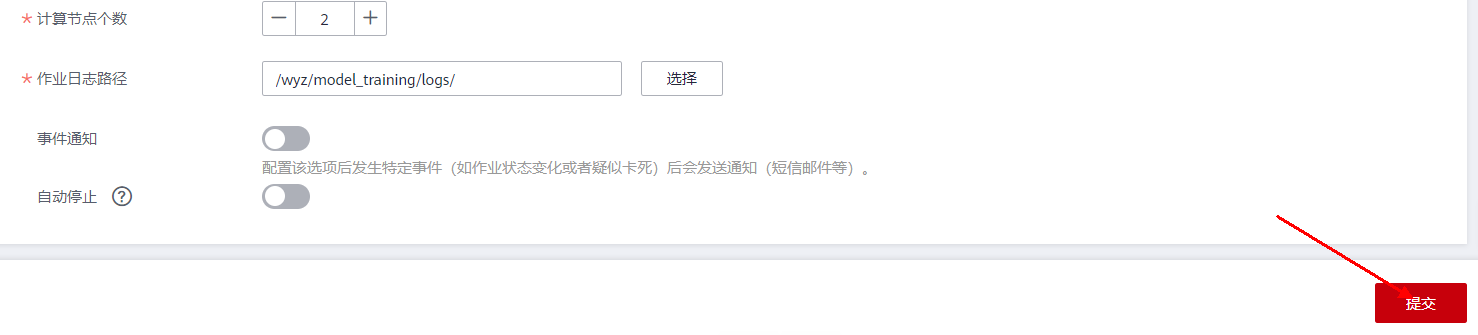
点击“提交”,如下图所示
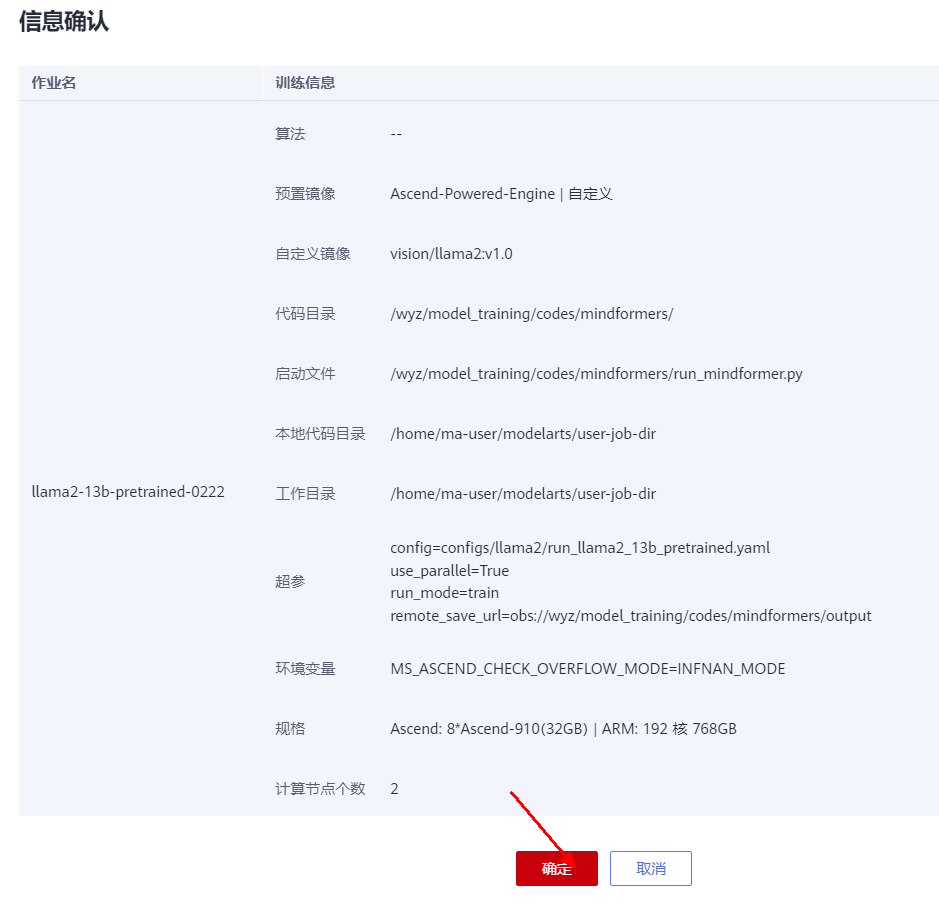
点击“确定”,如下图所示
如下所示,表明训练任务正常开启运行

如下所示,表明训练任务成功完成
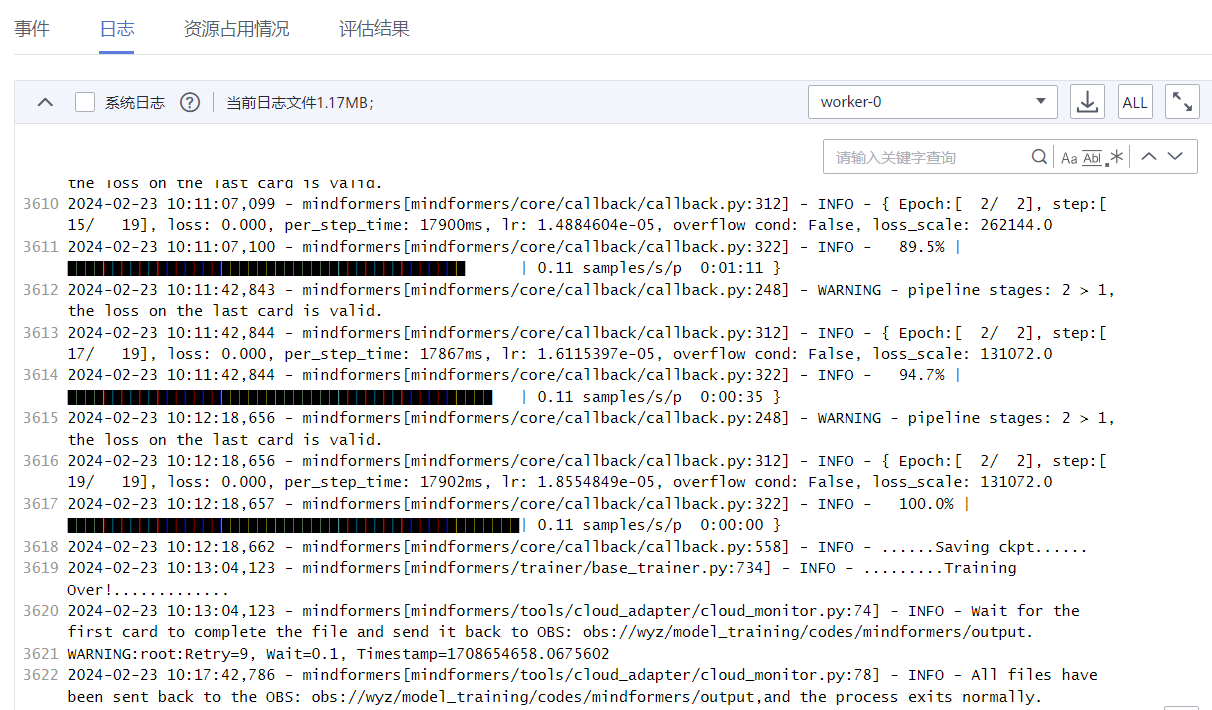
备注:1. 预训练输出的log日志路径:obs://xxx/model_training/codes/mindformers/output/log ;
2. 预训练checkpoint存储路径:obs://xxx/model_training/codes/mindformers/output/checkpoint ;
5.2. 微调
llama2-13b的微调目前有 全参微调 和 Lora微调
5.2.1. 全参微调
llama2-13b的全参微调至少需要2机16卡,并且需要在平台的云上设置训练任务,本文档以2机16卡为例。
备注,在平台云上进行预训练的时候会用到镜像 swr.cn-north-300.hblfrgzn.com/vision/llama2:v1.0 ,因此在进行该训练任务的时候,需要先进行该镜像的注册(ps,镜像注册请参考文档“环境准备-注册镜像指导”,链接为:https://www.yuque.com/fanxiangyu-xamn0/sthma6/yy05acmwpm6dqgmx? singleDoc# )。
step 1. 修改模型对应的配置文件
参考 configs/llama2/run_llama2_13b_finetune.yaml 中训练数据集路径为微调数据集路径,并在 input_columns 中添加 labels ,如下图所示

修改微调时学习率, 优化器参数,seq_length , 新增 context 中参数, 与预训练不同,微调配置如下:
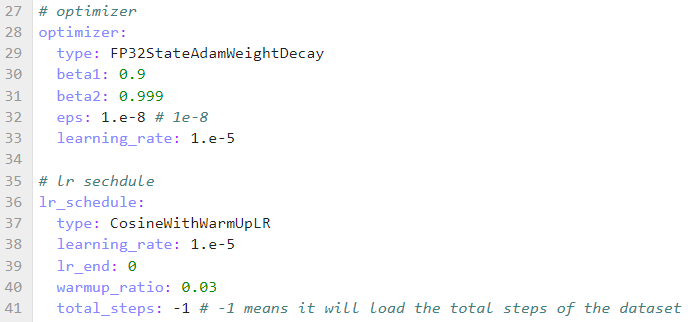
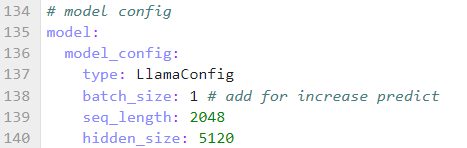
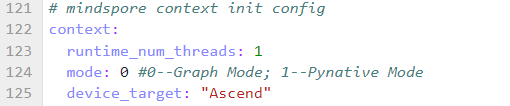
备注,alpaca数据集最长不超过2048,因此seq_length采用2048即可。
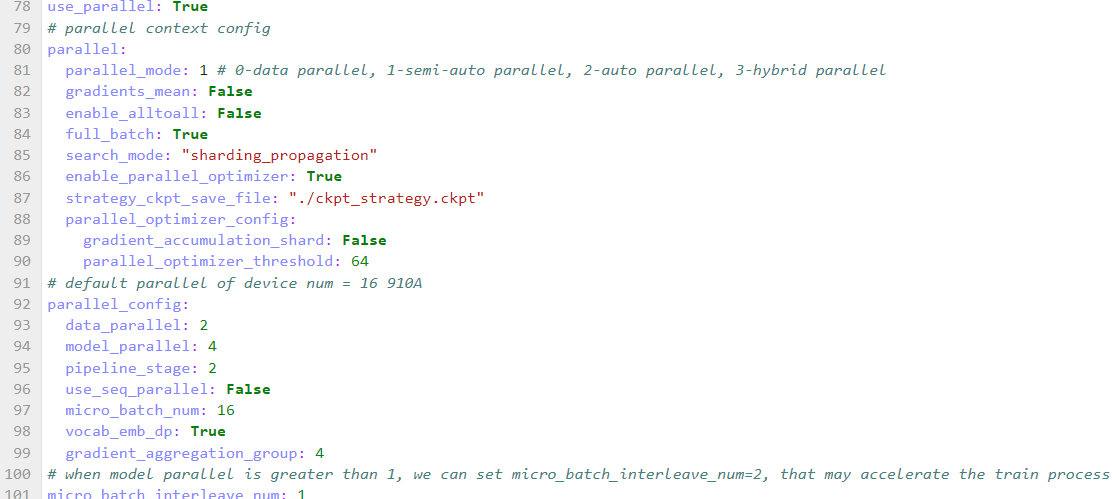
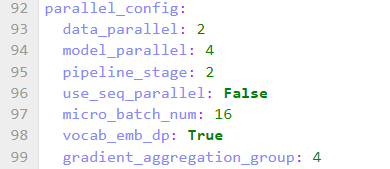
微调 llama2-13b 时修改并行策略配置,配置如下:
![]()
修改配置文件中的 load_checkpoint,配置预训练权重路径,如下图所示

step2. 配置云上环境
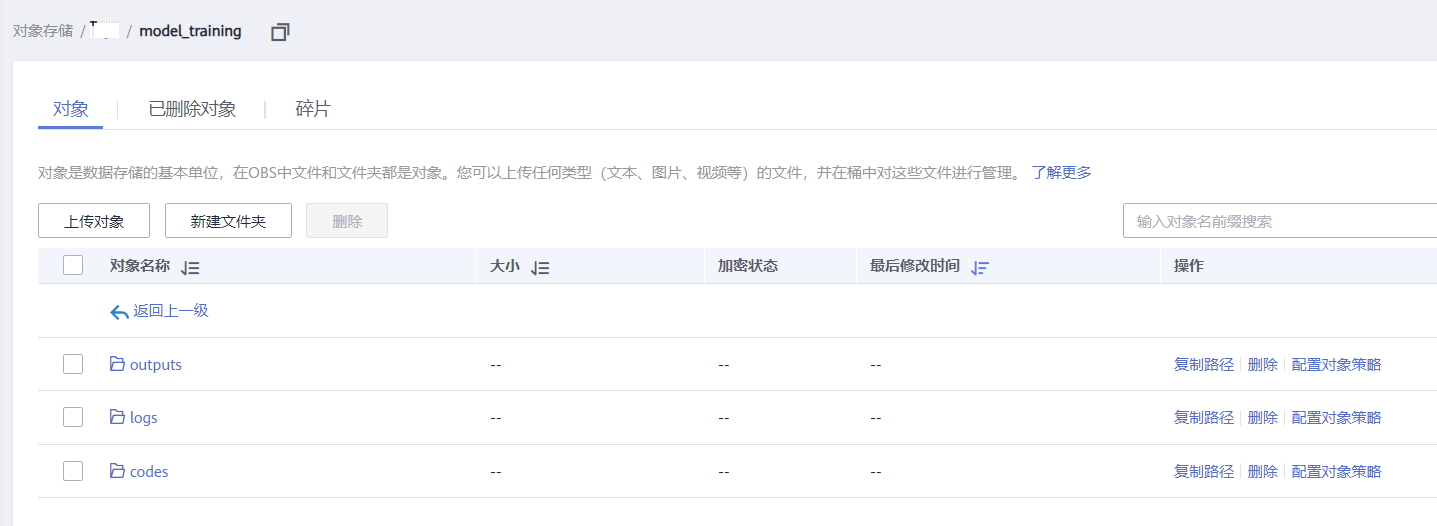
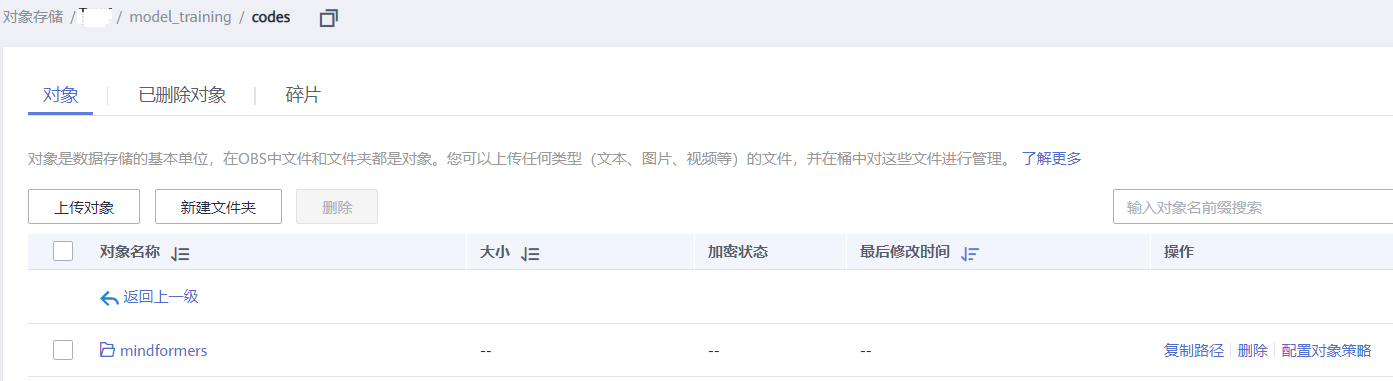
a. 将从步骤2.1中获得的代码以及权重文件放置到obs桶中,如下图所示
b. 设置云上训练任务参数
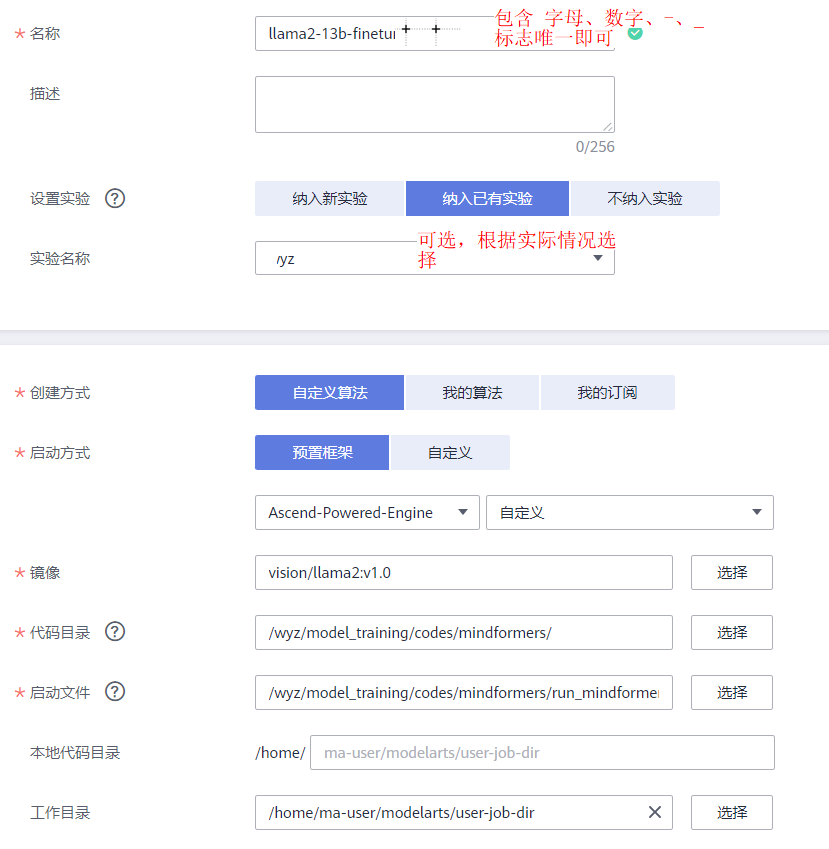
其中,“启动文件”的路径为“ /wyz/model_training/codes/mindformers/run_mindformer.py ”;
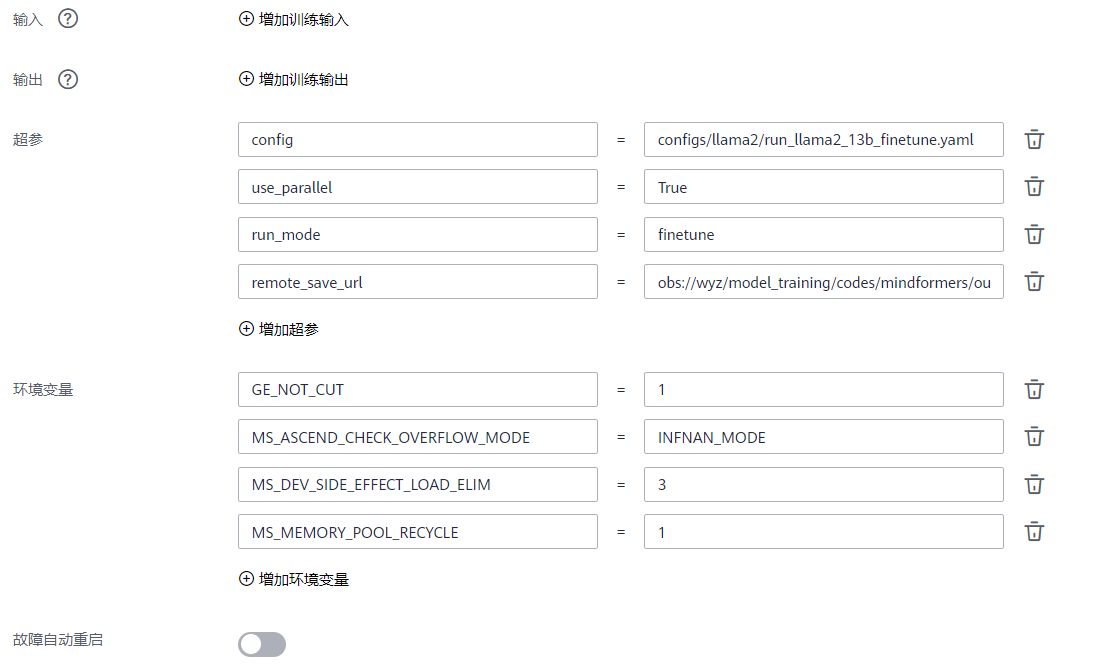
其中,“remote_save_url”的路径为“ obs://wyz/model_training/codes/mindformers/output ”;
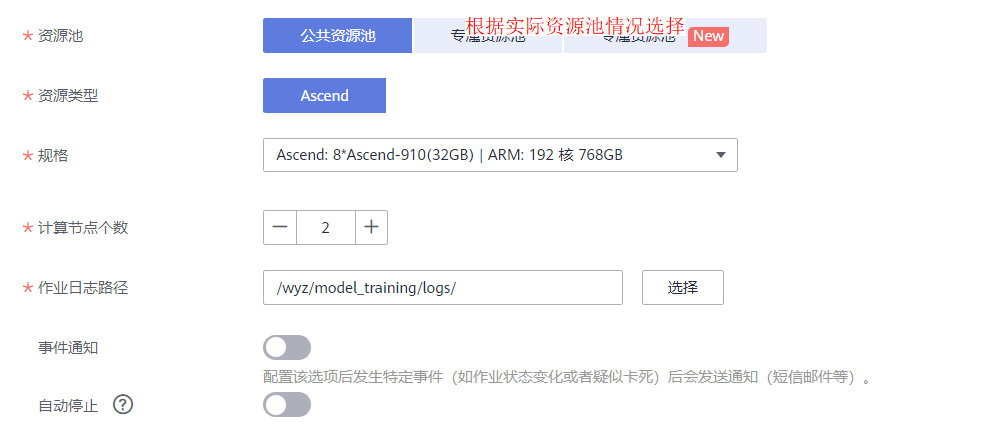
step 3. 开启训练任务
点击“提交”,如下图所示
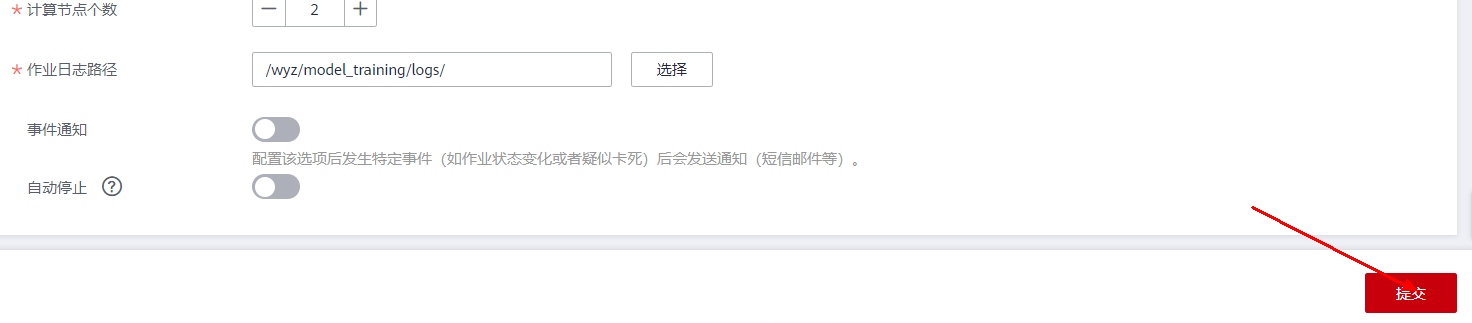
点击“确定”,如下图所示
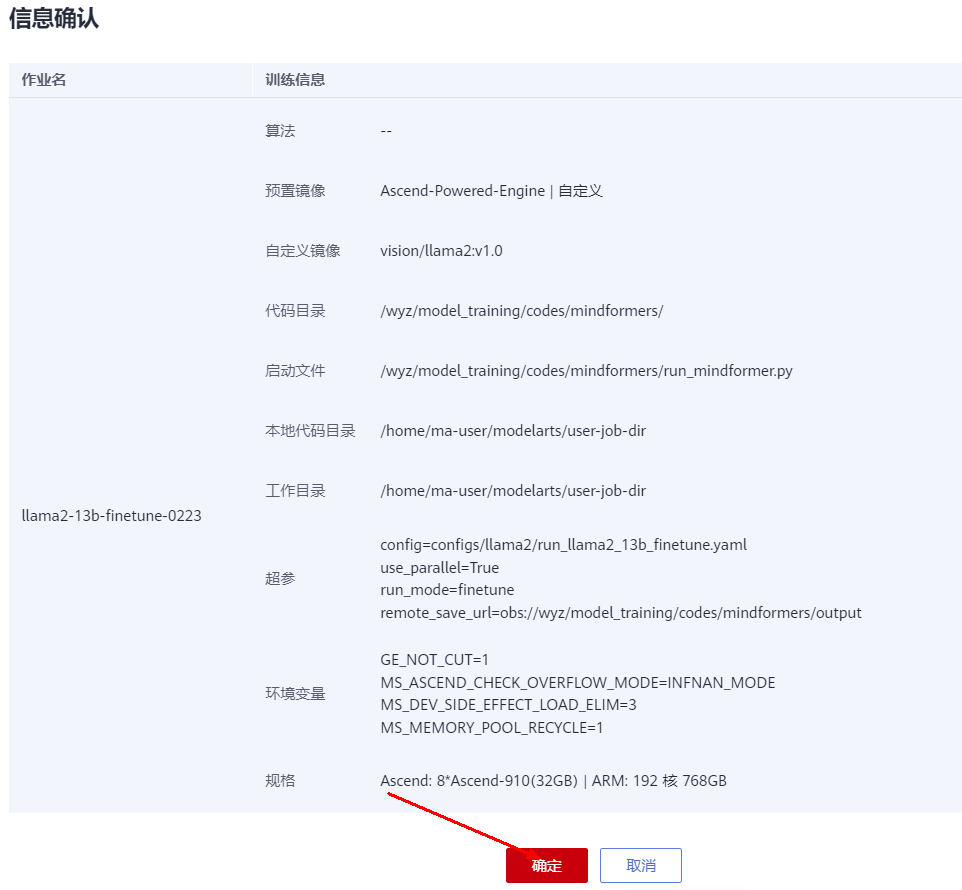
如下所示,表明训练任务正常开启运行
如下所示,表明训练任务成功完成
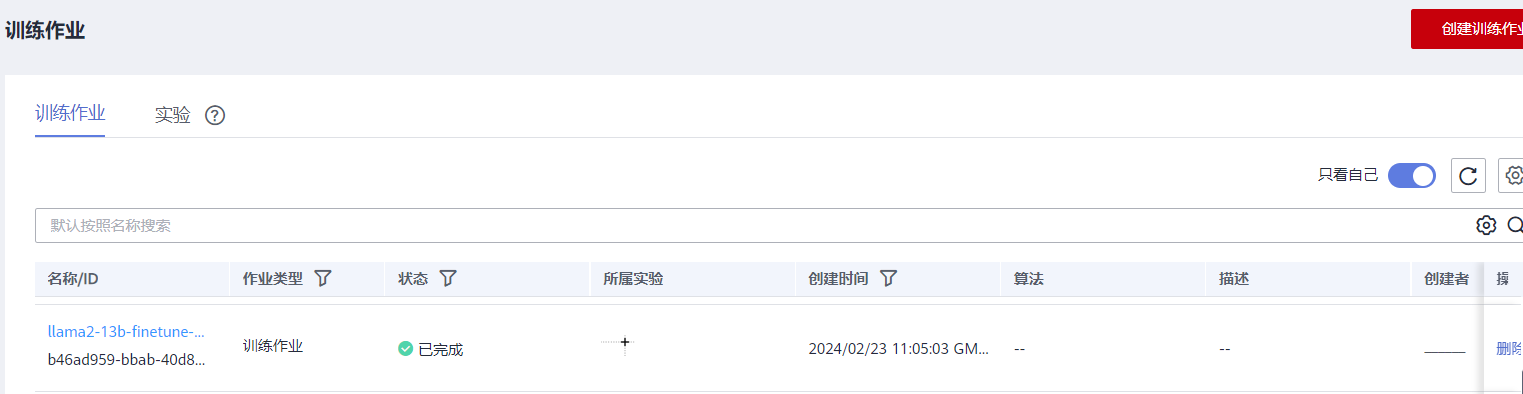
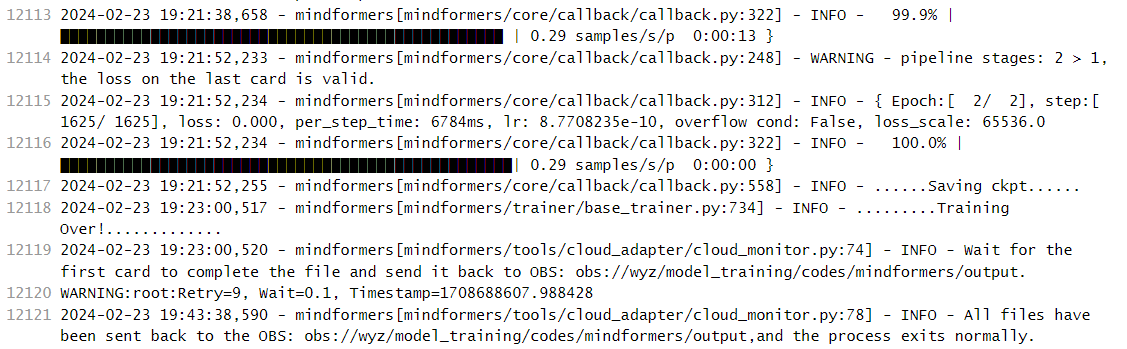
备注:1. 预训练输出的log日志路径:obs://xxx/model_training/codes/mindformers/output/log ;
2. 预训练checkpoint存储路径:obs://xxx/model_training/codes/mindformers/output/checkpoint ;
5.2.2. Lora微调
用LoRA低参微调算法,冻结原模型权重,仅在小规模参数量上进行训练,使大模型在少量资源的情况下也能训练。使用LoRA算法进行低参微调时,使用 configs/llama2/run_llama2_13b_lora.yaml 配置文件,该配置文件包含了lora低参微调算法所需的配置项。
Lora低参微调本文档以8卡为例
step 1. 修改数据集/模型权重配置路径
修改 configs/llama2/run_llama2_13b_lora.yaml 脚本中train_dataset 的 dataset_dir 为前文生成的数据集路径,如下图所示

修改 configs/llama2/run_llama2_13b_lora.yaml 脚本中的 load_checkpoint 为预训练模型权重路径,如下图所示

step 2. 设置环境变量
cd /home/ma-user/work/mindformers/scripts
vi env_npu_finetune.sh
# 打开注释 "export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE" # llama2_7b 不用设置该项",如下图一所示
# 然后保存关闭
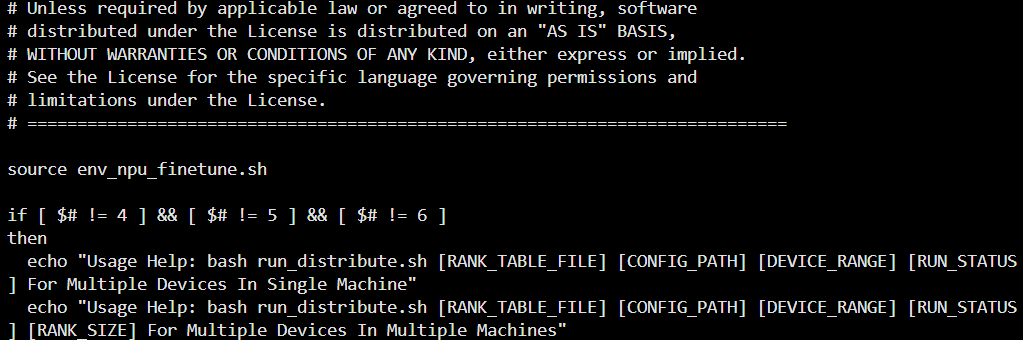
vi run_distribute.sh
# 在 run_distribute.sh 文件中作如下修改(如下图二所示),然后保存关闭
source env_npu_finetune.sh图一

图二
step 3. 启动lora微调任务
# 执行如下命令,拉起8卡分布式预训练
cd /home/ma-user/work/mindformers/scripts
bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/llama2/run_llama2_13b_lora.yaml [0,8] finetune如下图所示
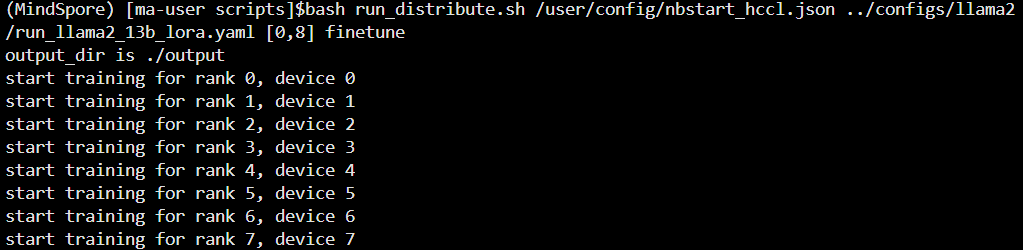
日志中如下图所示,说明训练成功
图片。。。。。。
备注:1. 启动命令执行时如果出现 “run_distribute.sh: line 69: ulimit: max user porecesses: cannot modify limit: Operateion not permitted”或者类似的内容,请忽略;
2. Lora低参微调输出的log日志路径:/home/ma-user/work/mindformers/output/log ;
3. Lora低参微调checkpoint存储路径:/home/ma-user/work/mindformers/output/checkpoint ;
5.3. 推理
llama2-13b提供“基于generate的推理、基于pipline的推理、基于run_minformer推理”这三种推理方式,同时也分别支持单卡或者多卡推理,本文档以“基于generate的推理”的单卡推理为例(了解其他推理方式请参考链接 docs/model_cards/llama2.md · MindSpore/mindformers - Gitee.com )。
本文档以lora低参微调后的分布式权重为例
step 1. 分布式权重合并
# llama2-13b进行Lora低参微调后checkpoint存储路径为 /home/ma-user/work/mindformers/output/checkpoint ,
# 由于在 Lora低参微调 的时候开启了流水线并行( 即,pipeline_stage: 4 )
# 因此会有如下命令
cd /home/ma-user/work/mindformers/output
mkdir target_ckpt
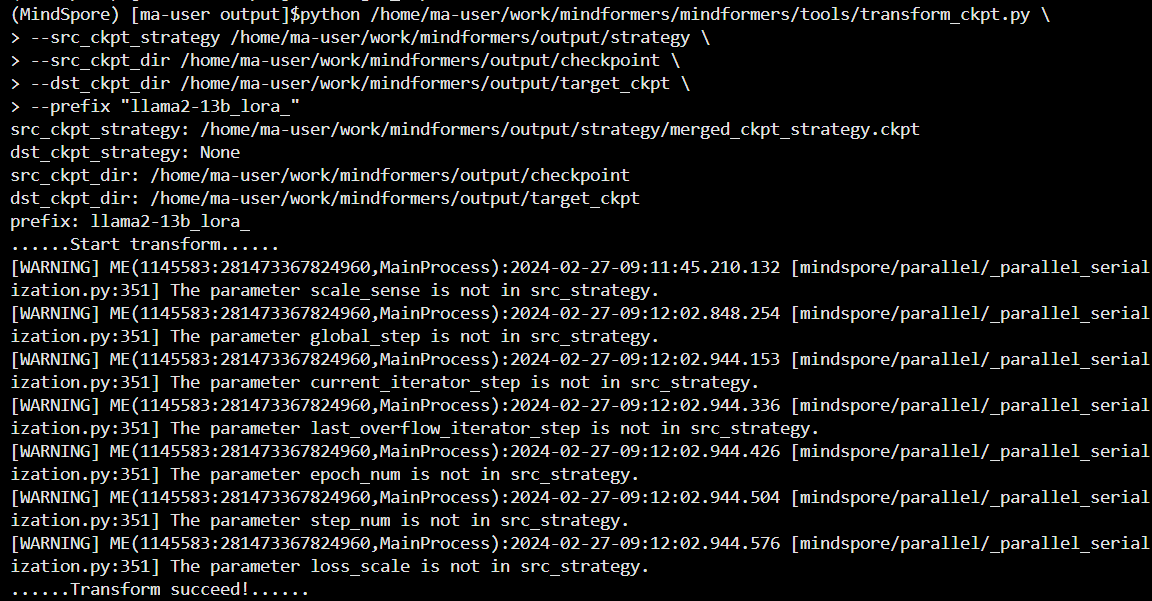
python /home/ma-user/work/mindformers/mindformers/tools/transform_ckpt.py \
--src_ckpt_strategy /home/ma-user/work/mindformers/output/strategy \
--src_ckpt_dir /home/ma-user/work/mindformers/output/checkpoint \
--dst_ckpt_dir /home/ma-user/work/mindformers/output/target_ckpt \
--prefix "llama2-13b_lora_"如下图所示,分布式权重合并成功
合并后的权重如下图所示

备注,src_ckpt_strategy:源权重对应的分布式策略文件路径。源权重为完整权重则不填写;若为分布式权重,视以下情况填写:
a. 源权重开启了流水线并行:权重转换基于合并的策略文件,填写分布式策略文件夹路径,脚本会自动将文件夹内所有ckpt_strategy_rank_x.ckpt合并,并在文件夹下生成merged_ckpt_strategy.ckpt;如果已有merged_ckpt_strategy.ckpt,可以直接填写该文件路径;
b. 源权重未开启流水线并行:权重转换基于任一策略文件,填写任一ckpt_strategy_rank_x.ckpt路径即可。
step 2. 修改推理配置文件
修改 configs/llama2/run_llama2_13b_lora_infer.yaml 配置文件,如下图所示
![]()
step 3. 推理脚本
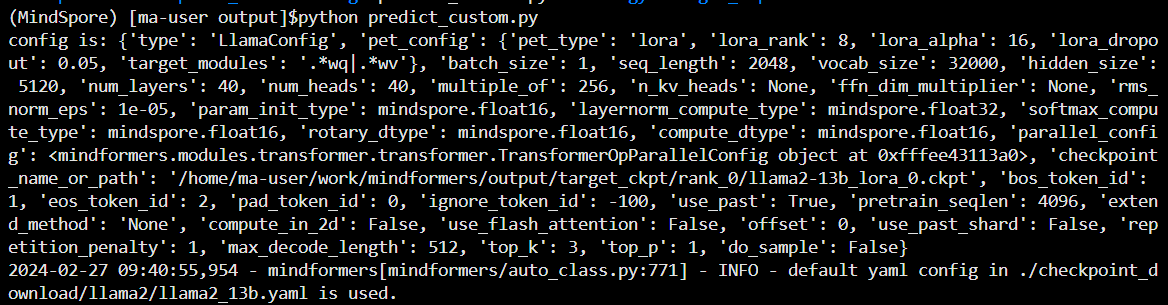
在目录 /home/ma-user/work/mindformers/output 下,执行 touch predict_custom.py 命令,创建一个 名称为 predict_custom.py 的文件,将下面的内容拷贝到该文件中。
import argparse
import mindspore as ms
import numpy as np
import os
from mindspore import load_checkpoint, load_param_into_net
from mindspore.train import Model
from mindformers import MindFormerConfig, LlamaConfig, TransformerOpParallelConfig, AutoTokenizer, LlamaForCausalLM
from mindformers import init_context, ContextConfig, ParallelContextConfig
from mindformers.tools.utils import str2bool
from mindformers.trainer.utils import get_last_checkpoint
def main(args):
"""main function."""
# 输入
# inputs = ["I love Beijing, because",
# # "LLaMA is a",
# # "Huawei is a company that"
# ]
# set model config
config = MindFormerConfig(args.yaml_file)
# 初始化环境
init_context(use_parallel=config.use_parallel,
context_config=config.context,
parallel_config=config.parallel)
model_config = LlamaConfig(**config.model.model_config)
model_config.parallel_config = TransformerOpParallelConfig(**config.parallel_config)
# model_config.batch_size = len(inputs)
model_config.batch_size = 1
model_config.use_past = args.use_past
model_config.seq_length = args.seq_length
if args.checkpoint_path and not config.use_parallel:
model_config.checkpoint_name_or_path = args.checkpoint_path
print(f"config is: {model_config}")
# build tokenizer
tokenizer = AutoTokenizer.from_pretrained(args.model_type)
# build model from config
model = LlamaForCausalLM(model_config)
# if use parallel, load distributed checkpoints
if config.use_parallel:
# find the sharded ckpt path for this rank
ckpt_path = os.path.join(args.checkpoint_path, "rank_{}".format(os.getenv("RANK_ID", "0")))
ckpt_path = get_last_checkpoint(ckpt_path)
print("ckpt path: %s", str(ckpt_path))
# shard model and load sharded ckpt
warm_up_model = Model(model)
warm_up_model.infer_predict_layout(ms.Tensor(np.ones(shape=(1, model_config.seq_length)), ms.int32))
checkpoint_dict = load_checkpoint(ckpt_path)
not_load_network_params = load_param_into_net(model, checkpoint_dict)
print("Network parameters are not loaded: %s", str(not_load_network_params))
count_i = 0
while True:
if count_i == 0:
inputs = "你好"
else:
inputs = input("please input your question (if you want to logout, put in 'quit' please): ")
if inputs == "quit":
break
inputs_ids = tokenizer(inputs, max_length=model_config.seq_length, padding="max_length")["input_ids"]
output = model.generate(inputs_ids,
max_length=model_config.max_decode_length,
do_sample=True,
top_k=model_config.top_k,
top_p=model_config.top_p)
print(tokenizer.decode(output))
count_i += 1
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--model_type', default='llama2_13b', type=str, help='which model to use.')
parser.add_argument('--device_id', default=0, type=int, help='set device id.')
parser.add_argument('--checkpoint_path', default='/home/ma-user/work/mindformers/output/target_ckpt/rank_0/llama2-13b_lora_0.ckpt', type=str, help='set checkpoint path.')
parser.add_argument('--use_past', default=True, type=str2bool, help='whether use past.')
parser.add_argument('--yaml_file', default="/home/ma-user/work/mindformers/configs/llama2/run_llama2_13b_lora_infer.yaml", type=str, help='predict yaml path')
parser.add_argument('--seq_length', default=2048, type=int, help='predict max length')
args = parser.parse_args()
main(args)
其中,“ --checkpoint_path ”、“ --yaml_file ”可以根据实际位置填写;
step 4. 执行推理
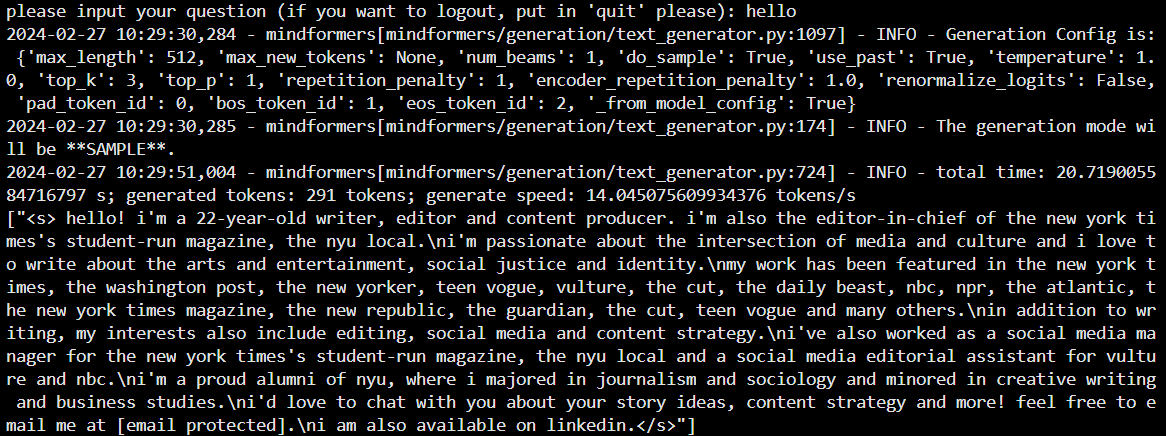
# 执行单卡推理为例
python predict_custom.py如下图所示,则推理成功
6. FAQ
1、问题:llama2-13b的全参微调在生成的checkpoint里面保存了多个ckpt,但是从文件名字来看后面保存的ckpt的最后修改时间比前面保存的ckpt的最后修改之间还要靠前。
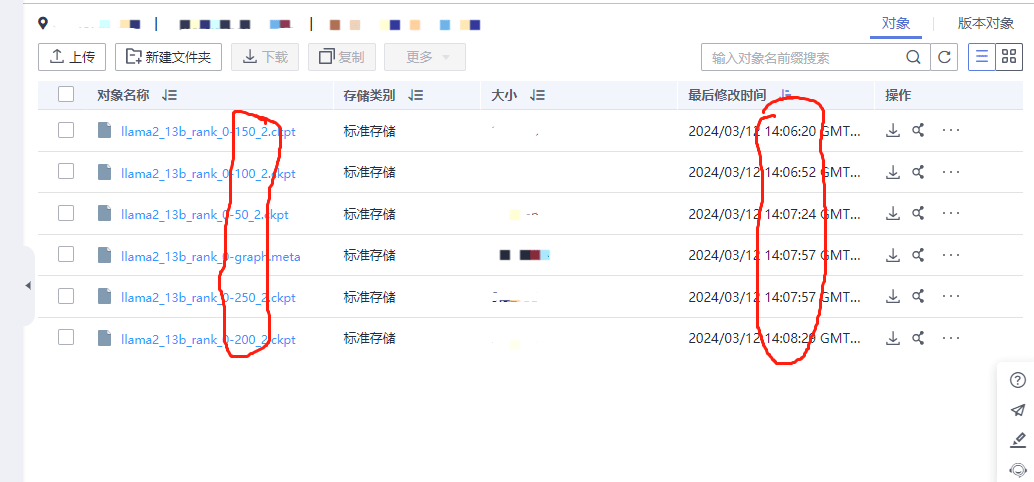
解答:obs上面的最后修改时间是将ckpt传输上obs的时间,并不是ckpt的生成时间,ckpt是先在机器上生成然后再上传到obs上面的,所以可能会存在时间和ckpt顺序对不上的情况 。
2、问题: 使用官方的llama2-13b的ckpt全参微调生成的分步式权重合并之后,权重从官方的24g涨到了146g。
解答:因合并的是mindformers/output/checkpoint路径下的权重,该路径下的ckpt文件中包含优化器参数,mindformers/output/checkpoint_network路径下的权重是不包含优化器参数的,合并之后文件大小是正常的。















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









